
- 1【github】github 获取 token 的网址_公开 github token 有哪些?
- 2Fairygui优化教程(一)分享向
- 3龙芯3A4000 Pmon启动信息_龙芯3a4000启动信息
- 4使用命令行修改Ubuntu 24.04的网络设置_ubuntu 24 netplan
- 51、opencv介绍与开发环境搭建
- 6使用conda安装gcc_your compiler (g++ 4.8.5) may be abi-incompatible
- 7PLSQL Developer连接oracle 报错ORA-12170: TNS:Connect timeout occurred解决办法
- 8【花雕学编程】Arduino BLDC 之基于深度学习的自主导航机器人控制
- 9Android实验 ContentProvider_contentprovider的应用实验
- 10binlog2mysql_MYSQL工具之binlog2sql闪回操作
中电信翼康济世数据中台基于Apache SeaTunnel构建数据集成平台经验分享
赞
踩

作者 | 中电信翼康工程师 代来
编辑 | Debra Chen
一. 引言
Apache SeaTunnel作为一个高性能、易用的数据集成框架,是快速落地数据集成平台的基石。本文将从数据中台战略背景、数据集成平台技术选型、降低Apache SeaTunnel使用门槛及未来展望几个方面,详细讲解我们是如何基于Apache SeaTunnel快速构建数据集成平台的。
二. 数据中台战略背景
随着医疗行业对数据驱动决策的需求不断增加,挖掘医疗数据要素价值,激发新质生产力潜能机遇迫在眉睫。中电信翼康通过自研的“数据中台”开展医疗健康数据要素全流程管理和一站式赋能,打造医疗健康数据要素运营底座,助力医疗数据的价值挖掘与AI模型应用。在此战略背景下,数据集成平台作为我们数据中台的“大动脉”,需要能够快速落地且能够满足中台复杂的数据集成场景需求。
三. 数据集成平台技术选型
3.1. 关键考虑因素
在对数据集成平台底层进行技术选型时,需要考虑以下几个关键因素:
- 性能:数据集成引擎需要具备高吞吐量和低延迟,能够高效处理海量数据。
- 扩展性:数据集成引擎应具有良好的扩展性,能够根据业务需求动态扩展处理能力。
- 易用性:数据集成平台应易于使用和维护,减少对专业技术人员的依赖。
- 生态支持:数据集成引擎应支持多种数据源和目标,具备良好的生态系统支持。
3.2. 选择Apache SeaTunnel的优势
目前,市场上主流的数据集成技术主有Sqoop、Datax、Kettle、Flink CDC、Canal、Airbyte等。Apache SeaTunnel具备以下优势,使其成为我们数据集成平台的理想选择:
性能
根据官方最新公布的数据来看,Apache SeaTunnel在相同测试场景下比Datax快40%-80%,比Airbyte快30倍,其具有无与伦比的性能优势。我们也在客户现场亲测了一下,8C32G服务器上做同数据库上jdbc-source到jdbc-sink的性能测试,我们的数据集成平台的速率平均比第三方平台快近两万条每秒。优秀的性能源自于SeaTunnel优秀的设计,以JDBC连接器为例,SeaTunnel使用了数据库连接复用、动态分片、而SeaTunnel的zeta引擎更是实现了动态线程共享技术。在完成数据同步的同时尽量减少资源的使用,提高效率。
部署方式
在我们的客户场景中,大多数的医院只能提供前端采集节点的物理机给我们部署采集服务,而平台是部署在中心端的,只有采集端到医院数据库网络是通的,中心端到前端采集节点网络是通的,不能夸端通信。只有少数客户所有的服务可以部署在一套环境中。这就要求我们的部署必须是非常灵活的。SeaTunnel既支持分布式部署也支持单机部署,其无中心化的设计确保系统的高可用机制和易扩展。其可让每个节点可以既是Master也可以同时是Worker,也可以让Master和Worker分开部署。前者适合中小规模部署,后者适合超大规模部署。
容错
SeaTunnel的容错也是非常优秀的。
从集群角度看,当集群某一节点宕机,其任务可以自动容错到其他集群节点。当我们开启集群的IMAP持久化之后,即使集群节点全部宕机,也可以通过持久化的数据在重启集群时自动恢复。这里需要注意的是当集群第一个节点启动后会加载持久化的IMAP数据,因此集群节点之间启动时间差不宜太长,否则可能会造成所有任务都打到第一个启动的节点上去。
从作业的角度看,SeaTunnel也拥有checkpoint机制,当作业因意外突然异常时,也能从checkpoint恢复从而保证昂贵的数据同步任务不用重新同步。此外,由于网络延迟、节点故障等原因,分布式系统中的数据可能具有一致性问题,SeaTunnel在相关连接器中也实现了二阶段提交,能够保证数据的一致性。
丰富生态
SeaTunnel已经支持100+种数据源,并且易于扩展和支持自己的生态。其支持整库同步、多表同步、断点续传。更支持自动建表,这种功能体现出SeaTunnel设计的用心,这个功能在平台侧易实现且于用户而言是非常友好的功能,这在同步的表非常多的时候尤其能体现出其优势。
集成引擎架构
SeaTunnel的EtLT的架构非常适合数据中台的场景,在数据中台场景中,90%的场景都是将数据从源端搬运到目标端,其中可能包含转换(Transform),但这个T是一个小写的t,其主要包括复制列、过滤列、切分字段等转换而不是join或者group by之类的操作。这在数据中台中非常常见,当数据进入数仓平台之后在数据开发阶段才有大T的需求。此外EtLT的设计可谓是ETL的升级版,在很多场景下其数据同步的速率是远远高于ETL架构的。
平台架构
如果我们不选择SeaTunnel作为数据集成引擎,那么我们的平台架构可能就是这样子:
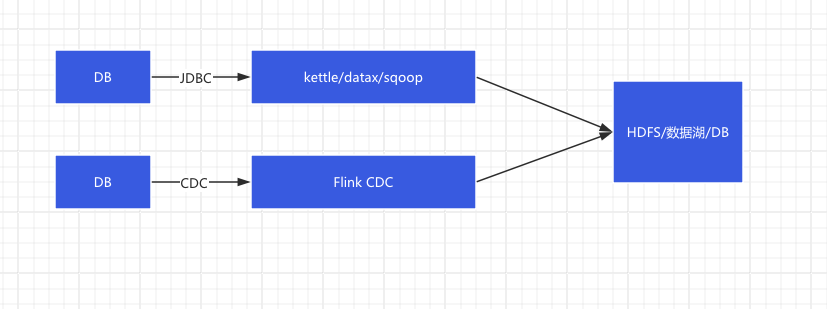
这种架构的劣势就是,使用多数据集成引擎,维护成本高昂,另外其还需要flink的执行环境来完成实时同步任务。从快速落地数据集成平台角度来看不是很友好,需要深入研究多数据集成引擎。当我们采用Seatunnel,则数据集成平台的架构可以优化成下面这样子:
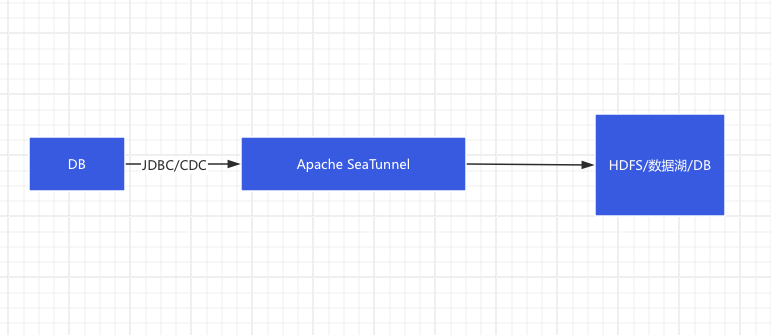
我们只需要研究Apache seatunnel,并基于此快速落地数据集成平台,如果有不满足需求的也可以基于其二次开发,开发运维成本都相对前者低很多。
四. 如何降低Apache SeaTunnel使用门槛
1. 友好的功能界面
为了降低使用门槛,可以提供一个可视化的配置界面,使用户通过图形化界面来配置数据集成任务,而无需编写复杂的配置文件。
批流一体的任务创建
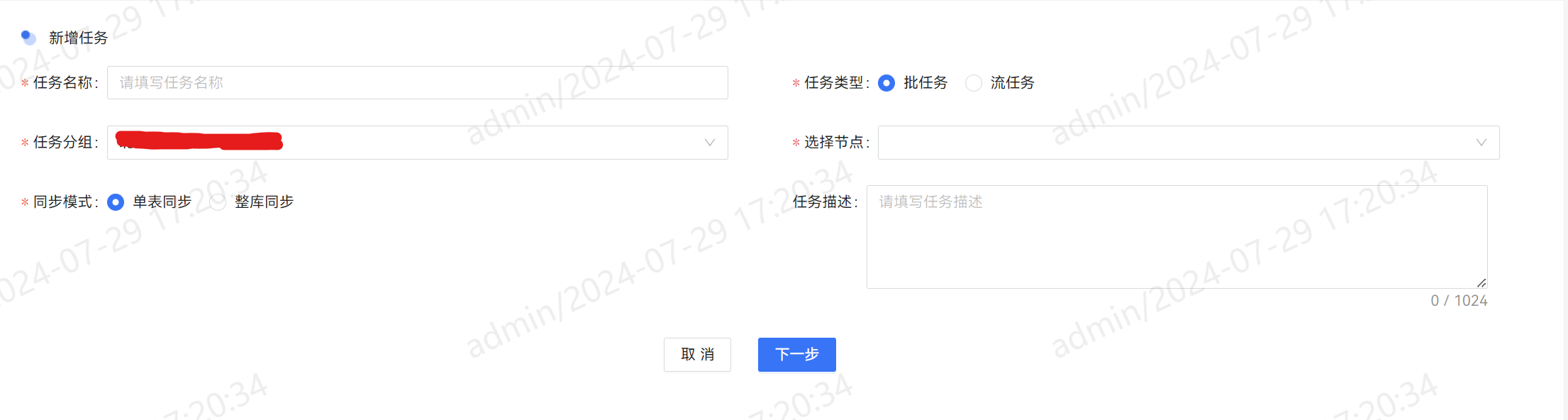
选择数据源进行配置,支持参数配置(可选)
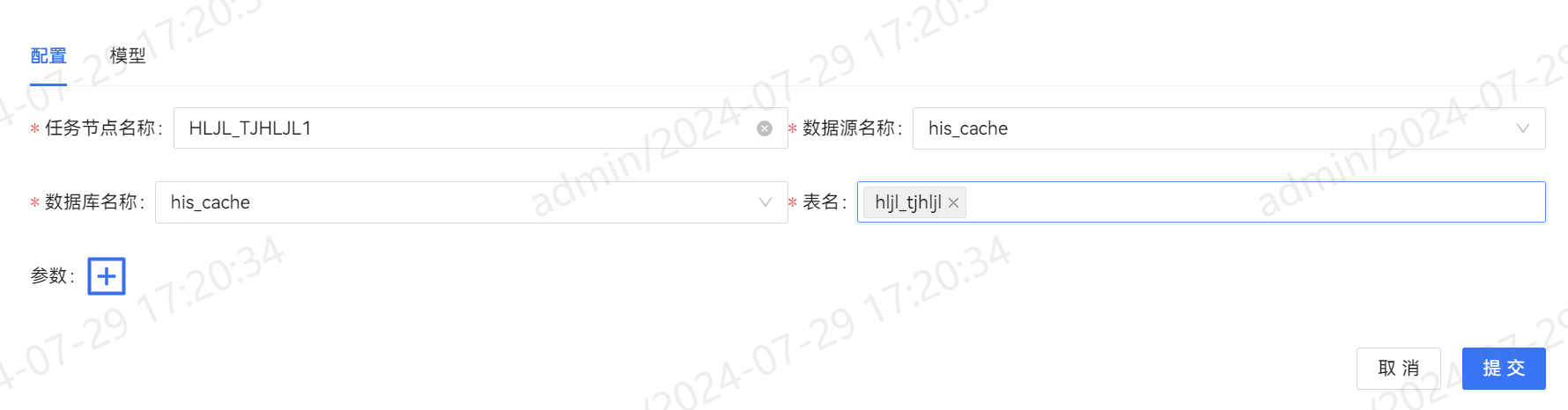
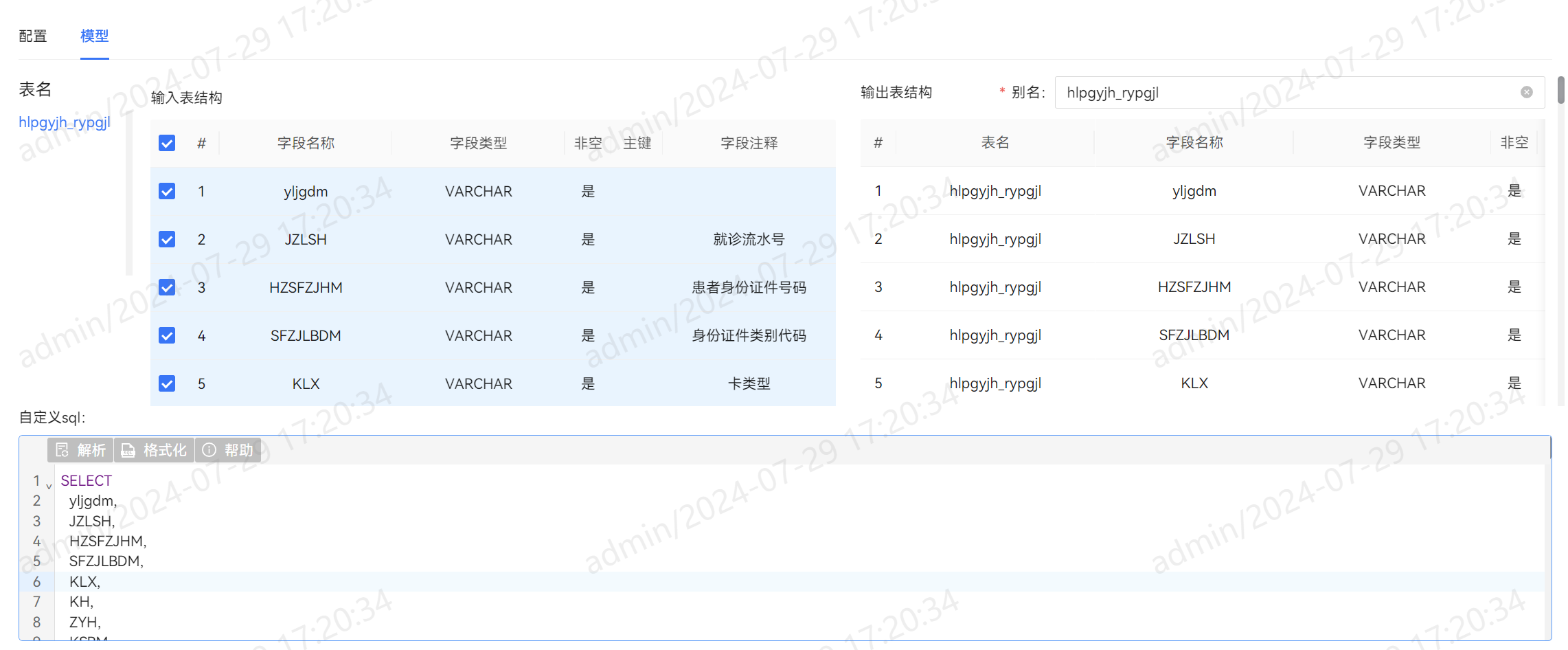
同步任务配置映射关系,可以灵活的调整字段顺序并且支持自定义字段值,增加缺省字段,删除多余字段。

针对复杂sql进行数据关联查询
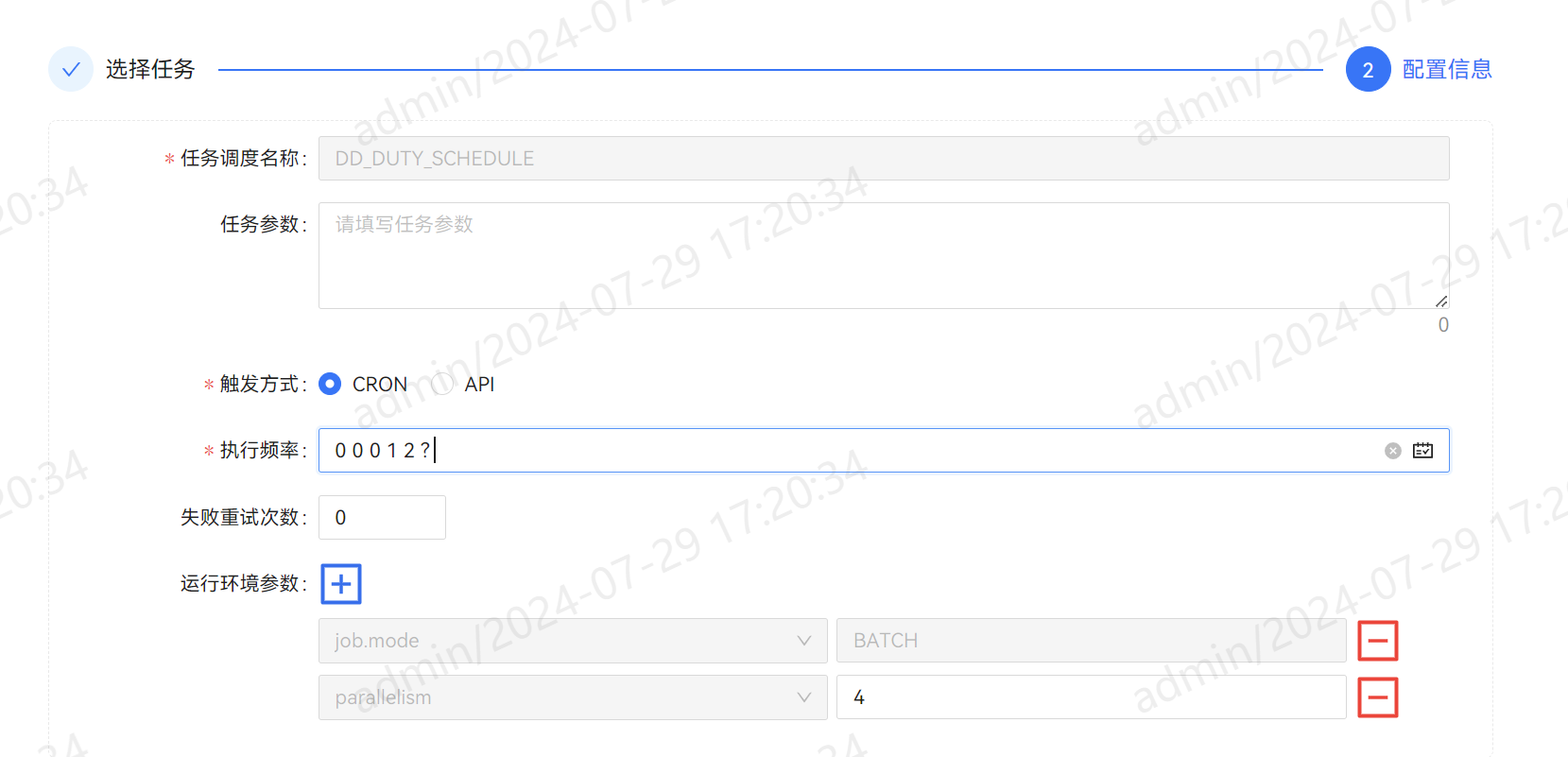
支持批任务周期性调度方式以满足定时全量或增量同步
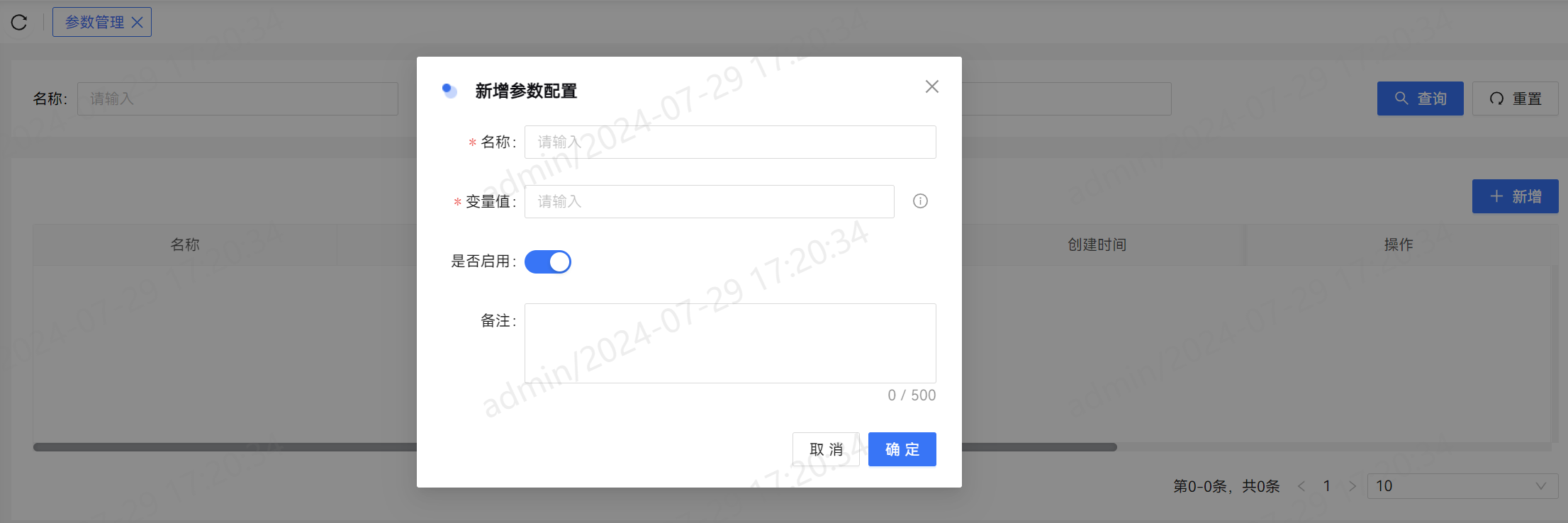
支持全局参数设置
以上为我们产品功能的一些样例截图,整个产品的功能远不止如此,通过这些样例抛砖引玉,帮助用户如何快速落地数据集成平台起到一个引导作用。
2. 提供丰富的文档和示例
优秀的数据集成平台当然少不了丰富和优秀的文档,通过提供详细的使用文档和丰富的示例代码,帮助用户快速上手。包括如何安装、配置和调试,以及常见问题的解决方案。
主要文档包括环境要求、项目配置、配置文件详解、运行测试、常见问题解决方案等,以常见问题解决方案为例:
常见问题解决方案
数据源连接问题:
确保数据源地址、端口和认证信息正确无误。 检查网络连接和防火墙设置。
数据转换错误:
检查转换规则是否正确。 确保所有字段和类型都匹配。
性能问题:
调整Connector参数和其他配置以提高性能。 优化数据转换逻辑。
插件问题:
确保所有必要的插件都已安装并正确配置。 检查插件的版本兼容性。
3. 集成自动化部署工具
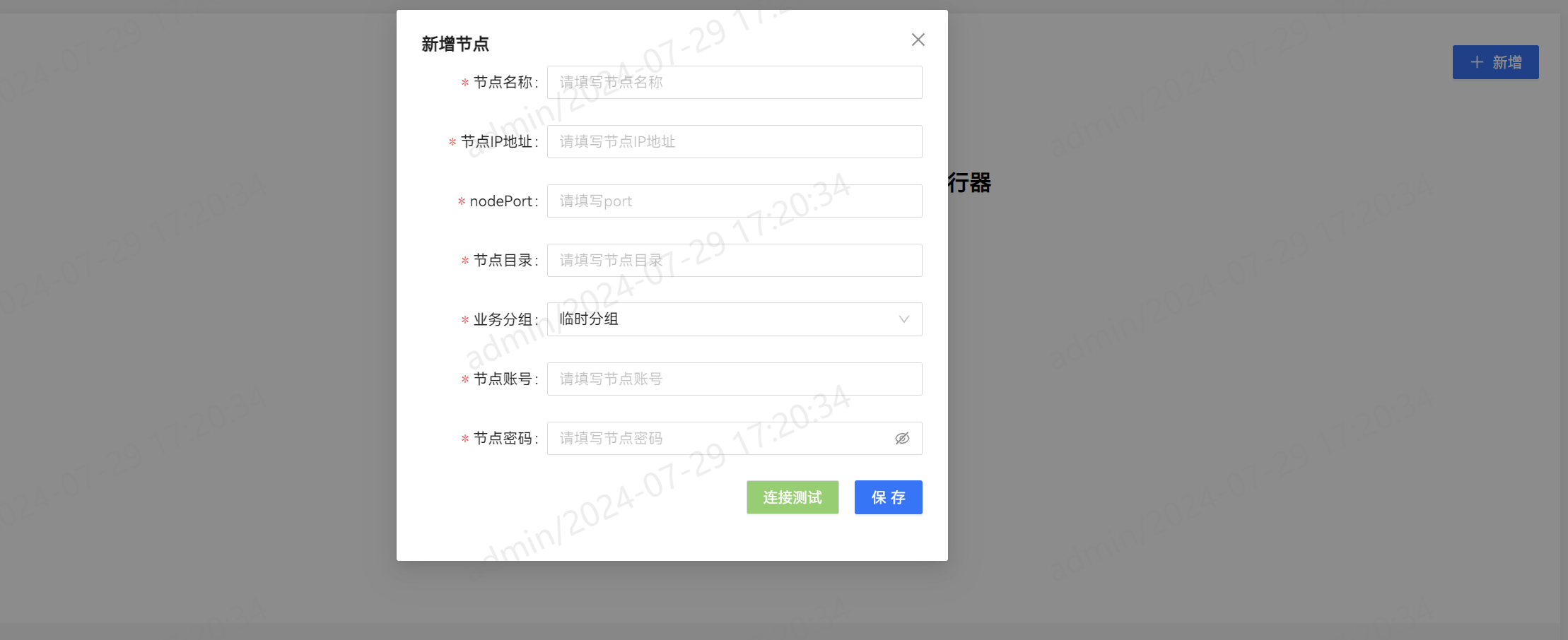
SeaTunnel的自动化部署和管理,进一步降低使用和维护的难度。实现了这种根据服务器地址信息一键部署sSeaTunnel服务的功能。
下面是实现了对于部署的seatunnel服务进行实时监控
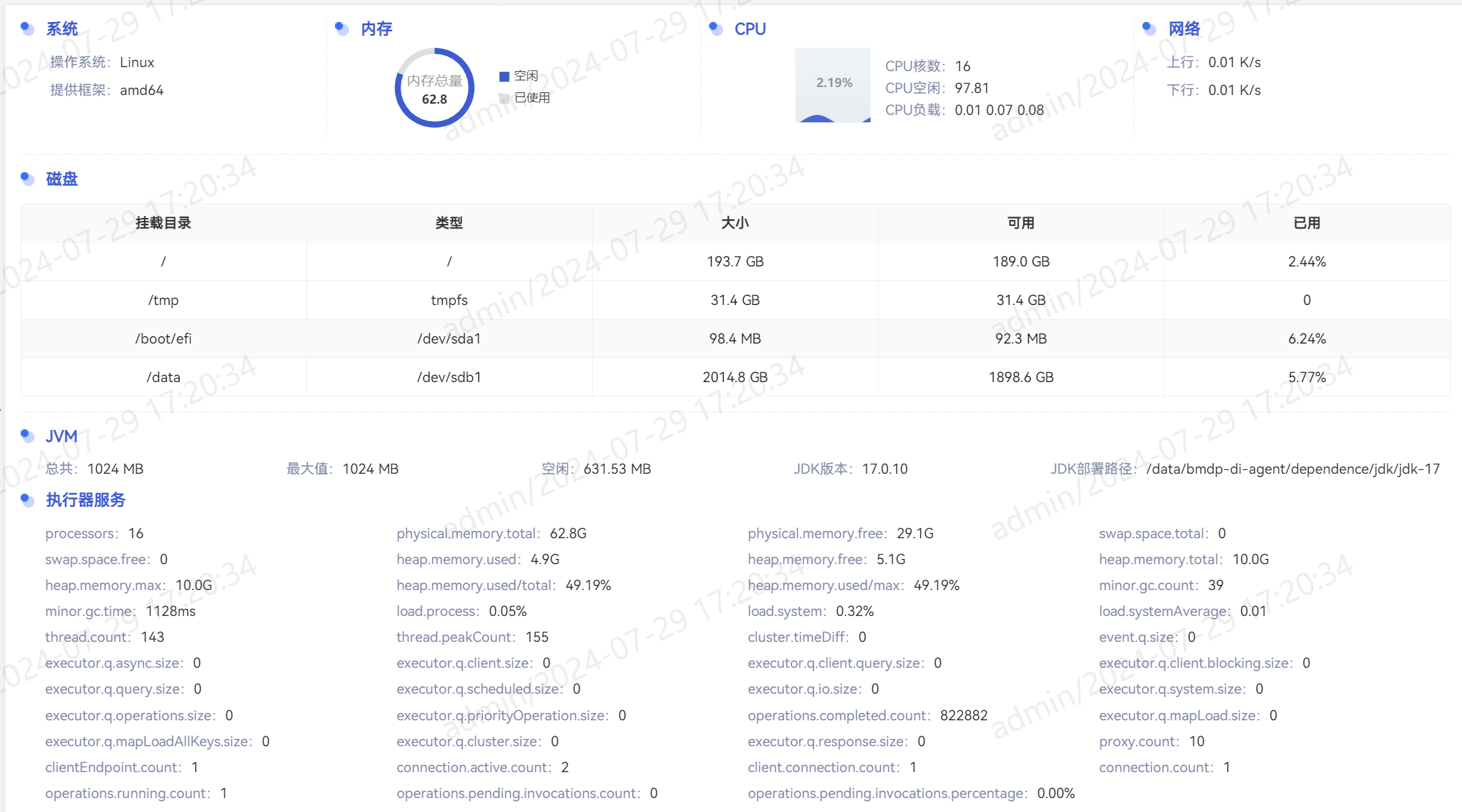
4. 社区支持
在整个数据集成平台的开发及实施过程中,难免会遇到一些问题,有的问题社区已经有一部分经验了,例如SeaTunnel集群的容错和恢复等功能,社区都能积极的给予回答和帮助。此外,有些功能不能满足我们的实际业务需求,例如在湖仓一体的数据中台架构中,我们使用的Apache paimon作为数据湖,但社区的Paimon connector尚不能完全满足我们的业务需求,我们先后针对Paimon connector进行了BUG修复及增加了很多新Feature
- 支持cdc写paimon
- 支持paimon sink自动建表,自动建表支持指定partition key、primary key并且支持指定多分桶(大数据量写场景下可提高写入性能)
- 支持paimon的多表sink
- 支持指定格式写paimon(默认是orc,可指定parquet、avro格式)
- 解决date字段写入不正确的问题、支持timestmap(n)类型
- 支持kerberos认证及HA模式hdfs集群
- 支持Hive catalog
- 支持写入Sink表前前置类型转换校验
- 修复批写数据丢失问题
以上只是对社区贡献的缩影,我们对社区的贡献不止于此,既然选择了Apache SeaTunnel作为数据集成引擎,享受了社区带来的益处,当然作为回报我们也应该积极的贡献社区、反馈社区让大家一起越来越优秀。
五. 未来与展望
随着医疗行业对大数据的需求不断增长,Seatunnel 作为一种高效、灵活的数据集成工具,将在医疗信息化建设中发挥重要作用,特别是在数据集成和处理方面。随着医疗行业对数据驱动决策的需求不断增加,Seatunnel 的功能和特性能够很好地满足医疗大数据平台的需求。以下是 Seatunnel 在医疗行业的一些展望:
1. 多数据源集成
集成医院的电子病历系统、影像信息系统(PACS)、实验室信息系统(LIS)等,实现跨系统的数据共享。
2. 数据标准
支持HL7 FHIR(Fast Healthcare Interoperability Resources)等医疗行业标准,提高数据的标准化和互操作性。
3. 安全性和隐私保护
数据加密:采用加密技术保护数据安全,尤其是在传输过程中。
匿名化和脱敏:实现数据的匿名化和脱敏处理,保护患者隐私。
4. AI与机器学习集成
数据集成平台将引入更多的智能化特性,如智能推荐配置等,帮助用户更高效地进行数据集成和处理。
六. 总结
Apache SeaTunnel作为一个高效、灵活的数据集成平台,在数据中台战略中扮演着重要角色。通过本文的介绍,读者可以了解如何基于SeaTunnel快速搭建数据集成平台,并在实际应用中灵活运用。未来,随着技术的不断发展,SeaTunnel将继续在数据集成领域发挥重要作用,助力企业实现数据驱动的业务变革。
本文由 白鲸开源科技 提供发布支持!

