- 1UIWebView和WKWebView
- 2Linux笔记--查看Linux系统自动Kill掉的进程_linux查看进程被杀掉原因
- 3c++ 报错 error: call of overloaded ‘abs(unsigned int)’ is ambiguous
- 4教你如何实现长按图片保存到相册_开启app允许长按保存图片
- 5怎么在Anaconda上更换python版本_anaconda更改新安装的python版本
- 6【目标检测】YOLO v1 (You Only Look Once) 详细解读
- 7UE5笔记【五】操作细节——光源、光线参数配置、光照图修复_ue5光照需要重建
- 8DELL服务器创建raid_戴尔服务器做raid
- 9Kubernetes 持久卷_volumeclaimtemplates
- 10【计算机网络常见面试题】电信网络的分类_电信网络类型分类的理解
[入门篇]Linux操作系统fork子进程的创建以及进程的状态 超超超详解!!!我不允许有人错过!!!_linux操作系统实验教程fork实验
赞
踩
目录
0.前言
上一篇博客我们解决了什么是进程(大格局了解进程),尤其是对进程运行原理以及进程控制块PCB的理解,本文我们将以此为基础,着重讲解子进程的创建和进程的状态,绝对也是干货爆满。
本篇博客的所有相关实验代码已上传至Gitee,请君自取: practice8 · onlookerzy123456qwq/Linuxtwo - 码云 - 开源中国 (gitee.com)https://gitee.com/onlookerzy123456qwq/linuxtwo/tree/master/practice8下面正文开始!!!
1.fork()创建子进程讲解
1.1fork()的简单介绍
我们之前创建进程的方式就是在一个路径下 ./proc 执行一个程序,将该程序加载到内存执行起来,在程序中就会创建一个进程。当然我们也知道创建一个进程就意味着在内存中载入了该进程的代码和数据,以及OS为该进程创建的进程控制块task_struct。
因为 进程==相关内核数据结构+进程的资源代码和数据
以上我们是用户主动执行创建一个进程,那我们如何在代码当中,在一个进程当中执行语句让进程自己去再创建一个新的进程呢?这就用到了我们的fork了!!!
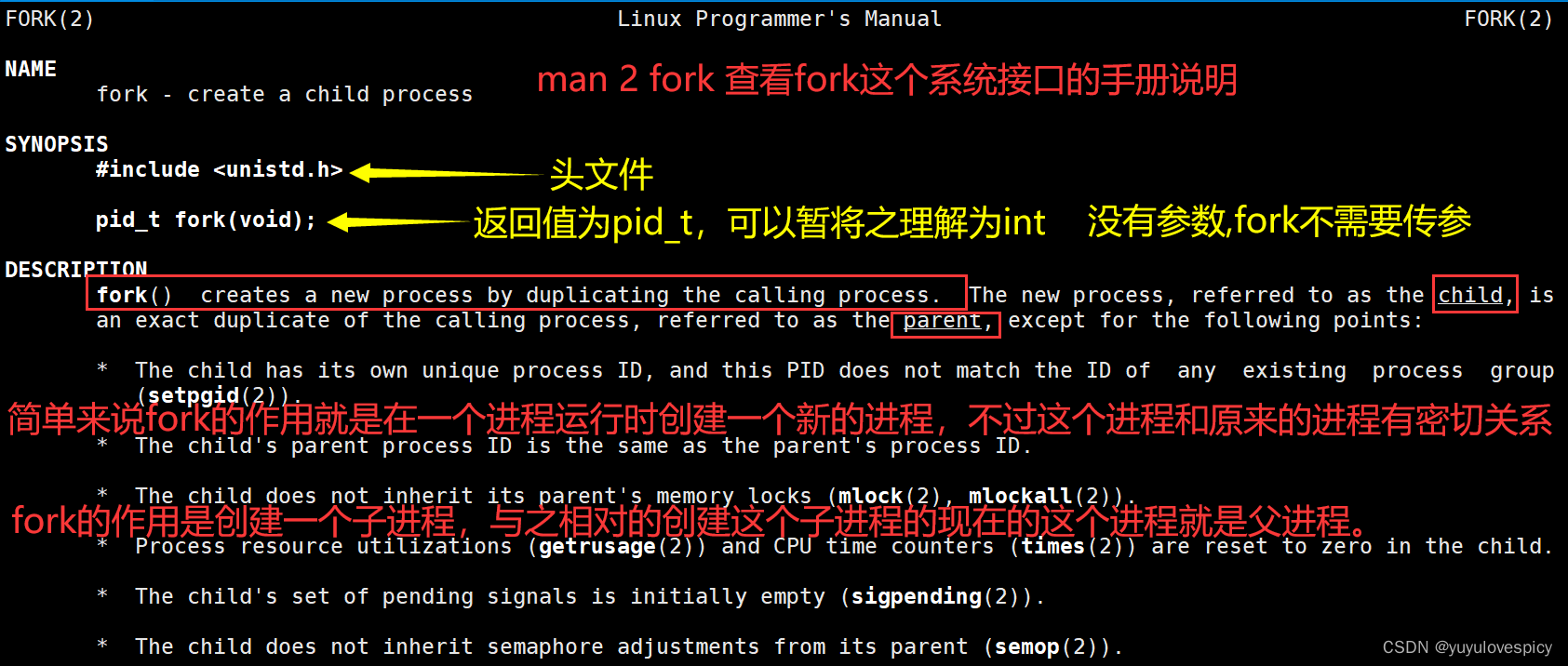
首先fork()是Linux操作系统中的一个系统调用接口,其作用是创建子进程,创建进程就意味着为这个子进程创建一个PCB数据结构,但是这里子进程是比较特殊的,子进程和父进程有密切的关系,子进程的代码和数据其实是很有讲究的,这个我们在后面讲述。
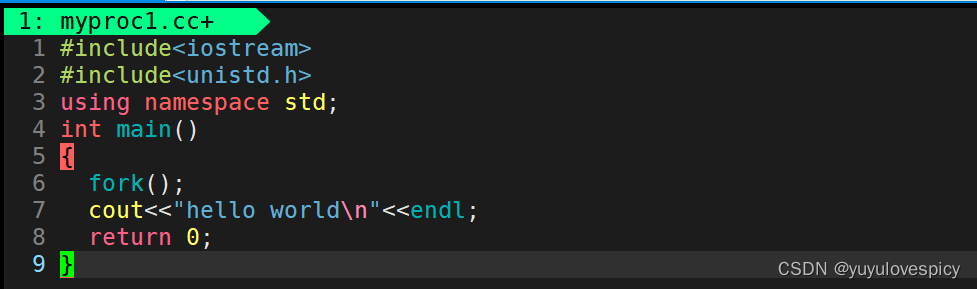
总之我们明确一件事,fork的作用就是能够在代码运行时创建一个新的进程,我们将之称之为当前进程的子进程,其实也就意味着现在内存中多了一个进程,即多了一个执行流。下面我们来体验一下fork的作用:
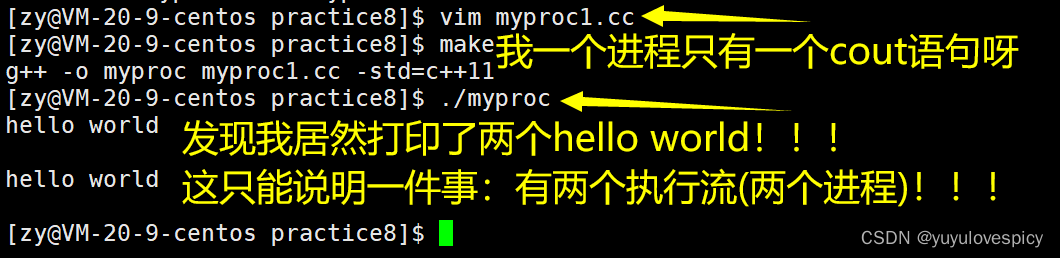
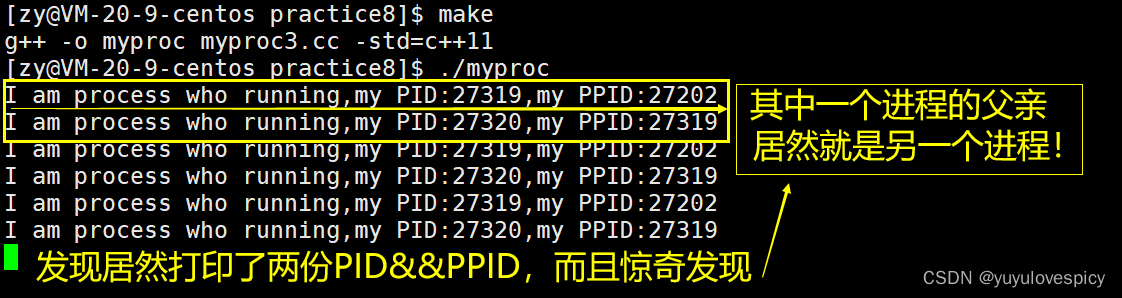
展示1:
展示2:
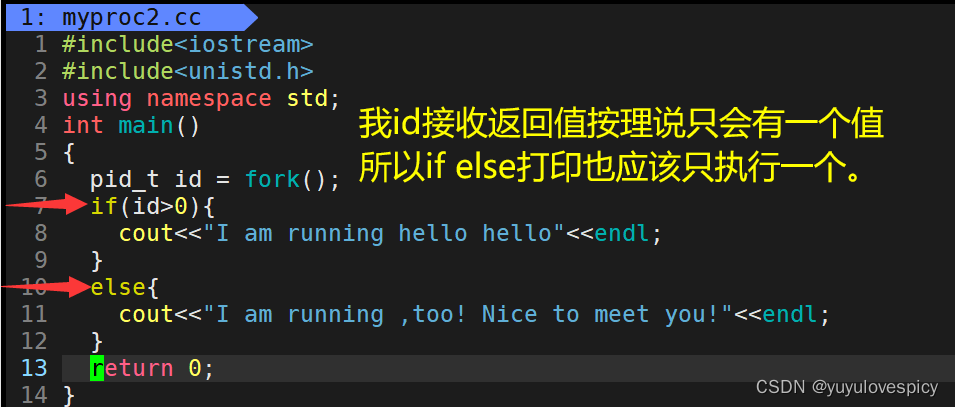
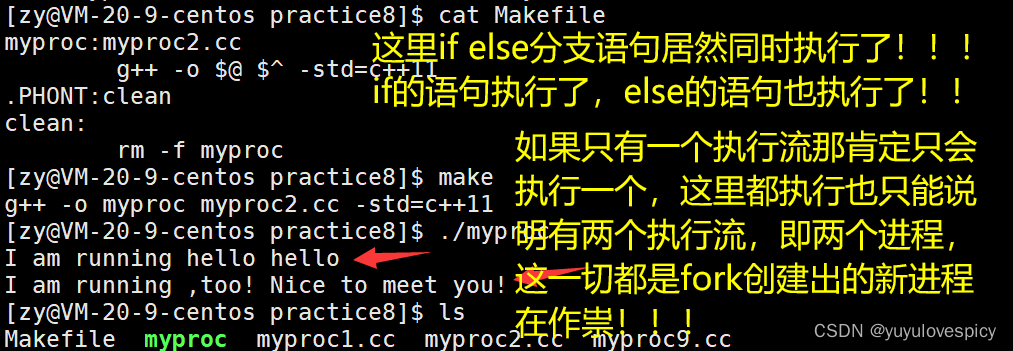
展示3:
打印了两份消息,打印出来的消息是不同的, 可是进程中的代码当中我们只cout了一次,为什么能打印出来两种内容呢,我们观察pid ppid发现这是父子进程的关系。其实真正的原因只有一个,那就是Fork创建的子进程在运行,而原来的父进程也在运行,这是两个进程都在运行,即两个程序在“同时”跑!一个进程的的在打印它的PID,PPID,另一个进程在打印它的PID,PPID。
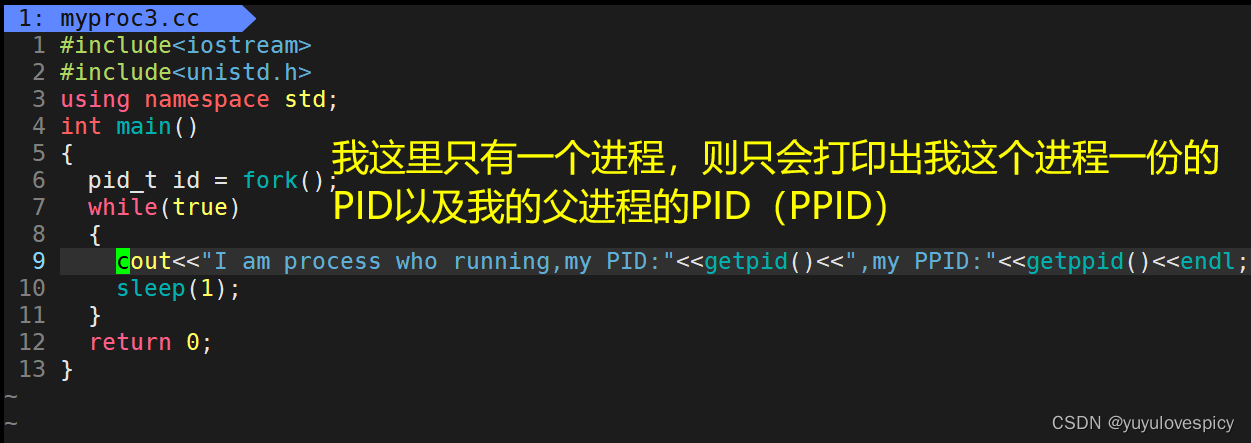
1.2 创建子进程详解
1.2.1 如何理解fork创建子进程
1.我们 ./proc 运行起来一个程序 或者是 在进程中 fork() , 其本质上都是一样的,在操作系统的层面都是在创建一个进程,而且在上面创建进程的方式,是没有差别的。
2. fork()的本质是创建进程,那就一定会导致一个结果:系统里多了一个进程,而进程是什么,进程==与进程相关的内核数据结构task_struct + 进程的代码和数据。所以创建进程后理应在系统中多了一套子进程自己的PCB以及自己的代码和数据。
1.2.2 子进程的PCB以及子进程的代码和数据
这个创建的PCB其实就是针对fork()创建出的子进程,OS对之创建一个属于这个子进程的task_struct,从而OS可以管理task_struct数据结构的方式来管理这个子进程。这是一定的。
那话说回来,那子进程的代码和数据呢???答:子进程它的代码和数据,在默认情况下,会“继承”父进程的代码和数据。当然我们补充一点:内核数据结构task_Struct也会以父进程的task_Struct为模板,初始化子进程的task_Struct。
我们如何理解这一点呢?我们举一个生动的例子:
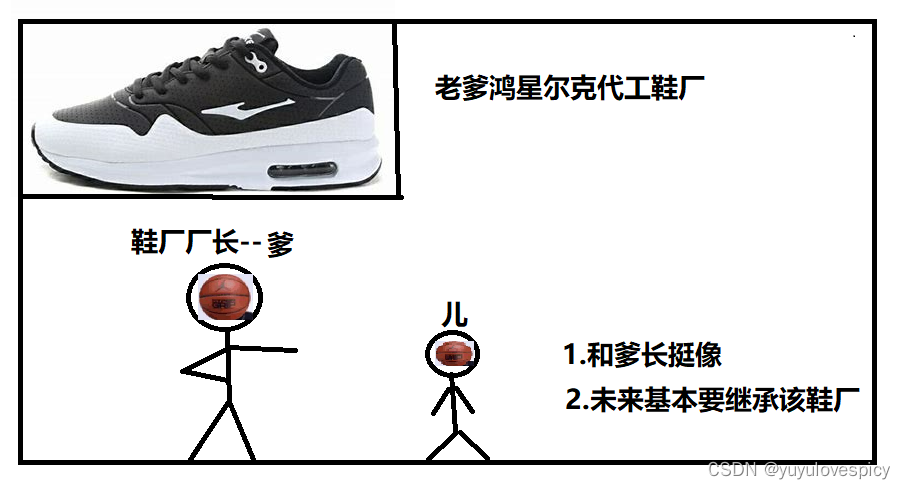
话说你爸其实是一个鞋厂的老板,举个例子,是ERKE鸿星尔克品牌的专业代工厂,从你诞生的那一刻起,基本上要发生两件事情。第一件事情,你的相貌会以你爹为模板为基础,我们要相信基因的力量,进而长出自己的模样,第二件事情,你以后也大概率会子承父业,继承你爹的鞋厂,继续当厂二代。(当然后续也可能你会自主创业,比如你自己又开了个自己品牌的鞋厂,这是也很有可能发生的,确实存在这种情况,但是我们暂不考虑)
相貌会以你爹为模板长出自己的样子,这是刻在自己基因里的东西,一定会影响到你的。而后续你的事业,大概会继承你爹开的的鞋厂做厂二代。
这里我们要看到你和你爹鞋厂用的是同一个鞋厂,你和你爹的五官样貌却是真真实实有两份的,不过都有继承。这里的鞋厂&&五官样貌,可以类比子进程的代码和数据&&内核数据结构。子进程的内核数据结构task_struct就是子进程的“五官样貌”,子进程一定会以父进程的task_struct为模板来创建出自己的task_struct。子进程的代码和数据就是鞋厂,这个鞋厂是父进程开创的,父子共用的是同一个鞋厂,子进程的代码和数据用的是父进程的那一份,此时父子进程共用同一份代码和数据!!!
当然如果后续你翅膀硬了,独立自主性强了,你自己开办了自己品牌的新鞋厂,这当然是可以的,此时就可以类比为,子进程和父进程不再共享同一份代码和数据,而是子进程也有了独属于自己的一份代码和数据。
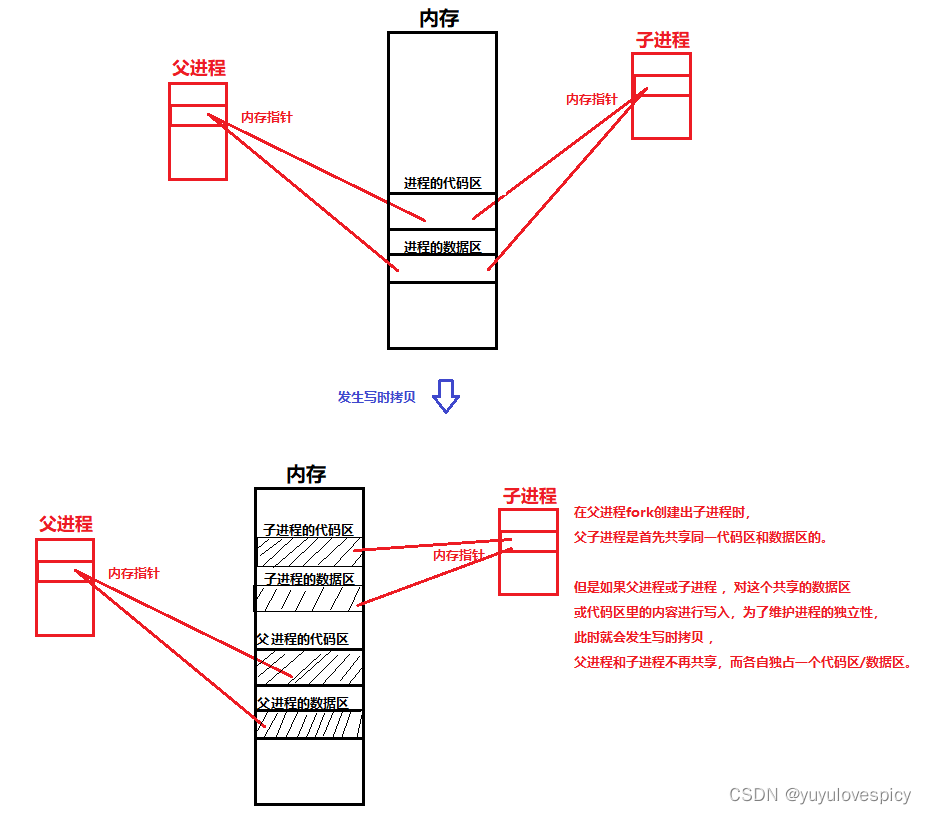
总结一下,刚刚被fork创建出的子进程,其内核数据结构task_struct是以父进程为模板创建出自己的PCB的,其代码和数据是一开始是共享父进程的代码和数据的,但是后续会因某种特定情况的发生不再共享,而父子进程各独占一份代码和数据。
那么这种特定的情况到底是什么呢???那就是发生写入!!!!!!!!!!!!!
父子进程一开始是共享同一份代码和数据的,如果此时某个进程(无论父进程还是子进程)在执行的时候,对这同一份数据区做出了写入操作,即修改了这份共享的数据区里的内容,那就会在写入之前把这块数据区先拷贝一份,父子进程不再共享同一块数据区,而是让这两个进程分别独占一份数据区,然后再哪个进程对他自己的数据区进行写入。这个现象还有一个响当当的名字----写时拷贝。
同理,如果父子进程现在在共享同一份代码段,当某个进程(无论父还是子)对这份共享的一个代码段进行了写入,即修改这块共享的代码段,那么此时就会在修改代码区之前,先把这块代码段拷贝一份,此时加上原来共享的代码段现在就有两份代码区,让父子进程各自独用一块代码段,然后父进程/子进程再各自该修改就修改自己的那份代码段就可以了。
不过,我们现在这个程度只能在父子进程运行的时候只能发生数据的改变,而不能发生代码的改变,所以就是我们只能观察到数据区的写时拷贝,而观察不到代码区的写时拷贝。所以本篇博文主要讨论数据的写时拷贝。
1.2.3为什么要共享&&写时拷贝
首先我们提出两个问题:
为什么在要发生写时拷贝呢,让父子进程一直共享同一份代码和数据不可以吗?
fork创建出的子进程为什么要和父进程共享同一份代码和数据呢,直接在一开始就拷贝一份代码和数据,让他们直接各自独占一份代码和数据不也很好吗?
我想说的是:操作系统这样设计出来父子进程共享代码和数据以及后续写时拷贝机制是有道理的。
问题一:为什么要发生写时拷贝?
答:为了维护进程的独立性,不要让进程间的运行相互干扰。
我们首先举一个例子来说明一下系统中进程的独立性:
我们在Windows操作系统中开着微信聊天,QQ聊天,网易云音乐,CSDN写博客这几个进程,那现在如果网易云音乐这个进程挂掉了,即现在网易云闪退了,会影响我们继续写CSDN博客吗?事实上是不会的,网易云进程挂掉并不影响我们CSDN这个进程。QQ进程挂掉也不影响我们在微信进程的聊天。 同样的微信挂掉,也不会影响我们QQ聊天的继续。
所以这说明了一件事->进程具有独立性!!!进程和进程之间是互不影响的。一个进程挂掉不会影响另一个进程。
如果父子当中的一个进程会写入影响他们共享的数据区,此时父子进程还共享同一份数据的话,那其实就不能维护父进程和子进程之间的独立性了。(假设现在是子进程要写入数据区,而父进程仍然需要保持数据区的不变,此时父子进程要维护独立性的话,必须给子进程再单独开辟一块数据区,让他们单独占有一个数据区,子进程写入自己的数据区,父进程仍然可以使用原来不能改变的数据区,这样就维护住了进程之间的独立性)
问题二:父子进程为什么一开始要共享代码和数据?
答:降低创建进程的成本以及提高创建进程的效率。
如果我们每次fork创建子进程后,都要100%发生数据区和代码区的写时拷贝,那其实创建子进程的成本是很高的,而且很多情况下,你创建的子进程是不需要发生写入,不需要改变数据区和代码区的,做的仅仅是读取数据的工作,此时单独给子进程单独拷贝一份数据和代码其实是非常浪费的!而这种情况下让父子进程共享同一块数据区和代码区,成本就会低很多且不影响父子进程的运行。后面父子进程如果要发生写入,我们再写时拷贝单独拷贝也不迟嘛。
至此,我们就明白了子进程创建的实质,子进程的task_struct以及子进程的代码和数据,对父进程的“继承”性,以及代码数据共享以及写时拷贝机制。
现在有了对子进程创建机制的理解,在此基础上,我们再细致了解一下可以创建子进程的fork函数。
1.2.4 什么时候发生写时拷贝
其实发生写时拷贝的时机很好把握,就一句话,无论是父进程还是子进程,只有他们其中任一个进程,对一个他们都能看到、都能使用或者更准确的说是都能获取、都能写入的变量,进行写入,就会发生写时拷贝。
分解一下:
who does :父进程or子进程任一个。
who does whom : 父子进程都可以看到,都可以获取到,都可以对之读写的变量。
when :当父进程/子进程任一个写入该种变量时发生。
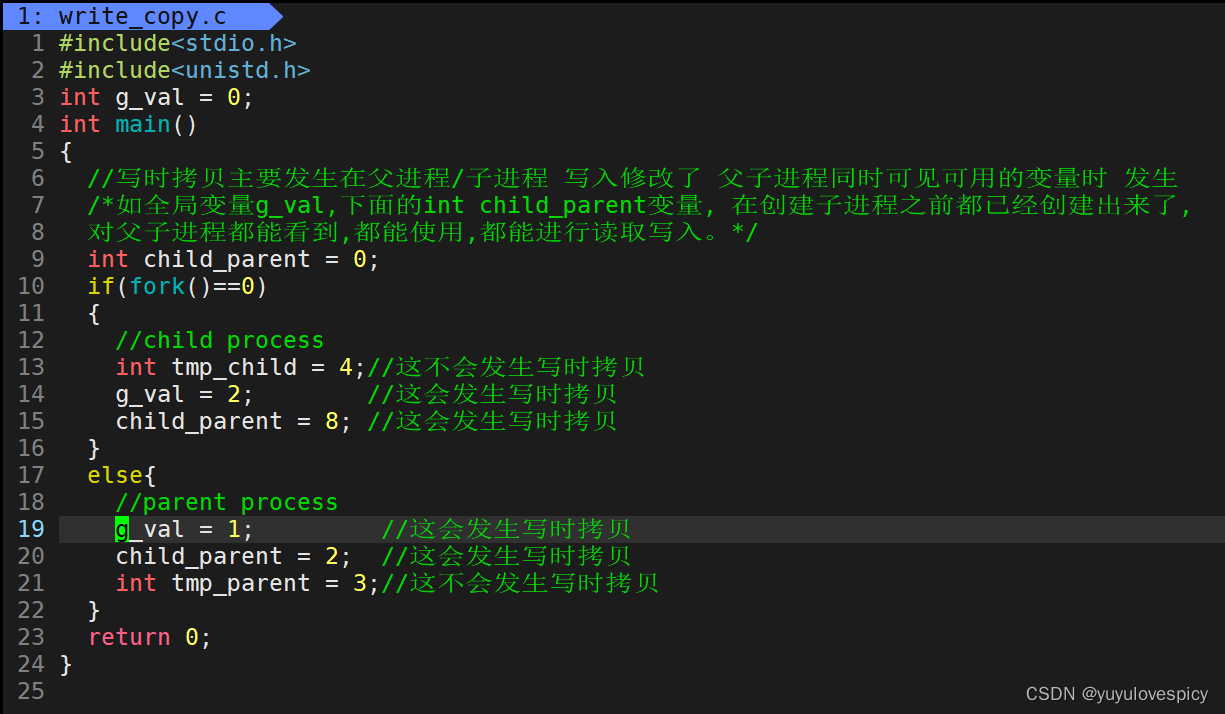
所以对下面代码当中:
对于全局变量g_val,在fork创建子进程之前创建的变量child_parent,这些都是父进程和子进程都可以看到,都可以获取,都可以对之写入的变量。当在写入 g_val , child_parent 变量时都能发生写时拷贝。
而对于tmp_child,tmp_parent,这些父进程或子进程自己单独定义的变量,比如父进程就获取使用不到子进程自己定义的变量tmp_child,子进程就获取使用不到父进程自己定义的变量tmp_parent。所以对这些变量写入,tmp_child = 1 , tmp_parent = 2 等等,都是不会发生写时拷贝的。
1.3 fork函数返回值详解
1.3.1引入fork返回值的作用
首先问一个问题:我们的父进程和子进程是共享同一段代码的,大多数执行的也是同一段代码,那父子进程是不是只能做一样的事情呢?
这样其实是不合理的!我们父进程创建出子进程,其目的肯定是让子进程去完成什么不同的任务,然后子进程再把完成任务的反馈信息(子进程的退出信息)告诉父进程,这实际上才是父进程创建子进程的目的以及整个父子进程间运行的逻辑,父子进程要做的事情(执行的代码)肯定是要不一样的。
那我们如何让执行同一段代码的父子进程干不同的事情(执行不同的代码)呢?
这时候就要靠fork的返回值了!!!
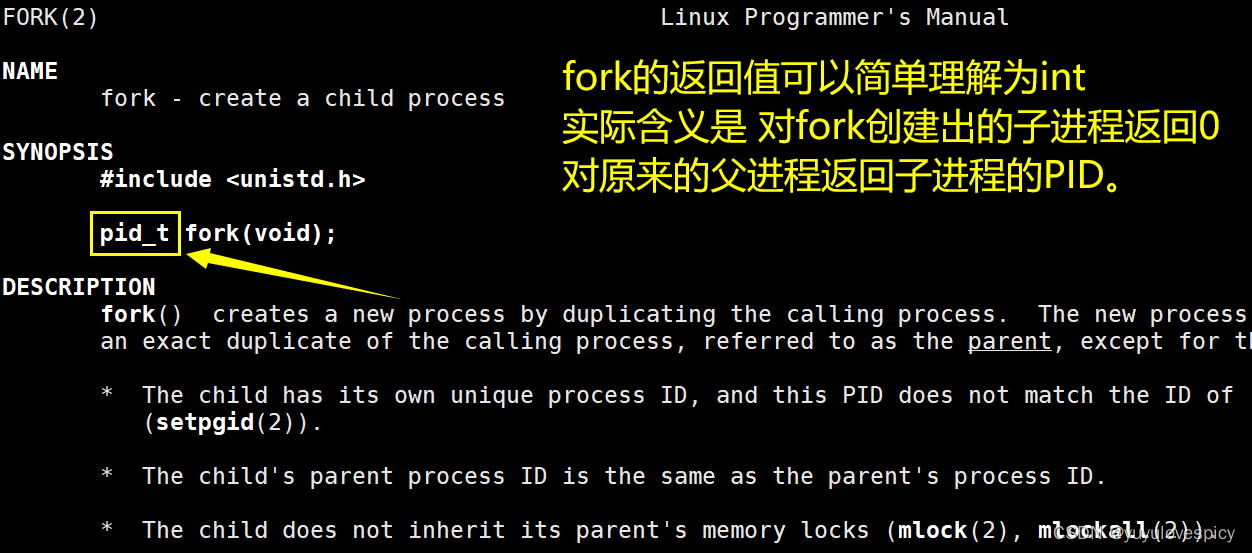
这里附上fork返回值官方文档介绍
翻译:成功创建子进程的话,那子进程的PID值就会返回给父进程,0就会被返回给新创建的子进程。如果创建子进程失败的话,-1就会被返回给父进程,当然子进程也不会被创建也就没有返回,同时全局错误码errno也会被设置。
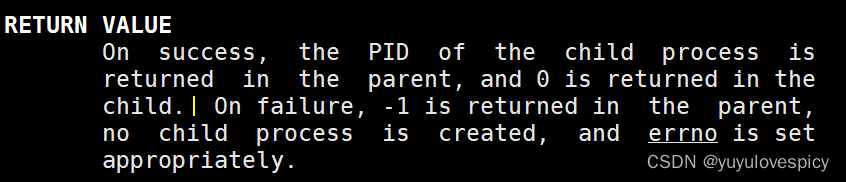
fork对子进程返回0值,对父进程返回子进程PID值,这样就可以根据这个返回值进行执行代码的分流,示例如下:
可是这样理解并不全面,下面我再带领大家细品fork创建子进程的这个过程的全逻辑。
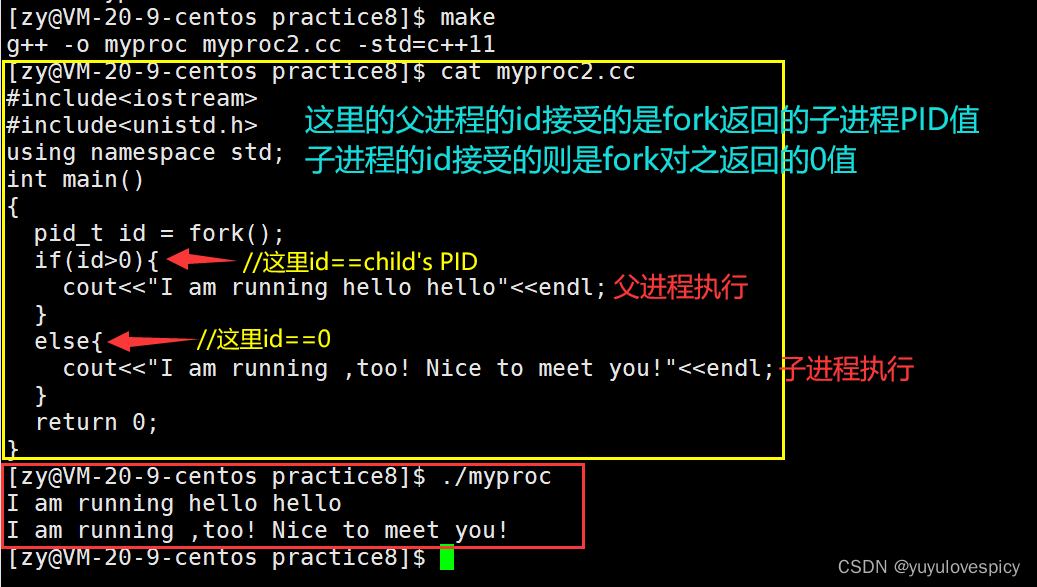
1.3.2 fork返回执行逻辑剖析
如何理解两个返回值?返回这两个返回值期间具体到底发生了什么?为什么要分别返回两个返回值呢?
返回两个返回值并不是两次返回这么简单,中间还牵扯着写时拷贝的问题。
给父子进程返回两个不同的返回值,是为了让父子进程即使共用同一个代码区,也能执行不同的逻辑。
下面我们做细致的分析:
解答第一个问题->:fork函数return期间发生了什么:
我们首先要明白一个问题,一个函数在return之前,他的核心逻辑是不是已经执行完了?当然是这样,函数核心工作完成了,最后再return一个值给上一层反馈嘛~ 。那么其实也就是说fork()函数要return值的时候,其实fork函数的核心已经执行完了,即现在系统中已经多了一个进程,父进程的子进程就已经被创建出来了。
即fork返回的时候,此时父进程和子进程就已经在共享同一份代码段和数据区了。但是故事的转机体现在fork的返回值上!!!!!当返回值返回到某一个进程的时候,(此时他们还共用同一块数据区),return值是不是会对数据区发生写入!!!是的!!!此时他们共享的数据区中的id变量被写入了,其实无论id被赋值成0还是子进程PID,本质上都是在数据区上的写入!!!此时就会触发写时拷贝机制!!!!!子进程和父进程各自独享一块数据区!此时子进程可以对他数据区里的id赋值0,父进程在他的数据区的id赋值子进程的PID值,从而维护住父子进程的独立性。
我们看如下代码:
解决第二个问题->: 为什么给父子进程返回两个不同的返回值:
现在如果是处于return之后(当然已经发生了写时拷贝)父进程的数据区的id值为子进程PID,子进程的数据区的id值为0,那我们此时就可以利用父子进程各自数据区中不同的id值(本质是fork返回值),进行if else分流,执行不同的逻辑。再说的明白一点,id赋值fork的返回值后,其实就是此时父进程数据区的id==子进程PID,子进程数据区的id==0, 此时父进程再往下执行就是执行else(id>0)后面的逻辑,子进程就只想if(id==)后面的逻辑,不过他们本质还是在共享使用同一份代码区,只不过他们被(id值)fork的返回值,分流执行不同的逻辑了!!!

如此我们就解决了即使父子进程共享同一段代码区,父子进程仍可执行不同逻辑的这个痛点了,破局之点就在fork的返回值以及父子进程的写时拷贝机制!!!
1.3.3 小问题补充
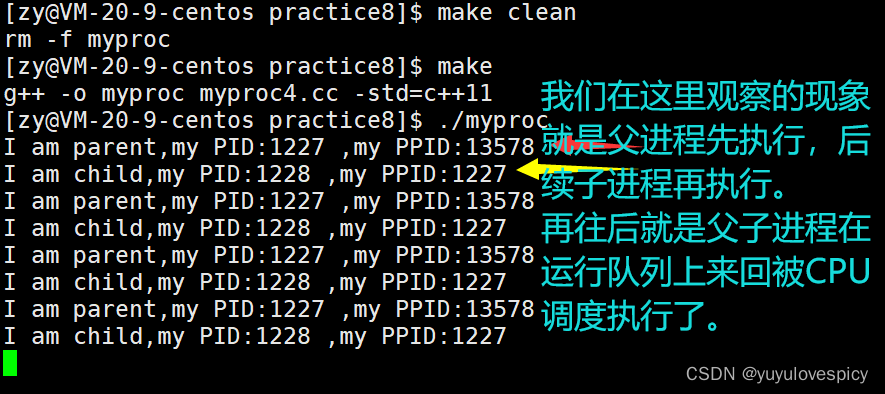
那fork创建出来了子进程,加上现在的父进程是有两个进程,就是有两个执行流了,那先执行父子哪个进程呢?
我们观察到的现象是父进程先得到了执行,其实并不是这样的,先执行父进程还是子进程这其实是由环境有关的,而且其实先执行谁都没关系,毕竟父子进程之间都是有独立性的,而且进程的执行也是在运行队列上排队接受CPU仅一个时间片的多次来回执行,谁先谁后这个问题也并不是特别的重要。
2.进程状态
2.1 进程状态引入
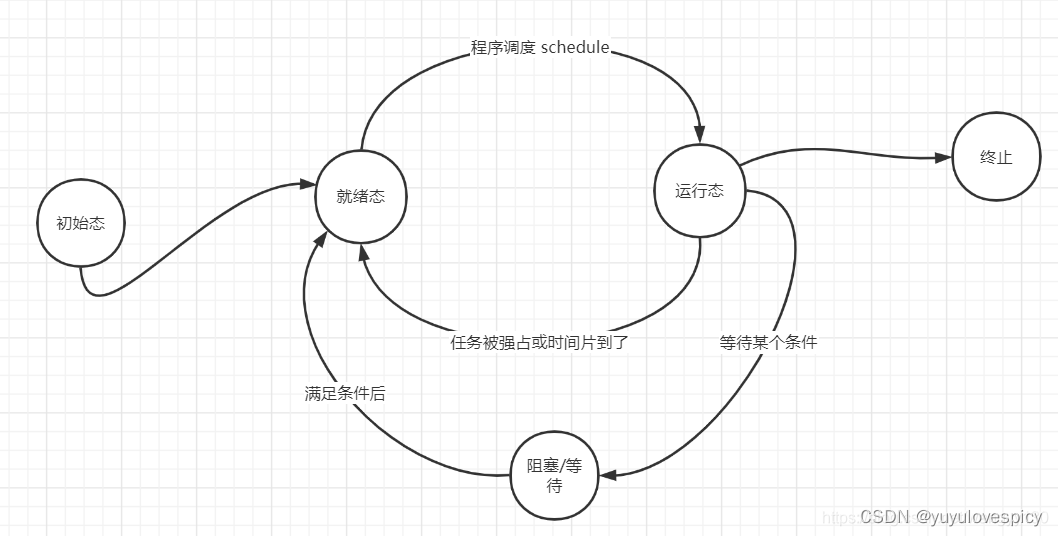
如图, 我们先浅显的描述一遍:一个进程在被创建出来时就是初始态,他可以运行在等待CPU时就是就绪态,在运行的时候就是运行态,条件不足不可以运行就无法就绪,就会去挂起等待(阻塞)。
我们不禁要问,什么是就绪,什么是运行,这两个态在系统当中具体是什么样的,什么是挂起,为什么要等待挂起/阻塞等待(等待,阻塞,挂起可以暂时理解为一件事)呢?一个进程从创建到执行的全过程中到底要经历什么呢?进程的状态有哪些呢?如何查看进程状态呢?每个状态存在又代表了什么呢?下面我们将一一解答!
2.2 初识进程中的状态
在Linux操作系统中,进程主要有 R状态(运行状态),S状态(等待/挂起/阻塞状态/浅度睡眠状态),D状态(深度睡眠状态/不可中断状态),T状态(暂停状态),t状态(跟踪暂停状态),X状态(死亡状态),Z状态(僵尸状态)。
英文解释为 R-running , S-sleeping , D-disk sleep , T-stopped , t-tracing stop , X-dead , Z-zombie 。
进程的状态信息存储在哪里呢?
那必然是该进程的task_struct(进程控制块PCB)当中,task_struct里面存储着进程的属性信息嘛~
进程状态的意义是什么呢?
首先进程状态描述的是你进程现在正在干什么,比如你现在处于R状态,就证明你这个进程正在运行(或即将运行),比如你处于S状态,就证明你这个进程正在挂起等待,比如你这个进程标志处于T状态,就说明这个进程是正在暂停的。
所以进程状态可以描述出你这个进程现在在干什么,可以方便操作系统快速判断进程,从而让OS快速完成特定的功能。比如调度,你现在一个进程处于S等待/挂起状态,操作系统就可以快速判断出你这个进程实际上正在等待什么东西,此时OS就不会把你调度去CPU运行。比如你现在进程PCB标志X死亡状态,说明这个进程已经死亡了,OS此时看到这个进程的X状态信息后,也不会再调度你了。
所以进程状态,本质上就是一种分类!!!!
2.3 R状态解析
首先我们知道进程要被CPU执行,进程的PCB就要被调度到运行队列run_queue上排队,之后接受CPU一个一个时间片的来回排队调度运行。
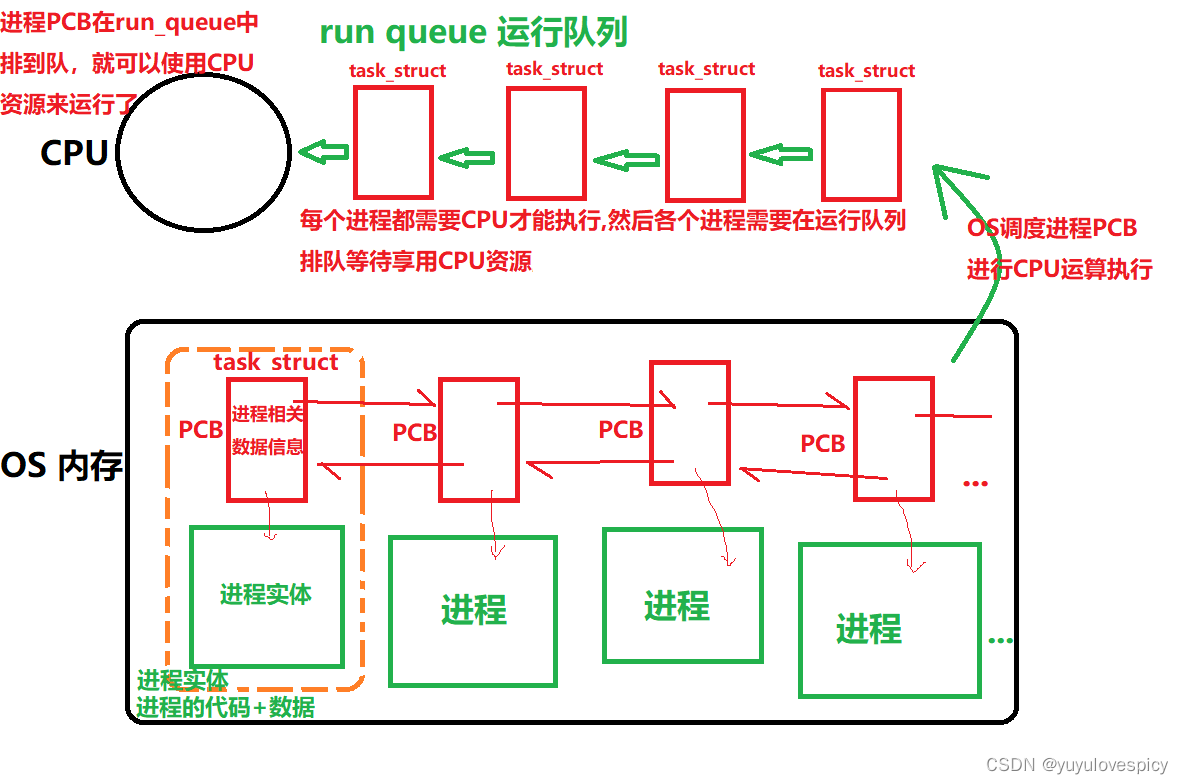
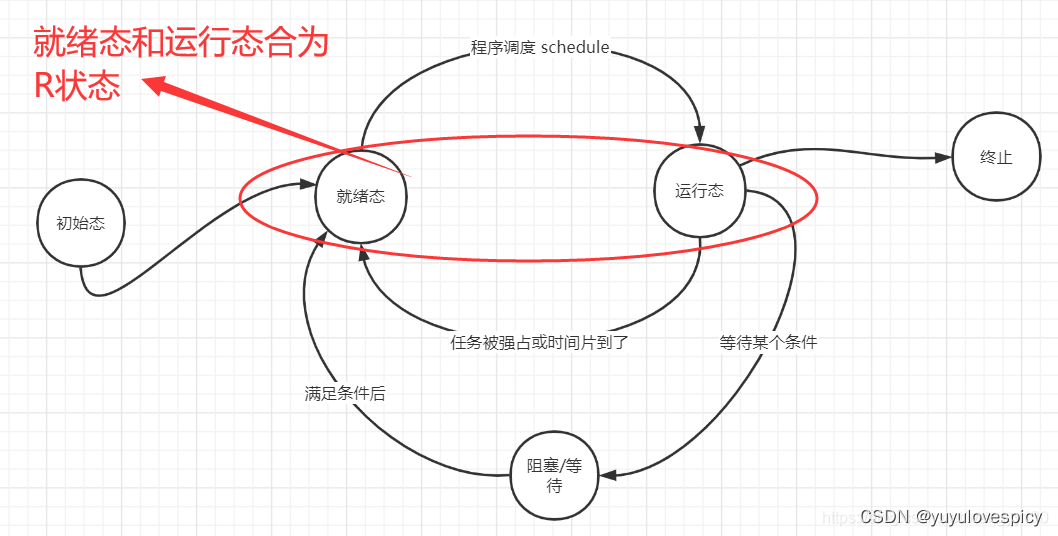
R状态(running)首先他叫运行状态,但是如果一个进程PCB显示它正处于R状态,那能不能说明这个进程就正在占有CPU资源呢?其实这样并不准确,所谓的R状态,不仅只是运行态,还包括就绪态!其实是就绪态和运行态的集合!进程处于R状态不能说明这个进程一定正在占有CPU资源(运行态),也有可能这个进程在运行队列run_queue中等待CPU资源(就绪态)。在运行队列中等待CPU资源或进程正在享用CPU资源,都可以表明这个进程可以运行,即都可以称R状态。
也就是说进程表明它可以被执行了,也就是说他就会在运行队列run_queue中排队,或者它排到队了,正在使用CPU资源。在Linux操作系统下,这两种情况下进程都是R状态!!!
2.4 S状态解析
2.4.1 S状态的具体表现
S状态(sleeping),也可以称之为挂起状态,等待状态,阻塞状态,浅度睡眠状态,这些名字都是有相应道理的,空说S状态并不具体,下面我们通过几个具体例子,了解进程在处于S状态时,是为了什么,在干什么:
比如今天你今天在宿舍想打游戏,但是在打游戏前,你就必须要等待电脑开机,电脑不开机你就暂时不具备打游戏的条件,要打游戏必须等待电脑资源开机!
比如说今天我这个进程,今天想从网络当中读取一个数据,可是现在网络上还没有数据,比如数据还没有传到网络上,所以你这个进程就得等待网络资源响应,等到网络上数据到了之后,进程才会继续执行。因为进程代码的执行逻辑就是先从网络中获取到数据,然后处理数据嘛,读取不到数据肯定不能往下执行嘛~
比如说今天进程必须要从磁盘上读取某个文件内容,可是磁盘上现在没有文件。再比如我这个进程必须要往磁盘上写入一些数据,可是磁盘现在已经写满了。进程就得等待磁盘上有文件,进程必须等待磁盘上有空闲空间出现时,才能继续运行下去。再比如你这个进程到了scanf,cin执行逻辑的一行,那是不是如果键盘外设不进行数据的输入,进程就无法读取到数据也就无法继续执行,此时进程就必须等待键盘资源了。当进程遇到外部资源条件不具备的时候,就必须得一直等待,等到某个资源条件具备,才会继续执行。
当我们想完成某种任务时,任务条件不具备,需要进程进行某种等待,(进程无法执行,什么事都干不了,就干等着),进程等待的状态,在Linux中就叫S状态/D状态。(S,D状态的区别我们在D状态详解时说明,这里我们暂把S状态和D状态先理解为一种等待状态)
但是有没有一种可能,现在整个宿舍里只有一台电脑,不仅是你,你和你室友都想玩游戏,这当然是有可能的,我和室友都想玩游戏,抛开后面你和室友玩游戏抢鼠标键盘的场景,现在是不是你和你的室友都要等待电脑的开机呢?这当然是,电脑不开机,不管是谁都没法玩游戏。例子中的你和室友其实就是一个一个的进程,例子中的电脑就是进程们要等待的某种资源,进程们都在等待某种资源,这也就是说,某种资源不一定只被一个进程等待,也有可能被多个进程等待。
再具体一点,系统中一个软件Or一个硬件,一定会有不止一个进程都想对之进行访问,一定有多个进程PCB在等待这个外设准备就绪,如要打印就要等待显示器就绪,要读取键盘就要等待用户从键盘上输入数据,多个不同的进程访问要访问同一个外设,就得排队访问,这其实也是一个队列,这个就叫做等待队列wait_queue,这个类似于运行队列run_queue,不过run_queue是进程们对CPU资源的排队等待,wait_queue是进程们对某外设资源软件资源的等待。所以这也告诉我吗进程不只会排队等待CPU资源,也可以排队等待其他资源。
所以这里我们就可以具象化系统中正在等待的进程了。如下图所示:一个一个的进程PCB需要使用某种外设资源,就需要等待某种外设资源就绪,也需要和其他进程排队等待,多个task_struct就组织在wait_queue等待队列中,然后等待外设资源的就绪以及其他进程对该外设资源的利用,这个task_struct在等待队列中,等待享用到某资源的过程,我们说该进程处于S等待挂起状态。
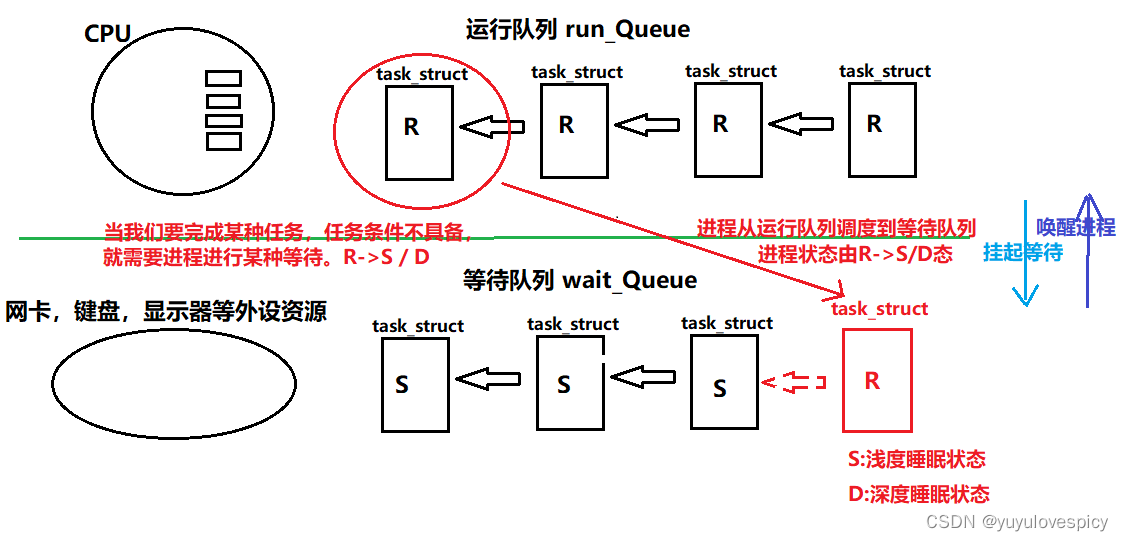
2.4.2 CPU视角下的进程等待
我们再从CPU的角度考虑等待这件事,首先我们看CPU是怎么做的,当一个进程运行到需要必须等待某种外设/软件资源的时候,此时CPU就会将这个进程PCB赶出run_queue运行队列,把该task_struct调度到对该外设/软件资源的等待队列wait_queue上,并将该进程PCB中的状态由R状态设置为S状态。那为什么要对进程这样做呢?
因为CPU不可能让这个进程在运行队列里什么事情都不能干,轮到这个进程享用CPU资源都时候不能执行,就只能一直等待某个资源就绪,这其实浪费了时间片,浪费了CPU的资源,所以CPU把这个进程PCB设为S状态,从运行队列run_queue丢到了该外设资源的等待队列wait_queue中去了。
当然如果这个进程PCB在等待队列中等待成功了某外设资源,即某外设资源对该进程已就绪,那就说明这个进程可以被CPU继续执行了!那此时进程PCB的状态就会由S状态再设置为R状态,从外设的等待队列wait_queue中回到CPU的运行队列run_queue里,继续进行进程的执行了。
这也可以帮助我们更好的理解状态其实是一种对进程的分类这一经典名言。
状态的本质是分类,我们通过不同的队列,其实就完成了对不同进程的分类。一类【S状态的PCB进程】是需要等待某种资源就绪的,而这一类进程都在等待队列wait_Queue,这一类【R状态PCB进程】是需要去被CPU直接去执行的,而这一列进程都在运行队列run_Queue中。
2.4.3 进程卡死与进程等待
在举个现实中的例子帮助我们理解进程等待:
比如现在我打开一个网易云音乐,现在他卡死了,本质上这是网易云这个进程的问题,是这个进程一直没有享用到CPU资源导致的,是在运行队列run_queue上长时间卡死了吗,不会的,纵使该进程优先级再低,系统中有平衡机制,网易云进程也可以被CPU执行到,从而执行下去不会卡死。
那是为什么呢?这很可能就是因为这个进程执行所必需的某个资源还没有就绪,导致这个进程一直在等待这个资源而一直无法被执行。比如说网易云现在需要的网卡当中的某些数据还没有就绪,我这个进程没有读到,网易云这个进程就必须在该网卡资源的等待队列wait_queue中等待该资源就绪,即此时该进程一直处于S状态,一直在等待,啥事都不干,无法去run_queue上被CPU执行,网易云这个进程也就卡死了。
所以,卡死的本质就是该进程一直没有被CPU执行 -> 一直在等待某种外设资源(处S状态) -> 最终我们可以看到一个弹窗:当前xxx进程无响应,是否让该进程继续等待OR直接退出该进程。
当然除了这种资源条件一直不具备的情况,外设不给力,导致进程PCB一直卡在等待队列无法执行,最终软件卡死的情况,还有一种卡死情况,那就是某个软硬件资源要被使用的人(进程)太多了,大家(要使用该资源的进程们)都挤在该资源的等待队列wait_queue里,CPU此时可能忙着唤醒别人(别的进程),而没有顾及到该进程,这个进程没有被调度到run_queue运行队列中被CPU执行,就只能一直在等待队列里卡死。
进程处于R状态的进程,要等某种资源时,进程PCB就会从运行队列run_Queue中,被放到等待队列wait_Queue中,进程状态就从R状态变成S/D状态这个过程就叫做挂起等待!!!也叫阻塞!!!
当然后续进程等待成功某种资源后,会被OS从等待队列wait_queue放到运行队列run_queue当中,(S->R),这个过程就叫做唤醒进程!!!
2.5 D状态解析
2.5.1 D状态对比S状态
D状态(disk sleep),可以称之为深度睡眠状态,换句话说,D状态是比S浅度睡眠状态更强更深的睡眠等待状态。D状态类似于S等待挂起状态,但是我们可以说这个D状态下的等待更加的坚决。
再具体说,S状态下的等待睡眠是可以中断的,如下面实例:
上面的例子演示了处于S状态正在等待某个资源就绪的进程是可以被杀死的,但是D状态下的等待睡眠是深度睡眠,是不可中断的,程操作系统不能奈何D状态的进程,D状态的进程不能被信号唤醒,GDB等调试工具也不能对它调试,我们下面举个生动的例子说明D状态的意义。

2.5.2 生动例子说明D状态意义
说现在有一个外设----磁盘,内存中有一个进程,内存中也有一个操作系统OS,然后我们知道进程让内存往磁盘上写入的时候,是一定要花时间去写的。磁盘往盘片上写数据,亦是需要花时间的。磁盘在工作,即磁盘在写入数据的时候,你进程只能在这边等,你在等什么呢?等磁盘把数据写完,然后(磁盘)告诉你(进程)写完的结果。铺垫完基本知识,我们开始故事讲述:

你是一个进程,你站在内存当中,然后你这个进程执行到某行代码逻辑,让内存中的某数据写入保存到磁盘当中,数据从内存output到磁盘,磁盘大哥说:“数据来了,那好,我去帮把数据写到盘片上,不过需要点时间,你进程给我在这等着,我写完告诉你成功还是失败。”然后磁盘就去工作了。此时进程不能从磁盘的wait_queue折回到run_queue运行队列继续执行,而是要继续在该磁盘的等待队列中等待,等待磁盘写入完成之后,接收反馈结果。所以进程就在这等待队列等着,也处于S状态(浅度休眠)了。
这个进程S等待磁盘写入的过程其实挺美好的,磁盘写入完成,然后把写入结果反馈给这个进程,然后进程再从等待队列回到运行队列继续执行。
但是!!!现在进程在等待的时候,OS操作系统路过了,OS说:“你这个进程干嘛呢,还在这里睡眠,在这里等待什么事也不做,白白占用系统资源,你都不看看我OS都忙成什么样了,现在内存资源都快不够用了!!!”,然后操作系统就直接把你这个处于S等待状态的进程给直接干掉了(OS作为进程的管理者当然也有这个权利)。不过这样问题就大了呀,我被杀死了,那磁盘在盘片上工作完成后,磁盘把写入的结果反馈给谁呢?写入保存成功了还好,那如果磁盘写入失败了,要把写入失败的消息反馈给进程,但是现在进程找不到了可怎么办!这样用户就不会知道保存磁盘其实是失败的!!!后果很严重!!!
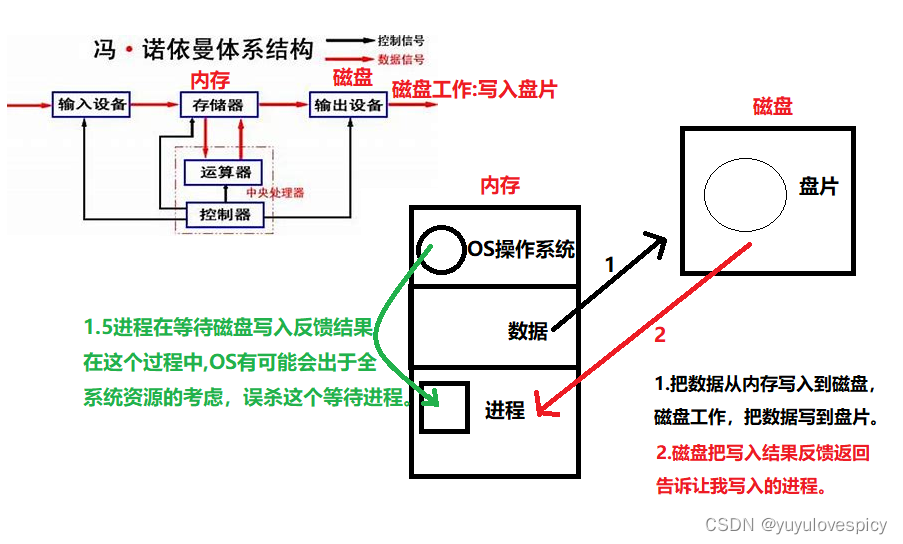
在这个过程当中,是进程,操作系统,磁盘三者谁的错呢,磁盘保存失败的反馈没有被接收,而用户自以为写入成功,那这个锅谁背呢?
是磁盘背锅吗?不对,磁盘只是个办事的,而且已经把写入失败的结果信息反馈了,磁盘找不到人接收信息,怎么能怪磁盘呢。是进程背锅吗?不对,进程好好的在磁盘的等待队列里等待磁盘的反馈信息,然后就被OS干掉了,这波不能怪进程。是OS操作系统背锅吗?也不对,OS需要考虑整个系统资源的调配,服务于这个计算机,现在内存资源紧张,OS干掉没有执行而占用系统资源的进程,这本身做的也没错呀。
很显然,这种情况下,三者其实都没错,但是如果在等待的S状态进程被OS不小心干掉了,而导致数据丢失,但是其实谁都没有问题,这种我们假设的情况我们能允许它存在吗?当然不允许!!!这件事的根本在于进程等待的时候,被操作系统误杀,那能不能不让这个进程在等待的时候被杀掉呢。操作系统考虑到了这一点!!!
如果进程处于S等待状态(浅度睡眠),在等待时就可以被OS杀死,而如果进程处于D状态(深度睡眠),此时就不会该进程就不会被OS干掉。这就是D状态的意义,只要你这个进程处于D等待睡眠状态,OS就不能干掉你。
故接下来故事反转:当你这个进程是处于D状态,在等待队列wait_queue中不可中断的等待磁盘,那如果此时OS路过,想要杀死你这个什么都不干,就在睡眠而却占有系统资源的进程,此时你这个进程默默掏出了D状态深度睡眠状态,那OS就不能杀死你了!就不能杀死这个D进程,D进程就是一个爷,OS就只得去杀别的在等待的进程了。
然后D状态的这个进程就安然无恙的等待磁盘写入,等待接收磁盘的反馈信息,等磁盘就绪时,该进程就会被唤醒,携带反馈信息回到运行队列,被CPU继续执行,然后进程就可以将这个接收到的这个磁盘写入结果的信息反馈到上层。Perfect!!!
2.5.3 D状态进程问题补充
D状态的进程也会出现一个问题:如果系统中存在大量的D状态进程正在占有系统资源,由于甚至连OS都不能杀死D状态的进程,现在的对策就只有等待D进程自己执行完毕或者直接重启机器,否则没有任何方法处理掉D状态的进程,所以系统资源就会被大量占有,出现卡顿宕机的情况。
2.6 T状态介绍
T状态,暂停状态,英文名stopped。
T状态进程需求:执行某些任务的时候,这个进程需要暂停执行。
暂停不是睡眠等待,纵使S等待状态和T暂停状态有一点像,但其实根本上是不同的。他们的相同在于都不会被CPU执行。S状态是在等待队列wait_queue中等待某个外设资源,没有在run_queue中,不能接受到CPU的资源。而T状态是直接让这个进程暂停,CPU无法执行这个已经暂停的进程。如果说处于T状态的进程感受到的是时间暂停,那S状态下的进程感受到的则是时光流逝中无穷等待的感觉,这两类进程都不能去做事(被CPU执行)。
进程处于S状态(sleeping睡眠)是代码没有跑,什么事都没干,但是核心数据会被更新改变。比如你这个进程执行sleep语句时,sleep休眠多少时间了,这个数据会被更新,进程是真的在等待某件事情的到来,这个等待是有意义的,这个等待在某种意义上也是一种运行。而T状态则是彻底的中断,暂停!你压根不会有任何的数据更新!!!
2.7 t状态介绍
t状态,跟踪状态,英文名tracing stop。
事实上,追踪也是一种暂停态,比如进程在代码的某一行打了一个断点,运行就在断点处停下来了,这就是典型的t状态。即因为追踪而处于的暂停状态(t状态),当然此时t状态的进程也方便你查看数据。
2.8 X状态介绍

X状态,死亡状态,英文名dead。
进程死亡,说白一点,就是就等同于进程资源被回收。什么是进程资源的回收呢?我们知道创建进程的时候,做了什么动作,在回收的时候肯定要做相反的动作,所以:
回收进程资源 == 即回收进程相关的数据结构(task_struct) + 你的代码和数据(进程本体)。
进程X死亡,就是干干净净,什么都没有了!!!
所以进程的X死亡状态很少是很少能被我们获悉观察到,因为进程dead死亡,就意味着进程资源的释放,没有进程的资源你也很难观察到X死亡状态了。因为状态也是一种进程的属性数据,也是在PCB中保存的,进程的PCB数据结构和代码数据资源都被释放完毕了,存储在PCB的X状态也就没有了,我们也很难查看到X状态了。
进程退出死亡的全部过程:首先变成Z状态,最后再变成X状态,先僵尸,再死亡,进程首先退出,并不会回收所有该进程的资源,而是例如进程会先保留该进程的退出信息,进程进入僵尸Z状态,而当所有该进程的资源被回收之后,进程会进入X死亡状态。
2.9 Z状态详解

Z状态,僵尸状态,英文名zombie。
如何理解僵尸状态,我们先举一个生动的例子类比一下吧。
2.9.1 故事讲解
你作为一个热爱运动的优秀大学生,是十分喜欢晨跑的人,这天你正在晨跑,突然你发现有一个人从你旁边呼啸而过,他如风一般,但是这个风一样的男子在跑出你20m后突然倒下了,等你反应过去去看的时候,发现这个人其实已经失去了生命体征,大概率是某种恶性基本如心肌梗塞,脑溢血等疾病的突发,总之说明这个人只剩下遗体了(尊重死者),你虽然不会急救知识,但是你还是一个有良知的人,你会去做一件事----打电话,联系110,当然110说他们赶到的时候一定会随叫到120,所以你只打了110。等到110警察到达之后,警察要做的第一件事情,并不是立即把这个人的遗体处理掉,而是首先全面封锁现场,然后叫法医过来进行鉴定,这才是110首先一个干的事情,等待法医鉴定完毕才会通知后事部门回收遗体。
在这个现实中的例子中有两件事。
为什么这个人已死,只剩下遗体,警察不立即回收走呢,而是要封锁现场,然后叫法医过来鉴定呢?因为警察要调查出一件事,这个人是因为疾病还是他杀什么原因,即死因。调查死因这是第一件事。(调查死因的时候,遗体一直在那里躺着)
然后法医鉴定完毕之后,警察会不会直接撤走封锁线,直接说任务完成,就直接走了,把遗体放在风中凌乱呢?当然也不会,警察当然是要通知后事部门,把遗体处理好后,才会收队撤离。回收遗体这是第二件事。(在调查出死因之后,遗体才会回收)
当调查死因结束,警察做完再通知后事部门处理完遗体后,这件事才是真正结束了。
2.9.2 事例类比进程
在这里可以类比进程退出死亡的全程,警察在法医鉴定完成之后,通知后事部门把这个遗体真正回收完毕,这个人这件事才真正结束,类比进程就是这个进程才真正进入了X死亡状态,而之前法医调查死因,死者的遗体一直躺在地上的这段时间,类比进程就是这个进程处于的就是Z僵尸状态。
为什么警察来了之后不是立即回收遗体,而是先让遗体躺着呢,等法医鉴定完毕再做呢?
因为警察需要辨别死者的死亡原因!!!确定这个人是自杀,疾病还是他杀等。这是因为我们确定一个人死亡的原因是为了给社会一个交代,如果一个人的死因没有调查清楚,可能会引起社会恐慌,而且死因没有调查清楚,媒体会如何报道,舆情会如何发展,这些问题都非常难以处理。所以我们必须要调查遗体死因,从而给社会一个交代!!!
这个可以类比进程为什么要首先处于Z僵尸状态,而不是直接进入X死亡状态?
首先我们创建出一个进程(子进程),其目的是为了让这个进程去完成某种任务,那这个任务最终被这个进程完成的如何呢?你这个进程是把任务完成正常退出,还是中间不小心被OS干掉了,还是因为进程自己代码有问题而进程退出,这些都要给父进程要对系统有一个交代!!!
遗体要在地上躺一会,被法医鉴定原因,然后才会回收遗体,这个遗体躺着的过程类比进程就是,进程处于Z状态。继续类比,其实进程退出的时候,并不会回收掉一切资源,也即不会直接进入X死亡状态,退出的进程而是会暂存该进程的退出信息,其实这个退出信息就可以类比例子中暂不被回收的遗体。
那这个进程的退出信息暂存在哪里呢?进程的退出信息也是数据,这个数据跟进程强相关,那肯定就是存放在这个进程的PCB task_struct中。即当一个进程退出的时候,它的所有资源并不是会立即释放的,而是首先让这个进程进入僵尸,把这个进程的退出信息存在这个进程的PCB中,来供我们的父进程或系统去读取,调查死因之后(读取退出信息后)才会退出。
这仿佛遗体在说:"我还不能被回收(进程X回收所有资源),我遗体还要躺一会(先进入Z状态 退出信息保存到PCB),我的死因还没有调查清楚!"
总之,一个进程的退出并不会立即进入X状态回收所有进程资源,而是会首先进入Z状态保存退出信息到PCB。等到其退出信息被父进程/系统读取后,所有的进程资源被父进程/系统回收,该进程才进入X状态。
实际上,进程退出之后,它的退出状态,退出码等退出信息都是会写在这个进程的task_struct中的,进程的僵尸状态,就是进程的退出信息保存在PCB中,进程的部分资源仍然存在,所以僵尸资源就会占用系统资源,这样就会导致内存泄漏等问题。我们会在下篇博客中介绍如何解决僵尸状态,以及退出信息退出码。
2.10 进程状态总结
就绪态就是进程在run_Queue运行队列里等待CPU资源;运行态就是CPU的时间片到来运行该进程。就绪态+运行态在Linux下是R状态。
挂起等待/阻塞状态 就是 S , D , T状态,一般来说是S/D状态,S,D状态的进程,在某资源的等待队列wait_Queue中等待该资源就绪,T状态的进程就是处于完全的暂停状态。
3. 在实践中验证各个状态
我们主要进行对于R,S,T状态的验证,D状态进程的实现需要涉及到读盘写盘(这样才会产生等待却不可以被OS杀死的进程),会对云服务器产生损害,所以我们不验证。
3.1 R状态验证
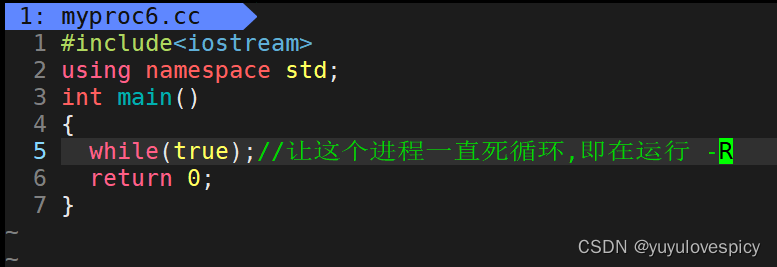

也就是说这个Myproc进程一直在进行死循环一直在run_Queue上等待/享用CPU的资源。
3.2 S状态验证
3.2.1 S状态简单示例
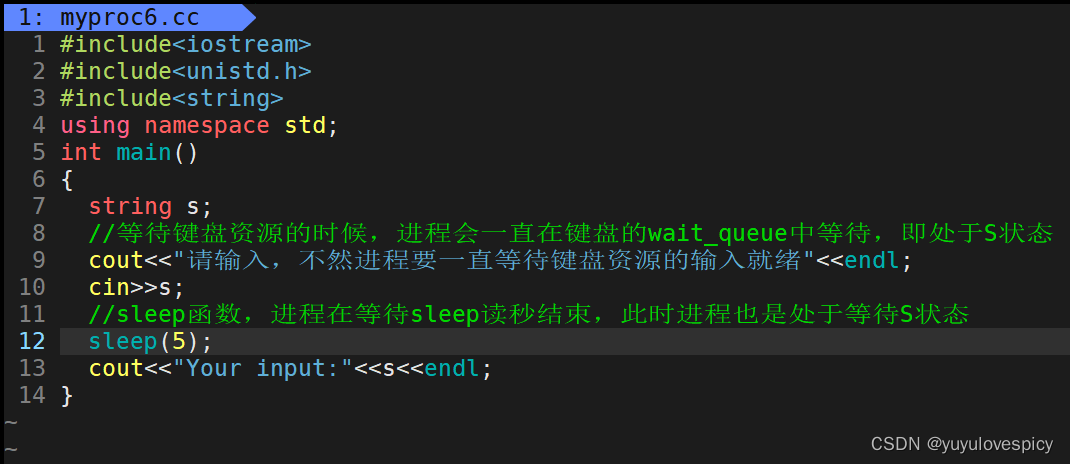
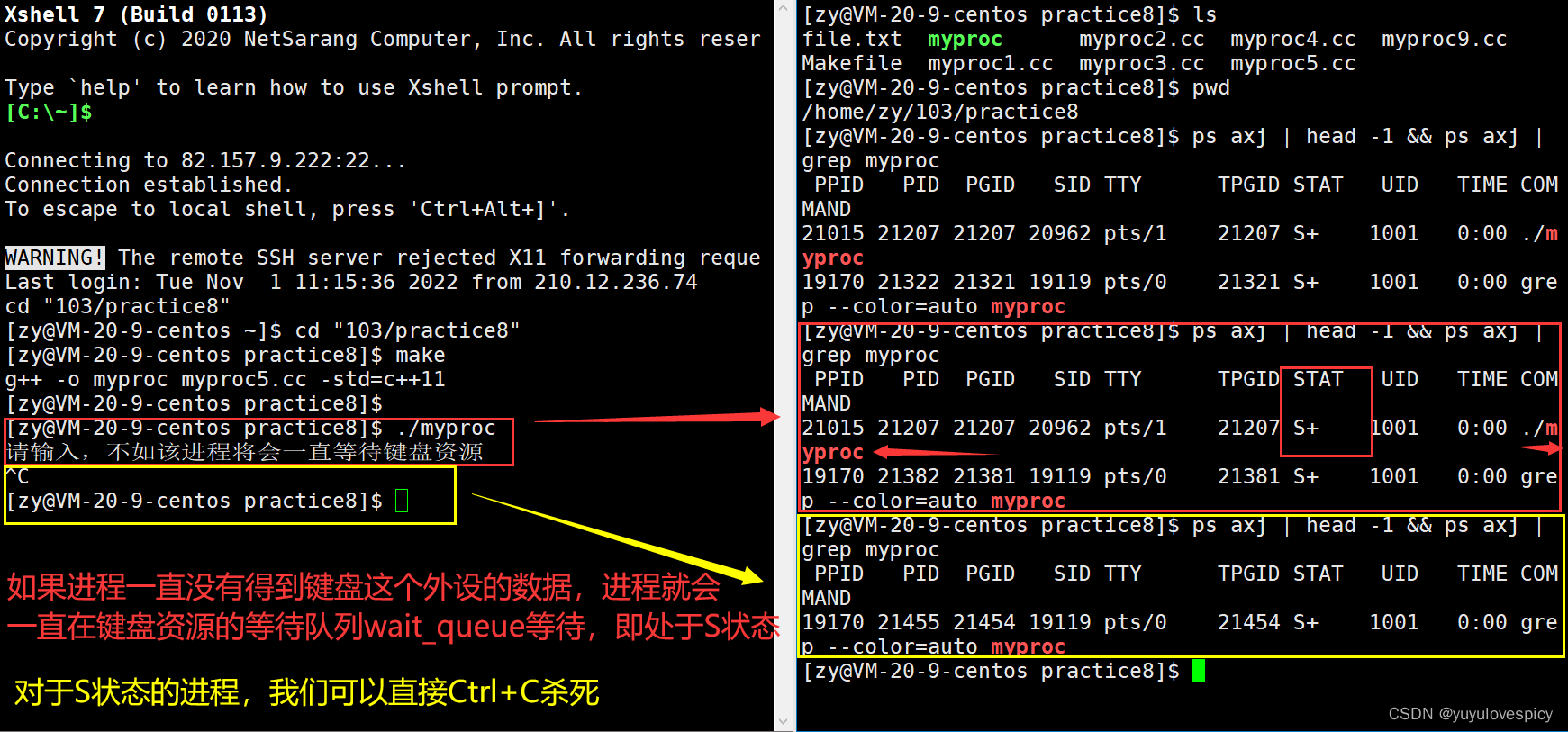
进程在等待键盘这个外设资源(输入设备)的数据时,在键盘的等待队列wait_Queue中等待,处于的就是S状态。
3.2.2 S状态复杂示例
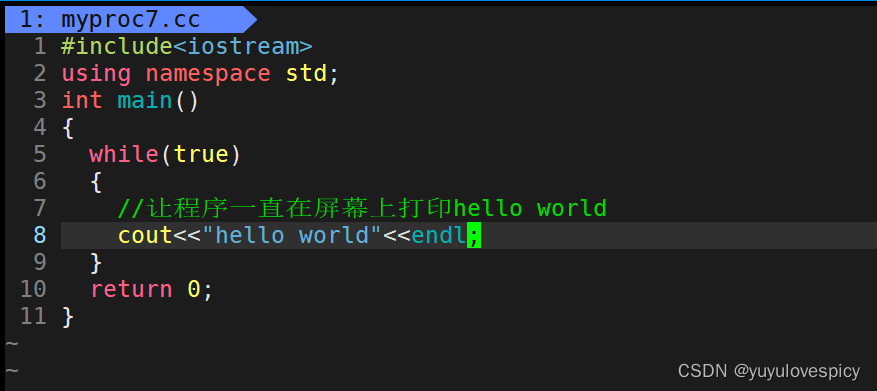

此时我们惊奇的发现,这个进程明明执行的逻辑是一直cout打印hello world,应该是一直在执行,一直处于R状态呀,而且我都打印出来了,肯定也在CPU上执行了呀,那为什么会出现检测到该进程一直处于S状态呢?
首先我们明白,S状态表面这个进程在等待某个外设资源,而这个进程要执行的逻辑就是打印,能涉及到的外设就是显示器,显示器也不是一直可以被这个特定的进程使用的,所以这个进程处于S状态,是在显示器的wait_Queue等待队列当中。而这个确实执行了打印逻辑,所以肯定在某些个时刻,是处于R态,享受CPU资源或处在运行队列当中的。
我们可以确定,这个进程既有R态,也有S态,那为什么检测出来的都是S态呢?这肯定是因为这个进程的绝大部分时间都是处于S状态,所以我们监测到的也基本上是S状态,R状态很难被捕捉,那为什么绝大部分时间是处于S状态而不是R状态呢?
cout<<"hello world"<<endl , 这个语句是在进行到屏幕上的打印,是从内存打印到外设(输出设备)output的过程,也即I/O过程,IO从内存到外设,这个过程的效率是很慢的!
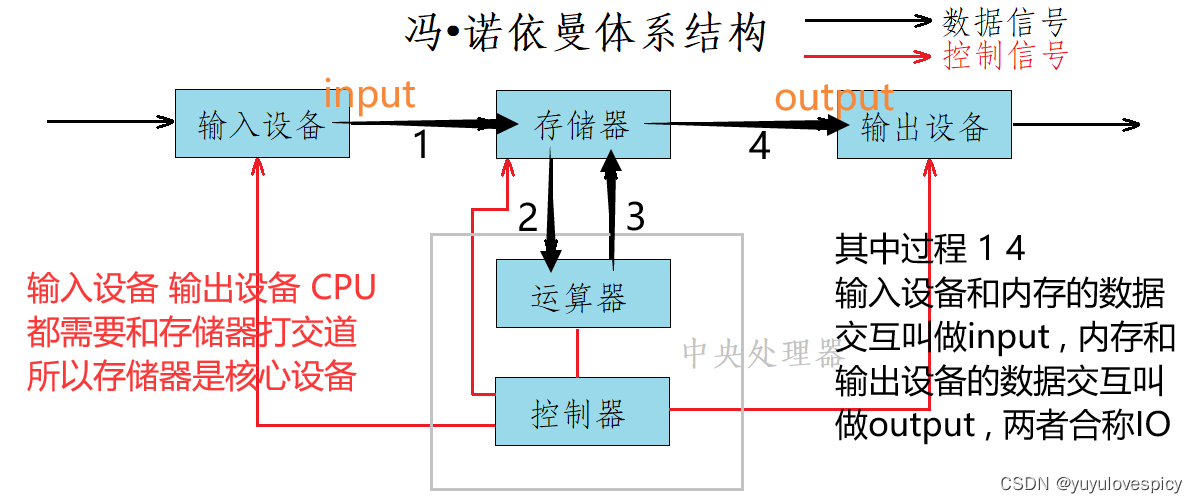
所以进程每做一次打印,打印的数据就要经历从内存到外设经过漫长的IO。同时,显示器也不是每时每刻都能被打印的,进程需要等待每一次输出设备--显示器的就绪,所以其实进程等待的时间是远长于进程在CPU上执行打印的时间的。
在追求效率以及速度极快的CPU看来,你等待硬件资源的时间太长了,会损耗我CPU的运行效率,所以CPU就把你这个进程的PCB从运行队列放到等待队列里去了,也就是从R状态->S状态,然后长久的处于S状态,显示器就绪后再短暂的回到运行队列R执行,之后再回来,周而复始。这才是较为完整的逻辑。
所以其实这个进程并不是用户感官上认为的那样,这个进程并不是一直在R运行,而是其实,大部分时间都处于S(sleeping 休眠)等待状态,等待显示器资源的就绪,毕竟打印需要显示器资源就绪,就需要IO,而IO是非常非常慢的,实际R运行的时间是非常少的。
我们再对比一下,加深一下理解:
while(true); vs while(true){cout<<hello world;}
Test1:while(true); ->
Test2:while(true){cout<<hello world;} ->
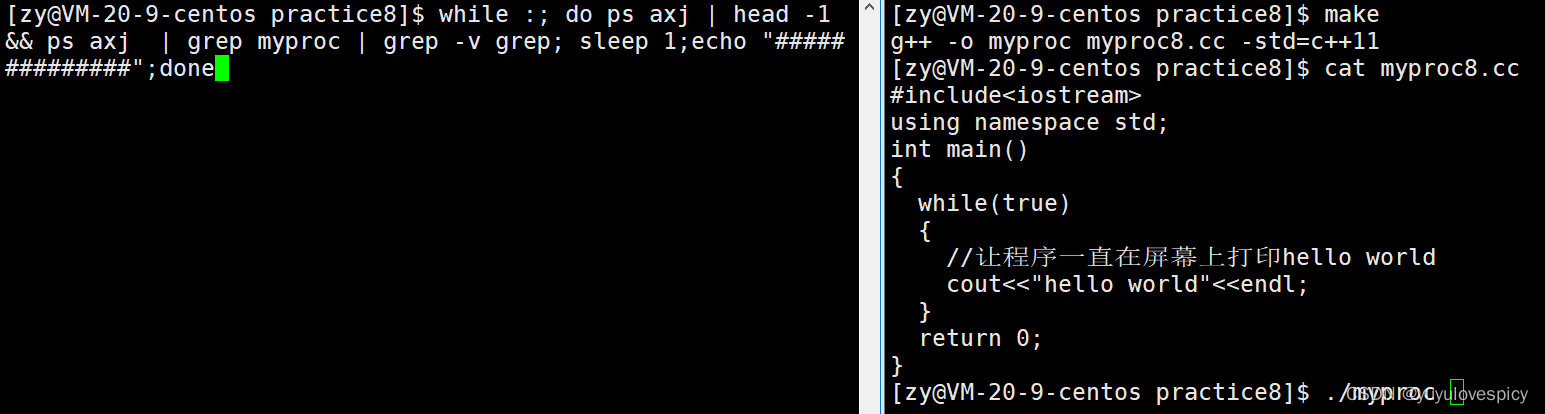
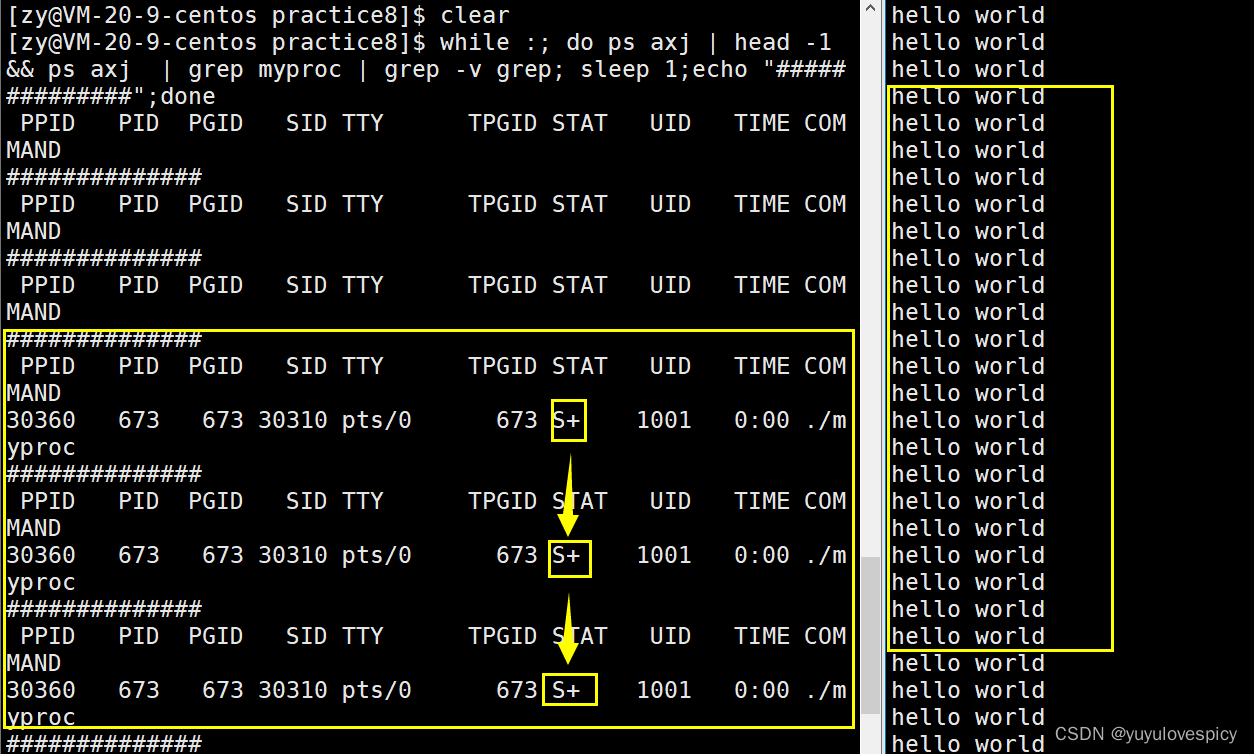
前者while(true);死循环执行,是不需要等待什么资源的,可以直接被CPU执行,所以也就是说,会一直在运行队列run_Queue中,一直处于R状态。
而后者 while(true){cout<<hello world} ,需要等待显示器资源就绪,才能完成打印,其大部分时间不在CPU执行,而是在显示器资源的等待队列wait_Queue里等待,所以大部分时间都是处于S状态,而只有小部分时间处于R状态。

3.3 T暂停状态演示
3.3.1 T状态进程演示
T状态,是进程直接暂停的状态,任何数据不会再有改变,在现实中看就像时间暂停一般。那我们如何中断暂停一个正在运行的进程呢?
我们要通过使用信号的方式,来暂停进程 ,当然具体信号的概念我们在后面的博客讲,我们首先讲操作系统中信号的使用。
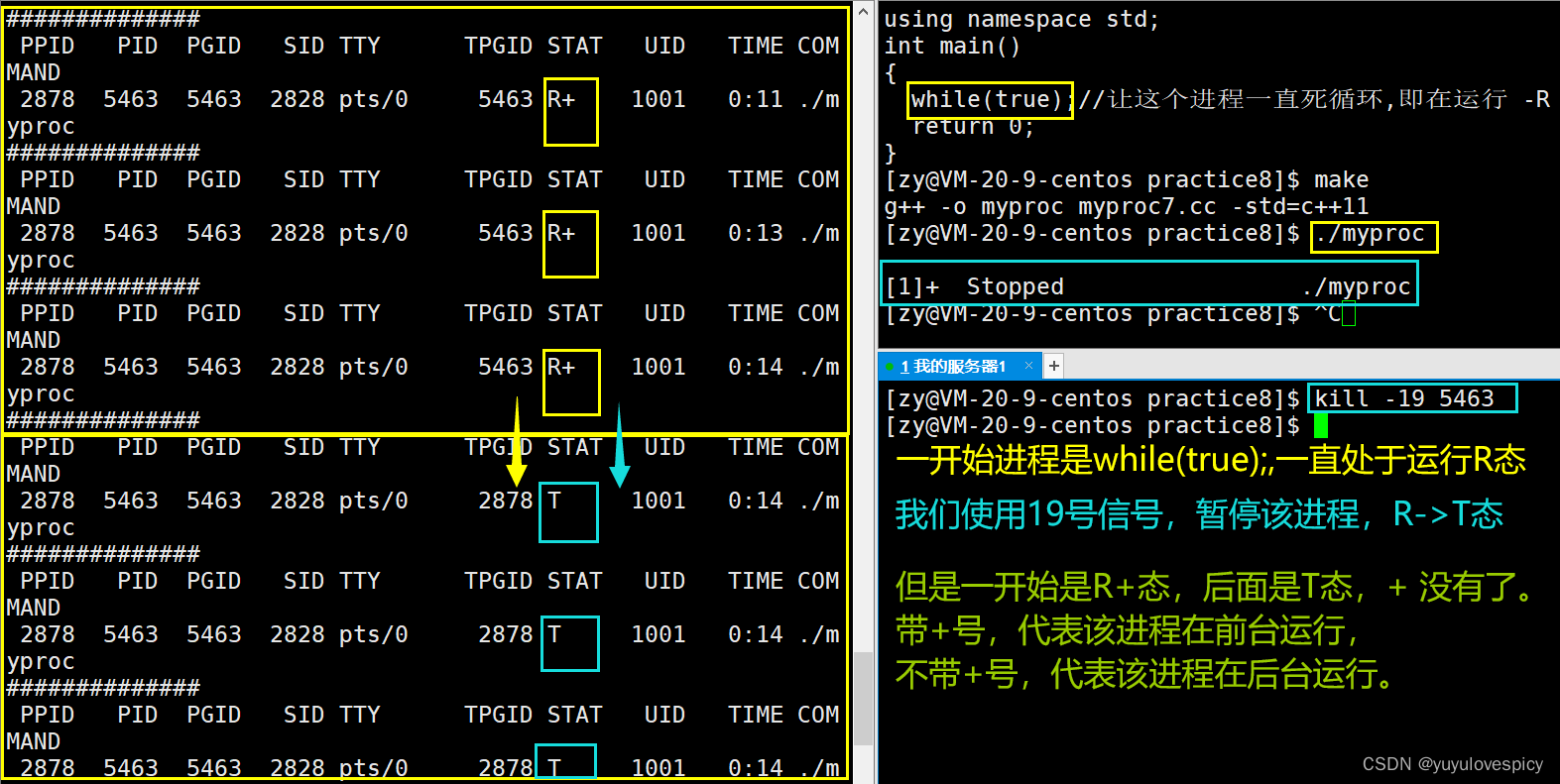
所以我们可以通过指令 kill -19 PID , 就可以暂停PID进程,从而该进程中断执行,该进程就变成了T状态。下面我们做实验:
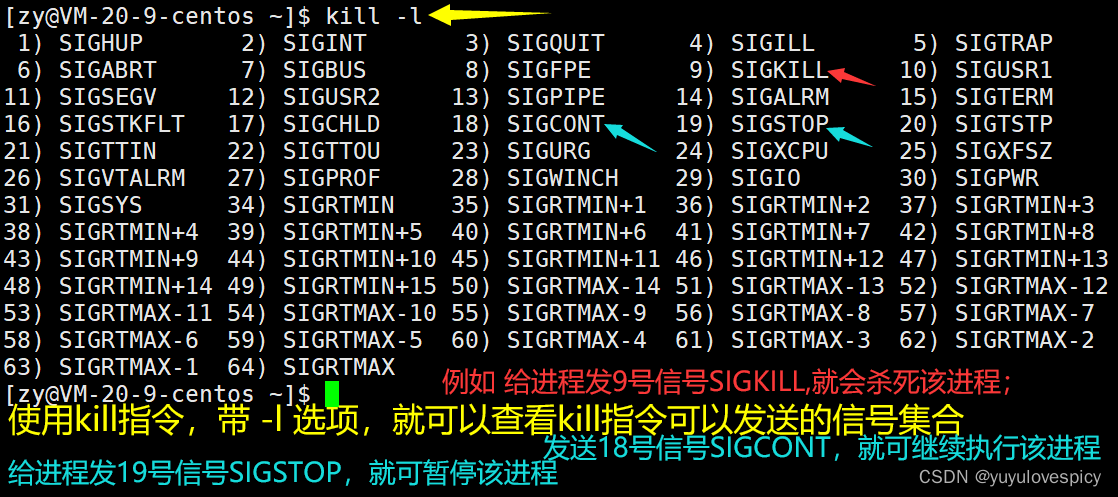
关于前台进程,后台进程,这对概念我们在后面讲述,我们这里主要演示T状态。
下面我们演示18号信号,SIGCONT,可以让中断暂停的进程continue继续跑起来。

对处于R+状态的进程发送19号信号SIGSTOP,将进程暂停,会将这个进程由前台运行变成后台运行。
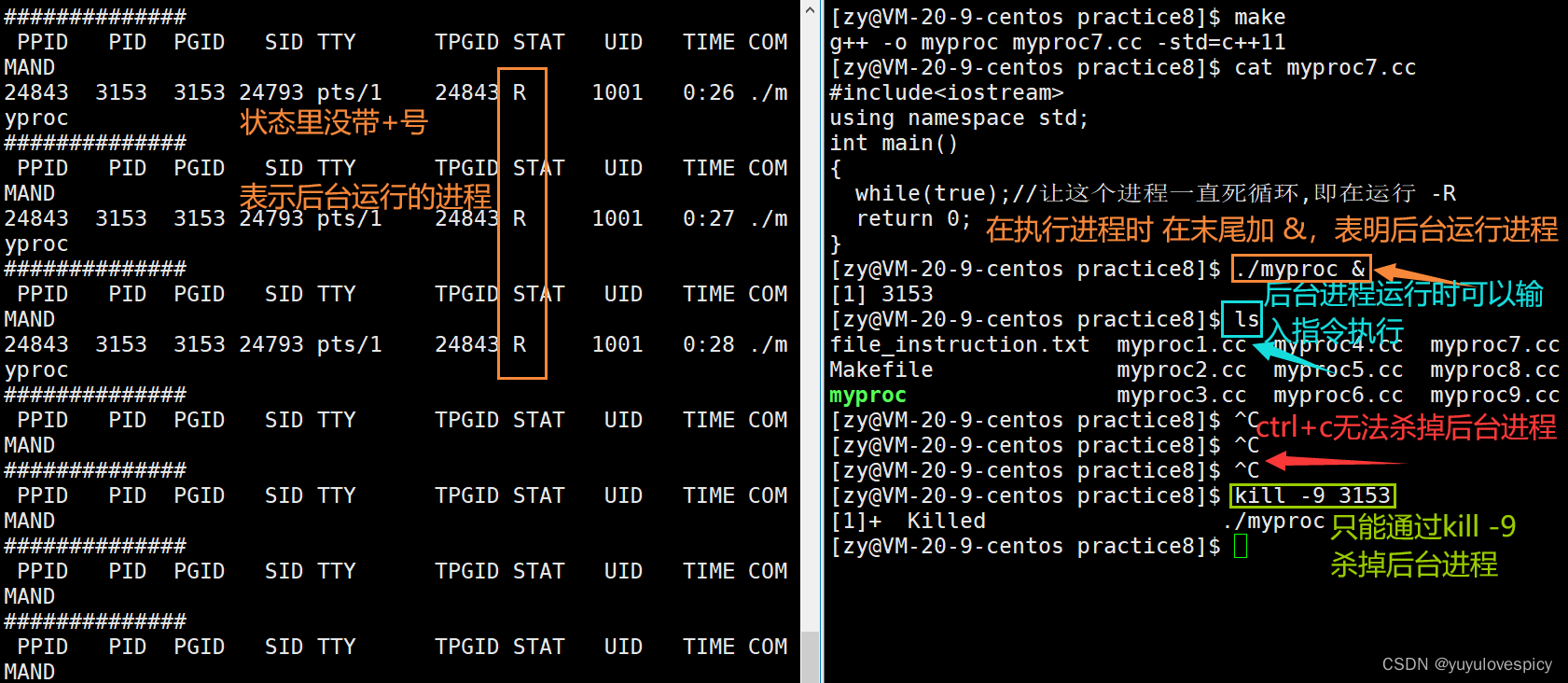
我们可以发现一个现象,无论进程现在处于T状态,还是R状态,这些不带+号的后台进程(当然排除普通的R+状态 带+号表示前台进程),现在 我们Ctrl+C想删除这个myproc进程是没有办法的,这其实是后台进程的特性。

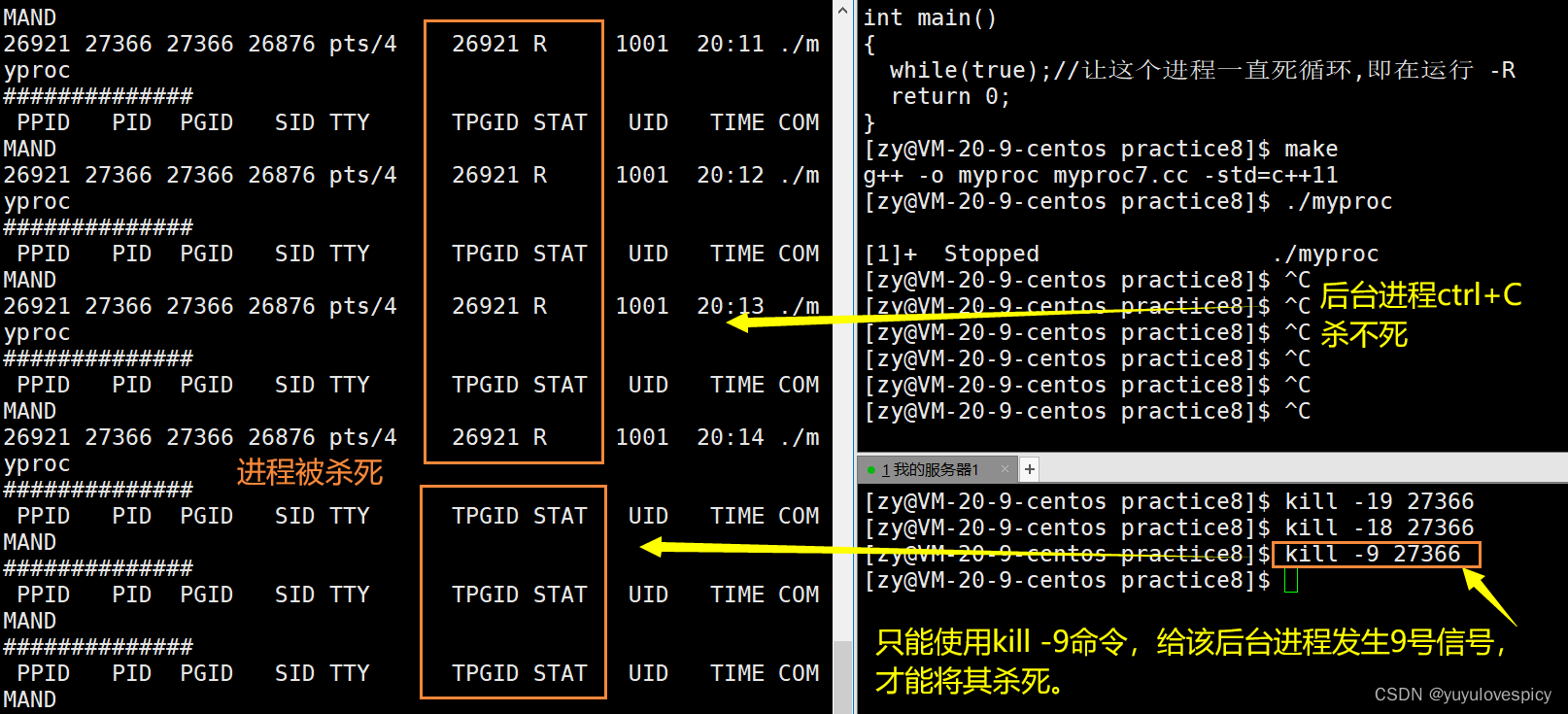
3.3.2 前台运行&&后台运行
在系统中运行进程,进程可以在前台运行,也可以在后台运行,我们平时在命令行上执行的程序,fork创建的子进程,都是让进程在前台运行。那如何让进程在后台运行呢?前台进程和后台进程有什么区别呢?
让程序在前台运行:平时直接在命令行上敲./proc 执行起来的程序,后续就是前台运行的进程。
前台运行的特点:
1.在前台执行的进程可以被 ps axj 指令监控到是带+号的状态的(如R+)。
2.我们Ctrl+C是可以直接杀死这个进程的。当然kill -9 PID也可以杀死。
3.在前台进程执行的时候是无法执行ls,pwd等指令的。
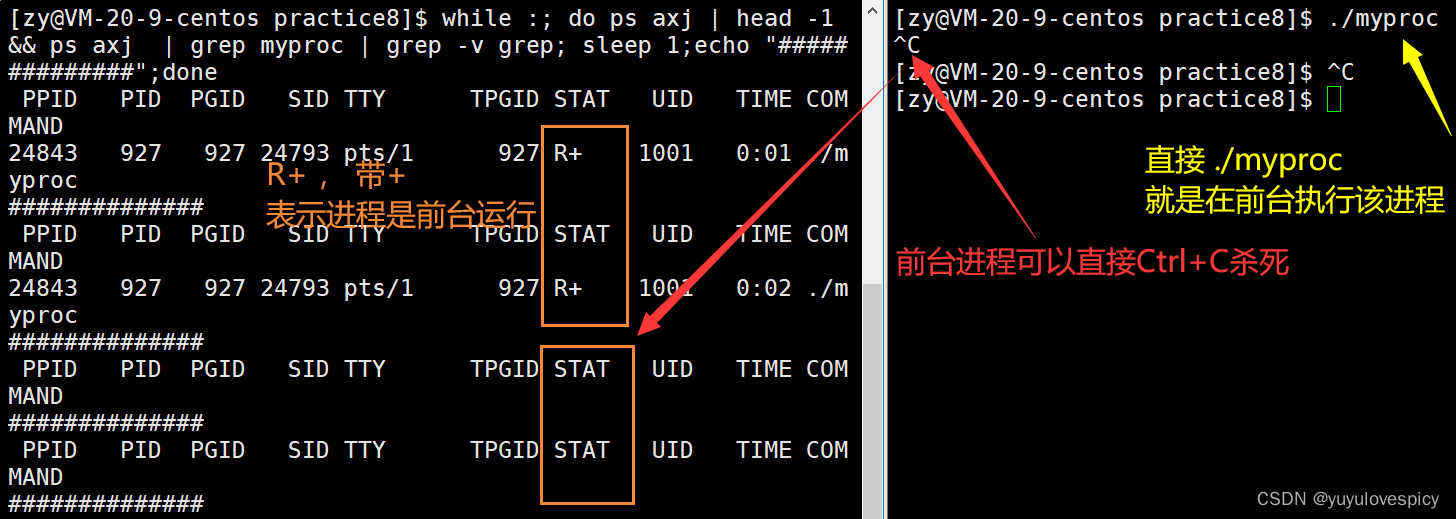

让程序在后台运行:除了刚才给运行的进程发19 18号信号,让进程变为后台进程,我们通常是在执行程序时在后面带一个&号,使该进程在后台运行。
后台运行的特点:
1.在前台执行的进程可以被 ps axj 指令监控到是不带带+号的状态的(如R,T等)。
2.我们Ctrl+C是可以直接杀死这个进程的,只能通过强大的 kill -9 PID指令杀死。
3. 后台运行的进程,在命令行上输入ls pwd mkdir是可以直接执行的。
3.4* Z僵尸状态演示
3.4.1 Z状态进程的回收
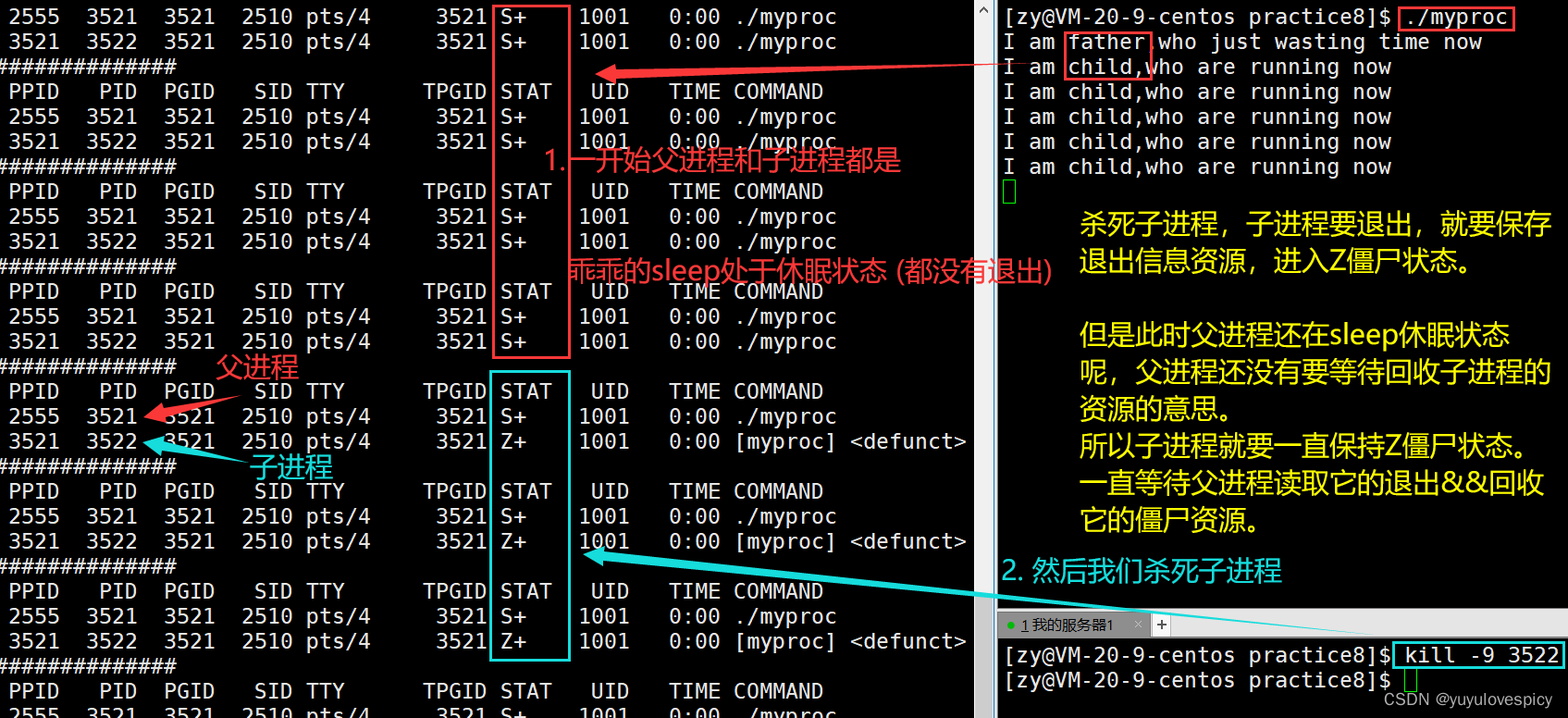
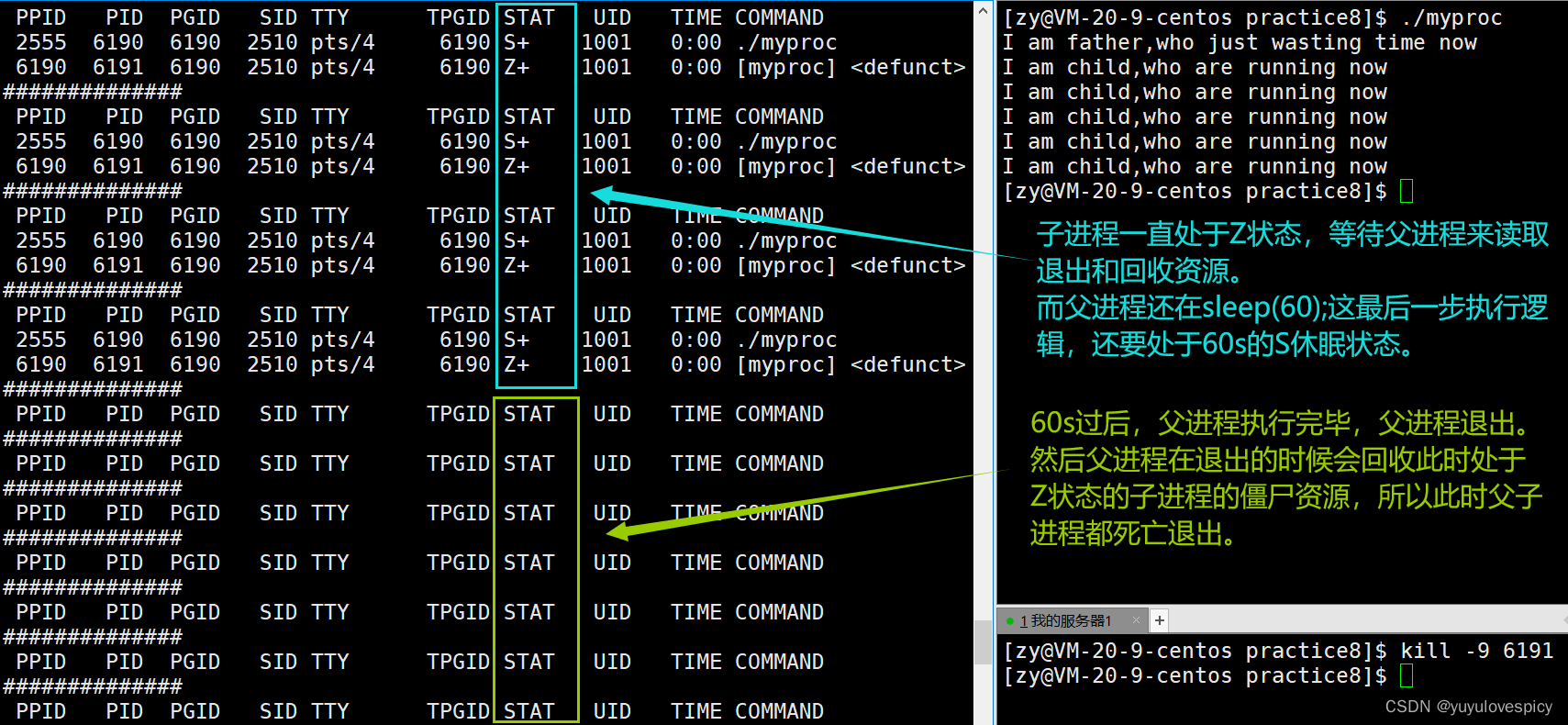
如果一个进程运行完毕要退出了,这个进程就要保持住自己的退出信息到PCB中,以供父进程/系统去读取,而不会回收进程的全部资源。这个进程要退出,而资源没有被回收的过程,进程所处的状态就是Z僵尸状态。
回到我们刚刚调查死因的例子,如果这个人的遗体一直在风中凌乱,没有被警察法医调查完死因,同样此时后事部门没有被警察通知,所以也就没有后事部门去回收,那其实死者的遗体就会一直在风中凌乱,这其实在现实中影响是非常恶劣的。
同样的类比,如果这个进程处于Z状态,即此时进程还有没有被回收完毕的退出信息资源。如果这个进程的的退出信息资源一直没有被父进程/系统读取到,同时资源也就没有被回收,那就会一直处于Z状态,一直占用系统资源。
故死者的遗体需要被警察知道,然后二板斧:警察组织调查死因,警察通知后事部门回收。
要退出的Z进程也需要被知道,然后被组织读取退出信息,并被回收。
死者的遗体由警察去负责,那负责这个进程的退出信息读取和回收任务的是谁呢?
这当然是这个进程(子进程)的父进程!!!
所以子进程在退出,退出信息资源保存在系统中,处于Z状态的时候,这时候就需要父进程来进行对子进程退出信息的读取,以及由父进程读取退出信息后的回收该进程的僵尸资源,之后这个进程就可以由Z状态变X状态,最终死亡。
当然如果父进程一直没有去读取退出信息,一直没有回收这个子进程的僵尸资源,那这个子进程就会一直处于Z状态,一直占用系统资源。我们在后面博客会讲,父进程可以通过进程等待的方式来对子进程进行退出读取以及资源回收。
所以接下来我们就从父子进程这重关系入手,来看子进程的Z状态。
3.4.2 Z状态验证1
如果我们父进程和子进程在运行的时候,突然杀死子进程,要让子进程退出,此时会发生什么呢?
根据之前的理论,遗体不会被立即回收,而是要首先被警察知道,然后警察组织调查死因&&之后后事部门的通知。
子进程当然会保存自己的退出信息,处于Z状态,等待父进程对退出信息的读取&&子进程资源的回收。下面我们看具体演示:


上面我们是在父子进程在运行的生活,我们首先杀死子进程,对Z僵尸状态的验证。那如果我们首先杀死父进程呢?
3.4.2 Z状态验证2
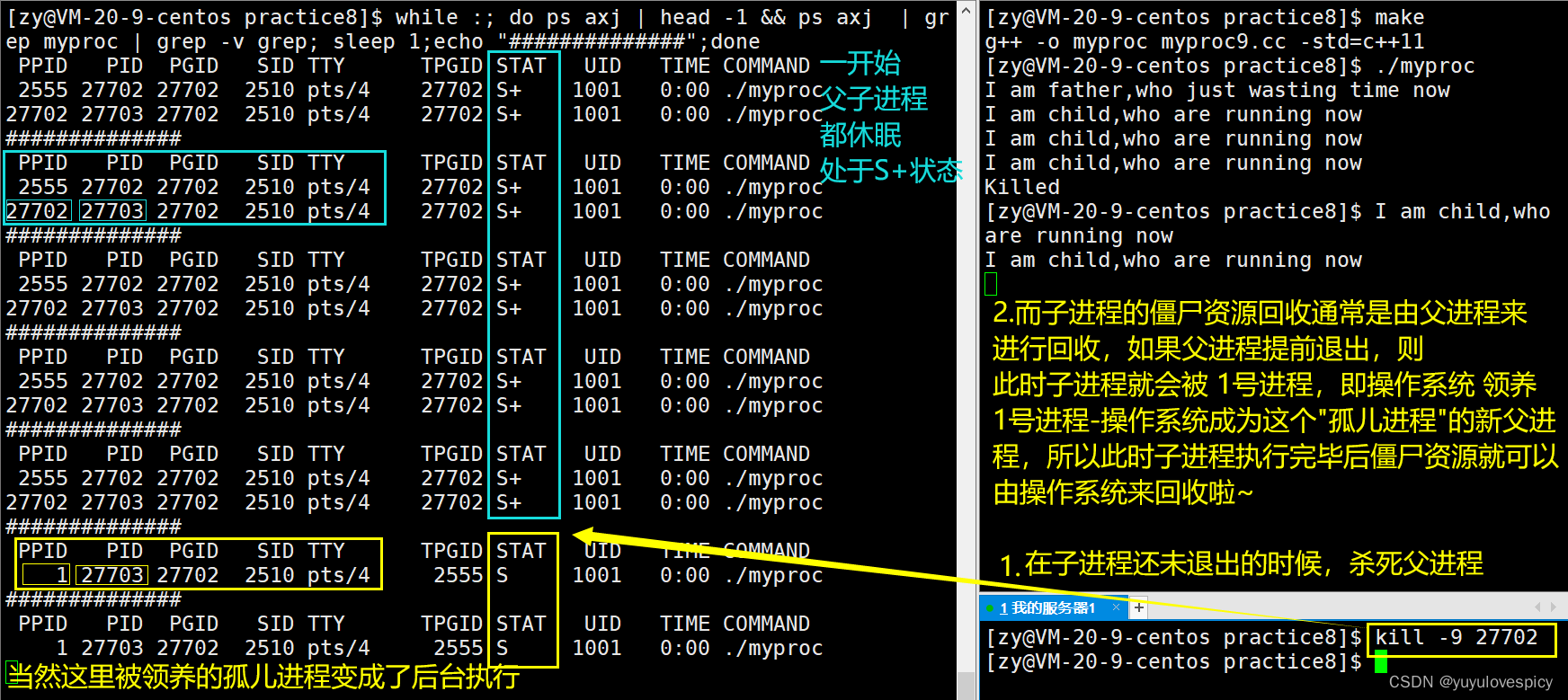
如果让父进程先于子进程退出,那子进程就会没有父进程了!这其实是非常严重的事情,因为子进程的退出信息需要父进程读取,子进程的Z僵尸资源需要被父进程回收!如果没有父进程的话,那这个被“抛弃”的子进程的僵尸资源就无法被回收,就会一直占用系统资源!其实这个被父进程“抛弃”的子进程有个特定称谓----孤儿进程。
在现实中,当一个小孩纸被父母抛弃的时候,会有好心人来领走抚养。在Linux操作系统当中,当父进程先于子进程退出时,对该类子进程会有一个类似的解决方案,那就是领养。
当子进程的父进程先于子进程退出时,子进程会被1号进程(PID==1)领养,1号进程成为该子进程的新父进程,这个1号进程其实就是操作系统。所以当这个子进程运行结束退出的时候,就由1号进程来读取退出信息,由1号进程来回收它的僵尸资源~