
- 1unity基础(5)——安装配置Visual Studio_unity安装visual studio2019
- 2turn.js 试用
- 3HarmonyOS开发实战之认证服务 (auth in Serverless by ArkTS)_arkts 用户注册代码
- 4使用Truffle for Vscode插件部署本地智能合约_vscode以太坊开发
- 5微信小程序设置 tabbar icon 大小_微信小程序tabbar图标大小
- 6Vue中使用百度地图Vue Baidu Map —— 获取当前位置_vue3中vue-baidu-map-3x获取当前位置
- 7Mixed Content: The page at ‘<URL>‘ was loaded over HTTPS, but requested an insecure script ‘<URL>‘.
- 8pygame windows下载安装方法_pygame库下载
- 9U3D对话任务插件 Dialogue System for Unity 研究(一)_dialogue system of unity插件介绍
- 10MySQL数据表的约束
近端策略优化(PPO)
赞
踩
Proximal Policy Optimization(PPO)
一.同策略和异策略
如果要学习的智能体和与环境交互的智能体是相同的,我们称之为同策略。如果要学习的智能体和与环境交互的智能体不是相同的,我们称之为异策略。
为什么我们会想要考虑异策略?让我们回忆一下策略梯度。策略梯度是同策略的算法,因为在策略梯度中,我们需要一个智能体、一个策略和一个演员。演员去与环境交互搜集数据,搜集很多的轨迹 τ,根据搜集到的数据按照策略梯度的公式更新策略的参数,所以策略梯度是一个同策略的算法。PPO 是策略梯度的变形,它是现在 OpenAI 默认的强化学习算法。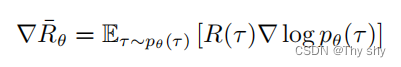
问题在于上式Eτ∼pθ(τ) 是对策略 πθ 采样的轨迹 τ 求期望。一旦更新了参数,从 θ 变成 θ′ ,概率 pθ(τ ) 就不对了,之前采样的数据也不能用了。所以策略梯度是一个会花很多时间来采样数据的算法,其大多数时间都在采样数据。智能体与环境交互以后,接下来就要更新参数。我们只能更新参数一次,然后就要重新采样数据,才能再次更新参数。这显然是非常花时间的,所以我们想要从同策略变成异策略,这样就可以用另外一个策略 πθ′、另外一个actor θ′ 与环境交互(θ′ 被固定了),用 θ′ 采样到的数据去训练θ。假设我们可以用 θ′ 采样到的数据去训练 θ,我们可以多次使用 θ′ 采样到的数据,可以多次执行梯度上升(gradient ascent),可以多次更新参数,都只需要用同一批数据。因为假设 θ 有能力学习另外一个actorθ′ 所采样的数据,所以 θ′ 只需采样一次,并采样多一点的数据,让 θ 去更新很多次,这样就会比较有效率。
二.重要性采样
重要性采样是,使用另外一种分布来逼近所求分布一种方法。假设我们有一个函数 f(x),要计算从分布 p 采样 x,再把 x 代入 f ,得到 f(x)。我们该怎么计算f(x) 的期望值呢?假设我们不能对分布 p 做积分,但可以从分布 p 采样一些数据 xi。把 xi 代入 f(x),取它的平均值,就可以近似 f(x) 的期望值。如下式所示
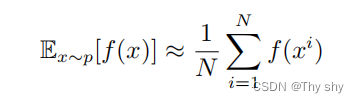
现在有另外一个问题,假设我们不能从分布 p 采样数据,只能从另外一个分布 q 采样数据 x,q 可以是任何分布。如果我们从 q 采样 xi,就不能使用上式,因为上式是假设 x 都是从 p 采样出来的。

我们就可以写成对 q 里面所采样出来的 x 取期望值。我们从 q 里面采样 x,再计算f\left( x\right) \dfrac{p\left( x\right) }{q\left( x\right) }f(x)q(x)p(x),再取期望值。所以就算我们不能从 p 里面采样数据,但只要能从 q 里面采样数据,就可以计算从 p 采样 x 代入 f以后的期望值。
重要性采样有一些问题。虽然我们可以把 p 换成任何的 q。但是在实现上,p 和 q 的差距不能太大。差距太大,会有一些问题。
三.重要性采样应用到PPO
现在要做的就是把重要性采样用在异策略的情况中,把同策略训练的算法改成异策略训练的算法。怎么改呢?如下式所示,之前我们用策略 πθ 与环境交互,采样出轨迹 τ,计算 R(τ )∇ log pθ(τ )。现在我们不用 θ 与环境交互,假设有另外一个策略 π′θ,它就是另外一个actor,它的工作是做示范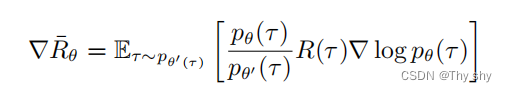
θ′ 的工作是为 θ 做示范。它与环境交互,告诉 θ 它与环境交互会发生什么事,借此来训练 θ。我们要训练的是 θ ,θ′ 只负责做示范,负责与环境交互。我们现在的 τ 是从 θ′ 采样出来的,是用 θ′ 与环境交互。所以采样出来的 τ 是从 θ′ 采样出来的,这两个分布不一样。我们本来要从p采样,但发现不能从 p 采样,所以我们不用 θ 与环境交互,可以把 p 换成 q,在后面补上一个重要性权重。
在做策略梯度的时候,实际更新梯度的过程可写为

我们可以通过重要性采样把同策略变成异策略,从 θ 变成 θ′。
根据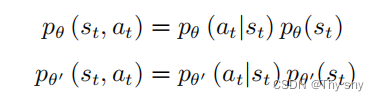
可以化简为

假设模型是 θ 的时候,我们看到 st 的概率,与模型是 θ′ 的时候,我们看到 st 的概率是一样的,即 pθ(st) = pθ′ (st)。因为 pθ(st) 和 pθ′ (st) 是一样的,所以我们可得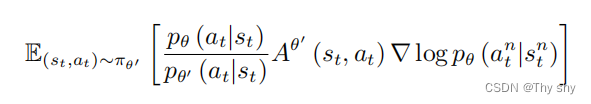
再带入
可以推导出,当我们使用重要性采样的时候,要去优化的目标函数为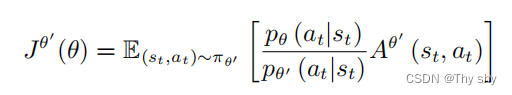
四.近端策略优化
重要性采样有一个问题:如果 pθ (at|st) 与 pθ′ (at|st)相差太多,即这两个分布相差太多,重要性采样的结果就会不好。怎么避免它们相差太多呢?这就是 PPO要做的事情。
在训练的时候,应多加一个约束(constrain)。这个约束是 θ 与 θ′ 输出的动作的 KL 散度(KL divergence),这一项用于衡量 θ 与 θ′ 的相似程度。我们希望在训练的过程中,学习出的 θ 与 θ′ 越相似越好。因为如果 θ 与 θ′ 不相似,最后的结果就会不好。添加约束如下式所示。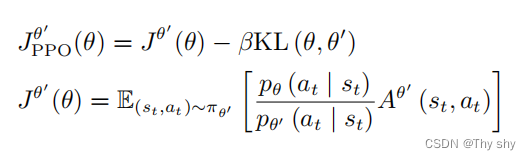
KL 散度到底指的是什么?这里我们直接把 KL 散度当作一个函数,输入是 θ 与 θ′,但并不是把 θ 或 θ′ 当作一个分布,计算这两个分布之间的距离。所谓的 θ 与 θ′ 的距离并不是参数上的距离,而是行为(behavior)上的距离。假设我们有两个演员——θ 和 θ′,所谓参数上的距离就是计算这两组参数有多相似。这里讲的不是参数上的距离,而是它们行为上的距离。行为距离(behavior distance)就是,给定同样的状态,输出动作之间的差距。这两个动作的分布都是概率分布,所以我们可以计算这两个概率分布的 KL 散度。把不同的状态输出的这两个分布的 KL 散度的平均值就是我们所指的两个演员间的 KL 散度。
五.PPO算法变种
近端策略优化惩罚(PPO-penalty)
近端策略优化惩罚算法。它先初始化一个策略的参数 θ0。在每一个迭代里面,我们用前一个训练的迭代得到的演员的参数 θk 与环境交互,采样到大量状态-动作对。根据 θk交互的结果,我们估测 Aθk (st, at)。我们使用 PPO 的优化公式。但与原来的策略梯度不一样,原来的策略梯度只能更新一次参数,更新完以后,我们就要重新采样数据。但是现在不同,我们用 θk 与环境交互,采样到这组数据以后,我们可以让 θ 更新很多次,想办法最大化目标函数,如式所示。这里面的 θ更新很多次也没有关系,因为我们已经有重要性采样,所以这些经验,这些状态-动作对是从 θk 采样出来的也没有关系。θ 可以更新很多次,它与 θk 变得不太一样也没有关系,我们可以照样训练 θ。
在 PPO 的论文里面还有一个自适应 KL 散度(adaptive KL divergence)。这里会遇到一个问题就,即 β 要设置为多少。这个问题与正则化一样,正则化前面也要乘一个权重,所以 KL 散度前面也要乘一个权重,但 β 要设置为多少呢?我们有一个动态调整 β 的方法。在这个方法里面,我们先设一个可以接受的 KL 散度的最大值。假设优化完 以后,KL 散度的值太大,这就代表后面惩罚的项没有发挥作用,我们就把 β 增大。另外,我们设一个 KL 散度的最小值。如果优化完以后,KL 散度比最小值还要小,就代表后面这一项的效果太强了,我们怕他只优化后一项,使 θ 与 θk一样,这不是我们想要的,所以我们要减小 β。β 是可以动态调整的,因此我们称之为自适应 KL 惩罚
近端策略优化裁剪(PPO-clip)
最大化的目标函数为
核心目的是不让 pθ(at|st) 与 pθk (at|st) 差距太大。

