图像识别训练样本集
ImageNet
ImageNet是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库。是美国斯坦福的计算机科学家李飞飞模拟人类的识别系统建立的。能够从图片识别物体。目前已经包含14197122张图像,是已知的最大的图像数据库。每年的ImageNet大赛更是魂萦梦牵着国内外各个名校和大型IT公司以及网络巨头的心。图像如下图所示,需要注册ImageNet帐号才可以下载,下载链接为http://www.image-net.org/

PASCAL VOC
PASCALVOC 数据集是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。图像如下图所示,包含VOC2007(430M),VOC2012(1.9G)两个下载版本。下载链接为http://pjreddie.com/projects/pascal-voc-dataset-mirror/

Labelme
Labelme是斯坦福一个学生的母亲利用休息时间帮儿子做的标注,后来便发展为一个数据集。该数据集的主要特点包括
(2)专门为学习嵌入在一个场景中的对象而设计
(3)高质量的像素级别标注,包括多边形框(polygons)和背景标注(segmentation masks)
(4)物体类别多样性大,每种物体的差异性,多样性也大。
(5)所有图像都是自己通过相机拍摄,而非copy
(6)公开的,免费的
图像如下图所示,需要通过matlab来下载,一种奇特的下载方式,下载链接为http://labelme2.csail.mit.edu/Release3.0/index.php
COCO
COCO是一种新的图像识别,分割和加字幕标注的数据集。主要由Tsung-Yi Lin(Cornell Tech),Genevieve Patterson (Brown),MatteoRuggero Ronchi (Caltech),Yin Cui (Cornell Tech),Michael Maire (TTI Chicago),Serge Belongie (Cornell Tech),Lubomir Bourdev (UC Berkeley),Ross Girshick (Facebook AI), James Hays (Georgia Tech),PietroPerona (Caltech),Deva Ramanan (CMU),Larry Zitnick (Facebook AI), Piotr Dollár (Facebook AI)等人收集而成。其主要特征如下
(2)通过上下文进行识别
(3)每个图像包含多个目标对象
(4)超过300000个图像
(5)超过2000000个实例
(6)80种对象
(7)每个图像包含5个字幕
(8)包含100000个人的关键点
图像如下图所示,支持Matlab和Python两种下载方式,下载链接为http://mscoco.org/
SUN
SUN数据集包含131067个图像,由908个场景类别和4479个物体类别组成,其中背景标注的物体有313884个。图像如下图所示,下载链接为http://groups.csail.mit.edu/vision/SUN/
Caltech
Caltech是加州理工学院的图像数据库,包含Caltech101和Caltech256两个数据集。该数据集是由Fei-FeiLi, Marco Andreetto, Marc 'Aurelio Ranzato在2003年9月收集而成的。Caltech101包含101种类别的物体,每种类别大约40到800个图像,大部分的类别有大约50个图像。Caltech256包含256种类别的物体,大约30607张图像。图像如下图所示,下载链接为http://www.vision.caltech.edu/Image_Datasets/Caltech101/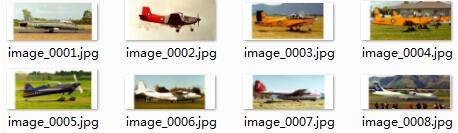
Corel5k
这是Corel5K图像集,共包含科雷尔(Corel)公司收集整理的5000幅图片,故名:Corel5K,可以用于科学图像实验:分类、检索等。Corel5k数据集是图像实验的事实标准数据集。请勿用于商业用途。私底下学习交流使用。Corel图像库涵盖多个主题,由若干个CD组成,每个CD包含100张大小相等的图像,可以转换成多种格式。每张CD代表一个语义主题,例如有公共汽车、恐龙、海滩等。Corel5k自从被提出用于图像标注实验后,已经成为图像实验的标准数据集,被广泛应用于标注算法性能的比较。Corel5k由50张CD组成,包含50个语义主题。
Corel5k图像库通常被分成三个部分:4000张图像作为训练集,500张图像作为验证集用来估计模型参数,其余500张作为测试集评价算法性能。使用验证集寻找到最优模型参数后4000张训练集和500张验证集混合起来组成新的训练集。
该图像库中的每张图片被标注1~5个标注词,训练集中总共有374个标注词,在测试集中总共使用了263个标注词。图像如下图所示,很遗憾本人也未找到官方下载路径,于是github上传了一份,下载链接为https://github.com/watersink/Corel5K

CIFAR(Canada Institude For Advanced Research)
CIFAR是由加拿大先进技术研究院的AlexKrizhevsky, Vinod Nair和Geoffrey Hinton收集而成的80百万小图片数据集。包含CIFAR-10和CIFAR-100两个数据集。 Cifar-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类。CIFAR-100由60000张图像构成,包含100个类别,每个类别600张图像,其中500张用于训练,100张用于测试。其中这100个类别又组成了20个大的类别,每个图像包含小类别和大类别两个标签。官网提供了Matlab,C,Python三个版本的数据格式。图像如下图所示,下载链接为http://www.cs.toronto.edu/~kriz/cifar.html

人脸数据库:
AFLW(Annotated Facial Landmarks in the Wild)
AFLW人脸数据库是一个包括多姿态、多视角的大规模人脸数据库,而且每个人脸都被标注了21个特征点。此数据库信息量非常大,包括了各种姿态、表情、光照、种族等因素影响的图片。AFLW人脸数据库大约包括25000万已手工标注的人脸图片,其中59%为女性,41%为男性,大部分的图片都是彩色,只有少部分是灰色图片。该数据库非常适合用于人脸识别、人脸检测、人脸对齐等方面的研究,具有很高的研究价值。图像如下图所示,需要申请帐号才可以下载,下载链接为http://lrs.icg.tugraz.at/research/aflw/
LFW(Labeled Faces in the Wild)
LFW是一个用于研究无约束的人脸识别的数据库。该数据集包含了从网络收集的13000张人脸图像,每张图像都以被拍摄的人名命名。其中,有1680个人有两个或两个以上不同的照片。这些数据集唯一的限制就是它们可以被经典的Viola-Jones检测器检测到(a hummor)。图像如下图所示,下载链接为http://vis-www.cs.umass.edu/lfw/index.html#download
AFW(Annotated Faces in the Wild)
AFW数据集是使用Flickr(雅虎旗下图片分享网站)图像建立的人脸图像库,包含205个图像,其中有473个标记的人脸。对于每一个人脸都包含一个长方形边界框,6个地标和相关的姿势角度。数据库虽然不大,额外的好处是作者给出了其2012 CVPR的论文和程序以及训练好的模型。图像如下图所示,下载链接为http://www.ics.uci.edu/~xzhu/face/

FDDB(Face Detection Data Set and Benchmark)
FDDB数据集主要用于约束人脸检测研究,该数据集选取野外环境中拍摄的2845个图像,从中选择5171个人脸图像。是一个被广泛使用的权威的人脸检测平台。图像如下图所示,下载链接为http://vis-www.cs.umass.edu/fddb/
WIDER FACE
WIDER FACE是香港中文大学的一个提供更广泛人脸数据的人脸检测基准数据集,由YangShuo, Luo Ping ,Loy ,Chen Change ,Tang Xiaoou收集。它包含32203个图像和393703个人脸图像,在尺度,姿势,闭塞,表达,装扮,关照等方面表现出了大的变化。WIDER FACE是基于61个事件类别组织的,对于每一个事件类别,选取其中的40%作为训练集,10%用于交叉验证(cross validation),50%作为测试集。和PASCAL VOC数据集一样,该数据集也采用相同的指标。和MALF和Caltech数据集一样,对于测试图像并没有提供相应的背景边界框。图像如下图所示,下载链接为http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/
CMU-MIT
CMU-MIT是由卡内基梅隆大学和麻省理工学院一起收集的数据集,所有图片都是黑白的gif格式。里面包含511个闭合的人脸图像,其中130个是正面的人脸图像。图像如下图所示,没有找到官方链接,Github下载链接为https://github.com/watersink/CMU-MIT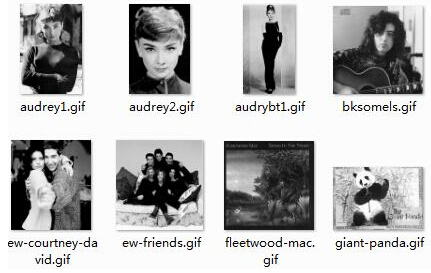
GENKI
GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别。GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。图像如下图所示,下载链接为http://mplab.ucsd.edu,如果进不去可以,同样可以去下面的github下载,链接https://github.com/watersink/GENKI
IJB-A (IARPA JanusBenchmark A)
IJB-A是一个用于人脸检测和识别的数据库,包含24327个图像和49759个人脸。图像如下图所示,需要邮箱申请相应帐号才可以下载,下载链接为http://www.nist.gov/itl/iad/ig/ijba_request.cfm
MALF (Multi-Attribute Labelled Faces)
MALF是为了细粒度的评估野外环境中人脸检测模型而设计的数据库。数据主要来源于Internet,包含5250个图像,11931个人脸。每一幅图像包含正方形边界框,俯仰、蜷缩等姿势等。该数据集忽略了小于20*20的人脸,大约838个人脸,占该数据集的7%。同时,该数据集还提供了性别,是否带眼镜,是否遮挡,是否是夸张的表情等信息。图像如下图所示,需要申请才可以得到官方的下载链接,链接为http://www.cbsr.ia.ac.cn/faceevaluation/
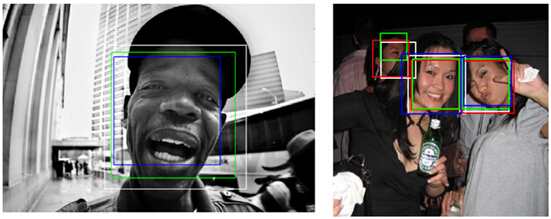
MegaFace
MegaFace资料集包含一百万张图片,代表690000个独特的人。所有数据都是华盛顿大学从Flickr(雅虎旗下图片分享网站)组织收集的。这是第一个在一百万规模级别的面部识别算法测试基准。 现有脸部识别系统仍难以准确识别超过百万的数据量。为了比较现有公开脸部识别算法的准确度,华盛顿大学在去年年底开展了一个名为“MegaFace Challenge”的公开竞赛。这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。图像如下图所示,需要邮箱申请才可以下载,下载链接为http://megaface.cs.washington.edu/dataset/download.html
300W
300W数据集是由AFLW,AFW,Helen,IBUG,LFPW,LFW等数据集组成的数据库。图像如下图所示,需要邮箱申请才可以下载,下载链接为http://ibug.doc.ic.ac.uk/resources/300-W/
IMM Data Sets
IMM人脸数据库包括了240张人脸图片和240个asf格式文件(可以用UltraEdit打开,记录了58个点的地标),共40个人(7女33男),每人6张人脸图片,每张人脸图片被标记了58个特征点。所有人都未戴眼镜,图像如下图所示,下载链接为http://www2.imm.dtu.dk/~aam/datasets/datasets.html
MUCT Data Sets
MUCT人脸数据库由3755个人脸图像组成,每个人脸图像有76个点的地标(landmark),图片为jpg格式,地标文件包含csv,rda,shape三种格式。该图像库在种族、关照、年龄等方面表现出更大的多样性。具体图像如下图所示,下载链接为http://www.milbo.org/muct/
ORL (AT&T Dataset)
ORL数据集是剑桥大学AT&T实验室收集的一个人脸数据集。包含了从1992.4到1994.4该实验室的成员。该数据集中图像分为40个不同的主题,每个主题包含10幅图像。对于其中的某些主题,图像是在不同的时间拍摄的。在关照,面部表情(张开眼睛,闭合眼睛,笑,非笑),面部细节(眼镜)等方面都变现出了差异性。所有图像都是以黑色均匀背景,并且从正面向上方向拍摄。
其中图片都是PGM格式,图像大小为92*102,包含256个灰色通道。具体图像如下图所示,下载链接为http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
行人检测数据库
INRIA Person Dataset
Inria数据集是最常使用的行人检测数据集。其中正样本(行人)为png格式,负样本为jpg格式。里面的图片分为只有车,只有人,有车有人,无车无人四个类别。图片像素为70*134,96*160,64*128等。具体图像如下图所示,下载链接为http://pascal.inrialpes.fr/data/human/
CaltechPedestrian Detection Benchmark
加州理工学院的步行数据集包含大约包含10个小时640x480 30Hz的视频。其主要是在一个在行驶在乡村街道的小车上拍摄。视频大约250000帧(在137个约分钟的长段),共有350000个边界框和2300个独特的行人进行了注释。注释包括包围盒和详细的闭塞标签之间的时间对应关系。更多信息可在其PAMI 2012 CVPR 2009标杆的论文获得。具体图像如下图所示,下载链接为http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
MIT cbcl (center for biological and computational learning)Pedestrian Data
该数据集主要包含2个部分,一部分为128*64的包含924个图片的ppm格式的图片,另一部分为从打图中分别切割而出的小图,主要包含胳膊,脑袋,脚,腿,头肩,身体等。具体图像如下图所示,下载链接为http://cbcl.mit.edu/software-datasets/PedestrianData.html,需要FQ才可以。
年龄,性别数据库
Adience
该数据集来源为Flickr相册,由用户使用iPhone5或者其它智能手机设备拍摄,同时具有相应的公众许可。该数据集主要用于进行年龄和性别的未经过滤的面孔估计。同时,里面还进行了相应的landmark的标注。是做性别年龄估计和人脸对齐的一个数据集。图片包含2284个类别和26580张图片。具体图像如下图所示,下载链接为http://www.openu.ac.il/home/hassner/Adience/data.html#agegender
车辆数据库
KITTI(Karlsruhe Institute ofTechnology and Toyota Technological Institute)
KITTI包含7481个训练图片和7518个测试图片。所有图片都是真彩色png格式。该数据集中标注了车辆的类型,是否截断,遮挡情况,角度值,2维和3维box框,位置,旋转角度,分数等重要的信息,绝对是做车载导航的不可多得的数据集。具体图像如下图所示,下载链接为http://www.cvlibs.net/datasets/kitti/
字符数据库
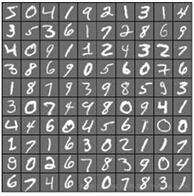
MNIST(Mixed National Instituteof Standards and Technology)
MNIST是一个大型的手写数字数据库,广泛用于机器学习领域的训练和测试,由纽约大学的Yann LeCun整理。MNIST包含60000个训练集,10000个测试集,每张图都进行了尺度归一化和数字居中处理,固定尺寸大小为28*28。具体图像如下图所示,下载链接为http://yann.lecun.com/exdb/mnist/