
- 1千兆网数据接收(一)_tcp和udp都可以用在千兆网卡上吗
- 2【浏览器系列】从输入网址(URL)到页面加载的全过程_浏览器输入url到页面加载全过程
- 3如何对比两个数据库中的结构、表数量、字段数量等是否一致的问题_如何对比两个数据库的一致性
- 41.2UiPath第一个案例HelloWorld_uipath 使用案例
- 5flink on k8s模式通过web UI界面查看任务运行情况_.通过 flink 的 web ui 来监视集群的状态和正在运行的作业(本地地址:localhost
- 6Go最全ffmpeg学习——音频源_nb_samples(1),轻松拿到了阿里Golang高级开发工程师的offer_使用ffmpeg生成一个有声音的白噪声mp3音频
- 7【Postman】Postman 接口测试工具详解 - 发送HTTP请求3_在线postman请求数据
- 8IDEA中实体类(POJO)与JSON快速互转_pojo to json
- 9@autowired注入失败_Spring依赖注入和自动注入
- 10《Google SRE工作手册》第5期(总46期)读书分享 (视频+文字版)
RocketMQ 是什么?它的架构是怎样的?和 Kafka 有什么区别?
赞
踩
RocketMQ 是什么?
RocketMQ 是阿里自研的国产消息队列,目前已经是 Apache 的顶级项目。和其他消息队列一样,它接受来自生产者的消息,将消息分类,每一类是一个 topic,消费者根据需要订阅 topic,获取里面的消息。

RocketMQ 的架构是怎么样的?
RocketMQ主要由Producer、Broker和Consumer三部分组成,如下图所示:

- Producer:消息生产者,负责将消息发送到 Broker.
- Broker:消息中转服务器,负责存储和转发消息。RocketMQ 支持多个 Broker 构成集群,每个 Broker 都拥有独立的存储空间和消息队列。
- Consumer:消息消费者,负责从 Broker 消费消息
- NameServer:名称服务,负责维护 Broker 的元数据信息,包括 Broker 地址、Topic 和 Queue 等信息Producer 和 Consumer 在启动时需要连接到 NameServer 获取 Broker 的地址信息。
- Topic:消息主题,是消息的逻辑分类单位。Producer 将消息发送到特定的 Topic 中,Consumer 从指定的Topic 中消费消息
- Message Queue:4:消息队列,是 Topic 的物理实现。一个Topic可以有多个 Queue ,每个 Queue 都是独立的存储单元。Producer 发送的消息会被存储到对应的 Queue 中,Consumer 从指定的 Queue 中消费消息
RocketMQ 和 Kafka 的区别?
RocketMQ 的架构其实参考了 Kafka 的设计思想,同时又在 Kafka 的基础上做了一些调整。
这些调整,用一句话总结就是,“和 Kafka 相比,RocketMQ 在架构上做了减法,在功能上做了加法”。
架构上做了减法
简化协调节点
Zookeeper 在 Kafka 架构中会和 broker 通信,维护 Kafka 集群信息。一个新的 broker 连上 Zookeeper 后,其他 broker 就能立马感知到它的加入,像这种能在分布式环境下,让多个实例同时获取到同一份信息的服务,就是所谓的分布式协调服务。
但 Zookeeper 作为一个通用的分布式协调服务,它不仅可以用于服务注册与发现,还可以用于分布式锁、配置管理等场景。Kafka 其实只用到了它的部分功能,用 Zookeeper 太重了。
所以 RocketMQ 去掉了 Zookeeper,引入 NameServer 用一种更轻量的方式,管理消息队列的集群信息。生产者通过 NameServer 获取到 topic 和 broker 的路由信息,然后再与 broker 通信,实现服务发现和负载均衡的效果。
Kafka 从 2.8.0 版本就支持将 Zookeeper 移除,通过在 broker 之间加入一致性算法 raft 实现同样的效果,这就是所谓的 KRaft 或 Quorum 模式。
简化分区
Kafka 会将 topic 拆分为多个 partition,用来提升并发性能。
在 RocketMQ 里也一样,将 topic 拆分成了多个分区,但换了个名字,叫 Queue,也就是"队列"。
Kafka 中的 partition 会存储完整的消息体,而 RocketMQ 的 Queue 上却只存一些简要信息,比如消息偏移 offset,而消息的完整数据则放到"一个"叫 commitlog 的文件上,通过 offset 我们可以定位到 commitlog 上的某条消息。
Kafka 消费消息,broker 只需要直接从 partition 读取消息返回就好,也就是读第一次就够了。
而在 RocketMQ 中,broker 则需要先从 Queue 上读取到 offset 的值,再跑到 commitlog 上将完整数据读出来,也就是需要读两次。
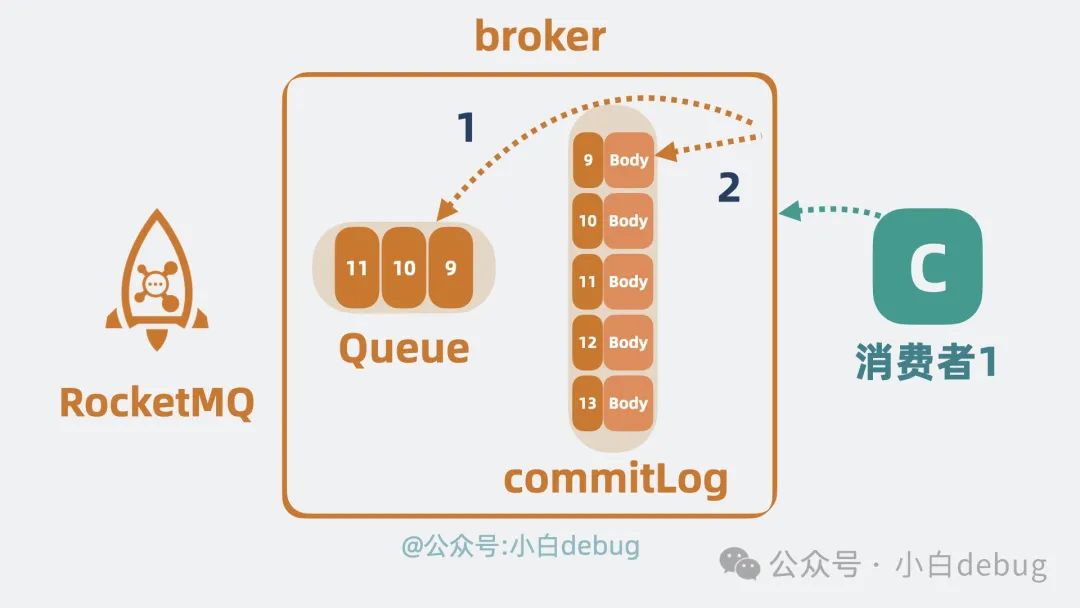
看起来 Kafka 的设计更高效?为什么 RocketMQ 不采用 Kafka 的设计?这就跟底层存储有关了
底层存储
Kafka 的 partition 分区,其实在底层由很多段(segment)组成,每个 segment 可以认为就是个小文件。将消息数据写入到 partition 分区,本质上就是将数据写入到某个 segment 文件下。
Kafka 同时写多个 topic 底下的 partition 就会越多, segment 也会越多,等同于同时写多个文件**,虽然每个文件内部都是顺序写,但多个文件存放在磁盘的不同地方,原本顺序写磁盘就可能劣化变成了随机写**。于是写性能就降低了。
为了缓解同时写多个文件带来的随机写问题,RocketMQ 索性将单个 broker 底下的多个 topic 数据,全都写到"一个"逻辑文件 CommitLog 上,这就消除了随机写多文件的问题,将所有写操作都变成了顺序写。大大提升了 RocketMQ 在多 topic 场景下的写性能。
CommitLog 逻辑上是一个大文件,实际是由多个固定大小的小文件构成,写慢一个小文件,就会创建一个新的来写。
简化备份模型
Kafka 会将 partiton 分散到多个 broker 中,并为 partiton 配置副本,将 partiton 分为 leader和 follower,也就是主和从。
RocketMQ 将 broker 上的所有 topic 数据到写到 CommitLog 上。如果还像 Kafka 那样给每个分区单独建立同步通信,就还得将 CommitLog 里的内容拆开,这就还是退化为随机读了。
于是 RocketMQ 索性以 broker 为单位区分主从,主从之间同步 CommitLog 文件,保持高可用的同时,也大大简化了备份模型。
功能上做了加法
消息过滤
我们知道,Kafka 支持通过 topic 将数据进行分类,比如订单数据和用户数据是两个不同的 topic,但如果我还想再进一步分类呢?比如同样是用户数据,还能根据 vip 等级进一步分类。假设我们只需要获取 vip6 的用户数据,在 Kafka 里,消费者需要消费 topic 为用户数据的所有消息,再将 vip6 的用户过滤出来。
而 RocketMQ 支持对消息打上标记,也就是打 tag,消费者能根据 tag 过滤所需要的数据。比如我们可以在部分消息上标记 tag=vip6,这样消费者就能只获取这部分数据,省下了消费者过滤数据时的资源消耗。
相当于 RocketMQ 除了支持通过 topic 进行一级分类,还支持通过 tag 进行二级分类。
支持事务
Kafka 也支持事务,比如生产者发三条消息 ABC,这三条消息要么同时发送成功,要么同时发送失败。
但是,写业务代码的时候,我们更想要的事务是,"执行一些自定义逻辑"和"生产者发消息"这两件事,要么同时成功,要么同时失败。
而这正是 RocketMQ 支持的事务能力。
加入延时队列
如果我们希望消息投递出去之后,消费者不能立马消费到,而是过个一定时间后才消费,也就是所谓的延时消息,就像文章开头的定时外卖那样。如果我们使用 Kafka, 要实现类似的功能的话,就会很费劲。
但 RocketMQ 天然支持延时队列,我们可以很方便实现这一功能。
加入死信队列
消费消息是有可能失败的,失败后一般可以设置重试。如果多次重试失败,RocketMQ 会将消息放到一个专门的队列,方便我们后面单独处理。这种专门存放失败消息的队列,就是死信队列。
Kafka 原生不支持这个功能,需要我们自己实现。
消息回溯
Kafka 支持通过调整 offset 来让消费者从某个地方开始消费,而 RocketMQ,除了可以调整 offset, 还支持调整时间( kafka 在0.10.1后支持调时间)

