
- 1宝塔部署阿里云盘webdav_宝塔安装 webdav
- 2超市经营分析_kaggle supermarket sales
- 3QT 通过config指定release和debug模式_qt config(debug)
- 4Ubuntu16.04安装teamviewer_package libminizip1 is not installed.
- 5什么是虚拟机,虚拟机有什么妙用?_虚拟机有什么用&license csdn
- 6vim的查找功能怎么使用_vim 查找
- 7php节目代理,基于php电视节目时间表接口示例
- 8java四种访问控制权限的总结_java提供了四种访问控制权限
- 9Ubuntu Server下启动/停止/重启MySQL数据库的三种方式(ubuntu 18.04)
- 10常见直播流协议,你学“废”了吗?_rtmp被淘汰了吗
【数据分析师-数据分析项目案例一】600w+条短租房数据案例分析_利用jupyter notebook分类模型的构建、预测、评估与分析结果说明租房案例
赞
踩
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/119940333(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
- 1
1 前言
1.1 数据集
-
本案例中的数据来自于爱彼迎(Airbnb)网站2018-2019年度的多伦多市的真实数据。
-
数据集中包含listings数据集,约有2万条数据,记录着所有的房屋信息,包括价格在内的几十项信息字段。
-
数据集中的另一个数据集是calendar,包含约650万条的租房交易数据,拥有每一天每一所住房的入驻信息。
1.2 数据分析思路梳理
常规数据分析,数据字段载入和常见数据ETL四板斧的清洗处理
-
方法1:
.isnull().sum()检查空值情况 -
方法2:
.shape检查数据尺寸 -
方法3:
.describe()查看数据字段数据类型 -
方法4:
.value_counts()查看数据集合数据分布情况
数据分析师最终是要把结果以可视化的方式进行呈现,所以对于分析得到的数据要进行图表化展示。由于本案例主要研究的目标是价格的依赖因素,所以我们采用价格和另一个因素的对比作图来观察。常见图形包括:
-
图形1: 柱状图,来观察数据的分布情况
-
图形2: 箱型图,来观察数据的范围
-
图形3: 散点矩阵图,来观察不同因素间的相互联系
-
图形4: 热力图,来快速筛选出高关联度的信息因素
传统的数据分析一般就会到此为止,但是对于探索试数据分析来说,事情才刚刚开始,为了更深入的进行数据分析,本案例开始引入机器学习模型,由于机器学习模型本质上就是数学模型,所以我们需要对数据集合进行特征工程,把数据集合变为方便模型识别的数组,本例中采用如下几个步骤:
- 步骤1:数据的标准化
- 步骤2:缺失数据的修复
- 步骤3:字符串类数据的编码化
- 步骤4:数据类型转换和单位统一
对于本例中的众多字段用简单的线性回归等模型已经不能很好的捕捉出数据的动态,所以我们采用一些符合机器学习模型,也就是利用一系列若关联的特性组合出强特性的模型,在本例中我们采用两个模型:
-
模型1 :随机森林模型,这个模型是一个复合模型,对特征和标签进行任意排列组合,然后通过概率方式进行建模,最大程度的降低过拟合的出现。
-
模型2 :微软的LightGBM模型也是最近几年非常火的复合模型,在本例中我们使用这个模型和随机森林进行模型对比,利用R2值来选出最合适的机器学习模型。
2 数据分析
2.1 数据加载
代码编写是在Anaconda集成环境下的jupyter notebook上进行,首先导入数据分析所需要的模块以及数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
calendar = pd.read_csv('toroto/calendar.csv.gz')
print('We have', calendar.date.nunique(), 'days and', calendar.listing_id.nunique(), 'unique listings in the calendar data.')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果如下:(数据包含了365天共17333份房间信息,nunique()方法是进行字段的唯一值查询,返回字段中唯一元素的个数)

2.2 数据查看
(1)数据维度和字段信息
calendar.shape
calendar.head()
- 1
- 2
- 3
输出结果如下:(共有630w+条交易记录,4个字段。listing_id: 房屋数据编号, date: 当前记录时间, available: 当前房间是否没被租赁, price 如果没有被租赁,则显示价格)

(2)交易的起止日期
calendar.date.min(), calendar.date.max()
- 1
输出结果如下:(交易的时间范围是在2018年10月6号至2019年10月5号,整整一年的时间)
(3)字段缺失值和字段统计
calendar.isnull().sum()
calendar.available.value_counts()
- 1
- 2
- 3
输出结果如下:(price字段,由于房子出租后,就没有价格显示,只有未出租才有价格,所以该字段存在着缺失值;available字段中f (false) 代表已经被租用 , t(true) 代表可以被出租)

3 数据可视化
3.1 每天房屋入住率
读取的数据中包含了1w多套房源,共有600w+交易记录,涵盖了交易的起止日期,因此可以探究每天房屋的入住情况(当天入住的数量除以总的房间数量)。具体分析的步骤如下:
#提取时间日期和房间状态字段并赋值新变量
calendar_new = calendar[['date', 'available']]
#添加一个新的字段记录房源是够被出租
calendar_new['busy'] = calendar_new.available.map( lambda x: 0 if x == 't' else 1)
#按照时间日期进行分组求解每日入住的均值并重置索引
calendar_new = calendar_new.groupby('date')['busy'].mean().reset_index()
#最后将时间日期转化为datetime时间格式
calendar_new['date'] = pd.to_datetime(calendar_new['date'])
#查看处理后的结果前五行
calendar_new.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果如下:(date字段就是时间日期,busy字段就代表这个每天的平均入住率)

输出结果汇总发现有个粉红色的警示输出提醒xxxWarning,需要了解一下pandas在进行数据处理和分析过程中会存在版本和各类模块兼容的情况,xxxWarning是一种善意的提醒,并不是xxxError,这类提醒不会影响程序的正常运行,也可以导入模块进行提醒忽略
import warnings
warnings.filterwarnings('ignore')
- 1
- 2
导入运行后,重新执行上述分析过程,输出结果如下:(此时就没有粉红色的xxxWarning提醒了)

每天房屋入住率求解完毕后,就可以进行可视化展现,由于绘制图形的x轴部分为时间日期,且时间跨度较大,一般是采用折线图进行绘制图形
#设置图形的大小尺寸
plt.figure(figsize=(10, 5))
#指定x和y轴数据进行绘制
plt.plot(calendar_new['date'], calendar_new['busy'])
#添加图形标题
plt.title('Airbnb Toronto Calendar')
#添加y轴标签
plt.ylabel('busy')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果如下:(通过图中我们可以看到,10-11月是最繁忙的,然后是第二年的7-9月,由于这份数据是来自爱彼迎多伦多地区,所以可以推断出整个短租房的入住率是在下半年会比较旺盛)
3.2 房屋月份价格走势
此次有两个分析技巧,由于价格部分带有$符号和,号,所以我们需要对数据进行格式化处理,并且转换时间字段。处理完时间字段后,使用柱状图进行数据分析
#先将时间日期字段转化为datetime字段方便提取月份数据
calendar['date'] = pd.to_datetime(calendar['date'])
#清洗price字段中的$符号和,号,最后转化为浮点数方便记性计算
calendar['price'] = calendar['price'].str.replace(',', '')
calendar['price'] = calendar['price'].str.replace('$', '')
calendar['price'] = calendar['price'].astype(float)
#按照月份进行分组汇总求解价钱的均值
mean_of_month = calendar.groupby(calendar['date'].dt.strftime('%B'),
sort=False)['price'].mean()
#绘制条形图
mean_of_month.plot(kind = 'barh' , figsize = (12,7))
#添加x轴标签
plt.xlabel('average monthly price')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出结果如下:(上一次转化datetime数据类型是calendar_new变量中的date字段,但是calendar变量中的date字段的数据类型还仍是字符串数据类型)

如果想要月份按照1-12月的方式进行顺序输出,可以重新指定索引。已有的索引放置在一个列表中,排好序后传入reindex()函数中,操作如下
#先查看原来的索引值
mean_of_month.index
#根据原有的索引值调整显示的位置顺序
month_index = ['December', 'November', 'October', 'September', 'August',
'July','June', 'May', 'April','March', 'February', 'January']
#重新指定索引后绘制图形
mean_of_month = mean_of_month.reindex(month_index)
mean_of_month.plot(kind = 'barh' , figsize = (12,7))
plt.xlabel('average monthly price')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果如下:(图中可以看出7月 8月和10月是平均价格最高的三个月)

3.3 房屋星期价格特征
#获取星期的具体天数的名称 calendar['dayofweek'] = calendar.date.dt.weekday_name #然后指定显示的索引顺序 cats = [ 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'] #提取要分析的两个字段 price_week=calendar[['dayofweek','price']] #按照星期进行分组求解平均价钱后重新设置索引 price_week = calendar.groupby(['dayofweek']).mean().reindex(cats) #删除不需要的字段 price_week.drop('listing_id', axis=1, inplace=True) #绘制图形 price_week.plot() #指定轴刻度的数值及对应的标签值 ticks = list(range(0, 7, 1)) labels = "Mon Tues Weds Thurs Fri Sat Sun".split() plt.xticks(ticks, labels) #如果不想要显示xticks信息,可以增添plt.show() plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出结果如下:(直接指定DataFrame绘制图形,可能x轴的刻度和标签信息不会全部显示,此时可以自行指定刻度数量和对应的标签值。短租房本身大都为了旅游而存在,所以周五周六两天的价格都比其他时间贵出一个档次。周末双休,使得入驻的时间为周五周六晚两个晚上)

3.4 不同社区的房源数量
读取另外一个数据文件,按照每个房源社区进行分组,统计房源的数量(id字段对应着房源独特的编号)
listings = pd.read_csv('toroto/listings.csv.gz')
print('We have', listings.id.nunique(), 'listings in the listing data.')
listings.groupby(by='neighbourhood_cleansed').count()[['id']].sort_values(by='id', ascending=False).head(10)
- 1
- 2
- 3
- 4
输出结果如下:(两个字段的分组求解过程基本就是最后一行代码的执行过程,最后还可以顺带按照字段进行排序和查看数据量)
3.5 房源评分情况
通过对review_scores_rating评分字段进行分布图绘制,可以查看价格的分布区间范围
#设置画布大小尺寸
plt.figure(figsize=(12,6))
#绘制分布图
sns.distplot(listings.review_scores_rating.dropna(), rug=True)
#取消右侧和上侧坐标轴
sns.despine()
- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:(此处的评分标准为0-100分制,通过上述表格可以看出总体来看爱彼迎的房屋好评率非常高)

3.6 房源价格情况
前面探究了房源价格和星期之间的关联,但是房价字段自身的信息并没有探究,可以使用describe查看价格的情况
listings['price'] = listings['price'].str.replace(',', '')
listings['price'] = listings['price'].str.replace('$', '')
listings['price'] = listings['price'].astype(float)
listings['price'].describe()
- 1
- 2
- 3
- 4
- 5
输出结果如下:(多伦多最昂贵的Airbnb房源价格为$ 12933 /晚(当时的价钱,现在的价钱是$ 64818 /晚),以下是房屋的链接:https://www.airbnb.ca/rooms/16039481?locale=en。通过链接可以发现之所以比平均价贵出约100倍,主要是因为这处房屋是多伦多最时尚的社区中的艺术收藏家阁楼。这些艺术收藏的价值大幅的拉高了这处房源的价格,使其和平均值有100倍的差距)

如果需要查看一下最大值或者最小值对应的记录,可以使用argmax或者argmin如下代码
listings.iloc[np.argmax(listings['price'])]
- 1
输出结果如下:(通过name信息可以核实,这份房源就是属于Art Collector艺术收藏品 )

由于在数据分析中,我们需要服从正态分布的原则,对于这样极端情况的存在,我们需要进行清理,所以把异常的价格的数据进行过滤,最终选择的价钱是保留0-600之间的数据。具体要选取某一数值,需要看一下当前数值以上对应的房源信息数量占全体的比重,这里选取大于600以上的房源仅有200+套,占总比1w+的比例很小,而且房源免费的只有7套

去掉极端值后我们继续观察现在的价格分布状态,绘制直方图
plt.figure(figsize=(12,6))
listings.loc[(listings.price <= 600) & (listings.price > 0)].price.hist(bins=200)
plt.ylabel('Count')
plt.xlabel('Listing price')
plt.title('Histogram of listing prices')
- 1
- 2
- 3
- 4
- 5
输出结果如下:(分箱数量bins可以自由指定,可以看出价格主要是在30-200之间)

3.7 不同社区与房源价格的关系
前面探究了不同社区和房源数量之间的关系,这里可以进一步探究不同社区和房源价钱之间的关系
plt.figure(figsize=(18,10))
sort_price = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('neighbourhood_cleansed')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='neighbourhood_cleansed', data=listings.loc[(listings.price <= 600) & (listings.price > 0)],
order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果如下:(最好的社区不仅房源的最高价高,而且平均价格也是所有社区中最高的,很有代表性)

3.8 品质房和普通房
在预定酒店时,浏览页面中常常会推出品质房源和普通房源,在这份数据集中也是存在字段记录这方面的信息,可以对比研究一下两者的价钱情况
sns.boxplot(y='price', x='host_is_superhost', data=listings.loc[(listings.price <= 600) & (listings.price > 0)])
plt.show()
- 1
- 2
输出结果如下:(品质房源要比普通房源的价格要高)

3.8 配套设施和房价的关系
酒店中的软装特性和多少也是和房源的价钱有着密切的关系,可以依循探究不同社区的房源价格的方式进行分析,代码基本上进行字段的修改就可以
plt.figure(figsize=(18,10))
sort_price = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('property_type')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='property_type', data=listings.loc[(listings.price <= 600) & (listings.price > 0)], order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果如下:(在今后绘制此类图形时候,代码可以直接复制后修改对应的字段和限制的范围即可。从这个图中可以看到在数据处理时,如果对于极端值不进行处理,则会显示出这样怪异的情况,例如Aparthotel 公寓式酒店 这个关键词的价格最高,但是通过boxplot我们又可以看出,其实只有一套这样的房产,所以数据并不完整。tend(帐篷)和parking space (停车位)这样的关键词也是数量很少的,导致了数据结果显示不准确)

根本原因就是分类中的数据值太少了,可以通过value_counts()进行查看。对于这种数值偏少的分类也可以设定一个数值作为分界点进行提取,或者根据展示需求直接提取前5、前10、前15的数据

3.9 房型和房价的关系
在租房时候,有整租有合租,还存在一些多人共用一间的情况(有点类似青年旅社),可以尝试性探究不同的房型与房价之间的关系
sort_price = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('room_type')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='room_type', data=listings.loc[(listings.price <= 600) & (listings.price > 0)], order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果如下:(整租价格最贵,其次是合租,最便宜的就是多人共用)

除了查看字段中各房型的房价信息,也可以逆向思维,根据价格来看不同房型的出租的多少,通过堆叠图来尝试探究
listings.loc[(listings.price <= 600) & (listings.price > 0)].pivot(columns = 'room_type',
values = 'price').plot.hist(stacked = True, bins=100)
plt.xlabel('Listing price')
- 1
- 2
- 3
输出结果如下:(有个明显的分界线,就是在100前后整租房的出租的数量和其它两种房型存在着较大的差距,100之前合租占据较大的比例,但是100以后就是整租的绝对优势了)
3.10 配套设施必备类型
酒店中房间的配套设施,比如wifi,卫生间,开窗,24小时热水等条件,尝试探究出租房中必备的配套设施都有哪些,首先对amenities字段的数据进行清洗,提取里面的具体设施
listings['amenities'].head()
listings.amenities = listings.amenities.str.replace("[{}]", "").str.replace('"', "")
listings['amenities'].head()
- 1
- 2
- 3
- 4
- 5
输出结果如下:(需要对花括号和引号进行去除,最后就是按照逗号进行分割)

找出前20个最重要的便利设施
pd.Series(np.concatenate(listings['amenities'].map(lambda amns: amns.split(","))))\
.value_counts().head(20)\
.plot(kind='bar')
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right', fontsize=12)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:(Wifi 暖气 厨房等便利设施是最重要的部分。这一部分有个很常用的功能,就是对一个字段中多项元素进行合并后进行统计计数后绘制图像)

配套设施和房价之间的关系。理解下面的前三行代码将会有不少的收获
#获取字段中的唯一元素
amenities = np.unique(np.concatenate(listings['amenities'].map(lambda amns: amns.split(","))))
#对包含的元素进行统计求平均值,排除空值
amenity_prices = [(amn, listings[listings['amenities'].map(lambda amns: amn in amns)]['price'].mean()) for amn in amenities if amn != ""]
#按照元素作为索引,平均价格作为值
amenity_srs = pd.Series(data=[a[1] for a in amenity_prices], index=[a[0] for a in amenity_prices])
#绘制前20的条形图
amenity_srs.sort_values(ascending=False)[:20].plot(kind='bar')
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right', fontsize=12)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果如下:(前两行代码也是很实用的功能,实现字段中包含的元素的进行统计求平均的过程,结果就是可以得到元素和对应的价格均值)

3.11 床位的数量和房价的关系
listings.loc[(listings.price <= 600) & (listings.price > 0)].pivot(columns = 'beds',values = 'price').plot.hist(stacked = True,bins=100)
plt.xlabel('Listing price in $')
- 1
- 2
输出结果如下:(先查看各出租房汇总不同床位出现的数量分布,主要集中在1,2,3,价钱也主要在0-200区间范围内)

然后查看一下每种床位数量的价格关系如下
sns.boxplot(y='price', x='beds', data = listings.loc[(listings.price <= 600) & (listings.price > 0)])
plt.show()
- 1
- 2
输出结果如下:(在这份数据中惊人的发现居然没有床的房屋价格比有2张床的房屋价格还要贵)

3.12 关联关系探索
之前的尝试性探索都是在指定两个字段,然后进行两两分析。可以通过columns查看一下所有的字段名称,输出如下

两两单独挑出来的字段进行分析就是基于常识,日常中都已经在大脑中潜意识认为这两个字段可能有所关联,如果一直使用这种方式很难挖掘出潜在的有价值信息,因此就可以借助pairplot绘制多字段的两两对比图或者heatmap热力图探究潜在的关联性
col = ['host_listings_count', 'accommodates', 'bathrooms', 'bedrooms', 'beds', 'price', 'number_of_reviews', 'review_scores_rating', 'reviews_per_month']
sns.set(style="ticks", color_codes=True)
sns.pairplot(listings.loc[(listings.price <= 600) & (listings.price > 0)][col].dropna())
plt.show()
- 1
- 2
- 3
- 4
输出结果如下:(只选取了部分字段)

进行热力图绘制,需要注意pairplot和heatmap绘制的图形都是只需要看主对角线上下一侧的图像即可,因为生成的图形是关于主对角线对称
plt.figure(figsize=(18,10))
corr = listings.loc[(listings.price <= 600) & (listings.price > 0)][col].dropna().corr()
plt.figure(figsize = (6,6))
sns.set(font_scale=1)
sns.heatmap(corr, cbar = True, annot=True, square = True, fmt = '.2f', xticklabels=col, yticklabels=col)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:(数字越接近1,说明字段之间的相关性越强,主对角线的数值不用看都是1)

热力图除了查看相关性外,还有一个重要的用处就是展示三个字段之间的关系,比如上面相关性图中可以看到价钱price字段和bathrooms床位以及bedrooms字段都有较强的关联关系,就可以使用热力图将三者的关系表现出来
plt.figure(figsize=(18,10))
sns.heatmap(listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby(['bathrooms', 'bedrooms'])\
.count()['price']\
.reset_index()\
.pivot('bathrooms', 'bedrooms', 'price')\
.sort_index(ascending=False),
cmap="Oranges", fmt='.0f', annot=True, linewidths=0.5)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果如下:(该热力图探究的是洗漱间和卧室的数量与房子数量的关系)
那么把count()改成mean(),就变成探究洗漱间和卧室的数量与房子平均价格之间的关系
plt.figure(figsize=(18,10))
sns.heatmap(listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby(['bathrooms', 'bedrooms'])\
.mean()['price']\
.reset_index()\
.pivot('bathrooms', 'bedrooms', 'price')\
.sort_index(ascending=False),
cmap="Oranges", fmt='.0f', annot=True, linewidths=0.5)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果如下:

4 特征工程
以上的内容就是传统的数据分析要完成的内容,分析的过程依赖于数据分析师本身的经验,而且结果都是以图表的形式进行展现,有一个痛点就是字段较多时候,要进行分析时就需要很多很多的图像,比如三个字段的分析,热力图就需要很多很多。此时就可以借助机器学习模型来探究,但是探究之前需要处理字段数据,进行特征工程。为了防止内存不足,建议在进行特征工程之前重新restart一下kernel,保证后续程序的正常运行,否则会提醒内存不足,程序报错
import pandas as pd
listings = pd.read_csv('toroto/listings.csv/listings.csv')
listings['price'] = listings['price'].str.replace(',', '')
listings['price'] = listings['price'].str.replace('$', '')
listings['price'] = listings['price'].astype(float)
listings = listings.loc[(listings.price <= 600) & (listings.price > 0)]
listings.amenities = listings.amenities.str.replace("[{}]", "").str.replace('"', "")
listings.amenities.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出结果如下:(数据读取之后将价格字段和设施字段还按照之前的处理方式进行预处理,注意这里程序运行后的标号,是restart之后的再次运行)

然后进行特征工程,先处理文本数据,将文本数据特征化,导入处理文本数据的模块,进行词向量转化
from sklearn.feature_extraction.text import CountVectorizer
count_vectorizer = CountVectorizer(tokenizer=lambda x: x.split(','))
amenities = count_vectorizer.fit_transform(listings['amenities'])
df_amenities = pd.DataFrame(amenities.toarray(), columns=count_vectorizer.get_feature_names())
df_amenities = df_amenities.drop('',1)
- 1
- 2
- 3
- 4
- 5
输出结果如下:(这一过程就是将amenities字段中所有的分类进行独热编码,然后形成DataFrame数据类型)

接着处理二分类字段,将true和false的分类替换成计算机识别的1和0分类。当存在多个二分类字段时候可以进行for循环统一进行数据转化,代码操作如下
columns = ['host_is_superhost', 'host_identity_verified', 'host_has_profile_pic',
'is_location_exact', 'requires_license', 'instant_bookable',
'require_guest_profile_picture', 'require_guest_phone_verification']
for c in columns:
listings[c] = listings[c].replace('f',0,regex=True)
listings[c] = listings[c].replace('t',1,regex=True)
- 1
- 2
- 3
- 4
- 5
- 6
接着对价钱相关的字段进行缺失值填充和噪音数据的清洗,最后不要忘记将数值的字段转化为浮点数。代码操作如下
listings['security_deposit'] = listings['security_deposit'].fillna(value=0)
listings['security_deposit'] = listings['security_deposit'].replace( '[\$,)]','', regex=True ).astype(float)
listings['cleaning_fee'] = listings['cleaning_fee'].fillna(value=0)
listings['cleaning_fee'] = listings['cleaning_fee'].replace( '[\$,)]','', regex=True ).astype(float)
- 1
- 2
- 3
- 4
并不是读取数据中的所有字段都有作用,比如在进行热力图判断字段之间的相关关系时,有些字段之间的相关关系的都是0,这些字段就可以直接被舍弃,选取有相关关系的字段重新组成一个数据集
listings_new = listings[['host_is_superhost', 'host_identity_verified', 'host_has_profile_pic','is_location_exact',
'requires_license', 'instant_bookable', 'require_guest_profile_picture',
'require_guest_phone_verification', 'security_deposit', 'cleaning_fee',
'host_listings_count', 'host_total_listings_count', 'minimum_nights',
'bathrooms', 'bedrooms', 'guests_included', 'number_of_reviews','review_scores_rating', 'price']]
- 1
- 2
- 3
- 4
- 5
接着就看一下这些字段中是不是还存在缺失值,上面只是进行了部分字段的处理,这里重现选取字段后仍然要进行缺失值的处理
for col in listings_new.columns[listings_new.isnull().any()]:
print(col)
- 1
- 2
输出结果如下:(说明还是有字段的缺失值未进行处理)
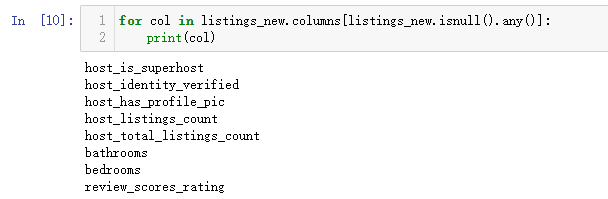
接着处理这部分字段的缺失值,按照中位数进行填充。当字段为分类字段时,填充的方式为中位数填充,前面处理的价格字段为连续字段,使用均值进行填充
for col in listings_new.columns[listings_new.isnull().any()]:
listings_new[col] = listings_new[col].fillna(listings_new[col].median())
- 1
- 2
然后对分类字段进行独热编码处理,并将编码后的结果与新数据进行合并
for cat_feature in ['zipcode', 'property_type', 'room_type', 'cancellation_policy', 'neighbourhood_cleansed', 'bed_type']:
listings_new = pd.concat([listings_new, pd.get_dummies(listings[cat_feature])], axis=1)
- 1
- 2
此时不要忘记最开始对文本编码的DataFrame数据,也需要进行合并,合并的方式为取交集,最终得到特征工程处理后的数据
listings_new = pd.concat([listings_new, df_amenities], axis=1, join='inner')
listings_new.head()
listings_new.shape
- 1
- 2
- 3
- 4
- 5
输出结果如下:(数据只剩下约1.7w,但是字段数量增加到了6000+)

5 机器学习
5.1 随机森林
特征工程完成后,就该进行机器学习模型的创建,首先使用随机森林回归模型进行建模,看看最终的效果如何。模型创建的过程以及评估的流程如下
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
y = listings_new['price']
x = listings_new.drop('price', axis =1)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state=1)
rf = RandomForestRegressor(n_estimators=500,
criterion='mse',
random_state=3,
n_jobs=-1)
rf.fit(X_train, y_train)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出结果如下:(x是没有标签的其余字段,y就是标签字段,切分数据集一般就按照七三开,这里按照训练集75%,测试集25%,随机种子状态设定为1。最后决策树模型设置500棵树,评价方式为均方差mse,随机种子状态为3,-1代表选择处理器性能全开)

训练过程会和选用的机器的性能相关,运行需要一定的时间,待运行完毕后就可以使用模型进行预测
y_train_pred = rf.predict(X_train)
y_test_pred = rf.predict(X_test)
rmse_rf= (mean_squared_error(y_test,y_test_pred))**(1/2)
print('RMSE test: %.3f' % rmse_rf)
print('R^2 test: %.3f' % (r2_score(y_test, y_test_pred)))
- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:(注意传入predict括号中的变量,传入X_train就对应得到训练集计算出来的预测标签,传入X_test就对应着测试集计算出来的预测标签,通过比对最终训练集和测试集的结果可以计算出最终的预测结果)

模型的预测结果出来之后,同时也可以查看模型得到的最重要的影响因素
coefs_df = pd.DataFrame()
coefs_df['est_int'] = X_train.columns
coefs_df['coefs'] = rf.feature_importances_
coefs_df.sort_values('coefs', ascending=False).head(20)
- 1
- 2
- 3
- 4
- 5
输出结果如下:(影响因素一列就为传入的字段的名称,影响的重要性,可以通过训练好的模型下面的feature_importances_属性获得)

5.2 LightGBM
只用一个模型建模获得结果没有对比性,无法判断最终的预测结果是好还是坏,因此在进行预测时候往往都不是只使用一个模型进行,而是采用至少两个模型进行对比,接下来就是使用LightGBM模型进行预测
需要先安装LightGBM模块,操作如下

然后从模块中导入回归模型,划分数据集后构建模型
from lightgbm import LGBMRegressor y = listings_new['price'] x = listings_new.drop('price', axis =1) X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state=1) fit_params={ "early_stopping_rounds":20, "eval_metric" : 'rmse', "eval_set" : [(X_test,y_test)], 'eval_names': ['valid'], 'verbose': 100, 'feature_name': 'auto', 'categorical_feature': 'auto' } X_test.columns = ["".join (c if c.isalnum() else "_" for c in str(x)) for x in X_test.columns] class LGBMRegressor_GainFE(LGBMRegressor): @property def feature_importances_(self): if self._n_features is None: raise LGBMNotFittedError('No feature_importances found. Need to call fit beforehand.') return self.booster_.feature_importance(importance_type='gain') clf = LGBMRegressor_GainFE(num_leaves= 25, max_depth=20, random_state=0, silent=True, metric='rmse', n_jobs=4, n_estimators=1000, colsample_bytree=0.9, subsample=0.9, learning_rate=0.01) #reduce_train.columns = ["".join (c if c.isalnum() else "_" for c in str(x)) for x in reduce_train.columns] clf.fit(X_train.values, y_train.values, **fit_params)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
输出结果如下:

如果显示上放的输出结果说明模型训练成功,但是过程并不一定会一帆风顺,可能会运行报错如下:TypeError: Cannot interpret '<attribute 'dtype' of 'numpy.generic' objects>' as a data type,此时可以升级一下pandas和numpy的版本,比如将pandas升级到1.2.4,numpy升级到1.20.2。然后重新运行当前的notebook就可以完美解决这个问题

接着就可以使用训练好的模型进行预测并查看模型得分,顺带可以将重要的影响因素进行可视化
y_pred = clf.predict(X_test.values)
print('R^2 test: %.3f' % (r2_score(y_test, y_pred)))
feat_imp = pd.Series(clf.feature_importances_, index=x.columns)
feat_imp.nlargest(20).plot(kind='barh', figsize=(10,6))
- 1
- 2
- 3
- 4
- 5
输出结果如下:(使用LightGBM模型进行预测的得分要比随机森林模型最终的得分要高,说明此数据集较适用于LightGBM模型)

最后对比两个模型最终给出的重要影响因素,可以发现前五个都是一样的,只是顺序上存在着不同。此外关于模型具体的讲解会在后续的机器学习部分详细介绍,这里就是明确数据分析案例的流程,知道如何进行模块的调用创建模型和预测

