
- 1如何在浏览器Web前端在线编辑PPT幻灯片?_前端实现可编辑 ppt
- 2IDEA如何回退提交的git代码_idea git撤回提交
- 3电脑安全模式怎么进?3种方式教会你!_电脑网络安全模式
- 4智能合约漏洞之整型溢出_erc20智能合约整数溢出怎么解决
- 5CDH集成Kerberos配置_cdh 的keytab 在哪里
- 6LRU、LFU_lfu、lru
- 7【Stable Diffusion】ComfyUI提示词预设插件(附插件)_comfyui风格提示词选择器
- 8Python--pandas导入导出数据_pandas将含有nan数据的行导出
- 9学习笔记——交通安全分析17
- 10Android-13-BroadcastReceiver(广播接收者)_android 13 broadcastreceiver
【数据结构(邓俊辉)学习笔记】图03——拓扑排序
赞
踩
0. 概述
学习下拓扑排序
1. 零入度算法
1. 1 拓扑排序
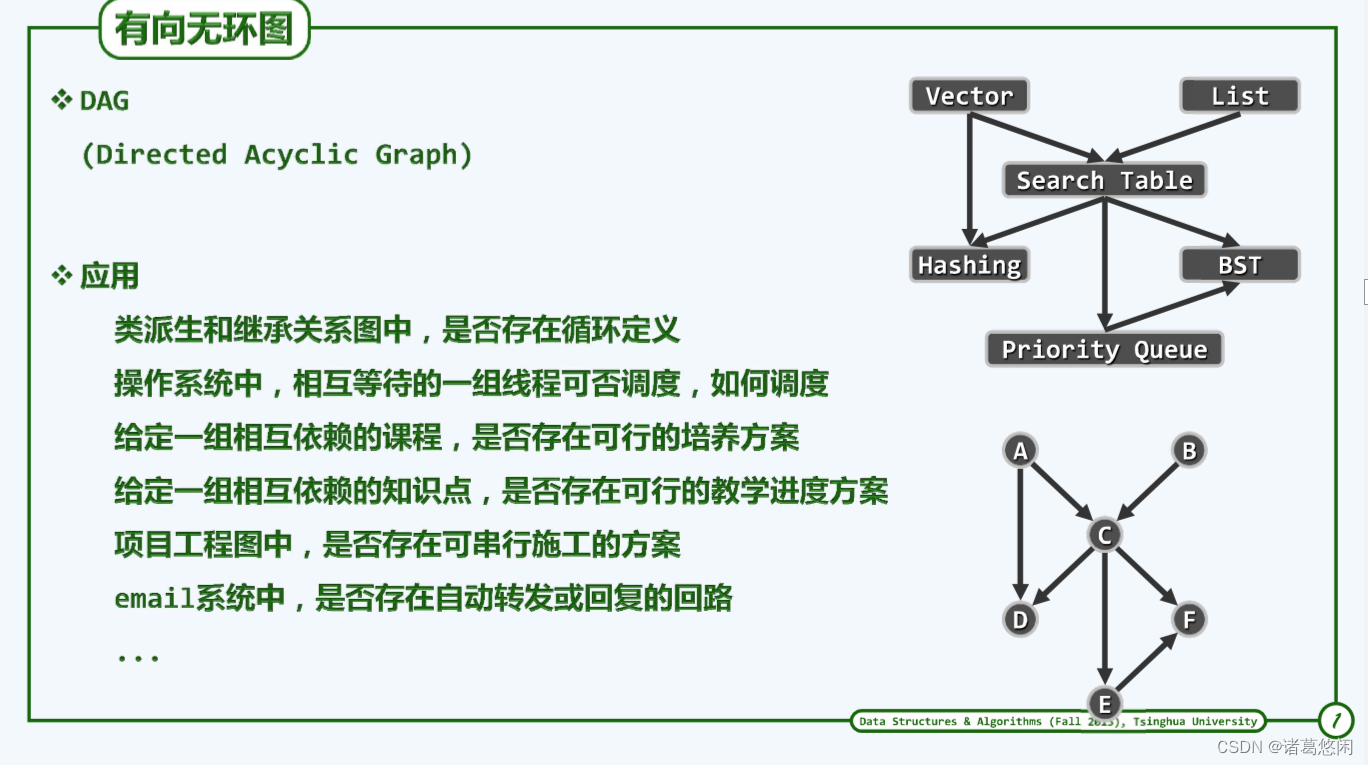
首先理解下拓扑排序
其实老师经常干这事,如编讲义,将已经知道的知识点串起来变成讲课序列。那怎么串起来呢?将知识点列出,将它们之间的相互关系描述下。要讲priority queue那上一讲需要讲什么内容,要讲hashing需要讲哪些内容,需要罗列出来。但是讲课不可能像分支一样平行一分为二裂开,最终都会变成下面这样平坦的线性序列。

(续)一个好的安排是什么呢?每当讲到一个知识点时,它所依赖的知识点都应该在此前依然讲过,这样就会变成一个线性序列。将原来图中所有的点整理成这样一个线性次序,前面点与后面点的边次序都是前指向后,没有后指向前,这就是对原图的拓扑排序。
1. 2 算法
- 如果真有这么一个图,怎么排呢?

因为这个图有依赖关系,所以是不折不扣的有向图,但有意思的是这里不能有环,如果有环路就有问题。

首先需要找到零入度的点——无任何依赖,在dag图中必然有这么一个点,由于DAG子图亦为DAG,于是可以利用减而治之思想,将这个零入度的点抹掉,接着找下一个零入度点。
- 那么这个算法如何实现?

图中已经有零入度的点A或B,任取一个,这里取A,放入队列中,等价将A点及其边从图中删除。由于DAG的子图亦是DAG,所以还会有零入度的点,将B点放入队列中,然后依次类推,当所有的点都放入队列后,队列中的节点顺序就是拓扑排序。
但这个方法并不好,实现起来比较麻烦,需要每次去找那个零入度的点,而且删除点及其边的时候还要更新相应信息,可能会对图产生伤害,那怎么做呢?看下下面的零出度算法
2. 零出度算法
2.1 算法
说服下自己,DAG既有零入度点也有零出度点,这个很重要,为什么这么讲,因为之前的DFS(深度优先搜索)可以帮我们实现这个方法。
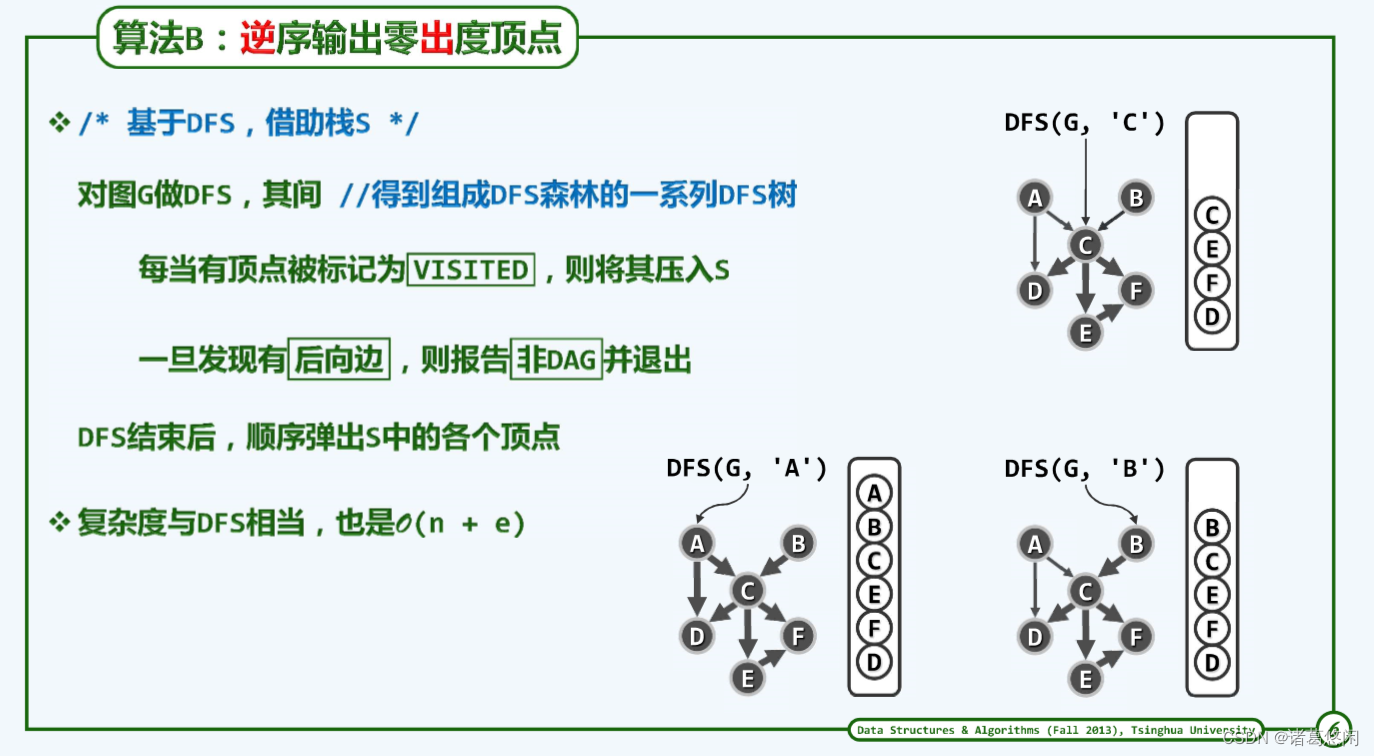
这样要做的事就比较简单,不需要零入度算法那这样改改度数等等。之前已经造出DFS算法,这样就可以搭DFS便车实现零出度算法。
如何实现呢?
2.2 实现

这里引入一个栈,排序结果将以逆序打印出来。随便找一个点,这里首先访问顶点V,将顶点V状态初始值设置为DISCOVERED,接着枚举V的所有邻居,视u的状态,分别处理,后续会做分析。访问所有邻居后,将顶点V的状态设置为VISITED,然后顶点V入栈。
接着还有顶点V的邻居处理方法还未做交代,怎么处理呢?

- 若顶点U的状态为UNDISCOVERED,更新顶点U的父亲为V,边的状态为TREE,作递归调用,从顶点u处深入。
- 顶点U的状态为DISCOVERED,一旦发现后向边,即图非DAG图,无拓扑排序,则退出而不再深入。
- 顶点U的状态为VISITED,更新下顶点状态。
2.3. 复杂度
这里仅额外引入的栈,规模不超过顶点总数O(n)。总体而言,空间复杂度与基本的深度优先搜索算法同样,仍为O(n + e)。该算法的递归跟踪过程与标准DFS搜索完全一致,且各递归实例自身的执行时间依然保持为O(1),故总体运行时间仍为O(n + e)。

