
- 1AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.01.15-2024.01.20
- 2Vue3 + ElementPlus的管理后台系统_vue3-element-plus-admin
- 3鸿蒙OS开源代码精要解读之——init_鸿蒙os代码 开源
- 4python tkinter random messagebox 实现一个界面化的石头剪刀布!_python实现界面化
- 5HarmonyOS Data Ability的了解和使用_harmonyos dataability
- 6Gradle sync failed “read time out“_gradle sync failed: read timed out
- 7List.js 组件_list.js官网下载
- 8手把手教程,用AI制作微信红包封面!
- 9限流之 Guava RateLimiter 实现原理浅析_ratelimiter.tryacquire() 一直false
- 10日期与数组与字符串的方法复习总结_日期使用字符数组的方法
YOLO系列理论学习(YOLOv1~v3)_yolo应该学哪个版本
赞
踩
前言
目标检测学习之YOLOv1~v3系列
参考b站uphttps://space.bilibili.com/18161609
一、YOLO v1
Yolo是典型的one stage网络
YOLO v1论文思想
- 将一幅图分成s×s个网格,如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
- 每个网格预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数。

通过正向传播,提取出1行如上图所示,将其进一步拆分,分成两组bonding box,pascal VOC一共有20个类别,故总长为30。confidence可以理解为我们预测的目标与真实目标的交并比(IOU)×Pr(Object),当网格中确实存在目标时,后面这项为1,否则为0。
网络结构

损失函数

YOLO v1存在的问题
当一些小目标聚集在一起时,预测结果非常差
当目标出现新的尺寸时,预测效果也比较差。
二、YOLO v2
YOLO v2原论文为YOLO9000,性能相比于YOLO v1提升了将近15个百分点。
YOLO v2相比于v1版本做了一些新的尝试
- v2在每个卷积层后面加上了BN层。
- 采用了更高分辨率的分类器(采用448×448输入尺寸)。
- 尝试使用基于anchor的边界框预测。
- 采用 k-means聚类的方法获得相应的priors(anchors)。
- 采用直接预测bounding box中心坐标的方式,每个anchor去负责预测目标中心落在某一个cell区域内的目标。
- 结合更低层的图像信息,将高层与低层进行融合。(FPN)
- 采用多尺度训练方法,每迭代10个batch,就将网络的输入尺寸进行一个随机的选择。
k-means聚类方法可参考博文使用k-means聚类anchors
网络结构

三、YOLO v3
YOLO v3没有什么太多创新点,主要是整合当前热门网络所构成的一个方法。
论文名称:YOLOv3: An Incremental Improvement
论文下载地址: https://arxiv.org/abs/1804.02767
YOLO v3的backbone改为Darknet-53,该backbone的结构与Resnet类似,但Darknet-53没有最大池化下采样,而是利用步距为2的卷积来对高和宽进行缩减。这样速度会进一步提升。

Darknet中的卷积层并不是普通的卷积层,是一个卷积+bn+LeakyReLU激活函数,(使用bn时卷积层没有偏置参数)。方框框住的部分是一个残差结构。
YOLO v3会在三个特征层上进行预测,每个特征层上会使用三种尺度,三种尺度在原论文中给出。

以YOLO v3 416模型为例,输入图像尺寸为416×416,通过Darknet53输出的预测特征图大小为13×13。接下来通过一个convolutional set
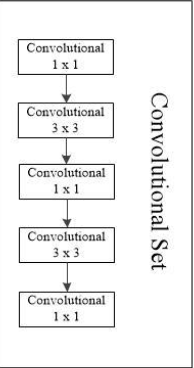
然后再通过一个3×3的卷积,得到第一个预测特征图,大小为13×13,最后使用一个卷积核大小为1×1的预测器在预测特征图上进行预测,预测参数的个数为13×13×3×(4+1+80)(COCO数据集,种类为80)。
在Convolational Set处往下进行,首先是经过1×1的卷积层,然后经过上采样,再与Darknet53中26×26的部分在深度上进行拼接(与FPN在对应维度上进行相加不同)。之后再进行一个Convolational Set处理,产生两个分支。第二个预测特征层与后面第三个预测特征层同理,在此不再赘述。
目标边界框的预测

与YOLO v2 相同,YOLO v3中采用的anchor机制与之前的ssd与faster r-cnn是有些许不同的,YOLO v3中网络所预测的有关目标中心点的回归参数并不是相对于anchor的,而是相对于当前cell的左上角这个点的。
正负样本匹配
针对每一个GT box,都会分配一个正样本,会选与GT重合最大的bounding box作为正样本,对于那些重合程度也超过阈值但不是最大的那些box,论文中说会直接丢弃该预测结果。剩下的样本均为负样本。
损失的计算

置信度损失
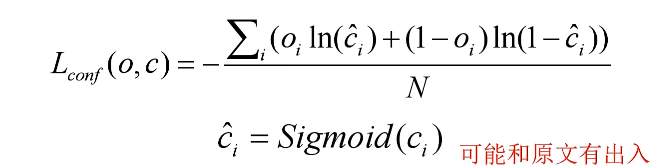
类别损失
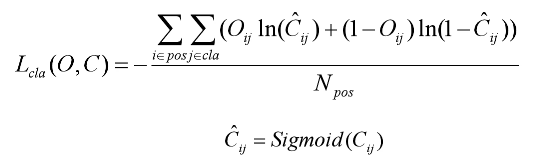
定位损失


