
- 1DataCanvas会员中心正式上线,这些新春福利请接住!
- 2计算机科学与技术专业毕业设计最新最全选题精华汇总-持续更新中_计算机科学与技术毕业设计选题
- 3系统集成的2种方式_a系统集成到b系统,谁提供接口
- 4基于SSM的红色文化展示小程序系统设计与实现【包调试】_红色展示系统
- 5k8s教程----零基础快速入门
- 6【SLAM随手记】ROS中编译ORB-SLAM2出错及解决方案:[rosrun] Couldn't find executable named Mono_[rosbuild] rospack found package "orb_slam2" at ""
- 7解决虚拟机无法联网_博途16虚拟机 不连网
- 8(C/C++)STL函数(3)二分算法题以及二分模板 和(蓝桥杯)递推与递归题目及解法(ACwing)_c语言实现stl分解
- 9java Maven连接mysql_java maven mysql
- 10从零开始理解Hugging Face中的Tokenization类_tokenizer.unk_token
超详细!手把手教你从零开始训练yolov5模型_yolov5模型训练
赞
踩
作者:抛到海里
编辑:3D视觉开发者社区
本文将从yolov5的下载安装开始,详细介绍从环境搭建到素材整理以及最后训练出目标图片模型的整个过程。以下为本文目录:
一、anconda环境搭建
二、yolov5下载安装
三、素材整理
四、模型训练
一、Anconda环境搭建
提醒:所有操作都是在anconda的yolo的环境下进行的,在创建yolo环境后,之后每次进入CMD都需要切换到yolo环境中去(否则进入默认的base环境中)
下载地址:https://www.anaconda.com/products/individual#Downloads
(下载对应版本anconda即可)
anconda安装好后,conda可以创建多个运行环境,默认是base环境。这里我们为yolo创建一个环境。
打开CMD命令行,为yolov5创建一个环境,注意这里用的python版本是3.8,版本过低后面可能会报错
conda create -n yolo python=3.8
- 1
执行
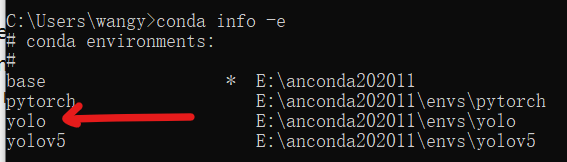
conda info -e
- 1
即可看到我们刚刚创建的yolo环境
执行
activate yolo
- 1
即可切换到我们的yolo环境下了。记住退出CMD或者切换CMD窗口之后,如果
想要进入我们的yolo环境,都需要运行activate yolo指令。不然默认是在base环境下。
除此之外,我们进行yolo模型训练代码的编写需要用到jupyter notebook,所以我们需要在yolo环境下进行安装
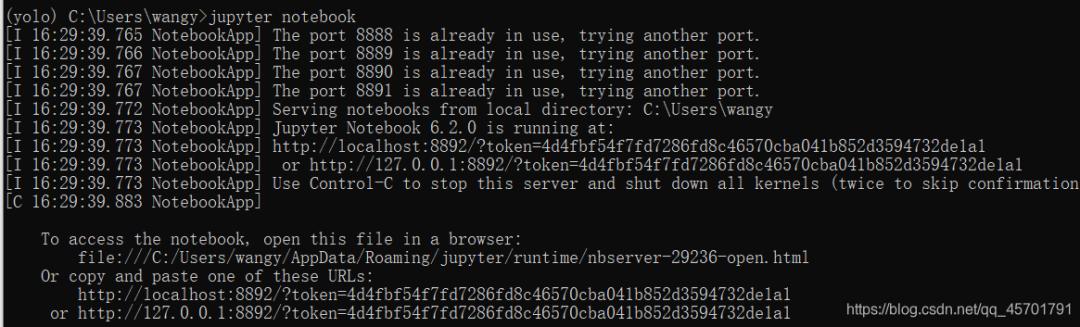
安装完成之后,我们只需要在yolo环境下输入
jupyter notebook
- 1
二、yolov5下载
下载地址:https://github.com/ultralytics/yolov5
下载yolov5源码,解压后,可以看到里面有requirements.txt文件,里面记录了需要安装的包,这个txt文件可以帮助我们一键下载这些依赖包。
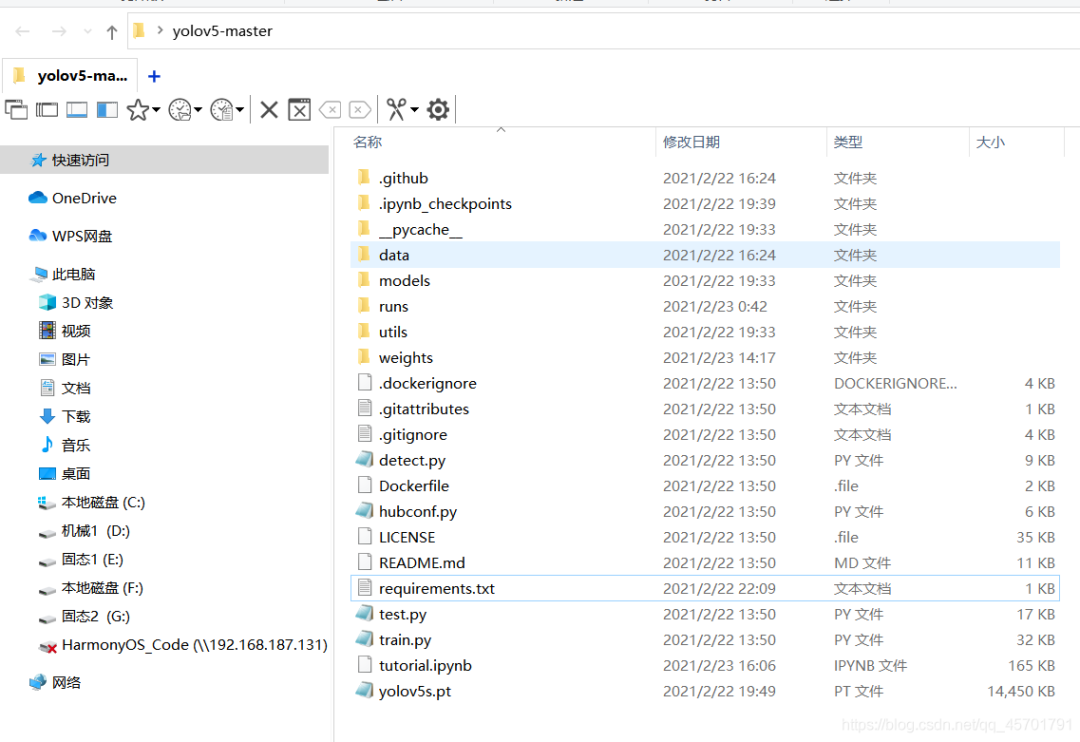
文件夹里也包含了train.py文件,这个也是我们接下来训练yolo模型需要用到的启动文件。(大家看到的文件夹内容会和我的有点不一样,因为我的下载下来后又添加了一些文件)
接着上面的requirement.txt,介绍如何安装里面需要安装的依赖。我们首先打开我们下载好的yolov5_master 文件夹,在上面输入cmd回车,可以直接在该文件夹目录下打开命令行。
在cmd命令行打开之后,大家千万记得要切换到我们的yolo环境下,不然就安装到base环境中去了。
activate yolo
- 1
然后运行
pip install -r requirements.txt
- 1
就会自动帮我们把这些依赖安装好了。接下来我们就要开始训练yolo模型了。
三、整理yolov5模型
为了完成训练工作,我们需要将训练的图片按照指定的格式进行整理,
详细参照yolov5官方指南:
https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
我这里也简要介绍一遍过程,然后也为大家避坑,我们在训练前首先需要采集图片样本,然后再对图片中的待识别物体进行标注。
我们首先需要建立如下的文件夹:
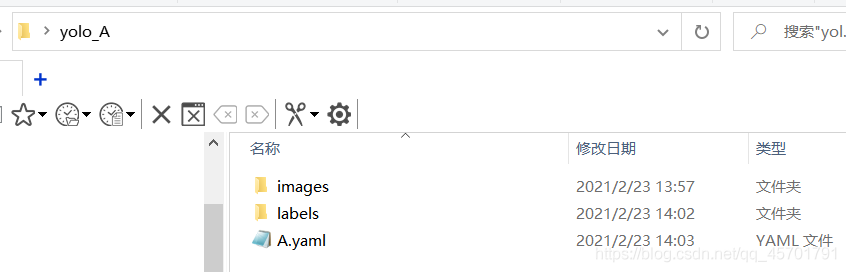
所有文件放在yolo_A文件夹下,子文件夹images用来存放样本图片,labels文件夹用来存储标注信息。A.yaml文件用来存放一些目录信息和标志物分类。
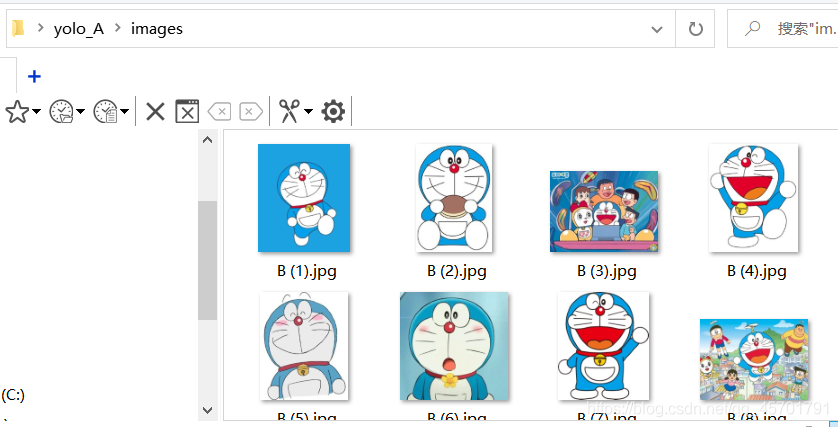
我这次测试的检测哆啦A梦的头像,我采集了50张哆啦A梦的样本,放到images文件夹下:
接下来我们就要进行图片的标注工作了,图片标注我们用到了一个名为labelimg的工具:下载地址:https://github.com/tzutalin/labelImg
大家下载解压之后,首先要做的是删除
labelImg-master\data\predefined_classes.txt文件中的内容,不然等会标记的时候会自动添加一些奇怪的类别。
然后在labelImg-master文件夹下打开cmd,进入我们的yolo环境中,然后我们还需要在yolo环境中安装一些labelimg运行需要的依赖,依次输入
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
- 1
- 2
- 3
现在,我们已经在yolo环境中安装好labelimg的依赖环境了,输入
python labelimg.py
- 1
即可进入我们的界面中来。进入之后,首先我们先把一些选项勾上,便于我们标记。然后,最重要的是把标记模式改为yolo。

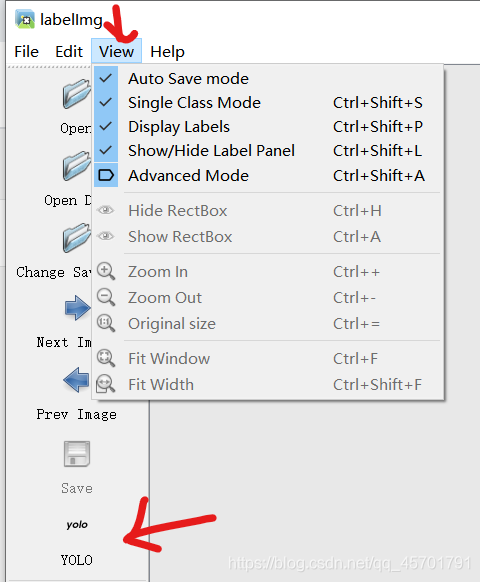
之后我们点击Open dir选择我们图片所在的images文件夹,选择之后会弹窗让你选择labels所在的文件夹。当然如果选错了,也可以点change save dir进行修改。
然后软件右上角我们打开这个选项,当我们标记图片后,就会自动帮我们归类到A了;
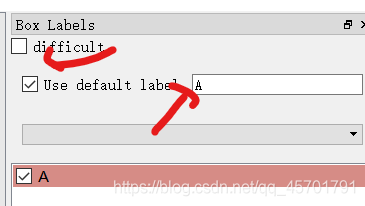
现在我们就可以开始进行标记了,常用的快捷键,用主要wad三个键;
Ctrl + u Load all of the images from a directoryCtrl + r Change the default annotation target dirCtrl + s SaveCtrl + d Copy the current label and rect boxCtrl + Shift + d Delete the current imageSpace Flag the current image as verifiedw Create a rect boxd Next imagea Previous imagedel Delete the selected rect boxCtrl++ Zoom inCtrl-- Zoom out↑→↓← | Keyboard arrows to move selected rect box
- 1
通过鼠标拖拽框选即可标注:

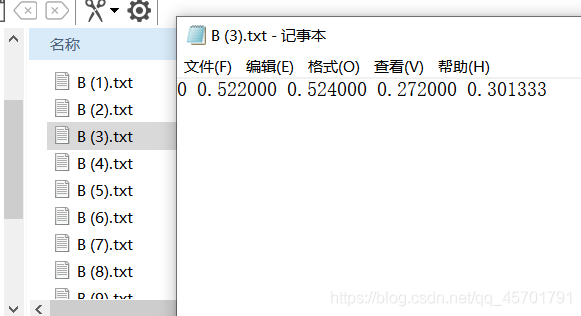
所有图片标注好之后,我们再来看我们的labels文件夹,可以看到很多txt文件。每个文件都对应着我们标记的类别和框的位置:
最后还要做的是建立yaml文件,文件的位置也不要放错:
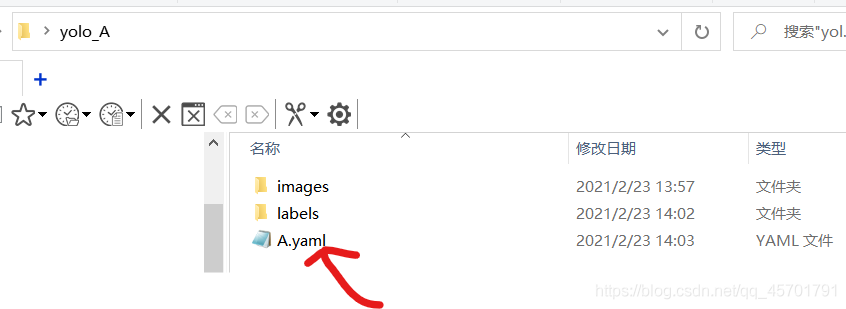
文件里面内容如下,其中train和val都是我们images的目录,labels的目录不用写进去,会自动识别。nc代表识别物体的种类数目,names代表种类名称,如果多个物体种类识别的话,可以自行增加。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../yolo_A/images/
val: ../yolo_A/images/
# number of classes
nc: 1
# class names
names: ['A meng']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这样,我们的训练的材料就已经准备好了。
四、yolov5模型训练
现在我们开始训练模型,由于电脑的配置过低,我采用的是谷歌colab平台进行训练,使用方法和notebook完全一样。使用云端colab会比使用本地的notebook多一些文件上传的操作,大家注意区分差异。
首先进行模块的导入,由于云端的colab还没有下载yolov5和他的依赖,所以加上前面两行,如果是本地notebook的用户,则注释掉前面三句:
!git clone https://github.com/ultralytics/yolov5 # clone repo%cd yolov5%pip install -qr requirements.txt # install dependenciesimport torchfrom IPython.display import Image, clear_output # to display imagesclear_output()print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
- 1
之后我把我们的的素材yolo_A文件夹压缩上传到colab,然后在colab上解压(本地notebook不需要这步操作)
!unrar x ../yolo_A ../
- 1
然后测试一下代码能否正常工作,顺带会下载yolov5s.pt文件,这个文件后面训练的时候会用到
!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/Image(filename='runs/detect/exp/zidane.jpg', width=600)
- 1
如果一切正常会显示如下图

接下来就要开始训练模型了:
!python train.py --img 640 --batch 50 --epochs 100 --data ../yolo_A/A.yaml --weights yolov5s.pt --nosave --cache
- 1
训练完成后,我们可以看到训练结果保存的位置:

在对应exp文件下可以看到用训练集做预测的结果:
Image(filename='runs/train/exp2/test_batch0_pred.jpg', width=800) # test batch 0 predictions
- 1
现在我们用训练出来的结果找一张网图做测试(文件名和导出预测文件地址不一定相同,但是相似,大家自行寻找)
!python detect.py --weights /content/yolov5/runs/train/exp2/weights/best.pt --img 640 --conf 0.25 --source ../test2.jpg
Image(filename='runs/detect/exp4/test2.jpg', width=600)
- 1
- 2
最终结果示意图:
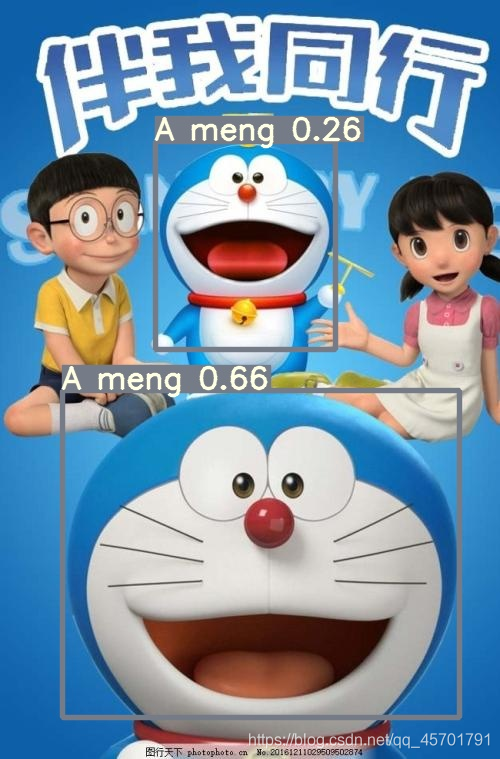
好了,基本上就完成了,如果想继续提高识别的精确度还需要使用到yolov5的实现原理以及相关参数的设定技巧。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入【3D视觉开发者社区】学习行业前沿知识,赋能开发者技能提升!
加入【3D视觉AI开放平台】体验AI算法能力,助力开发者视觉算法落地!
往期推荐:
1、奥比中光&英伟达第三届3D视觉创新应用竞赛圆满落幕!
2、 速来!2023第三届3D视觉创新应用竞赛决赛即将开启!
3、开发者社区「运营官」招募启动啦!_奥比中光3D视觉开发者社区的博客-CSDN博客
4、为什么你的手机后置摄像头越来越丑?ECCV2022这篇论文告诉你_奥比中光3D视觉开发者社区的博客-CSDN博客

