
- 1爱奇艺混合云内网DNS实践
- 2linux文件操作open、close、write、read、creat、lseek、以及fopen、fread、fwrite、fseek、fclose、fgetc、fputc、feof与之前有何区别_fread fwrite缓冲区
- 37个可以免费下载3D模型的网站_sd模型下载
- 4修改android系统初始默认语言_反编译改默认语音怎么改
- 5WPF实现拖动控件功能(类似从工具箱拖出工具)
- 6rocketmq 发送异步信息 org.apache.rocketmq.client.exception.MQClientException: The producer service state_the producer service state not ok, shutdown_alread
- 7Linux 系统文件权限管理(参考菜鸟教程)_linux 查看属主权限文件
- 8浅谈计算机科学与现代教育技术,现代教育技术浅谈论文
- 9CM311-1-CH(JL)-YST_905L3(B)-安卓9.0-原生设置-完美AI语音精简线刷固件包_cm311-1刷机包
- 10GPU并行计算基础知识科普_gpu并行计算原理
大数据基础教程Hadoop入门学习_大数据界面教程
赞
踩
大数据hadoop入门 分布式笔记
1.基础
1.1Hadoop核心
1. HDFS: Hadoop Distributed File System 分布式文件系统
2. YARN: Yet Another Resource Negotiator
3. Mapreduce:分布式运算框架
4. 资源管理调度系统
- 1
- 2
- 3
- 4
1.2HDFS
-
结构:
namenode为主节点
datanode为从节点
-
namenode(Master):接收客户端请求(Controller)
维护系统目录结构
管理block与文件的关系,block和datanode的关系
-
datanode(Slave):
储存文件
block存储于磁盘
副本
存储思路:
分布式存储文件,文件存储时切割为block默认128mb
每个block都分布在datanode中
hdfs文件系统的文件与真实block的映射关系由namenode管理
每个block都会在集群中存在多个副本,提升可靠性,吞吐量

![议将图片保存下来直接上传(img-Cfvb8qwA-1586914968409)(C:\Users\17566\Pictures\ScreenCapture\IMQtl7NdVd.png)]](https://img-blog.csdnimg.cn/20200415094414985.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDQ4MTAxMQ==,size_16,color_FFFFFF,t_70)
1.3 Linux
| 序号 | 命令 | 对应英文 | 作用 |
|---|---|---|---|
| 01 | ls | list | 查看当前文件夹下的内容 |
| 02 | pwd | print wrok directory | 查看当前所在文件夹 |
| 03 | cd [目录名] | change directory | 切换文件夹 |
| 04 | touch [文件名] | touch | 如果文件不存在,新建文件 |
| 05 | mkdir [目录名] | make directory | 创建目录 |
| 06 | rm [文件名] | remove | 删除指定的文件名 |
| 07 | clear | clear | 清屏 |
2.环境搭建



虚拟机(192.168.187.66)通过 虚拟网关(192.168.187.1) 连接windows(192.168.187.101)
2.1CentOs安装
2.1.1 关闭图形界面 init 3
[root@lkwhai]# vim /etc/inittab
id:5:initdefault:
#关闭图形界面
在id:5:initdefault这一行中,将其改成id:3:initdefault:
#打开图形界面
在id:3:initdefault这一行中,将其改成id:5:initdefault:

xshell远程操作linux
2.2主机名更改
[hadoop@lkwhai ~]$ vi /etc/sysconfig/network
2.3修改主机名和IP的映射关系
[hadoop@hadoop17 ~]$ sudo vi /etc/hosts
- 1
添加
192.168.187.66 lkwhai
- 1
- 2
2.4 使用FileZilla向linux传入jdk和hadoop
2.5 JDK和hadoop的安装
解压jdk.gz 和hadoop.gz
tar -zxvf hadoop-2.7.1...tar.gz -C ../文件目录/
- 1
tar -zxvf jdk....tar.gz -C ../文件目录/
- 1
2.5.1 tar命令格式
打包文件tar -cvf 打包文件.tar 被打包文件/路径
解包文件tar -xvf 打包文件.tar
2.5.2 环境变量
sudo vi /etc/profile/
添加
export JAVA_HOME=/../jdk安装目录
export PATH=$PATH:$JAVA_HOME/bin
- 1
- 2

source /etc/profile进行保存
2.5.3 防火墙关闭
systemctl status firewalld #查看防火墙的服务状态,
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
- 1
- 2
- 3

2.5.4 hadoop配置文件修改
- 配置hadoop的5个配置文件,以伪分布式运行
进入hadoop安装目录下/etc/hadoop/
修改hadoop-env.sh

修改core-site.xml
Hadoop核心配置文件 配置hdfs://lkwhai:9000 修改hdfs系统命名

改mapred-site.xml
MapReduce相关配置

修改yarn-site.xml
yarn框架运行环境配置

格式化(初始化)namenode
bin/hadoop namecode -format
**ps:多次格式化namenode会造成temp…version中namenode的clusterID的变化 **
namenode和datanode集群id不一致
故在格式化时应先删除data数据和log
修改hadoop安装目录/etc/hadoop/slaves
启动hdfs
Start-dfs.sh
启动yarn
Start-yarn.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
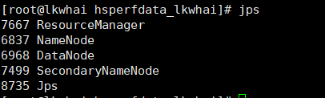
2.5.5 成功配置
进入
192.168.126.66:50070
(C:\Users\17566\AppData\Roaming\Typora\typora-user-images\image- png)]
png)]
2.5.6 修改hosts
vi /etc/hosts
添加
192.168,187.66 lkwahi
3 Hadoop使用
本地模式,一般用于编程开发阶段。
伪分布式运行模式,一般配置集群在YARN上运行MR程序。
完全分布式运行模式。
在xshell上
在网站192.168.126.66:50070utilities中Browse the file system中

3.1 hdfs文件传输
3.1.1发送文件
hadoop fs -put hadoop... hdfs//lkwhai:9000/
在web 端可显示
3.1.2 获取文件
hadoop fs -get hdfs://lwhai:9000/...文件
3.1.3 MapReduce使用
找到hadoop-mapreduce-examples.jar 进行使用
新建本地文件,并传到hdfs
运行MapReduce的词频计算程序/
3.2 Hadoop的目录结构
| 序号 | 命令 |
|---|---|
| bin目录 | 存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本 |
| etc目录 | Hadoop的配置文件目录,存放Hadoop的配置文件 |
| lib目录 | 存放Hadoop的本地库(对数据进行压缩解压缩功能) |
| sbin目录 | 存放启动或停止Hadoop相关服务的脚本 |
| share目录 | 存放Hadoop的依赖jar包、文档、和官方案例** |
3.3 Hadoop的命令
| hadoop fs | |
|---|---|
| 创建目录:mkdir | hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2 |
| 列表文件:ls | hadoop fs -ls /user |
| 查看文件:cat | hadoop fs -cat /input2/file1.txt /input2/file2.txt |
| 转移文件:put、get、mv、cp | 本地hadoop fs -put /home/hduser/file/file1.txt /home/hduser/file/file2.txt /input2 **hdfs:**hadoop fs -get /input2/file1 $HOME/file **移动:**hadoop fs -mv /input2/file1.txt /input2/file2.txt /user/hadoop/dir1 **复制:**hadoop fs -cp /input2/file1.txt /input2/file2.txt /user/hadoop/dir1 |
| 删除文件:rm、rmr | hadoop fs -rmr /user/hadoop/dir1 hadoop fs -rm /intpu2/file1.txt |
| 管理命令:test、du、expunge |
4 免密登陆配置(ssh)


ssh-keygen -t rsa
- 进入.ssh文件目录下
.ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
创建authorized_keys文件 chmod修改用户权限 用于存放公钥
- 生成公钥和密钥ssh-keygen -t rsa
此时id_rsa.pub下存放了公钥
Id_rsa存放了秘钥
-
将公钥放在authorized_keys文件下
-
启动hadoop进程时已经不用再输入密码了
-
在另一台主机建立授权列表将秘钥加入


RSA算法
非对称加密
加密过程:两个互质的质数相乘,能够得到一个新的数,而这个数通过一定的变化能够变成公钥,两质数就是形成私钥。公钥在机器的交流中流通。
当机器需要解密时,用自己的私钥验证别的机器传来的公钥,验证请求是否合法。
5 VMware克隆主机
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xNB6FL81-1586914968433)
mac地址唯一
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nfvGe7tq-1586914968434)(C:\Users\17566\AppData\Roaming\Typora\typora-user-images\image-20200407131728265.png)]
修改配置:修改ip
输入 vi /etc/sysconfig/network-scripts/ifcfg-ens33(更改红色部分信息即可)注意:网卡名称可能不一样,即不是ens33,也可能是其他的,可以通过
vi /etc/sysconfig/network-scripts/ 按两下Tab键提示,然后选择ifcfg-名称
修改ip
主机名与ip映射
sudo vi /etc/hosts
6.Hadoop
Namenode元数据管理和SecondaryNamenode
namenode管理节点,维护文件系统目录
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
Namenode始终在内存中保存metedata,用于处理“读请求”
到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。
Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。

NameNode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current目录中产生如下文件
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
(4)每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
SecondaryNameNode
从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
secondary通知namenode切换edits文件
secondary从namenode获得fsimage和edits(通过http)
secondary将fsimage载入内存,然后开始合并edits
secondary将新的fsimage发回给namenode
namenode用新的fsimage替换旧的fsimage
默认checkpoint指定时间间隔为3600s,可以通过修改hdfs-default.xml修改
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600<value>
</property>
- 1
- 2
- 3
- 4
dfs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
元数据存储
FileName
replicas 副本个数
block-ids,id2host指定分块地址

7.Hadoop的集群安全
1、NameNode启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
2、DataNode启动
**系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。**在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
3、安全模式退出判断
如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
读数据流程

网络拓扑-节点距离计算

机架感知

读数据

HDFS的体系结构
HDFS为了保证数据存储的可靠性和读取性能,对数据进行切块后进行复制并存储在集群的多个节点中。
NameNode节点: Master
存储元数据信息
元数据保存在内存/磁盘中
保存文件、block、datanode之间的映射关系
DataNode节点:Slave
存储block内容
存储在磁盘中
维护了block id到文件的映射关系
Block:基本存储单位
大规模的文件以一个标准切分成几块,分别存储到不同的磁盘上。这个标准就称为Block。
Block 默认的大小为64(128)M。
这样做有以下几点好处:
文件块可以保存在不同的磁盘上。在HDFS系统中,一个文件可以分成不同的Block存储在不同的磁盘上。
简化存储系统。这样不需要管理文件,而是管理文件块就可以了。
有利于数据的复制。在HDFS系统中,一个数据节点一般会复制3份
对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。
HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
block太大影响传输时间,太小增加索引寻址时间
hdfs与java

Hadoop FileSystem API主要类
org.apache.hadoop.fs.FileSystem
org.apache.hadoop.conf.Configuration
org.apache.hadoop.fs.FSDataInputStream
org.apache.hadoop.fs.FSDataOutputStream
org.apache.hadoop.fs.Path
org.apache.hadoop.fs.FileStatus
- 使用FileSystem API编程步骤
- 获取Configuration对象
- 获取文件系统的实例FileSystem对象
- 使用FileSystem对象操作文件
使用
FileSystem类主要方法

- 第一步:获取Configuration对象,得到Hadoop参数配置信息
Configuration conf=new Configuration(); //实例化Configuration
conf.addResource(“hdfs-site.xml”); //手动加载参数文件hdfs-site.xml
conf.addResource(“mapred-site.xml”); //手动加载参数文件mapred-site.xml
conf.set(“mapreduces.job.reduces”,”1”); //直接指定某个属性
- 1
- 2
- 3
- 4
- 得到文件系统的实例FileSystem对象
public static FileSystem get(Configuration conf)
public static FileSystem get(URI uri,Configuration conf)
- 1
- 2
- 使用FileSystem对象操作文件
// 获取本地配置信息core-site.xml
Configuration conf = new Configuration();
// 获取文件系统实例,core-site.xml中指定了HDFS文件系统
FileSystem fs = FileSystem.get(conf);
InputStream in = null;
try {
in = fs.open(new Path(“/input2/file1.txt”));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);//Hadoop提供的工具
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 创建文件
public FSDataInputStream create(Path f)
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path f=new Path(uri);
FSDataOutputStream outputStream=fs.create(f);
InputStream in=new ByteArrayInputStream(
"Hello!Hadoop HDFS!".getBytes("UTF-8"));
IOUtils.copyBytes(in,outputStream,4096,true);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 复制文件
public void copyFromLocalFile(Path srcPath,Path dstPath)public void copyToLocalFile(Path srcPath,Path dstPath)
String srcFile=“/home/hduser/file/file2.txt”; //源文件必须是本地文件
String dstFile=“hdfs://node1:9000/input2/file2.txt”; //目标文件必须是HDFS文件
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path srcPath=new Path(srcFile);
Path dstPath=new Path(dstFile);
fs.copyFromLocalFile(srcPath, dstPath);//复制本地文件至HDFS
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 删除文件
public boolean delete(Path f,boolean recursive)
String uri=“hdfs://node1:9000/input3”;
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path f=new Path(uri);
fs.delete(f,true);
- 1
- 2
- 3
- 4
- 5
- 6
- 重命名文件
public boolean rename(Path fromPath,Path toPath)
String fromFile=“hdfs://node1:9000/input2/file2.txt”;//旧文件名
String toFile=“hdfs://node1:9000/input2/file2new.txt”;//新文件名
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path fromPath=new Path(fromFile);
Path toPath=new Path(toFile);
fs.rename(fromPath, toPath);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
hdfs实现的方式
使用Hadoop URL
使用FsUrlStreamHandlerFactory
使用Hadoop FileSystem API
Configuration
FSDataInputStream
FSDataOutputStream
Path
FileStatus
使用FileSystem类
读取、创建、复制、删除、重命名、查询
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
8.MapReduce



Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(MapTask进程)对每一个<K,V>调用一次
- 1
- 2
- 3
- 4
- 5
- 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
- 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
Reduce阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法
- 1
- 2
- 3
- 4
- 在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。
- 写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
- 把reduce的输出保存到文件中。
MapReduce优点
- 通过接口完成程序,易开发
- 扩展性强
- 容错性强,好移植
- 海量数据离线处理的支持

