
热门标签
热门文章
- 1程序员如何入门 AI 应用开发?_ai应用开发需要学习什么
- 2【Java项目学习 Day01】创建JavaWeb的Maven项目_maven创建javaweb项目
- 3基于STM32的智能家庭安防系统_智能家居stm32教程
- 4DSL与自动化测试 – 用Python实现简单的DSL_自动化测试dsl工具
- 5【.NET资源收集】C#与时俱进的知识点..._c#函数式编程 编写更优质的c#代码pdf下载
- 6Coze扣子开发指南:用免费API自己创建插件_扣子api
- 7【Android】四大组件(Activity、Service、Broadcast Receiver、Content Provider)、结构目录
- 8python脚本批量生成数据
- 9python绘制算法时间维度图_算法运行时间图怎么画
- 10基于ROS的多差速移动机器人编队控制仿真实现_基于ros2的多机器人编队
当前位置: article > 正文
Python爬取豆瓣电影+数据可视化,爬虫教程!_python爬虫10页电影
作者:空白诗007 | 2024-08-07 01:02:44
赞
踩
python爬虫10页电影

1. 爬取数据
1.1 导入以下模块
- import os
- import re
- import time
- import requests
- from bs4 import BeautifulSoup
- from fake_useragent import UserAgent
- from openpyxl import Workbook, load_workbook
1.2 获取每页电影链接
- def getonepagelist(url,headers):
- try:
- r = requests.get(url, headers=headers, timeout=10)
- r.raise_for_status()
- r.encoding = 'utf-8'
- soup = BeautifulSoup(r.text, 'html.parser')
- lsts = soup.find_all(attrs={'class': 'hd'})
- for lst in lsts:
- href = lst.a['href']
- time.sleep(0.5)
- getfilminfo(href, headers)
- except:
- print('getonepagelist error!')
1.3 获取每部电影具体信息
- def getfilminfo(url,headers):
- filminfo = []
- r = requests.get(url, headers=headers, timeout=10)
- r.raise_for_status()
- r.encoding = 'utf-8'
- soup = BeautifulSoup(r.text, 'html.parser')
1.4 保存数据
- def insert2excel(filepath,allinfo):
- try:
- if not os.path.exists(filepath):
- tableTitle = ['片名','上映年份','评分','评价人数','导演','编剧','主演','类型','国家/地区','语言','时长(分钟)']
- wb = Workbook()
- ws = wb.active
- ws.title = 'sheet1'
- ws.append(tableTitle)
- wb.save(filepath)
- time.sleep(3)
- wb = load_workbook(filepath)
- ws = wb.active
- ws.title = 'sheet1'
- ws.append(allinfo)
- wb.save(filepath)
- return True
- except:
- return False

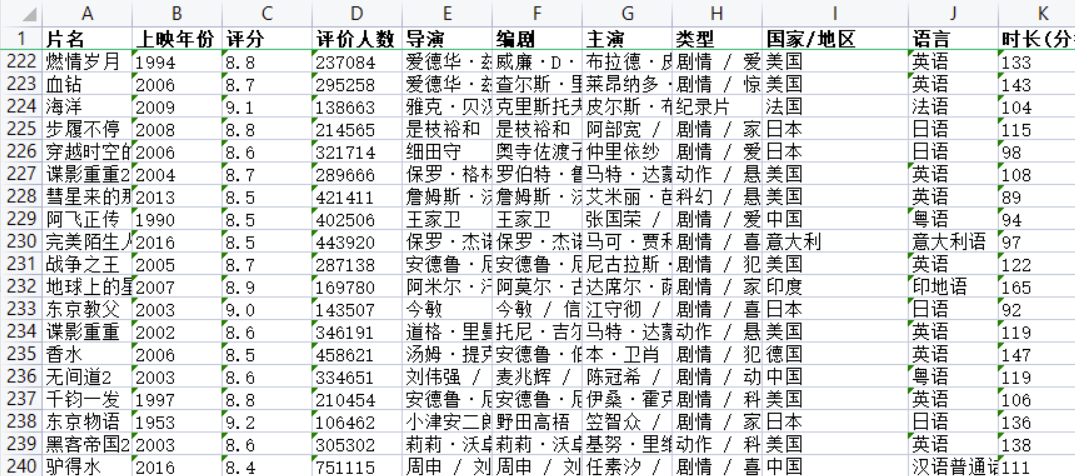
2. 数据可视化
2.1 导入以下模块
- import pandas as pd
- from pyecharts import options as opts
- from pyecharts.charts import Bar
2.2 用pandas模块读取数据
- data = pd.read_excel('/home/mw/input/TOP2508837/TOP250.xlsx')
- data.head(10)
2.3 各年份上映电影数量柱状图(纵向)
- def getzoombar(data):
- year_counts = data['上映年份'].value_counts()
- year_counts.columns = ['上映年份', '数量']
- year_counts = year_counts.sort_index()
- c = (
- Bar()
- .add_xaxis(list(year_counts.index))
- .add_yaxis('上映数量', year_counts.values.tolist())
- .set_global_opts(
- title_opts=opts.TitleOpts(title='各年份上映电影数量'),
- yaxis_opts=opts.AxisOpts(name='上映数量'),
- xaxis_opts=opts.AxisOpts(name='上映年份'),
- datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_='inside')],)
- )
2.4 各地区上映电影数量前十柱状图(横向)
- def getcountrybar(data):
- country_counts = data['国家/地区'].value_counts()
- country_counts.columns = ['国家/地区', '数量']
- country_counts = country_counts.sort_values(ascending=True)
- c = (
- Bar()
- .add_xaxis(list(country_counts.index)[-10:])
- .add_yaxis('地区上映数量', country_counts.values.tolist()[-10:])
- .reversal_axis()
- .set_global_opts(
- title_opts=opts.TitleOpts(title='地区上映电影数量'),
- yaxis_opts=opts.AxisOpts(name='国家/地区'),
- xaxis_opts=opts.AxisOpts(name='上映数量'),
- )
- .set_series_opts(label_opts=opts.LabelOpts(position="right"))
- )
-
2.5 电影评价人数前二十柱状图(横向)
- def getscorebar(data):
- df = data.sort_values(by='评价人数', ascending=True)
- c = (
- Bar()
- .add_xaxis(df['片名'].values.tolist()[-20:])
- .add_yaxis('评价人数', df['评价人数'].values.tolist()[-20:])
- .reversal_axis()
- .set_global_opts(
- title_opts=opts.TitleOpts(title='电影评价人数'),
- yaxis_opts=opts.AxisOpts(name='片名'),
- xaxis_opts=opts.AxisOpts(name='人数'),
- datazoom_opts=opts.DataZoomOpts(type_='inside'),
- )
- .set_series_opts(label_opts=opts.LabelOpts(position="right"))
- )
最后:如果你对Python感兴趣,想要学习Python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/空白诗007/article/detail/940206?site
推荐阅读
相关标签

