- 1Spring Boot 启动成功,但是无法访问 Controller 里面的方法_springboot进不去controller
- 2keras: Data Load & Data Preprocessing_keras data dataloader
- 3vue-element-admin $notify 内容过长不自动换行的问题_$notify数据过长换行
- 4小米游戏本bios_年轻人的第一台游戏本?——小米游戏本2019评测
- 5逻辑运算符
- 6爬虫遇到网页审查元素(开发者工具)打不开怎么办?_爬虫无权访问开发者工具
- 7汽车多重定位,实时定位追踪,远程查看汽车运行轨迹_lbs轨迹实时定位
- 8GEE系列:第7单元 利用GEE进行遥感影像分类【随机森林分类】_gee遥感影像分类实习报告
- 9随机森林如何评估特征重要性_随机森林 特征重要性
- 10YOLOv9改进 | 一文带你了解全新的SOTA模型YOLOv9(论文阅读笔记,效果完爆YOLOv8)
MySQL的utf8与utf8mb4编码,以及utf8_bin、utf8_general_ci编码区别_mysql utf8_bin
赞
踩
utf8和utf8mb4的区别
一、简介
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
二、内容描述
那上面说了既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符等等(utf8的缺点)。
通常,计算机在存储字符时,会根据不同类型的字符以及编码方式分配存储空间。例如以下几种编码方式;
①ASCII编码中,一个英文字母(不分大小写)占用一个字节的空间,一个中文汉字占用两个字节的空间。一个二进制的数字序列,在计算机中作为一个数字单元存储时,一般为8位二进制数,换算为十进制。最小值0,最大值255。
②UTF-8编码中,一个英文字符占用一个字节的存储空间,一个中文(含繁体)占用三个字节的存储空间。
③Unicode编码中,一个英文占用两个字节的存储空间,一个中文(含繁体)占用两个字节的存储空间。
④UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要占用2个字节的存储空间(Unicode扩展区的一些汉字存储需要4个字节)。
⑤UTF-32编码中,世界上任何字符的存储都需要占用4个字节的存储空间。
既然utf8能兼容绝大部分的字符,为什么要扩展utf8mb4?
随着互联网的发展,产生了许多新类型的字符,例如emoji这种类型的符号,也就是我们通常在聊天时发的小黄脸表情,这种字符的出现不在基本多平面的Unicode字符之中,导致无法在MySQL中使用utf8存储,MySQL于是对utf8字符进行了扩展,增加了utf8mb4这个编码。
所以,设计数据库时如果想要允许用户使用特殊符号,最好使用utf8mb4编码来存储,使得数据库有更好的兼容性,但是这样设计会导致耗费更多的存储空间。
三、在mysql中存在着各种utf8编码格式:
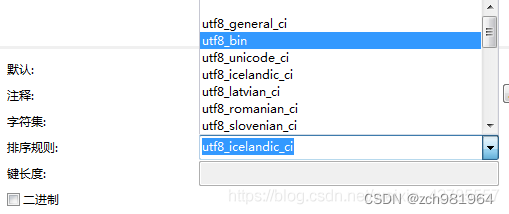
utf8_bin将字符串中的每一个字符用二进制数据存储,区分大小写。
utf8_genera_ci不区分大小写,ci是case insensitive的缩写,即一般大小写不敏感。
insensitive ; 中文解释: adj. 感觉迟钝的,对…没有感觉的
utf8_general_cs区分大小写,cs是case sensitive的缩写,即大小写敏感。
case sensitive 中文解释:敏感事件;大小写敏感;注重大小写;全字拼写须符合
用utf8_genera_ci没有区分大小写,导致这个字段的内容区分大小写时出问题:
作为密码时就会出现不合理的方面;
而验证码则一般不区分大小写,所以用这个就合理
utf8_general_cs这个选项一般不用,所以使用utf8_bin区分大小写
在mysql对于类型为varchar数据默认不区分大小写;
字段以“utf8_bin”编码使其区分大小写。(bin===>Binary二进制)
在二进制中 ,小写字母 和大写字母 不相等.即 a !=A
在mysql中介绍排序规则两种修改方案:
一.通过SQL(结构化查询语言(Structured Query Language))来修改
alter table emp
modify ename varchar(30) collate utf8_general_ci