
热门标签
热门文章
- 1STM32的常用C语言_stm32c语言编程300例
- 2webpack打包的dist文件,如何查看页面效果!_打包后的dist文件 发给别人怎么看效果
- 3爬虫 — 验证码反爬_网络爬虫验证码逆向
- 4为国产发声!原来国内版Devin早已问世!?_devin如何使用
- 5项目中遇到的问题及解决方式_no matching version found for @babel/plugin-propos
- 6华为交换机看DHCP分配_网络IP地址应该如何进行分配?IP地址的有效分配管理方法...
- 702-Kubernetes中的NameSpace与Pod
- 8如何在VMWare的Ubuntu虚拟机中设置共享文件夹
- 9W806的编译环境准备_w806 upgrade tool打印cc
- 10LF-YOLO
当前位置: article > 正文
2.1 经验误差与过拟合 机器学习
作者:笔触狂放9 | 2024-03-07 11:01:01
赞
踩
2.1 经验误差与过拟合 机器学习
通常我们把分类错误的样本数占样本总数的比例称为“错误率”。即若m个样本中有a个样本分类错误,则错误率为E=a/m;相应的,1-a/m称为“精度”,即精度=1 - 错误率。
更一般的,我们把学习器的实际预测输出与样本真实输出之间的差异称为“误差”。学习器在训练集上的误差称为‘训练误差’或‘经验误差’,在新样本上的误差称为‘泛化误差’。显然,我们需要泛化误差较小的模型。但是因为很多时候我们不知道新样本是什么样,实际上我们只能尽量减少经验误差。
但是倘若一个学习器在训练样本上几乎完美,那么这是否是一个我们需要的模型呢?实际上,这样的模型往往不是我们所需要的。因为请注意,我们所需要的是在新样本下依然能良好适配的学习器。我们想要的是一个‘普遍规律’。在训练样本上训练过好的学习器,很有可能把训练模型的自身特性当成了我们的普遍存在的所有潜在样本的一般性质。这样就会导致泛化能力下降,这种现象我们成为“过拟合”。所以往往我们的学习器不是特别“精准”。与之相对应的是“欠拟合”,这是指对训练样本的一般性质尚未学好。如下图:
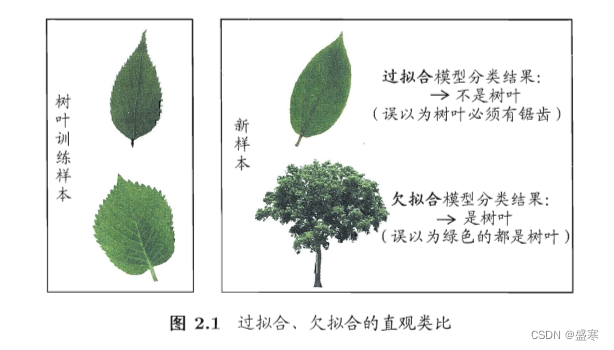
当我们遇到新样本时,倘若我们的学习器过拟合,会把叶子上的锯齿误认为叶子的普遍特征,这样就导致没有锯齿的叶子不是树叶。如果欠拟合,会把树也误认为树叶。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/205208
推荐阅读
相关标签

