- 1python:webbrowser --- 方便的 Web 浏览器控制工具_python webbrowser
- 2[C#]C# OpenVINO部署yolov8图像分类模型_c# openvino yolov8
- 3YOLOV5代码general.py文件解读_assert len(files), 'file not found: %s' % file # a
- 4docker部署Jenkins(Jenkins+Gitlab+Maven实现CI/CD)
- 5TPS插值方法
- 6CentOS/Red Hat 安装cuDNN_centos 安装cudnn
- 7支付宝商家二维码收款、订单状态查询、退款API试用笔记_阿里支付二维码下单后返回的qrcode和inneruid
- 8springboot整合支付宝当面付以及退款,查询订单状态,关闭订单(详细步骤)_java 支付宝关闭订单
- 9html添加工具栏,添加带有命令的工具栏 (HTML)
- 10sql server的具体安装教程_sql server安装博客教程
YOLO V7源码解析_yolov7代码
赞
踩
1.命令行参数介绍
YOLO v7参数与YOLO v5差不多,我就直接将YOLO v5命令行参数搬过来了,偷个懒
- --weights:初始权重
- --cfg:模型配置文件
- --data:数据配置文件
- --hyp:学习率等超参数文件
- --epochs:迭代次数
- -imgsz:图像大小
- --rect:长方形训练策略,不resize成正方形,使用灰条进行图片填充,防止图片失真
- --resume:恢复最近的培训,从last.pt开始
- --nosave:只保存最后的检查点
- --noval:仅在最后一次epochs进行验证
- --noautoanchor:禁用AutoAnchor
- --noplots:不保存打印文件
- --evolve:为x个epochs进化超参数
- --bucket:上传操作,这个参数是 yolov5 作者将一些东西放在谷歌云盘,可以进行下载
- --cache:在ram或硬盘中缓存数据
- --image-weights:测试过程中,图像的那些测试地方不太好,对这些不太好的地方加权重
- --single-cls:单类别标签置0
- --device:gpu设置
- --multi-scale:改变img大小+/-50%,能够被32整除
- --optimizer:学习率优化器
- --sync-bn:使用SyncBatchNorm,仅在DDP模式中支持,跨gpu时使用
- --workers:最大 dataloader 的线程数 (per RANK in DDP mode)
- --project:保存文件的地址
- --name:保存日志文件的名称
- --exist-ok:对项目名字是否进行覆盖
- --quad:在dataloader时采用什么样的方式读取我们的数据,1280的大图像可以指定
- --cos-lr:余弦学习率调度
- --label-smoothing:
- --patience:经过多少个epoch损失不再下降,就停止迭代
- --freeze:迁移学习,冻结训练
- --save-period:每x个周期保存一个检查点(如果<1,则禁用)
- --seed:随机种子
- --local_rank:gpu编号
- --entity:可视化访问信息
- --quad:
- 四元数据加载器是我们认为的一个实验性功能,它可能允许在较低 --img 尺寸下进行更高 --img 尺寸训练的一些好处。
- 此四元整理功能会将批次从 16x3x640x640 重塑为 4x3x1280x1280,这不会产生太大影响 本身,因为它只是重新排列批次中的马赛克,
- 但有趣的是允许批次中的某些图像放大 2 倍(每个四边形中的 4 个马赛克中的一个放大 2 倍,其他 3 个马赛克被删除)
2.训练策略
ema:移动平均法,在更新参数的时候我们希望更平稳一些,考虑的步骤更多一些。公式为:,当系数为
时,相当于考虑
步更新的梯度,YOLO v7默认
为0.999,相当于考虑1000步更新的梯度
3.网络结构
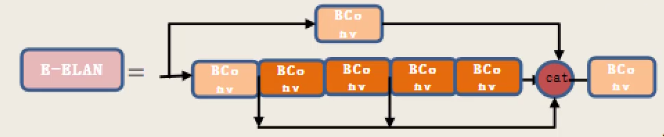
E-ELAN:
如下图所示,配置文件的部分就是E-ELAN模块,有四条路径,分别经过1个卷积、1个卷积、3个卷积和5个卷积,其中有3条路径共享了特征图。最后,对四条路径的特征图进行拼接。经过E-ELAN后,相较于输入,特征图通道数加倍。
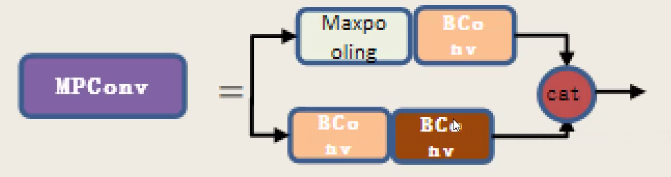
MPCONV:
对于MPconv,也分为两条路径,一条经过Maxpooling层,另一条路径经过卷积进行下采样,可以理解为综合考虑卷积和池化的下采样结果,以提升性能。最后,对特征图进行拼接。
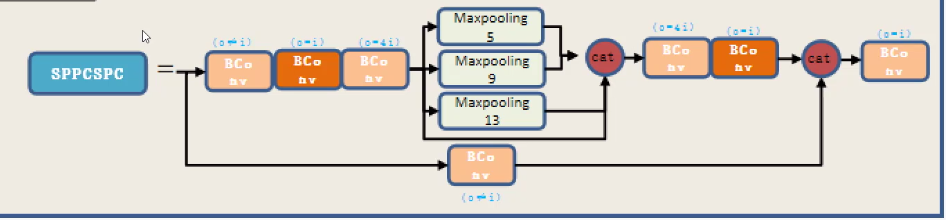
SPPCSPC:
YOLO v7还是采用了SPP的思想,首先对特征图经过3次卷积,然后分别经过5*5,9*9,13*13的池化,需要注意的是,将5*5与9*9最大池化的特征图进行ADD操作,与13*13和原特征图进行拼接,经过不同kenel_size的池化,实现了对不同感受野的特征融合。然后再经过2次卷积,与经过一次卷积的特征图进行拼接。
代码如下:
- class SPPCSPC(nn.Module):
- # CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
- def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
- super(SPPCSPC, self).__init__()
- c_ = int(2 * c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c1, c_, 1, 1)
- self.cv3 = Conv(c_, c_, 3, 1)
- self.cv4 = Conv(c_, c_, 1, 1)
- self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
- self.cv5 = Conv(4 * c_, c_, 1, 1)
- self.cv6 = Conv(c_, c_, 3, 1)
- self.cv7 = Conv(2 * c_, c2, 1, 1)
-
- def forward(self, x):
- x1 = self.cv4(self.cv3(self.cv1(x)))
- y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
- y2 = self.cv2(x)
- return self.cv7(torch.cat((y1, y2), dim=1))
PAN:
yolo v7还是采用了YOLO v5的PAN,经过SPPCSPC层后的特征图不断进行上采样,并与低层信息进行融合,实现了低层信息和高层信息的特征融合,然后进行下采样,与低层进行特征融合,实现了高层信息与低层信息的特征融合。
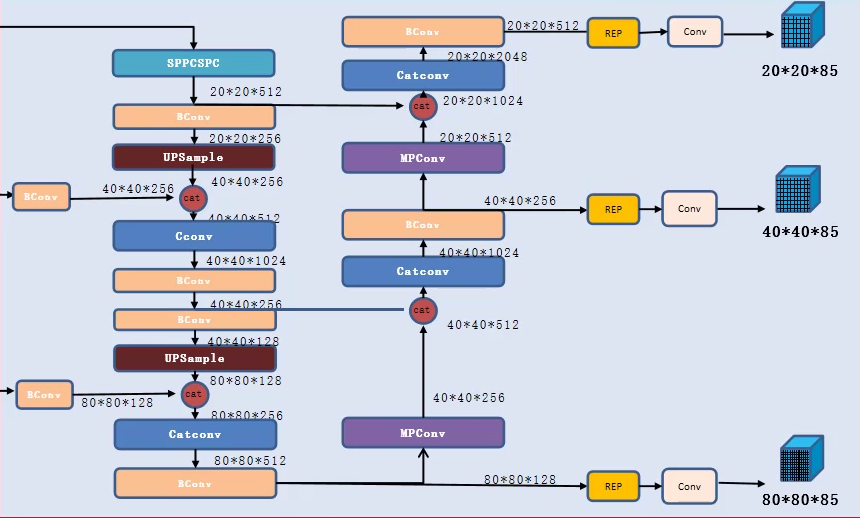
HEAD:
head部分首先经过一层repconv,由3条路径组成,1层1*1的卷积、1层3*3的卷积和1层BN层。 经过repconv后,经过输出层输出结果
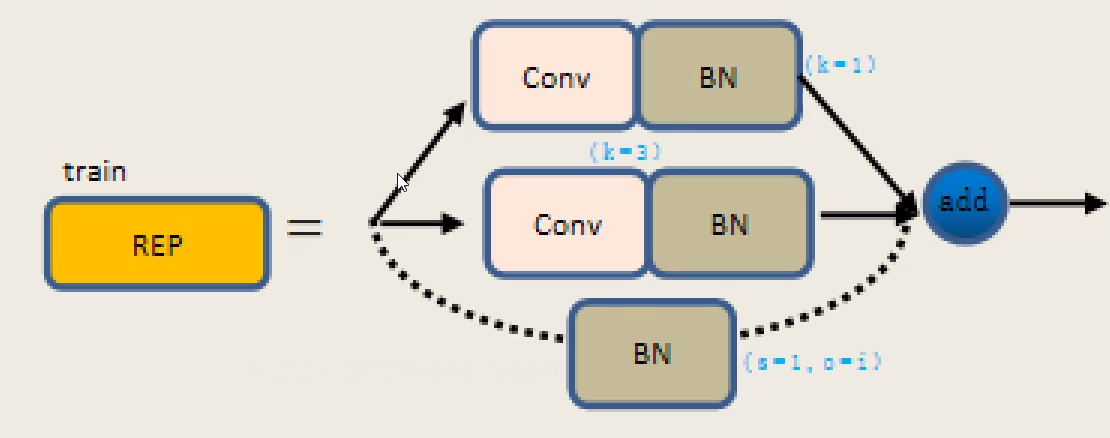
代码如下:
- class RepConv(nn.Module):
- # Represented convolution
- # https://arxiv.org/abs/2101.03697
-
- def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
- super(RepConv, self).__init__()
-
- self.deploy = deploy
- self.groups = g
- self.in_channels = c1
- self.out_channels = c2
-
- assert k == 3
- assert autopad(k, p) == 1
-
- padding_11 = autopad(k, p) - k // 2
-
- self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
-
- if deploy:
- self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
-
- else:
- self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
-
- self.rbr_dense = nn.Sequential(
- nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
- nn.BatchNorm2d(num_features=c2),
- )
-
- self.rbr_1x1 = nn.Sequential(
- nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False),
- nn.BatchNorm2d(num_features=c2),
- )
-
- def forward(self, inputs):
- if hasattr(self, "rbr_reparam"):
- return self.act(self.rbr_reparam(inputs))
-
- if self.rbr_identity is None:
- id_out = 0
- else:
- id_out = self.rbr_identity(inputs)
-
- return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
-
- def get_equivalent_kernel_bias(self):
- kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
- kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
- kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
- return (
- kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
- bias3x3 + bias1x1 + biasid,
- )
-
- def _pad_1x1_to_3x3_tensor(self, kernel1x1):
- if kernel1x1 is None:
- return 0
- else:
- return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
-
- def _fuse_bn_tensor(self, branch):
- if branch is None:
- return 0, 0
- if isinstance(branch, nn.Sequential):
- kernel = branch[0].weight
- running_mean = branch[1].running_mean
- running_var = branch[1].running_var
- gamma = branch[1].weight
- beta = branch[1].bias
- eps = branch[1].eps
- else:
- assert isinstance(branch, nn.BatchNorm2d)
- if not hasattr(self, "id_tensor"):
- input_dim = self.in_channels // self.groups
- kernel_value = np.zeros(
- (self.in_channels, input_dim, 3, 3), dtype=np.float32
- )
- for i in range(self.in_channels):
- kernel_value[i, i % input_dim, 1, 1] = 1
- self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
- kernel = self.id_tensor
- running_mean = branch.running_mean
- running_var = branch.running_var
- gamma = branch.weight
- beta = branch.bias
- eps = branch.eps
- std = (running_var + eps).sqrt()
- t = (gamma / std).reshape(-1, 1, 1, 1)
- return kernel * t, beta - running_mean * gamma / std
-
- def repvgg_convert(self):
- kernel, bias = self.get_equivalent_kernel_bias()
- return (
- kernel.detach().cpu().numpy(),
- bias.detach().cpu().numpy(),
- )
-
- def fuse_conv_bn(self, conv, bn):
-
- std = (bn.running_var + bn.eps).sqrt()
- bias = bn.bias - bn.running_mean * bn.weight / std
-
- t = (bn.weight / std).reshape(-1, 1, 1, 1)
- weights = conv.weight * t
-
- bn = nn.Identity()
- conv = nn.Conv2d(in_channels = conv.in_channels,
- out_channels = conv.out_channels,
- kernel_size = conv.kernel_size,
- stride=conv.stride,
- padding = conv.padding,
- dilation = conv.dilation,
- groups = conv.groups,
- bias = True,
- padding_mode = conv.padding_mode)
-
- conv.weight = torch.nn.Parameter(weights)
- conv.bias = torch.nn.Parameter(bias)
- return conv
-
- def fuse_repvgg_block(self):
- if self.deploy:
- return
- print(f"RepConv.fuse_repvgg_block")
-
- self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
-
- self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
- rbr_1x1_bias = self.rbr_1x1.bias
- weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
-
- # Fuse self.rbr_identity
- if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity, nn.modules.batchnorm.SyncBatchNorm)):
- # print(f"fuse: rbr_identity == BatchNorm2d or SyncBatchNorm")
- identity_conv_1x1 = nn.Conv2d(
- in_channels=self.in_channels,
- out_channels=self.out_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- groups=self.groups,
- bias=False)
- identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
- identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
- # print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
- identity_conv_1x1.weight.data.fill_(0.0)
- identity_conv_1x1.weight.data.fill_diagonal_(1.0)
- identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
- # print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
-
- identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
- bias_identity_expanded = identity_conv_1x1.bias
- weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
- else:
- # print(f"fuse: rbr_identity != BatchNorm2d, rbr_identity = {self.rbr_identity}")
- bias_identity_expanded = torch.nn.Parameter( torch.zeros_like(rbr_1x1_bias) )
- weight_identity_expanded = torch.nn.Parameter( torch.zeros_like(weight_1x1_expanded) )
-
-
- #print(f"self.rbr_1x1.weight = {self.rbr_1x1.weight.shape}, ")
- #print(f"weight_1x1_expanded = {weight_1x1_expanded.shape}, ")
- #print(f"self.rbr_dense.weight = {self.rbr_dense.weight.shape}, ")
-
- self.rbr_dense.weight = torch.nn.Parameter(self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
- self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
-
- self.rbr_reparam = self.rbr_dense
- self.deploy = True
-
- if self.rbr_identity is not None:
- del self.rbr_identity
- self.rbr_identity = None
-
- if self.rbr_1x1 is not None:
- del self.rbr_1x1
- self.rbr_1x1 = None
-
- if self.rbr_dense is not None:
- del self.rbr_dense
- self.rbr_dense = None
输出层:
对于输出层,YOLO v7采用了yoloR的思想,首先对于经过repconv的特征图,经过ImplicitA层,我个人的理解是,ImplicitA相当于就是各个通道一个偏置项,以丰富各个通道所提取的信息,同时这个偏置项是可以学习的。经过ImplicitA后的特征馈送到输出层中,将输出的结果ImplicitM层,ImplicitM层我的理解是他对输出结果进行了放缩,能够更好的进行回归框的预测。
- class ImplicitA(nn.Module):
- def __init__(self, channel, mean=0., std=.02):
- super(ImplicitA, self).__init__()
- self.channel = channel
- self.mean = mean
- self.std = std
- self.implicit = nn.Parameter(torch.zeros(1, channel, 1, 1))
- nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
-
- def forward(self, x):
- return self.implicit + x
-
-
- class ImplicitM(nn.Module):
- def __init__(self, channel, mean=1., std=.02):
- super(ImplicitM, self).__init__()
- self.channel = channel
- self.mean = mean
- self.std = std
- self.implicit = nn.Parameter(torch.ones(1, channel, 1, 1))
- nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
-
- def forward(self, x):
- return self.implicit * x
4.损失函数
损失函数的输入有3个部分,第一个是预测值,第二个是标签,第三个是图像img
预测值即为上面模型的输出,而对于标签target, 维度为物体数量*6,对于第二个维度,第一列为标签的索引,第二列为物体所属类别,而后面四列为物体检测框。
候选框的偏移
首先,对target进行变换,让target包含anchor的索引,此时target维度为
number of anchors,number of targets,7,最后一个维度7的组成为:batch索引,类别,x,y,w,h,anchor索引。
对于偏移,偏移的思想是应对正负样本不均衡的问题,通常来说,负样本远远多于正样本。因此,通过偏移,可以构建更多的正样本。对于样本的中心点,只要目标的中心点偏移后位于附近的网格,也认为这个目标属于这个网格,对应的锚框的区域为正样本
具体过程为:
-
输入target标签为相对坐标,将x,y,w,h映射到特征图上
-
计算锚框与真实框的宽高比,筛选出宽高比在1/r~r(默认为4),其他相差太大的锚框全部,去除,这样可以保证回归结果
- 分别以左上角为原点和右下角为原点得到中心点的坐标
-
对于每一个网格,选出中心点离网格中心点左、上小于0.5的target,并且不能是边界,例如:当中心点距离网格左边的距离小于0.5时,中心点左移0.5,此时,该网格左边的网格对应的锚框也为正样本。
通过,偏移,增加了正样本的数量,返回整数作为中心点所在网格的索引,最终得到存储batch_indices, anchor_indices, grid indices的索引矩阵和对应的anchors
代码如下:
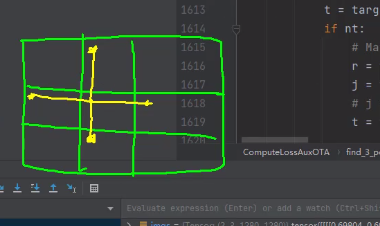
- def find_3_positive(self, p, targets):
- # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
- na, nt = self.na, targets.shape[0] # number of anchors, targets
- indices, anch = [], []
- gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
- #---------------------------------------------------------------------------------#
- # number of anchors,number of targets
- # 表示哪个target属于哪个anchor
- #---------------------------------------------------------------------------------#
- ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
- # ---------------------------------------------------------------------------------#
- # number of anchors,number of targets,7
- # 最后一个维度7的组成为:batch索引,类别,x,y,w,h,anchor索引
- # ---------------------------------------------------------------------------------#
- targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
-
- # ---------------------------------------------------------------------------------#
- # 对于样本的中心点,只要目标的中心点偏移后位于附近的网格,也认为这个目标属于这个网格,对应的锚框的区域为正样本
- # ---------------------------------------------------------------------------------#
- g = 0.5 # bias
- off = torch.tensor([[0, 0],
- [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
- # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
- ], device=targets.device).float() * g # offsets
-
- for i in range(self.nl):
- anchors = self.anchors[i]
- # 特征图的h,w
- gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
-
- # Match targets to anchors
- # target标签为相对坐标,将x,y,w,h映射到特征图上
- t = targets * gain
- if nt:
- # Matches
- # 计算锚框与真实框的宽高比,筛选出宽高比在1/r~r(默认为4),其他相差太大的锚框全部
- # 去除,这样可以保证回归结果
- r = t[:, :, 4:6] / anchors[:, None] # wh ratio
- j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
- # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
- t = t[j] # filter 去除相差太大的锚框
-
- # Offsets 偏移操作
- # 到左上角的距离,相当于就是以左上角为原点
- gxy = t[:, 2:4] # grid xy
- # 到右下角的距离,相当于就是以右下角为原点
- gxi = gain[[2, 3]] - gxy # inverse
- # 对于每一个网格,选出中心点离网格中心点左上角小于0.5的target,并且不能是边界
- # 例如:有两个真实框,需要判断,第一个物体是否满足要求,第二个物体是否满足要求,
- # 将所得的的矩阵转置,j代表在H维度是否满足要求,k代表在w维度是否满足要求
- j, k = ((gxy % 1. < g) & (gxy > 1.)).T
- # 对于每一个网格,选出中心点离网格中心点右下角小于0.5的target,并且不能是边界
- l, m = ((gxi % 1. < g) & (gxi > 1.)).T
- # 对应于上面的五个偏移
- j = torch.stack((torch.ones_like(j), j, k, l, m))
- # target重复五次对应于五个偏移,然后判断能否进行偏移,比如,到网格左边的距离小于0.5,就向左进行偏移,
- # 需要注意的是,上面给的+1,但是下面操作是减,因此到网格左边的距离小于0.5,就向左进行偏移
- t = t.repeat((5, 1, 1))[j]
- offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
- else:
- t = targets[0]
- offsets = 0
-
- # Define batch_indice,class
- b, c = t[:, :2].long().T # image, class
- gxy = t[:, 2:4] # grid xy
- gwh = t[:, 4:6] # grid wh
- # 执行偏移操作
- gij = (gxy - offsets).long()
- gi, gj = gij.T # grid xy indices
-
- # Append
- a = t[:, 6].long() # anchor indices
- indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
- anch.append(anchors[a]) # anchors
-
- return indices, anch
候选框的筛选分析:
yolo v7的候选框的筛选跟YOLO v5和YOLO X均不相同,对于上面候选框的偏移,我们最终得到了9个锚框,然后分别计算这9个锚框的类别损失和IOU损失之和。
具体过程为: 首先对候选框进行初筛,取出初筛的索引及对应的预测结果,计算出对应的x,y和w,h。需要注意的是,计算过程与初赛过程相对应。对于x,y的计算,若x,y分别为相对于网格的距离,范围为0~1,经过偏移后,x,y的取值范围为-0.5~1.5。对w和h也进行限制,初筛的时候,我们将宽高比大于4的都去掉了,因此,预测的范围也为0-4。然后计算预测框和真实框的iou,取出iou损失中最小的topk,如果多于10个候选框,取10个,少于10个候选框,全部取。然后 对topk的iou进行累加操作,最后取[iou之和]个候选框,相当于iou很小的候选框统统不要,最小为1个,其目的去除iou很小的候选框。并计算出iou损失,和分类损失进行加权,根据加权的结果筛选出对应的候选框。如果出现多个真实框匹配到了同一候选框的情况,此时对应的anchor_matching_gt > 1。比较哪一个真实框跟这个候选框的损失最小,损失最小的真实框匹配上该候选框,其他地方置为0。最后对信息进行汇总,返回batch索引,anchor索引,网格索引,对应的真实标签信息和锚框,并按照输出层进行统计。
代码如下:
- def build_targets(self, p, targets, imgs):
-
- #indices, anch = self.find_positive(p, targets)
- indices, anch = self.find_3_positive(p, targets)
- #indices, anch = self.find_4_positive(p, targets)
- #indices, anch = self.find_5_positive(p, targets)
- #indices, anch = self.find_9_positive(p, targets)
-
- matching_bs = [[] for pp in p]
- matching_as = [[] for pp in p]
- matching_gjs = [[] for pp in p]
- matching_gis = [[] for pp in p]
- matching_targets = [[] for pp in p]
- matching_anchs = [[] for pp in p]
-
- nl = len(p)
-
- for batch_idx in range(p[0].shape[0]):
- # 取出batch对应的target
- b_idx = targets[:, 0]==batch_idx
- this_target = targets[b_idx]
- if this_target.shape[0] == 0:
- continue
-
- # 取出对应的真实框,转换为x1,y1,x2,y2
- txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
- txyxy = xywh2xyxy(txywh)
-
- pxyxys = []
- p_cls = []
- p_obj = []
- from_which_layer = []
- all_b = []
- all_a = []
- all_gj = []
- all_gi = []
- all_anch = []
-
- for i, pi in enumerate(p):
-
- # 有时候index会为空,代表某一层没有对应的锚框
- # b代表batch_index,a代表anchor_indices,
- # gj,gi代表网格索引
- b, a, gj, gi = indices[i]
- idx = (b == batch_idx)
- b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
- all_b.append(b)
- all_a.append(a)
- all_gj.append(gj)
- all_gi.append(gi)
- all_anch.append(anch[i][idx])
- # size为初筛后的候选框数量,值为输出层的索引
- from_which_layer.append(torch.ones(size=(len(b),)) * i) # 来自哪个输出层
-
- fg_pred = pi[b, a, gj, gi] # 对应网格的预测结果
- p_obj.append(fg_pred[:, 4:5])
- p_cls.append(fg_pred[:, 5:])
-
- grid = torch.stack([gi, gj], dim=1) # 网格坐标
- # 与候选框的偏移相对应,若x,y分别为相对于网格的距离,范围为0~1,经过偏移后,x,y的取值范围为-0.5~1.5
- # 而下面的预测结果经过sigmoid后的范围为0~1,最终计算的范围为-0.5~1.5
- pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] #/ 8.
- #pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
- # 对w和h也进行限制,初筛的时候,我们将宽高比大于4的都去掉了,因此,预测的范围也为0-4
- pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] #/ 8.
- pxywh = torch.cat([pxy, pwh], dim=-1)
- pxyxy = xywh2xyxy(pxywh) # 转换为x,y,w,h
- pxyxys.append(pxyxy)
-
- pxyxys = torch.cat(pxyxys, dim=0)
- if pxyxys.shape[0] == 0:
- continue
- # 对三层的结果进行汇总,可能有些层结果为空
- p_obj = torch.cat(p_obj, dim=0)
- p_cls = torch.cat(p_cls, dim=0)
- from_which_layer = torch.cat(from_which_layer, dim=0)
- all_b = torch.cat(all_b, dim=0)
- all_a = torch.cat(all_a, dim=0)
- all_gj = torch.cat(all_gj, dim=0)
- all_gi = torch.cat(all_gi, dim=0)
- all_anch = torch.cat(all_anch, dim=0)
-
- # 计算ciou损失
- pair_wise_iou = box_iou(txyxy, pxyxys)
-
- pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
-
- # 取出iou损失中最小的topk,如果多于10个候选框,取10个,少于10个候选框,全部取
- top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1)
- # 对iou进行累加操作,最后取[iou之和]个候选框,相当于iou很小的候选框统统不要,最小为1个
- dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
-
- # 将类别转换为one_hot编码格式
- gt_cls_per_image = (
- F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
- .float()
- .unsqueeze(1)
- .repeat(1, pxyxys.shape[0], 1)
- )
-
- # 真实框目标的个数
- num_gt = this_target.shape[0]
- # 预测概率:p_obj*p_cls
- cls_preds_ = (
- p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
- * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
- )
-
- y = cls_preds_.sqrt_()
- pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
- torch.log(y/(1-y)) , gt_cls_per_image, reduction="none"
- ).sum(-1)
- del cls_preds_
-
- # 总损失:cls_loss+iou_loss
- cost = (
- pair_wise_cls_loss
- + 3.0 * pair_wise_iou_loss
- )
-
- matching_matrix = torch.zeros_like(cost)
- # 取出损失最小的候选框的索引
- for gt_idx in range(num_gt):
- _, pos_idx = torch.topk(
- cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
- )
- matching_matrix[gt_idx][pos_idx] = 1.0
-
- del top_k, dynamic_ks
- # 竖着加
- anchor_matching_gt = matching_matrix.sum(0)
- # 处理多个真实框匹配到了同一候选框的情况,此时对应的anchor_matching_gt > 1
- if (anchor_matching_gt > 1).sum() > 0:
- # 比较哪一个真实框跟这个候选框的损失最小
- _, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
- matching_matrix[:, anchor_matching_gt > 1] *= 0.0
- # 损失最小的真实框匹配上该候选框,其他地方置为0
- matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
- # 正样本索引
- fg_mask_inboxes = matching_matrix.sum(0) > 0.0
- # 正样本对应真实框的索引
- matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
-
- # 汇总
- from_which_layer = from_which_layer[fg_mask_inboxes]
- all_b = all_b[fg_mask_inboxes]
- all_a = all_a[fg_mask_inboxes]
- all_gj = all_gj[fg_mask_inboxes]
- all_gi = all_gi[fg_mask_inboxes]
- all_anch = all_anch[fg_mask_inboxes]
-
- # 真实框
- this_target = this_target[matched_gt_inds]
-
- # 按照三个输出层合并信息
- for i in range(nl):
- layer_idx = from_which_layer == i
- matching_bs[i].append(all_b[layer_idx])
- matching_as[i].append(all_a[layer_idx])
- matching_gjs[i].append(all_gj[layer_idx])
- matching_gis[i].append(all_gi[layer_idx])
- matching_targets[i].append(this_target[layer_idx])
- matching_anchs[i].append(all_anch[layer_idx])
-
- # 按照输出层,汇总整个batch的信息
- for i in range(nl):
- if matching_targets[i] != []:
- matching_bs[i] = torch.cat(matching_bs[i], dim=0)
- matching_as[i] = torch.cat(matching_as[i], dim=0)
- matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
- matching_gis[i] = torch.cat(matching_gis[i], dim=0)
- matching_targets[i] = torch.cat(matching_targets[i], dim=0)
- matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
- else:
- matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
- matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
- matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
- matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
- matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
- matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
-
- return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
损失函数:
损失函数与YOLO v5 r6.1版本并无变化,主要包含分类损失、存在物体置信度损失以及边界框回归损失。分类损失和置信度损失均使用交叉熵损失。回归损失使用C-IOU损失。
辅助头网络结构:
当添加辅助输出时,网络结构的输入为1280*1280,第一层需要对图片进行下采样,作者考虑到节省参数,第一层下采样采取间隔采样的做法。
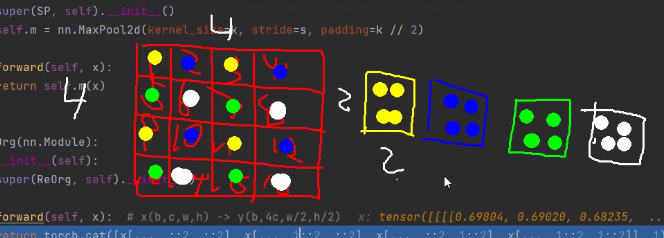
代码如下:
- class ReOrg(nn.Module):
- def __init__(self):
- super(ReOrg, self).__init__()
-
- def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
- return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
对于辅助输出,一共有八层,对于辅助输出,在损失函数的处理上有所区别,在标签分配上,辅助输出的偏移量为1,因此一共有5个网格,另外,在候选框的初步筛选上,辅助头的top_k为20。这一系列的处理,能够提升辅助头输出的召回率。因此,辅助头更加关注召回率。在损失函数上,辅助头的损失计算用0.25进行缩放。
模型的重参数化:
卷积和bn的重参数化:bn层的公式如图所示,可以变换为wx+b的形式
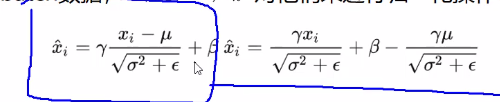
因此,可以得到bn层w和b的权重矩阵。

将卷积公式带入其中,最终得到融合的权重矩阵和偏差的计算公式。
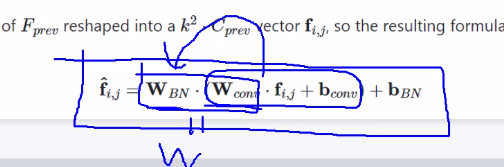
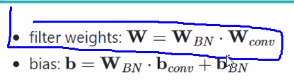
对于1*1和3*3卷积的参数化,将1*1的卷积核周围用0填充和3*3的卷积核相加