- 1基于Java+SpringBoot+Vue前后端分离婚纱影楼管理系统设计和实现_springboot vue婚纱影楼系统
- 2保姆级教程-如何使用LLAMA2 大模型_如何调用 llama 的 api
- 3Jenkins忘记密码解决方案_jenkins忘记用户名和密码
- 4《Python编程:从入门到实践》第12章:武装飞船_python入门到实践中的 ship.bmg
- 52023美赛E题_2023美赛e题 背景 光污染是用来描述任何过度或不良的使用人工光。一些我们称之为
- 6MYSQL 8 UNDO 表空间 你了解多少
- 7vs code解决无法识别已安装python库的问题(Mac版)
- 8初始MyBatis,w字带你解MyBatis
- 9video 标签设置样式_video标签样式
- 10如何在论文中画出漂亮的插图?
【LLM_01】ChatGLM2-6B本地安装与部署(大语言模型)_本地部署 解压即用 大语言模型
赞
踩
1、简介
(1)ChatGLM2-6B
ChatGLM2-6B是一个开源的、支持中英双语的对话语言模型,基于General Language Model (GLM)架构。
ChatGLM2-6B具备的能力:
- 自我认知:“介绍一下你的优点”
- 提纲写作:“帮我写一个介绍ChatGLM的博客提纲”
- 文案写作:“写10条热评文案”
- 信息抽取:‘从上述信息中抽取人、时间、事件’
大语言模型通常基于通识知识进行训练,因此在面向如下场景时,常常需要借助模型微调或提示词工程提升语言模型应用效果:
- 垂直领域知识
- 基于私有数据的问答

(2)LangChain
LangChain是一个用于开发由语言模型驱动的应用程序的框架。
主要功能:
- 调用语言模型
- 将不同数据源接入到语言模型的交互中
- 允许语言模型与运行环境交互
LangChain中提供的模块
- Modules:支持的模型类型和集成。
- Prompt:提示词管理、优化和序列化。
- Memory:内存是指在链/代理调用之间持续存在的状态。
- Indexes:当语言模型与特定于应用程序的数据相结合时,会变得更加强大-此模块包含用于加载、查询和更新外部数据的接口和集成。
- Chain:链是结构化的调用序列(对LLM或其他实用程序)。
- Agents:代理是一个链,其中LLM在给定高级指令和一组工具的情况下,反复决定操作,执行操作并观察结果,直到高级指令完成。
- Callbacks:回调允许您记录和流式传输任何链的中间步骤,从而轻松观察、调试和评估应用程序的内部。
LangChain的运用场景:
- 文档问答
- 个人助理
- 查询表格数据
- 与API交互
- 信息提取
- 文档总结
(3)基于单一文档问答的实现原理
1、加载本地文档:读取本地文档加载为文本
2、文本拆分:将文本按照字符、长度或语义进行拆分
3、根据提问匹配文本:根据用户提问对文本进行字符匹配或语义检索
4、构建Prompt:将匹配文本、用户提问加入Prompt模板
5、LLM生成回答:将Pronpt发送给LLM获得基于文档内容的回答
(4)大规模语言模型系列技术:以GLM-130B为例
- 自编码模型BERT:双向注意力,文本理解
- 自回归模型GPT:单向注意力,长文本生成
- 编码器-解码器模型T5:编解码,对话任务

GLM本质是类似一个自回归填空的过程
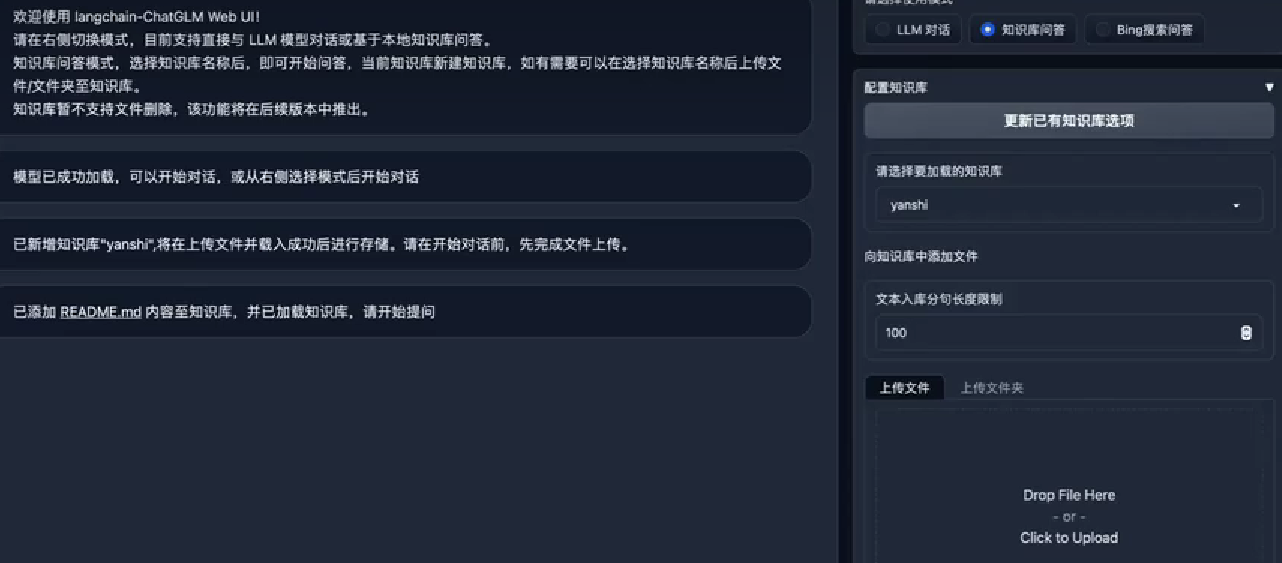
(5)新建知识库
新建知识库的过程相当于在本地新建一个路径,因此不支持路径当中存在中文。但是知识库的文件可以使用中文名称。
1、上传文件:将文件上传到知识库当中,这个过程相当于将文件加载成文本并进行向量化的过程。
(6)效果优化方向
1、模型微调:对llm和embedding基于专业领域数据进行微调。
2、文档加工:在文本分段后,对每段分别进行总结,基于总结内容语义进行匹配。
3、借助不同的模型能力:在text2sql、text2cpyher场景下需要产生代码时,可借助不同模型能力。
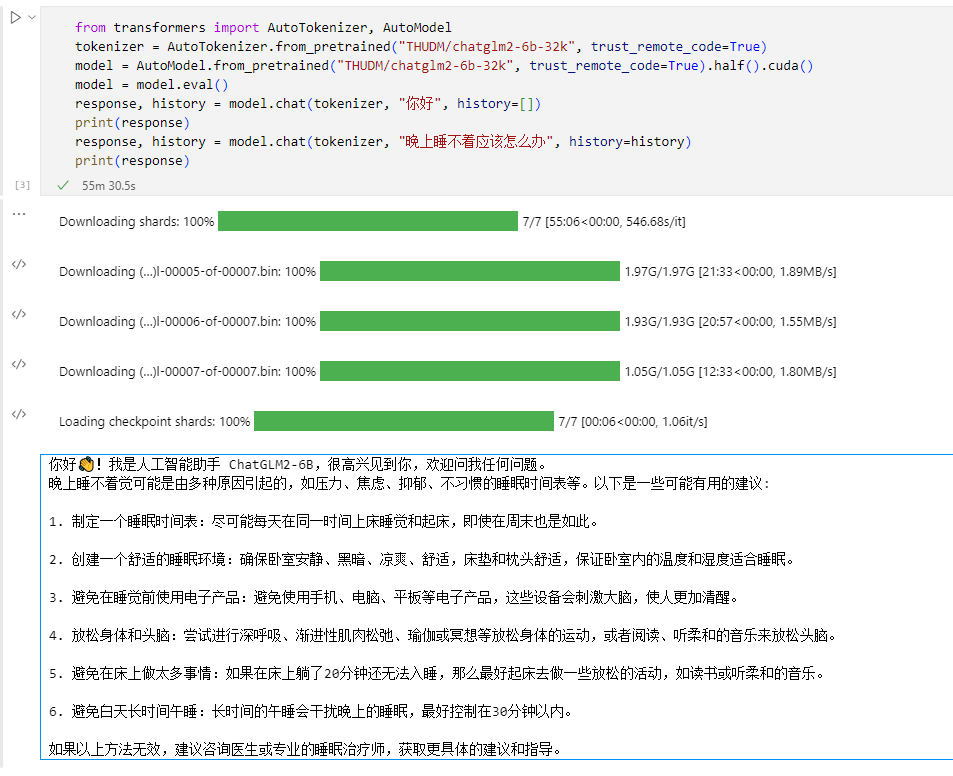
2、ChatGLM2-6B本地安装与部署
视频教程:视频教程:----->ChatGLM2-6B本地安装与部署-视频教程

注意 :chatglm2-6b相比于chatglm-6b在性能上提升了不少。在选择本地部署的时候,我查看到自己显卡只有512M,无法满足部署需要的24G显卡的要求。(注:查看显卡多大可以安装一个lu大师),因此我选择在某宝上租用了一个24G的GPU。
部署步骤如下:
1、根据视频上面的,先下载懒人安装包:懒人包一键部署
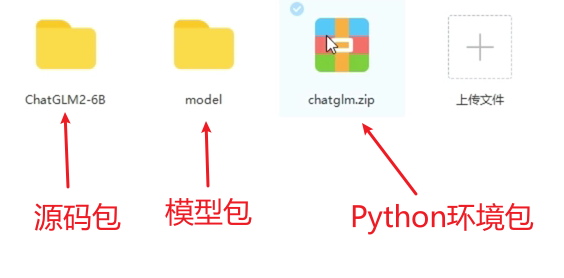
2、将chatglm.zip安装包解压缩之后放在ChatGLM2-6B文件夹下面
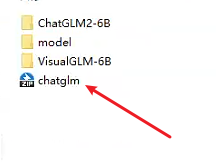
3、创建一个叫VisualGLM-6B的文件夹,在此文件夹里面再创建一个叫cache的文件夹
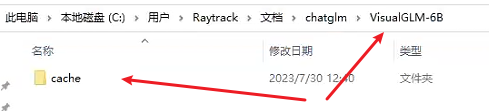
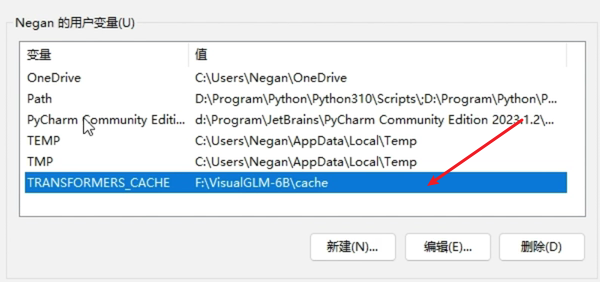
4、配置缓存文件
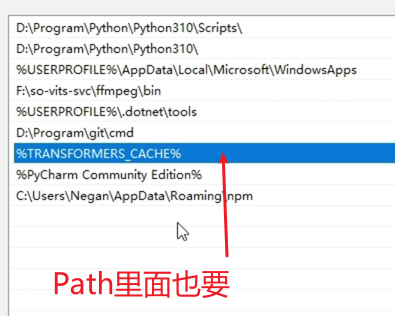
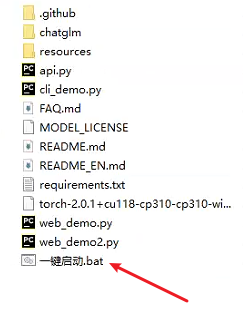
5、之后点击一键启动,启动项目
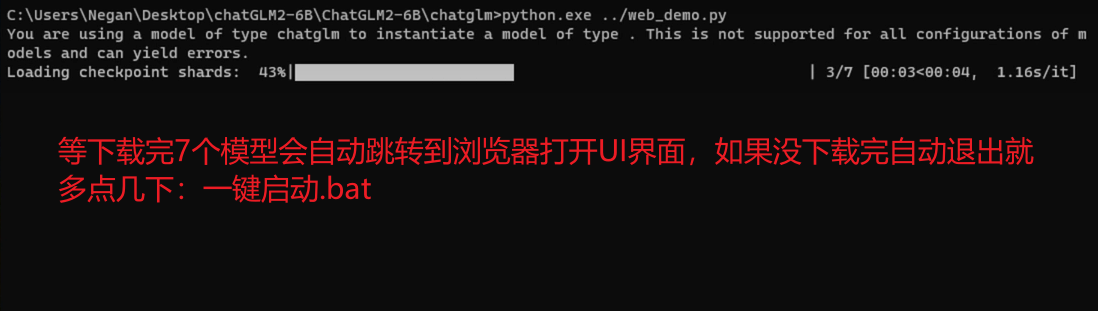
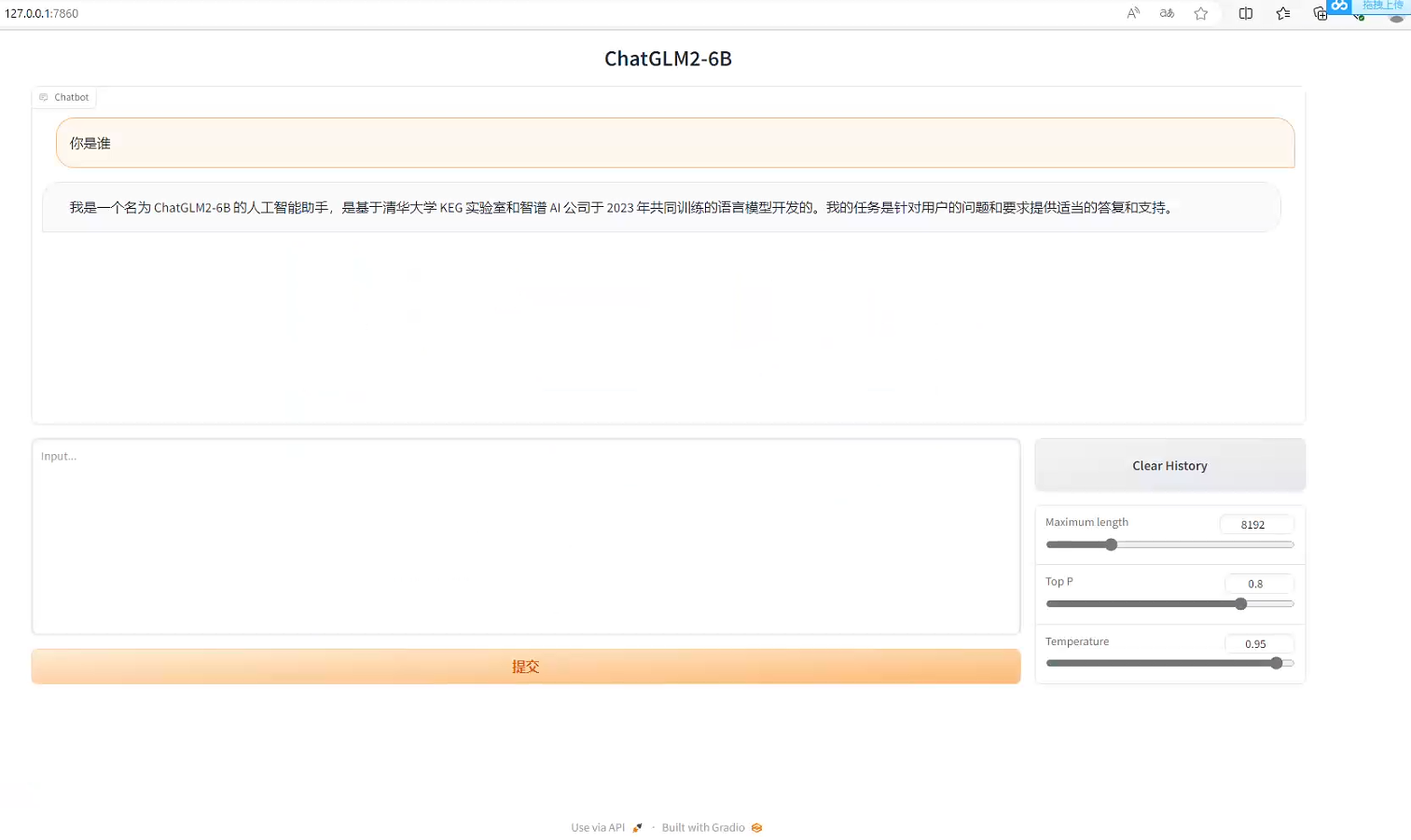
最终即可跳转到UI界面:
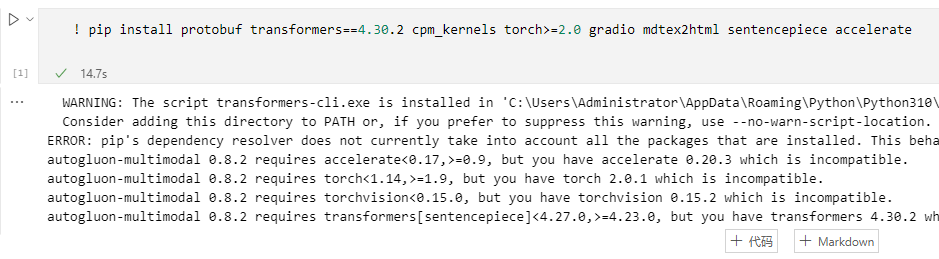
注:如果要自己部署请确保pytorch是2.0.1
3、ChatGLM2-6B-32K本地安装
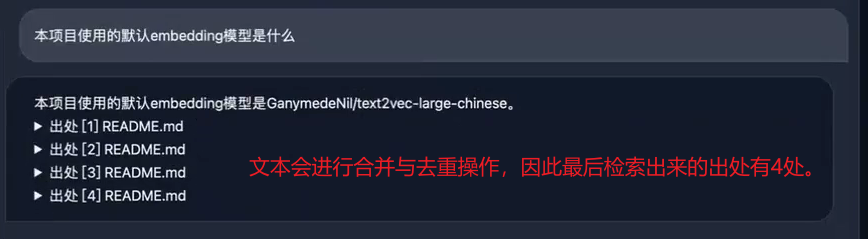
2023年8月3号GLM技术团队发布了基于 ChatGLM2-6B 的新模型 ChatGLM-6B-32k ,目前 langchain-chatglm 项目中已经可以使用,除此之外项目中还增加几款 embedding 模型作为备选,text2vec-base-multilingual,text2vec-base-chinese-sentence 和 text2vec-base-chinese-paraphrase。
此外,项目将于近期发布 0.2.0 版本,采用 fastchat + langchain + fastapi + streamlit 的方式进行了重构,预计最快本周上线。
模型下载地址:
chatglm2-6b-32k:https://huggingface.co/THUDM/chatglm2-6b-32k
text2vec-base-chinese-sentence:https://huggingface.co/shibing624/text2vec-base-chinese-sentence
text2vec-base-chinese-paraphrase:https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase
text2vec-base-multilingual:https://huggingface.co/shibing624/text2vec-base-multilingual