
- 1Postman 9.12.2安装及汉化
- 2Sora外部测试翻车了!3个视频都有Bug
- 3【python轻量级中台框架开发第一层】 ORM flask-sqlacodegen 两种模式
- 4C 语言string.h常见函数用法
- 5注意力机制_assertionerror: kernel size must be 3 or 7
- 6HuggingFace_huggingface linux登录
- 7Python数学建模-2.7SciPy库
- 8huggingface_hub 的 token 链接_#需要从hugging face上获得一个use_auth_toke
- 9面向对象程序设计 C++总结笔记(1)_c++面向对象程序设计读书笔记
- 10超强预测模型:二次分解-组合预测_分解集成预测模型
保姆级讲解 Stable Diffusion
赞
踩
目录
-
本文讲解思路介绍
-
一、引入
-
二、Diffusion Model
-
三、原文的摘要和简介
-
四、Stable Diffusion
-
4.1、组成模块
-
4.2、感知压缩
-
4.3、条件控制
-
-
五、图解 Stable Diffusion
-
5.1、潜在空间的扩散
-
5.2、条件控制
-
5.3、采样
-
5.4、Diffusion Model 与 Stable Diffusion Model 架构比较
-
-
六、工作流程总结
-
七、U-Net 结构解析
-
7.1、ResBlock
-
7.2、timestep_embedding
-
7.3、Prompt 文本 Embedding
-
7.4、SpatialTransformer
-
-
八、关键代码抽离
-
特别鸣谢
-
总结:以有涯随无涯
-
References
本文讲解思路介绍
本文以算法原理的角度去讲解 Stable Diffusion,其实今年年初就想写关于 Stable Diffusion 原理的文章,但是一直没有整段的空闲时间,断断续续的历时两个月才写完,篇幅长是在所难免的,所以会先介绍我的讲解思路:
-
【引入】:首先我会以AI绘画的发展历程作为本文《保姆级讲解 Stable Diffusion》的引入,并且简单的介绍一下在 Stable Diffusion 开源之前的主流生成模型思路的对比,以此来带出 Diffusion Model 的优势; -
【Diffusion Model】:然后会回顾 Diffusion Model 的前向和反向过程,并给出图解和概述,从而说明 Diffusion Model 的不足,即 Latent Diffusion Models 的提出动机; -
【原文的摘要和简介】:接下来会是原文的摘要和介绍,有了上一节的铺垫,学习原文作者写作手法的同时,也对 Stable Diffusion 的贡献有印象; -
【Stable Diffusion】:然后会宏观的介绍 Stable Diffusion 的组成模块,并且聚焦于模型本身,即训练的两个重要阶段:感知压缩、条件控制; -
【图解 Stable Diffusion】:然后会以图解的形式进行讲解,与上一节呼应,加深理解; -
【U-Net 结构解析】:然后是重点部分UNet的结构解析; -
【关键代码抽离】:最后对源码中的重点代码进行了抽离,方便阅读。
码字不易,画图不易,转载请注明出处!
一、引入

图 1:Latent Diffusion Models
我们先从AI绘画(Text-to-Image)的历史讲起,在2015年的时候,有一项工作叫 Automated Image Captioning,说他们已经能够做到从一张图片直接生成自然语言描述(Natural Language Descriptions),有了从图片到文本的生成,肯定会有人想到:从文字生成图片又会是怎么样的呢?
最先做出来的是发表在 ICLR’16 的 Generating Images from Captions with Attention,只不过它的 based structure 是 RNN,也就是说 language model 和 image model 都是基于 RNN 的,它生成的都是一些模糊的图片,如下:

图 2
比如左上角,美国的校车都是黄的,他们说:“已经能够生成其它颜色,从未有过的东西,虽然很模糊”,但是作为一个 Starting Point 来说已经相当不错了,在2016年的时候已经是SOTA结果了。
一直到2021年的时候才有了一个比较有影响力的工作就是 openAI 的 DALL,但是它不开源,随后有一篇开源的工作是 GLIDE,它的效果要比 DALL 好一些。2022年一开年,DALL-E 2发布,它依然不开源。同年7月,Google 公布其 Text-to-Image 模型 Imagen,并且几乎在同一时间段AI图像生成平台 Midjourney 也进行公测。同年8月,Stable Diffusion 的发布将AIGC和AI绘画彻底带出了圈。
我们要讲的 Stable Diffusion 是属于生成模型(Generative Model)的,现在主流的AI绘画模型就是各种 finetune 后的 Stable Diffusion,在这之前主流的生成模型基本可以分为下 图的四类:
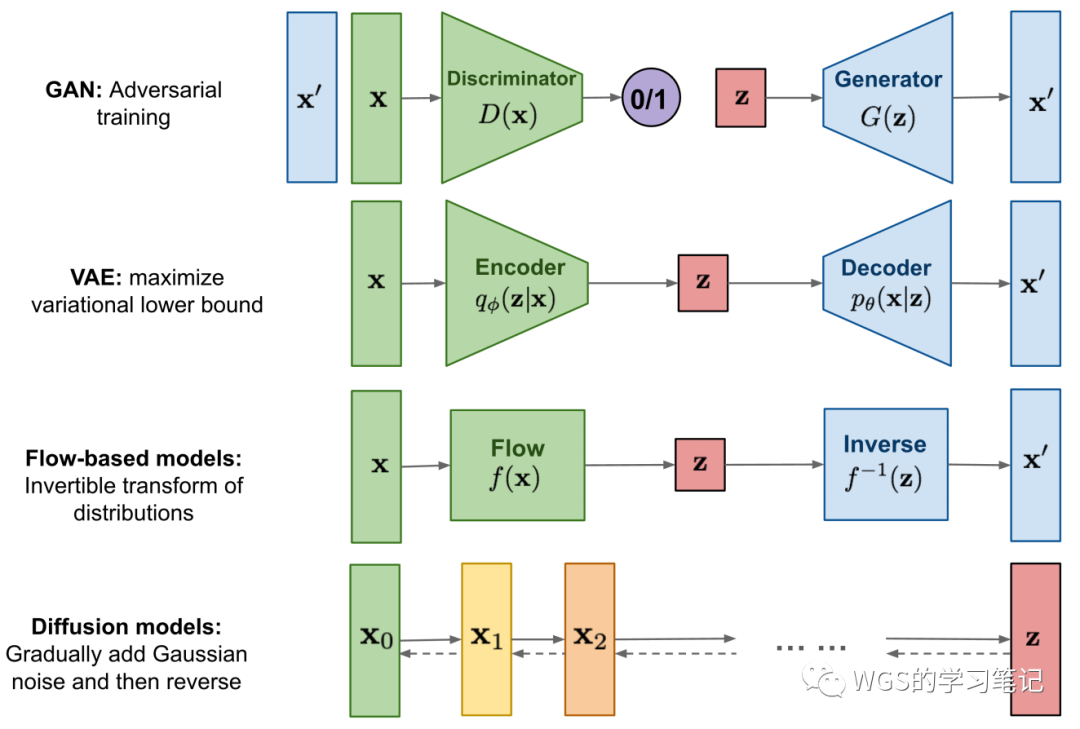
图 3:不同类型的生成模型的概述
-
一种是GAN(生成对抗网络),它是训练两个模型,分别是 Discriminator 和 Generator,这两个模型通常就是神经网络。Generator 试图生成一些和原始样本一致的假样本,Discriminator 试图区分、鉴别样本是属于生成的还是真实的,所谓的对抗就是指训练的时候两个模型的最大最小博弈,理想状态下 Generator 越来越强,导致 Discriminator 无法分辨样本是生成的还是真实的,即概率值稳定在0.5左右。
-
一种是VAE(变分自编码器),它的思路和 GAN 还不太一样,它是把学到一个 latent representation 中,再从 latent representation 中学习怎样 decode 回 。它的做法是 Encoder 要学一个的分布,从分布里面采样一些样本作为 latent representation,也就是 Deocder 的输入,Deocder 学会如何从 latent representation 中重构回原样本,我们用 MSE 监督输入和输出,同时也要注意 latent representation 不能离正太分布太远,防止学到比较夸张的分布。
-
Flow流模型和上面两个完全不同,它是先设立一个模型,还有它的 inverse,inverse 就是数学里的概念,可以从 latent variable 转回 x,通常也是用神经网络来表示,这里最大的挑战就是在 inverse。我们学一个 latent representation ,接着再把它给扭回来,但事实上NN并不容易将它给 inverse 回去,所以flow模型的难点就在于 inverse,这也导致其没有太多的变体。
-
Diffusion Models 又是另一种思路,它将通过一点一点的加噪,变成最后接近于的分布,我们也可以叫它 latent representation,随着一点点的加噪,这个 latent representation 最后就几乎变成了纯noise的,这就是Diffusion Process,而一步步的去噪,即反向去噪过程才是我们要学习的。
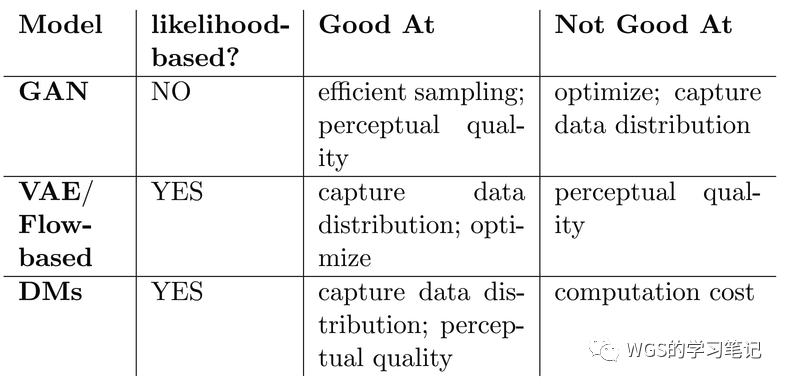
图4:生成模型的优势与劣势
这些模型都各有利弊,GAN在其中比较特别,它没有 likelihood 这个概念,GAN的不足在于它很难优化,对于数据分布捕获的不是很准,VAE 和 Flow 相比之下挺容易优化,但是它们的生成效果要差一些,比如细节不足等,Diffusion Models 也属于 likelihood based model,它的生成效果比较清晰,但是它训练成本很高。
为了降低 Diffusion Models 的训练资源,并且节省推理成本,Latent Diffusion Models / Stable Diffusion 应运而生。
注意:Stable Diffusion 没有单独的论文,它是建立在 Latent Diffusion 基础上的,它俩的思想一致,只有prompt的编码方式不同,其它没什么区别。
二、Diffusion Model
在 Diffusion For Images 的数据化+函数化理解 中我们提到,Diffusion Model 把添加噪声的图片送入网络学习,这就会使得网络学习的东西充满随机性,避免“生成的图片过于死板”。之前写过有关 Diffusion Model 的推导:保姆级讲解 Diffusion 扩散模型(DDPM),所以我们抛开公式以图的形式再回顾一下 Diffusion Model,通俗来讲,Diffusion Model 的训练包括两个过程:
-
正向扩散过程:在图像中添加噪声;
-
反向扩散过程:去除图像中的噪声,这个过程也被称为去噪、采样;
之前把前向扩散的加噪类比成分子运动,再比如它就像一滴墨水滴入一杯水中,墨滴在水中扩散。可能几分钟后,它随机分布在整个水中,直到我们再也无法判断它最初是落在中心还是靠近边缘。
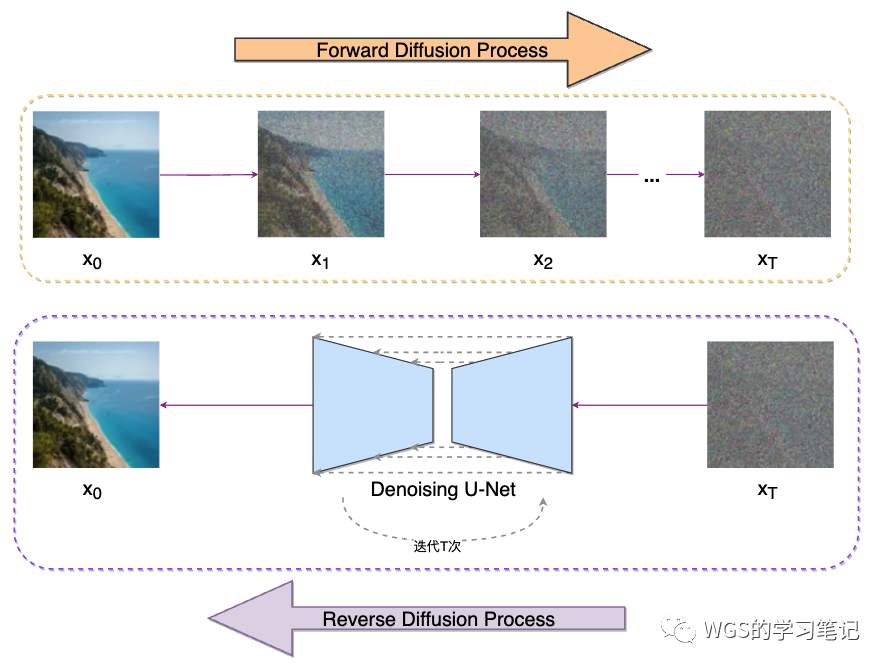
图 5:Diffusion Model
训练过程的伪代码如下:

图 6:Diffusion Model 训练伪代码
-
我们从样本中采样出并添加噪声;
-
对时间步采样出,并且可以对进行 Embedding;
-
生成服从正态分布的随机噪声;
-
网络预测,计算真实噪声与估计噪声之间的MSE;
-
反向传播进行梯度更新,直至收敛。
以上训练步骤图例表示为:

图 7:Diffusion Model 训练流程图
我们可以抛开一些无关的实现细节,用简洁的伪代码来实现前向扩散过程:
- class DDPM(nn.Module):
-
- def forward(self, x0):
- t = torch.randint(0, T, shape=B)
-
- return p_losses(x0, t)
-
- def p_losses(self, x0, t, noise=torch.rand_like(x0)):
- x_t = q_sample(x0, t, noise)
- pred = UNet(x_t, t)
- loss = get_loss(pred, noise).mean()
-
- return loss
反向扩散(去噪)的伪代码为:

图 8:Diffusion Model 采样去噪伪代码
-
从高斯分布采样;
-
按照的顺序进行迭代;
-
如果令;如果,服从高斯分布;
-
利用公式求出均值和方差,进而求得;
-
经过上述迭代,恢复。
表示每个时间步通过和来预测高斯噪声。
反向扩散就是采样过程,也就是从高斯噪声中绘制图像的过程,上述步骤图例为:

图 9:Diffusion Model 采样去噪流程图
在 保姆级讲解 Diffusion 扩散模型(DDPM) 中的反向扩散过程的推导中,我们最后求得的为:
我们发现它不再依赖于,因为式中、、都是已知的,所以它就是和的一个关系式,所以整个反向扩散说白了其本质就是从中减去缩放的随机噪声,所以上述图例可以简化为:
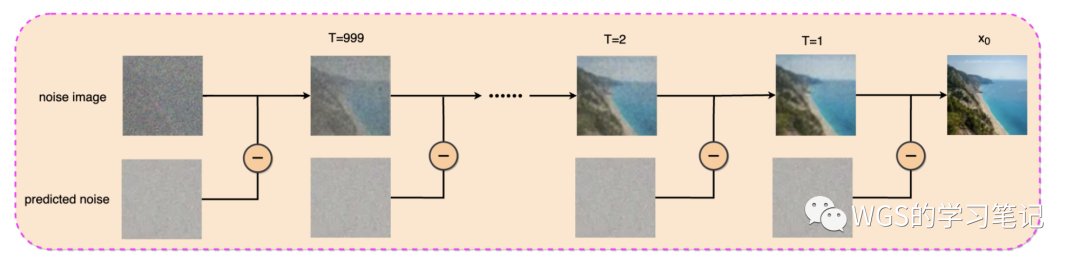
图 10 反向扩散本质说明图
有同学私信我问:为什么会有个步骤,而不是一次性的把noise都给去掉呢?这里给出两个比较容易理解的解释:
-
一个比较直白的解释是,从一个全是噪音的图片,通过去噪把图片 recover 成原来的样子,这是个很难的过程,所以需要把一个难的工作、或者说是步骤给 breaking down 成很多小的步骤,就是所谓的一步一步的去噪;
-
从条件机制的角度来考虑,一步步的去噪还有个好处就是我们在每一步都可以通过条件,来控制、引导生成图片,这样生成的结果就会越来越符合我们输入的prompt,即我们想要的样子。
扩散模型的最主要的不足就是其去噪过程非常耗时,并且非常消耗内存,因为在采样过程中会迭代的向UNet中输入完整尺寸的图片来进行预测,说白了就是在实际的像素空间上进行大量的运算,这就使得纯扩散模型在总扩散步数和图像尺寸较大时训练的极其缓慢。
Latent Diffusion Models 就是为了解决这个问题提出来的,它通过在较低维度的潜在空间(latent space)上应用扩散过程,而非使用实际的像素空间,它降低了模型对计算资源的消耗。
三、原文的摘要和简介
需要再强调的是 Stable Diffusion 并没有单独的论文,它和 Latent Diffusion 思想一样,只是 Stable Diffusion 借鉴了 Google 的 Imagen,用了 CLIP ViT-L/14 文本编码器,它是预训练好的,在整个训练过程中是冻结的,作用就是把我们的文本提示prompt作为条件,注入到去噪生成过程中,其它的和 Latent Diffusion 是一样的,我们来看一下原文的摘要,这部分基本把这篇文章的两个贡献给写出来了:

图 11
作者开篇就说它们的扩散模型在图像合成上达到了SOTA,它通过一种向导的形式,去控制图像的生成过程,并且不需要重新训练。这里主要指的是通过文本作为导向去控制图像生成。
然而这些模型通常直接操作在像素空间上,优化非常大的扩散模型需要消耗巨大的算力,推断也是如此。因为扩散模型是一种逐渐把噪声恢复成原始图像的过程,它跟VAE和GAN不一样,VAE和GAN直接生成出来的就是原始图的逼真图。
为了使扩散模型在有限的计算资源上训练,并且保留它们的质量和灵活性,他们用了一种方法,就是首先训练了一个强大的预训练自编码器,这个自编码器所学习到的是一个潜在的空间,这个潜在的空间要比像素空间要小的多,把扩散模型在这个潜在的空间去训练,大大的降低了对算力的要求,这是它的第一个贡献。
第二个贡献是说,它们引入了一个 交叉注意力层 到模型架构中,以此来实现多模态的训练,这个交叉注意力层可以是一种更一般形式的条件注入,也就是说它可以把文本、边界框和图像,通过统一的方式注入到扩散模型中。
最后说的是他们的扩散模型达到了新的SOTA,在图像修复、和以类别为条件的图像合成上,并且在不同的任务上获得了非常有竞争力的性能,包括了文本到图像的生成、无条件的图像生成、超分辨率任务,相比较在像素空间内训练的扩散模型大大降低了对显存的需求。
接下来我们看一下原文介绍中有关训练过程的描述:

图 12
这一部分是在说,之前在像素空间训练的扩散模型需要强大的算力,导致的结果就是这样的模型只能在小范围内去传播游玩,大众级别的显卡是跑步起来的,为了使我们也能玩到这么强大的模型,需要一个方法,这个方法就是在降低它的算力的同时,保证它的质量。

图 13
然后就提出了一个分离潜在空间(Departure to Latent Space),它把学习的过程分成了2个阶段:
-
第一个阶段被称为感知压缩阶段(perceptual compression stage),感知压缩阶段就是去除了高频率的细节,但是仍然学到了一些语义变体,这个阶段其实就是在训练自编码器,这个自编码器的潜在空间其实也是一个latent图像,但是它会比原始图像小的多,并且是尽可能接近原始图像,学到原始图像的形状,但是像原始图像的纹理、细节都会被去除掉。
-
第二个阶段就是实际的生成模型的学习阶段,这个生成模型就是扩散模型,它将学到的是语义和概念,这个阶段也叫语义压缩阶段(semantic compression stage)。
-
这个阶段的意思就是说,比如有一个杯子放在桌子上,那么杯子和桌子之间的关系是什么样的,就可以理解为语义压缩。
-

图 14
他们去寻找感知平衡,也就是说在第一阶段学习到了一个潜在的空间即减少了对算力的需求,并且在训练扩散模型的时候不损失它的质量(合成图像的质量)。
他们首先训练了一个自编码器,它提供了一个低纬度的表示空间,它在感知上是等同于数据空间的,也就是像素空间的,重要的是对比之前的方法,不需要依赖于非常多的空间压缩,也就是说下采样,将扩散模型放到这个潜在空间训练,它拥有更好的缩放属性,相对于空间维度的数据,被降低复杂性后它依然提供了非常高效的图像生成,这个时候训练扩散模型的时候,不需要训练第一阶段的自编码器了,他们把这样的模型叫做 Latent Diffusion Models。

图 15
然后他们说了这么做的一个很大优势是,只需要训练一次通用的自编码器,就可以把它拼接到不同的扩散模型任务上,像文本生成图像任务,设计了一个架构,它连接了 Transformer 和扩散模型的 UNet backbone,这使得我们可以使用任意类型的基于token的条件注入方式。
四、Stable Diffusion
4.1、组成模块
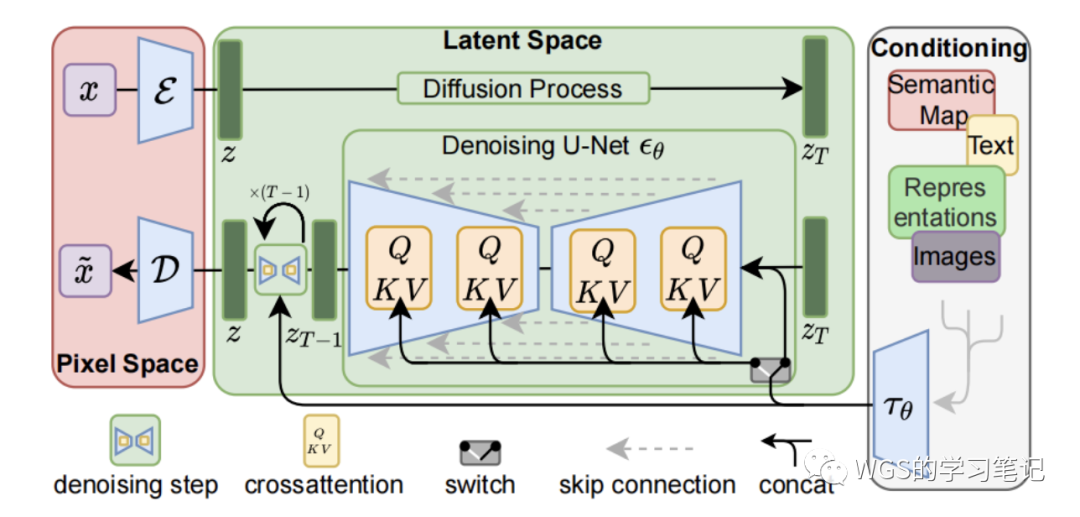
图 16:Latent Diffusion Models
-
左边红色是像素空间 pixel space;
-
中间绿色区域是隐空间 latent space;
-
右边灰色的是条件 condition;
我们对上图加上图例:
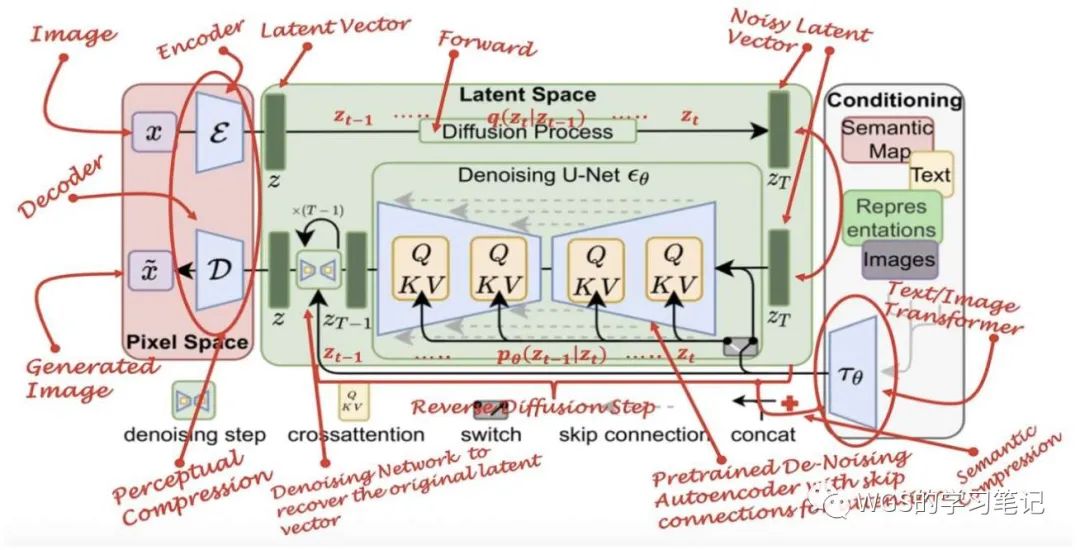
图 17:Latent Diffusion Models 加图例
我们可以看到其有三个主要组成部分:
-
Variational AutoEncoders (VAE)
-
VAE 由编码器(Encoder,)和解码器(Decoder,)组成;
-
编码器可以对图像进行压缩,可以理解为它能忽略图片中的高频信息,只保留重要的深层特征,将其压缩到一个 latent space,然后我们可以在这个 latent space 中进行 Diffusion Process,将其结果作为 U-Net 的输入;
-
解码器负责将去噪后的 latent 图像恢复到原始像素空间;
-
这个就是所谓的 感知压缩(Perceptual Compression),它将高维特征压缩到低维,然后再在低维空间上进行操作的方法具有普适性,可以很容易的推广到文本、音频、视频等不同模态的数据上;
-
-
Condition-Encoder
-
以 Text-to-Image 为例,Condition为文本,文本编码器是一个基于 Transformer 的编码器,它将 prompt 序列映射至潜在文本嵌入序列,使得输入的文字被转换为 U-Net 可以理解的嵌入空间以指导模型对潜表示的去噪;
-
在 Latent Diffusion 中用的是 Bert,stable diffusion 中用的是 CLIP,这是从模型结构上它俩唯一的不同。
-
-
U-Net
-
这部分主要是以 cross-attention 和 residual 模块组成;
-
cross-attention 的作用是指导图像的生成;
-
residual 模块是为防止 U-Net 在下采样时丢失重要信息,所以添加了跳跃连接;
-
U-Net在低维空间上操作,与像素空间中的扩散相比,降低了计算复杂度与内存消耗。
-
4.2、感知压缩
关于 VAE 可以看我之前写的文章:变分自编码器 VAE 详解
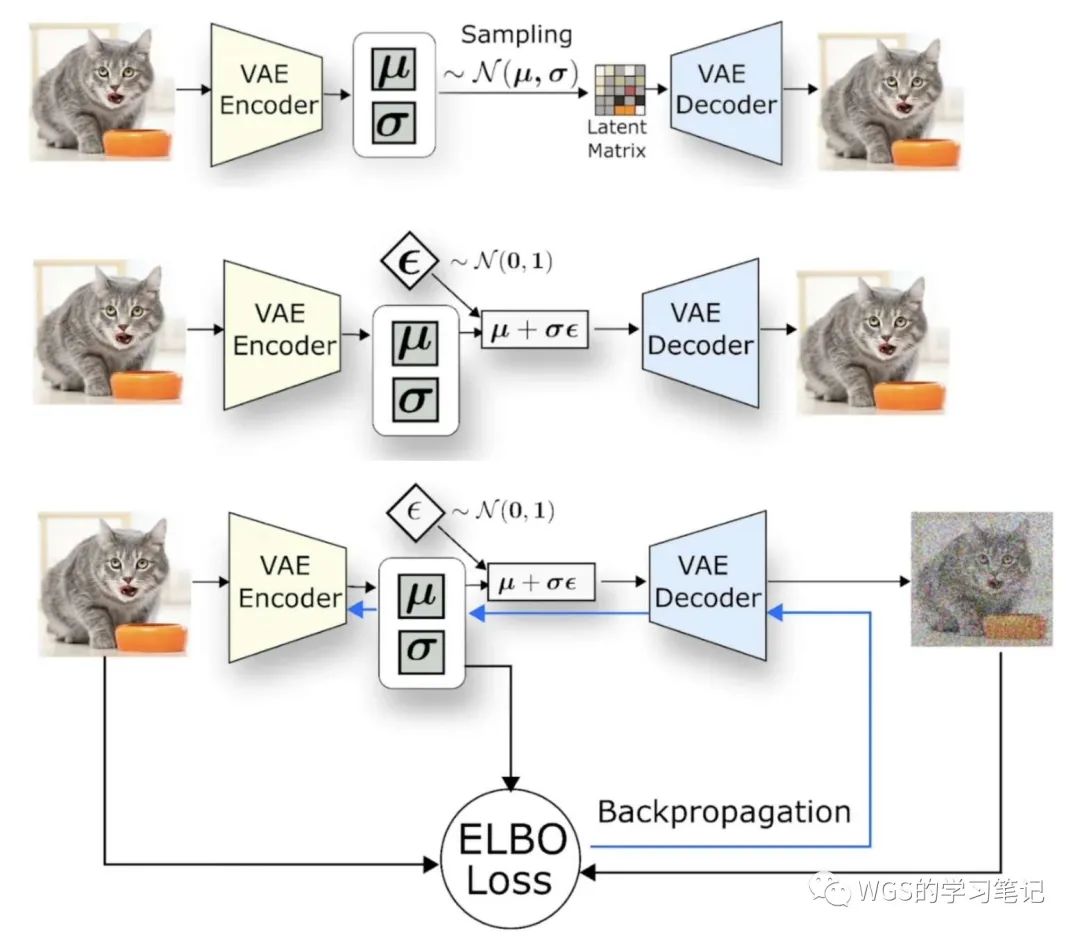
图 18:VAE
上图为 VAE 利用重参数化技巧的训练流程图,这一节我们理解所谓的感知压缩是什么就可以,VAE怎么训练的我们不去深究。
我们最开始提到过,由于原始的扩散模型直接在像素空间上训练,如果我们希望生成一张分辨率比较高的图片,这就意味着我们的训练空间也是高维的。引入感知压缩的目的就是想通过 VAE 这类自编码模型对原始图片进行降维压缩,想忽略掉其中的高频信息,只保留一些重要的特征。这种做法的好处就是能够大幅度降低训练和采样的计算复杂度,大大降低了落地门槛。
感知压缩主要是利用了一个预训练的自编码器,它是由感知损失和基于patch的对抗方式组合训练的VAE,这部分本文不做深究,我们统称为 VAE,它能够学习到一个在感知上等同于图像(像素)空间的 latent space representation,在训练时作者为了避免 latent space representation 出现高度的差异化,使用了两种正则化的方法:KL-reg 和 VG-reg,在 Stable Diffusion 中主要采用 AutoencoderKL 实现。
具体的说,给定一个RGB空间的图像:
-
我们利用 VAE 的 Encoder将编码为潜在表示:;
-
然后再用 Decoder从潜在空间中重构回像素空间:;
其中。
其实说白了,基于之前很多的工作足以证明,很多的 pixel 并不是特别的重要,它们并没有包含到视觉上面有意义的一些细节,或者说是和 prompt condition 有关联的视觉信息,但是之前的扩散模型依然在 pixel space 上训练,对每个像素都要学习怎么样去恢复和生成,模型就会有很大的负担,需要很大的计算资源。

图 19:VAE Encoder
4.3、条件控制
我们再来了解如何处理 Text Prompt (Condition)并将其输入噪声预测器,学过nlp的同学应该知道,Tokenizer 首先会将 prompt 中的每个单词转换为token,然后通过 Text Encoder 进行 Embedding,比如转为768维的向量,供噪声预测网络使用,如下图:

图 20:text prompt
当然 Condition 不仅限于文本,通过一个 Condition Encoder 将条件进行 Embedding,然后以 cross-attention 的形式融入 UNet 中,在 Stable Diffusion 中是以 ViT-L/14 Clip 作为文本编码器的。因为之前写过 cross-attention 的文章:多模态条件机制 Cross Attention,所以对于多模态特征使用注意了机制的融入方式这里不再赘述,那篇文章写的很清楚了。
举个例子,比如 text prompt 为:“a man with blue eyes”,对应图片是一个蓝色眼睛的男人,通过注意力机制会将“blue”、“eyes”,以及图片中蓝色眼睛区域进行配对,因此它会生成一个蓝眼睛的人,而不是穿蓝色衬衣的人。
如下图所示,加入 Condition Encoder 的工作流程,我们再来看一下加入 Condition 之后的损失:
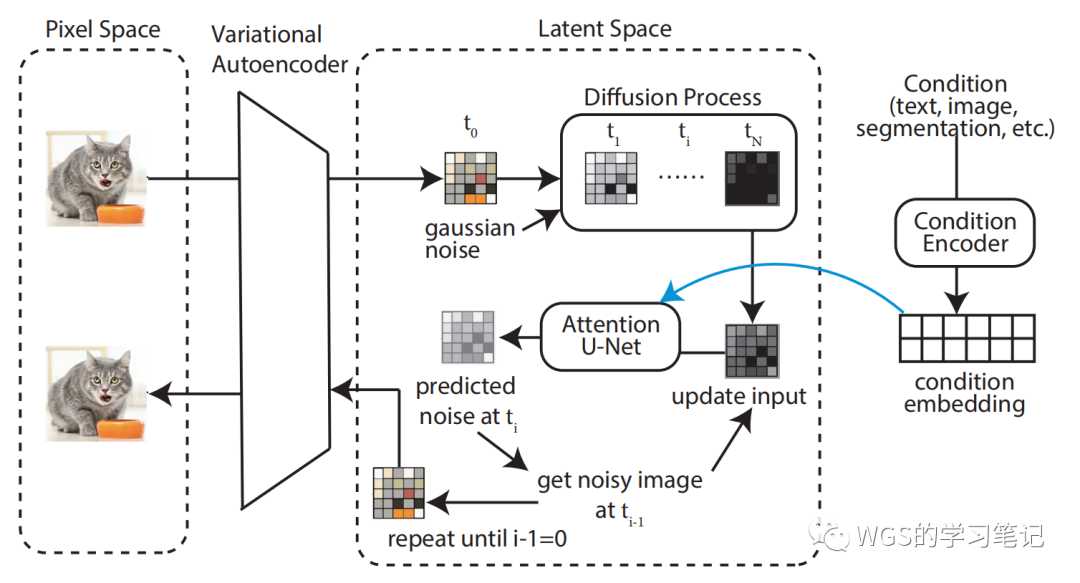
图 21:条件引导图例
我们之前提过,扩散模型可以理解为一个时序去噪自编码器,我们需要训练使得预测的噪声与真实噪声相近,则目标函数为:
而在 Latent Diffusion Models 中,引入了预训练的感知压缩模型,它包含一个编码器和一个解码器,这样就可以在训练时利用 得到 latent representation ,从而让模型在潜在表示空间中学习,其目标函数为:
对于条件生成任务,我们将拓展为:,这样就可以通过来控制图片合成的过程,通过在 UNet 上增加 cross-attention 机制来实现。
为了能够从不同的模态预处理,论文引入了一个领域专用编码器,它用来将映射成一个中间表示,这样我们就可以很方便的引入各种形式的条件,例如文本、类别、layout等,最终模型可以通过一个 cross-attention 将条件引导信息融入到 UNet 中,cross-attention 表示为:
其中是 UNet 的一个中间表征,则目标函数可以写为:
五、图解 Stable Diffusion
5.1、潜在空间的扩散
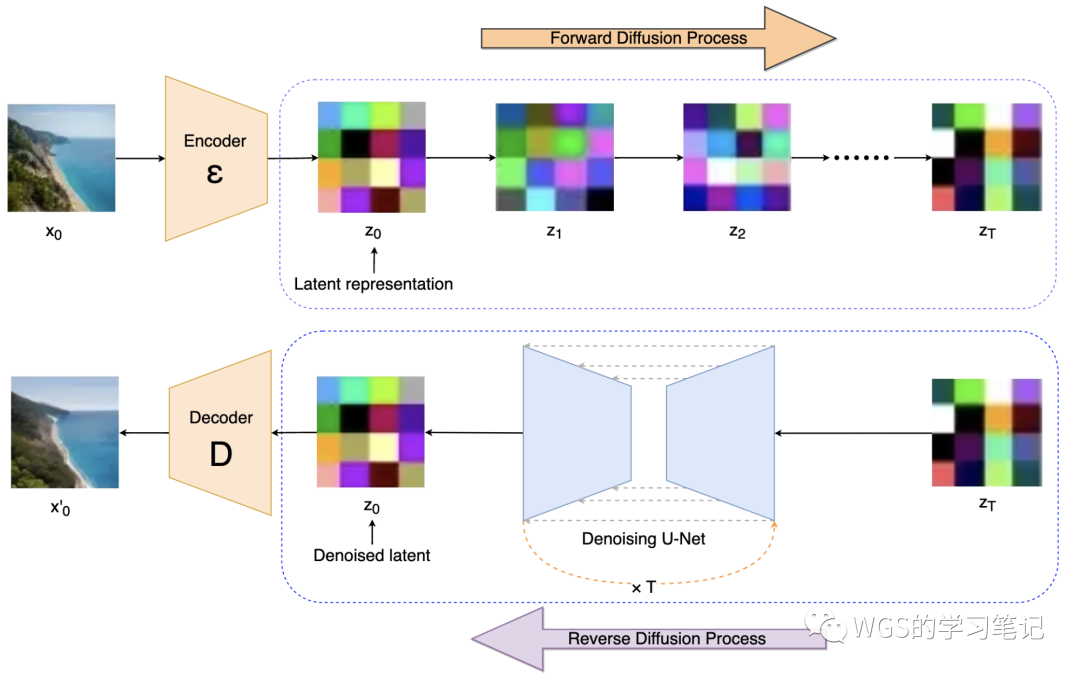
图 22
通过使用预训练VAE的编码器可以将全尺寸图像编码为低维的潜在数据,在 latent space 中进行正向扩散和反向去噪过程,然后利用解码器将潜在数据恢复到 pixel space:
-
正向扩散过程:向潜在数据中添加噪声;
-
反向扩散过程:从潜在数据中去除噪声;
5.2、条件控制
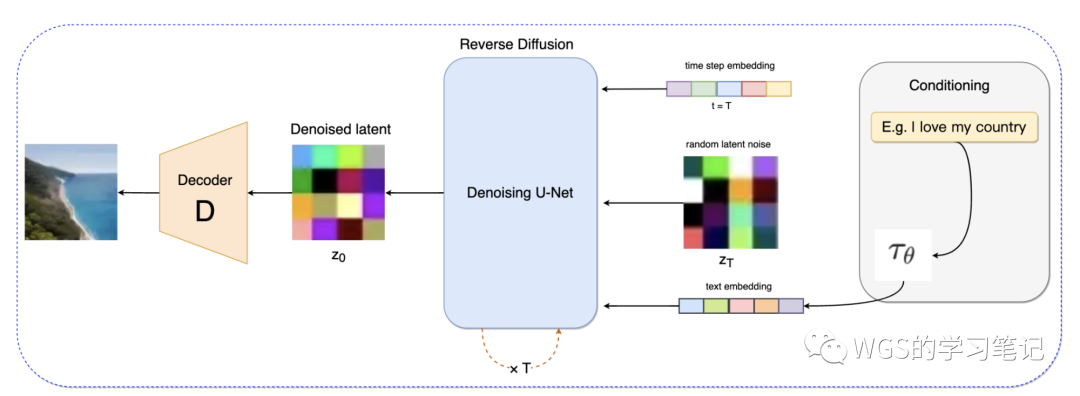
图 23
Stable Diffusion 通过修改 UNet 来实现条件生成,比如文本生成图像,将 cross-attention 与 UNet 进行融合:

图 24
需要说明的是,上图中的Switch开关用于在不同类型的调节输入之间进行控制:
-
对于文本输入,首先使用语言模型
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/225772
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

