
- 1解决在安装器中打开APP后,当APP从后台回到前台时,会重新启动的bug_app第一次安装完后退到后台再唤醒到前台会重启一边
- 2网易2020届预研(计算机图形学方向)实习面经_图形学面经
- 3【CSS 画个梯形】_css画梯形
- 4Linux进阶之 cd 命令_cd 到开始节点
- 5python安装pandas库,安装不成功原因分析及解决办法_pip install pandas
- 6signature=38e82e3947403ac896e5df4c12940bc1,check/yarn.lock at master · GraphQL-Training/check · GitH...
- 7竞赛 大数据疫情分析及可视化系统_疫情大数据exc
- 8Linux下通过Shell脚本快速进入指定目录_linux sh 进去目录
- 9基于Unity3D的RPG游戏的设计与实现(论文+源码)_kaic_unity3d论文游戏参考文献
- 10Pandas:DataFrame的行列操作_dataframe 整列 操作
详解低延时高音质:丢包、抖动与 last mile 优化那些事儿
赞
踩

本篇是「详解低延时高音质系列」的第三篇技术分享。我们这次要将视角放大,从整个音频引擎链路的角度,来讲讲在时变的网络下,针对不同的应用场景,如何权衡音质和互动的实时性。
当我们在讨论实时互动场景下的低延时、高音质的时候,我们其实要面对的是从端到端整个音频引擎链路上的音质问题。我们在第一篇文章中,简单的描绘过一条音频传输的过程,如果在该基础上再进一步细化,音频引擎的整个链路包含以下各步骤:
1. 采集设备对声学信号进行采样,形成计算机可操作的离散音频信号;
2. 由于音频信号的短时相关性,将音频信号进行分帧处理,经过 3A 解决方案处理声学、环境噪音、回声、自动增益等问题;
3. 编码器对音频信号进行实时压缩,形成音频码流;
4. 根据 IP+UDP+RTP+Audio Payload 的格式组包后发送端将音频数据包发向网络,重组经过网络到达接收端的数据包;
5. 经过抗抖缓存和解码器重建连续的音频流,播放设备将连续的音频流播放出来。
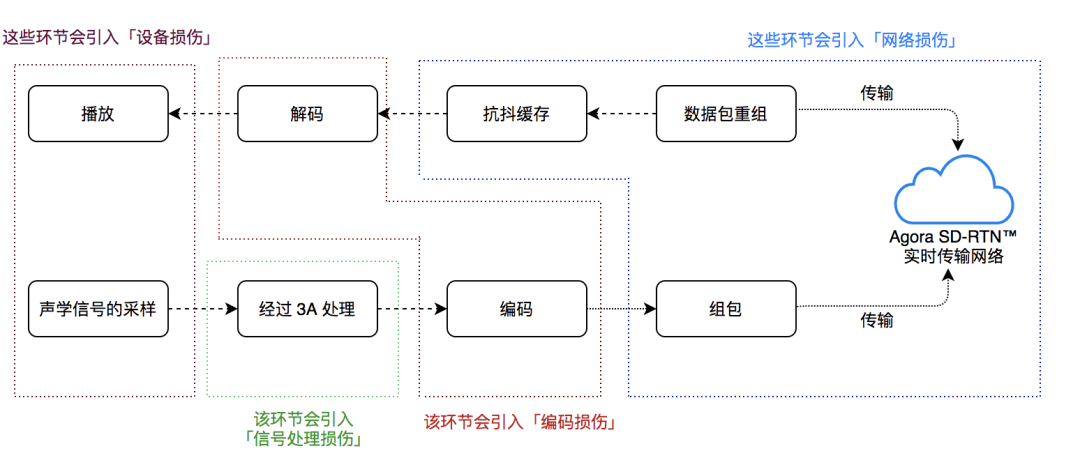
在以上不同的音频处理环节中,都会不可避免地对音频信号产生一些损伤。我们将上述因采集、播放而对音频信号引入的损伤称为「设备损伤」,在环节 2 引入的损伤称为「信号处理损伤」,在编码与解码过程中引入的称为「编码损伤」,环节 4 中的称为「网络损伤」。
如果要为用户提供全频带的高质量音频互动体验,就需要在上述的音频引擎链路支持全频带的处理,并在一些约束条件下(比如来自设备、网络带宽、声学环境等),将各个环节引入的损伤尽可能降低到最小。
当音频数据进入网络,它会遇到……
如果将网络视作信息的公路,那么音频数据包就像是一辆辆跑在公路上的车。这辆车从北京开到上海,途径的高速公路就是主干网络,崎岖山路就是弱网环境。假设每分钟都有一辆车从北京出发上路,那么他们会遇到三个实时传输中的常见问题:丢包、延时、抖动。
丢包
“丢包”指的是有的车无法在有效时间内无法达到终点,甚至可能永远也到不了终点。有的车可能永远堵在北京的三环上了,有的车可能中途出了车祸。假如我们的一百辆车里有五辆车因为各种原因没能按时到达上海,我们这次车队传输的“丢包率”就是 5%。是的,互联网传输也一样,它并不是百分百可靠的,总有数据无法按时传输到目的地。
延时
“延时”指的是每辆车从北京鸟巢开到上海的平均时间。显然,车队走高速公路肯定要比走各种小公路快很多,而且从鸟巢出发沿着怎样的路线开上高速公路也有很大影响,万一堵在了三环可就要多花好几个小时了。所以这个值和车队选择的行驶路线有关。互联网传输也是一样的道理,需要传输数据的两点之间经常是有很多可选路径的,而这些路径的延时往往相差很大。
抖动
“抖动”指的是车子到达的顺序、间隔和出发时的差异。虽然我们的一百辆车在北京是等间隔的一分钟一辆出发的,但是它们到达上海时却并不是按顺序一分钟一辆到达的,甚至可能有晚出发的车比早出发的车先到的情况。互联网传输也一样,如果简单地按照收到的音视频数据顺序直接播放出来,就会出现失真的现象。
总结来讲:
1. 在网络上进行实时的音频交互,编码后的音频码流根据实时传输协议组装成数据包。其中数据包从发送端按照各自的路线经过网络前往接收端。
2. 全球范围内,不同区域或者不同时间段,用户网络连接的服务质量有时非常差,且不可靠。
基于上述原因,数据包往往不是按准确的顺序到达接收端,而是在错误的时间以错误的顺序到达接收端,或数据包丢失等,这就会出现实时传输领域通常提到的问题:网络抖动(jitter),丢包(packet loss),延时(latency)。
丢包、延时、抖动,是基于互联网进行实时传输不可避免的三个问题,不论是在局域网、单一国家地区内传输,还是是跨国、跨地区传输,都会遇到。
这些网络问题,在不同区域的分布不同,以声网Agora 监控的网络实况来看,在网络相对较好的中国地区,99% 的音频互动需要处理丢包、抖动和网络延时等。这些音频会话中,20%由于网络问题会有超过 3% 的丢包,10%的会话有超过 8%的丢包。而在印度的表现差异较大,80%的音频互动中,大约有 40% 的会话丢失。在印度地区优化 2G/3G 网络下的服务质量,仍是提供音频服务的重点。
抖动、延迟、带宽的限制也是很多的,这些网络问题导致音频质量急剧下降,更甚者,影响音频信号的可懂度,即不能满足交换信息量的本质通信需求。因此,不论对于使用 WebRTC 的自研团队,还是提供实时服务的 SDK 服务,尝试修复这个过程中对音频信号引入的损伤,都是必修的课题。
丢包控制
为保证可靠的实时互动,处理丢包是必须的。如果没有提供连续的音频数据,用户会听到卡顿(glitches、gaps),降低了通话质量和用户体验。
丢包问题可以抽象为,如何在不可靠传输的网络上,完成可靠传输。通常使用前向纠错 FEC(Forward Error Correction)和 自动重传请求 ARQ(Automatic Repeat-reQuest)两个纠错算法,根据准确的信道状态估计制定相应策略来解决丢包问题。
FEC 是发送端通过信道编码和发送冗余信息,接收端检测丢包,且在不需要重传的前提下根据冗余信息恢复丢失的大部分数据包。即以更高的信道带宽作为恢复丢包的开销。相比ARQ的丢包恢复,FEC 体验上的延时更小,但由于发送了冗余的数据包,所以信道带宽消耗较多。
ARQ 使用确认信息 ack(acknowledgements signal,即接收端发回的确认信息表征已正确接收数据包)和 timeouts,即如果发送方在超时前没有收到确认信息 ack,则通过滑动窗口协议帮助发送端决策是否重传数据包,直到发送方收到确认信息 ack 或直到超过预先定义的重传次数。相比 FEC 的丢包恢复,ARQ 延时较大(因为要等待 ack 或不断重传),带宽利用率不高。
简单讲,丢包控制中使用的 FEC、ARQ 方法是通过额外的信道带宽,以及延时对丢失的数据包进行恢复。这就是传统抗丢包方法的现状,那么有什么可行的方法能解决呢?
我们就以之前开源的 Agora SOLO 为例。通常,编解码器做的事情是压缩、去冗余,而抗丢包从一定程度上讲是信道处理的扩大化。抗丢包是一种纠错算法的扩展,通过加冗余实现抗丢包。而 Agora SOLO 的策略,是把去冗余和加冗余进行结合,对重点信息加冗余,对非重点信息则更多的去冗余,以达到在信道和信源的联合编码的效果。
延时、抖动控制
数据包在网络传输、排队时本身就会产生延迟、抖动。同时,我们通过丢包控制恢复的数据包也会引入延时和抖动,通常使用自适应的 de-jitter buffer 机制进行对抗,确保音频等媒体流连续播放。
正如我们上文比喻的,数据包延迟的变化,我们称之为抖动(jitter),是一条音频流或其他媒体流数据包之间端到端单向延时的差异。自适应的逻辑是基于数据包到达间隔(IAT,inter-arrival times)的延时估计进行决策。当出现丢包控制未恢复的数据包、过度的抖动、延时、突发丢包,即超出自适应缓存可对抗的延时时,就会出现卡顿。此时接收端一般使用 PLC(Packet Loss Concealment)模块预测新的音频数据,以填充音频数据缺失(由于丢包、过度的抖动和延时引入的丢包、突发丢包)等产生的不连续的音频信号。
综上所述,处理网络损伤,是在不可靠的通信信道上面,通过丢包、延时、抖动控制方法确保数据包尽可能的顺序输出,结合 PLC 预测填充音频数据的缺失。
要尽可能减小网络损伤,需要结合以下五点增强弱网边界:
1. 准确的网络信道状态的估计,动态的对丢包控制的策略进行调整和应用;
2. 以及相配套的 de-jitter buffer,以更快、更准的学习速度适应网络的非稳态(好网络转差,差网络转好,突发的梳状网络)的变化,调整抗抖缓存至大于且更接近于稳态时等价延时的大小,才能确保收听者在该瞬时网络环境下的音质好,延时低,逐渐趋于理论最优;
3. 超出弱网可恢复边界时,通过降低码率(也常用来解决信道拥塞),提升信道带宽中冗余数据或重传次数的开销;
4. 并结合 PLC 对输入信号的适应能力,确保不同说话者,时变的背景噪声下尽可能的减小可察觉的噪声;
5. 在较小带宽下,通过编码器编码低码率且高质量的语音,结合3在网络服务质量差的情况下,增加弱网对抗的鲁棒性。
基于以上在丢包、延时、抖动的对抗策略,我们就可以基于互联网传输,提供更好的音频实时互动体验。就像我们之前说的,不同地区、不同时间段、不同网络下,网络的延时、抖动、丢包情况都不同。而声网Agora SDK 是面向全球提供高质量的音频交互服务,让全球各区域的用户在线上进行实时互动,通过音频引擎尽可能将线下的声学体验带给用户。因此我们也做了多次实地的测试,并观察 SDK 的 MoS 分(ITU-T P.863)和延时数据表现。
以下是我们在上海中环环线,使用相同设备,在相同运营商网络下,同时测试的Agora RTC SDK与友商产品的 MOS 分和延时数据。从统计来看,声网Agora SDK提供的实时音频交互服务,在提供较高音质的同时,延时更低。
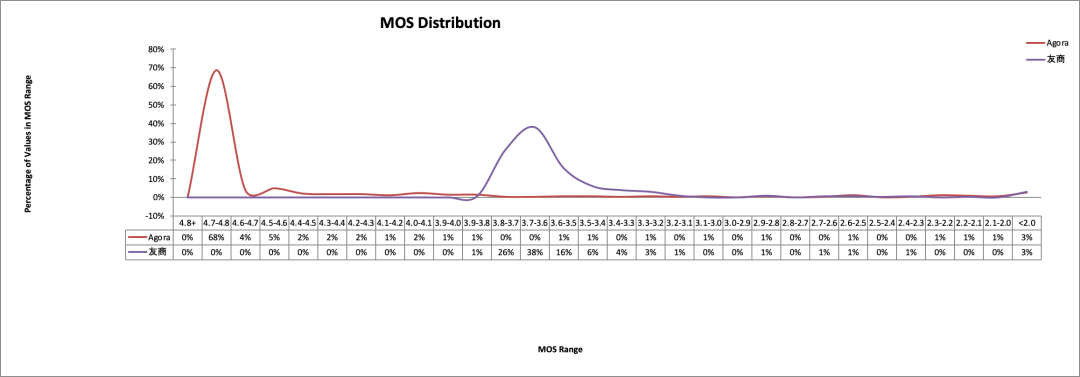
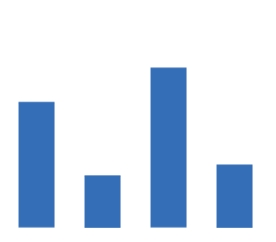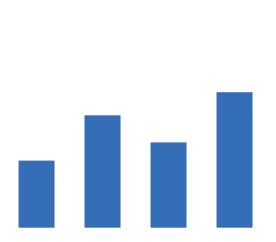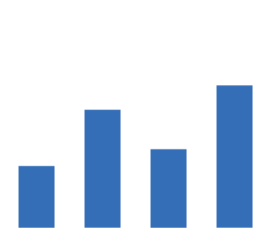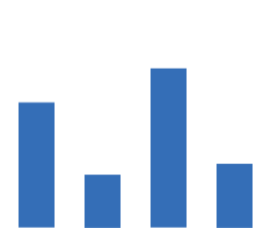
图:MoS 分对比
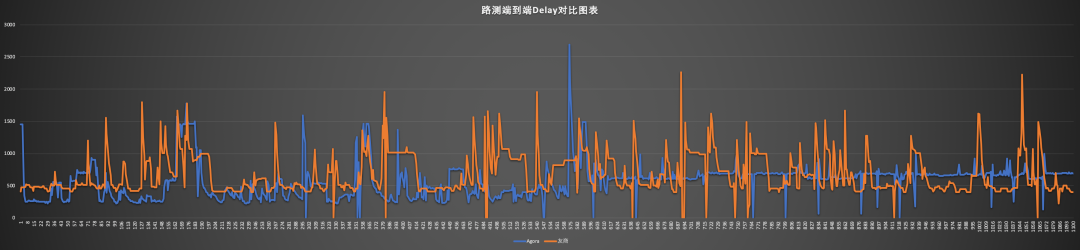
图:延时数据对比
可以从 MoS 分对比图看出,Agora SDK 的 MOS 主要分布在高分值[4.5, 4.7]区间段,友商主要分布在[3.4, 3.8]。再说一个数据大家可能会有更直观的概念。我们使用的微信,尽管与 RTC SDK 不属于同一类型的产品,但也提供语音通话服务。微信在无弱网环境下测量的最高 MoS 分是 4.19。
用户体验的实际音频质量,可由以下音频质量地图中圆点的颜色显示,绿色表示 MOS 分大于4.0;黄色表示 MOS 分处于[3.0, 4.0],红色表示[1, 3.0]。
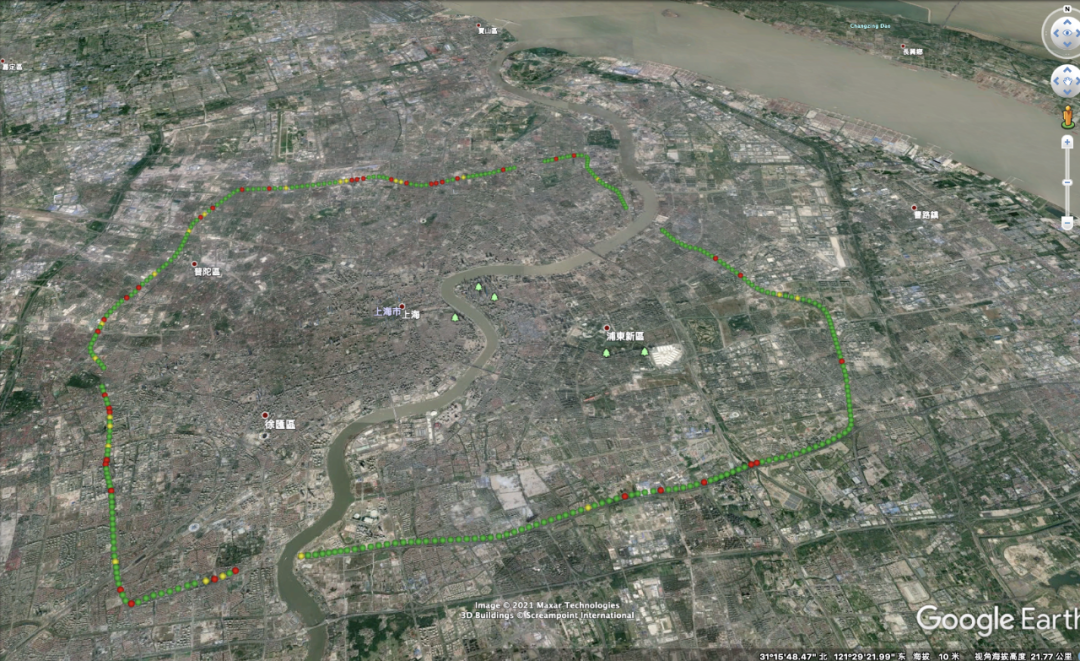
图:上海中环,Agora SDK 的音频质量

图:上海中环,友商 的音频质量
小结
丢包、延时、抖动是在实时互动场景下不可避免的问题。而且这些问题不仅会由于网络环境、时段、用户设备等因素不断产生变化,也会由于底层技术的发展而产生新的变化(比如 5G 的大规模应用)。所以我们针对它们的优化策略也要不断迭代优化。
在跟随音频信号从发送端经过网络到达接收端之后,音频体验的优化并没有结束。为了“高音质体验”,我们还要进一步在端上优化音质,下一篇我们详细分享其冰山一角,敬请期待。
相关阅读
END

