
- 1SAAS多租户系统的详细设计方案,后台数据库及各类框架详细设计方案-程序员必被的技术_多租户设计方案
- 2编码——ASCII、UTF-8等常见编码知识扫盲_辅助多语言平面(smp)
- 3C语言程序设计知识必备pdf,c语言程序设计复习知识总结.pdf
- 4Linux 的信号 signal_linux 发signal
- 5App弱网测试是怎么测试的!
- 6[轨迹规划实操] 横向优化算法+纵向DP算法的python复现(1)_轨迹规划 横向规划
- 7Transformers 研究指南
- 8git clone报错_git clone 命令报错
- 9iPhone手机蓝牙找不到AirPods耳机的解决方法_airpods蓝牙搜不到
- 10大数据最全Doris实战——结合Flink构建极速易用的实时数仓_flink doris,2024年最新大数据开发高级面试framework_fink基于doris实时数仓架构
微软亚洲研究院(MSRA)副院长周明:未来5-10年,NLP将走向成熟_周敏msra
赞
踩
近日,微软亚洲研究院(MSRA)副院长周明在「自然语言处理前沿技术分享会」上,与大家讲解了自然语言处理(NLP)的最新进展,以及未来的研究方向,以下内容由CSDN记者根据周明博士的演讲内容编写,略有删减。
周明博士于1999年加入微软亚洲研究院,不久开始负责自然语言研究组。近年来,周明博士领导研究团队与微软产品组合作开发了微软小冰(中国)、Rinna(日本)、Zo(美国)等聊天机器人系统。周明博士发表了120余篇重要会议和期刊论文(包括50篇以上的ACL文章),拥有国际发明专利40余项。
MSRA在机器翻译、中国文化、聊天机器人和阅读理解的最新进展
机器翻译
今年微软首先在语音翻译上全面采用了神经网络机器翻译,并拓展了新的翻译功能,我们叫做Microsoft Translator Live Feature(现场翻译功能),在演讲和开会时,实时自动在手机端或桌面端,把演讲者的话翻译成多种语言。
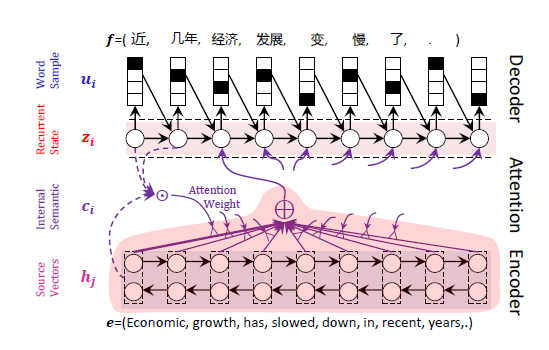
图1概括了神经网络机器翻译,简要的说,就是对源语言的句子进行编码,一般都是用长短时记忆(LSTM)进行编码。编码的结果就是有很多隐节点,每个隐节点代表从句首到当前词汇为止,与句子的语义信息。基于这些隐节点,通过一个注意力的模型来体现不同隐节点对于翻译目标词的作用。通过这样的一个模式对目标语言可以逐词进行生成,直到生成句尾。中间在某一阶段可能会有多个翻译,我们会保留最佳的翻译,从左到右持续。
这里最重要的技术是对于源语言的编码,还有体现不同词汇翻译的,不同作用的注意力模型。我们又持续做了一些工作,引入了语言知识。因为在编码的时候是仅把源语言和目标语言看成字符串,没有体会内在的词汇和词汇之间的修饰关系。我们把句法知识引入到神经网络编码、解码之中,这是传统的长短时记忆LSTM,这是模型,我们引入了句法,得到了更佳的翻译,这使大家看到的指标有了很大程度的提升。
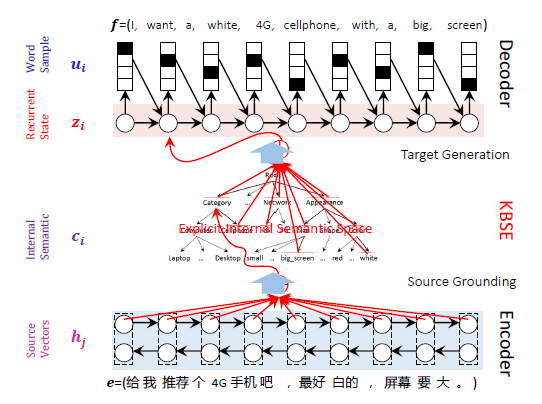
此外,我们还考虑到在很多领域是有知识图谱的,我们想把知识图谱纳入到传统的神经网络机器翻译当中,来规划语言理解的过程。我们的一个假设就是虽然大家的语言可能不一样,但是体现在知识图谱的领域上可能是一致的,就用知识图谱增强编码、解码。具体来讲,就是对于输入句子,先映射到知识图谱,然后再基于知识图谱增强解码过程,使得译文得到进一步改善。
以上两个工作都发表在本领域最重要的会议ACL上,得到很多学者的好评。

中国文化
大家会说,中国文化和人工智能有什么关系?中国文化最有代表性的是对联、诗歌、猜谜语等等,它怎么能够用人工智能体现呢?好多人一想这件事就觉得不靠谱,没法做。但是我们微软亚洲研究院就

