
- 1Wget用法、参数解释的比较好的一个文章 _wget成功
- 2python自定义函数的参数有多种类型_小议Python中自定义函数的可变参数的使用及注意点...
- 3vue3开源后台管理系统模板_vue3 后台模板
- 4程序员:分享几个好玩的东东(上)
- 5每日总结_每天的总结
- 6Pytorch:多模态大模型预训练、大模型微调:加载数据的正确姿势
- 7基于pytorch的图像识别基础完整教程_pytorch图像识别
- 82011-09-09 —— A5 —— 把 ON_KEY 键从休眠唤醒键改成开机关机键
- 9Android系统预置App进行权限预授权的方法_android 预制 应用 uid 权限
- 10Android stuido 中的keystore_android keystore country code
2023扩散模型最新技术进展汇总_扩散模型最新进展
赞
踩
随着Stable Diffusion和Midjourney等图像生成模型的爆火,今年在模型领域,扩散模型稳占主导地位。因此,与之相关的新技术也层出不穷,短短1个月,扩散模型相关的论文就有上百篇了,可见其发展的火热趋势。
这次我整理了一部分最新扩散模型相关论文来和大家分享,有50+篇,希望能帮助同学们获取新的思路~
1.Hyperspectral and Multispectral Image Fusion Using the Conditional Denoising Diffusion Probabilistic Model
标题:多光谱图像和超光谱图像融合使用基于条件去噪扩散概率模型
内容:Hyperspectral 图像有大量光谱信息,但空间分辨率低。多光谱图像如 RGB 图像有高空间分辨率,但波段不足。图像融合目标是获得同时具有高空间分辨率和高光谱分辨率的图像。现有方法依赖已知的图像退化模型,但这在实际中常常不可用。
本文提出基于条件去噪扩散模型 DDPM-Fus 的深度融合方法。它包含正向添加高斯噪声的扩散过程,以及反向从噪声版本预测高分辨率 HSI 的去噪过程。训练完成后,在测试数据上实现反向过程,根据高分辨率 MSI 和低分辨率 HSI 生成融合的高分辨率 HSI。实验结果展示了与其他深度学习融合方法相比的优势。

2.IPO-LDM Depth-aided 360-degree Indoor RGB Panorama Outpainting via Latent Diffusion Model
标题:IPO-LDM:基于潜在扩散模型的深度辅助室内360度RGB全景图像补painting
内容:作者提出使用潜在扩散模型(LDM)进行室内360° RGB全景图像补 painting的方法。
论文主要贡献:
-
提出一种新颖的双模态潜在扩散结构,在训练时同时利用RGB和深度全景数据,但在推理时仅需要RGB图像就能进行出色的补painting。
-
在每个扩散反噪声步骤中引入渐进式相机旋转,大幅提升全景图像的环绕一致性。
-
与SOTA方法相比,该方法不仅全景RGB图像补painting效果显著提升,还可以为不同mask生成多个不同且结构合理的结果。

3.How to Detect Unauthorized Data Usages in Text-to-image Diffusion Models
标题:如何检测文本到图像扩散模型中的未经授权的数据用法
内容:这篇文章提出了一种通过在受保护的数据集上训练的文本到图像扩散模型中植入注入记忆,来检测未经授权的数据用法的方法。
主要工作如下:
-
在受保护的图像数据集上修改图片,增加难以被人眼察觉但可以被扩散模型捕捉并记忆的独特内容,如隐秘的图像包装函数。
-
通过分析模型是否对注入的内容有记忆(即生成的图像是否被选择的后处理函数处理过),可以检测到非法使用未经授权数据训练的模型。
-
在Stable Diffusion和LoRA模型上的实验表明,该方法可以有效检测未经授权的数据用法。
-
该技术能够帮助保护艺术家的作品免受未经授权的使用。

4.Censored Sampling of Diffusion Models Using 3 Minutes of Human Feedback
标题:仅用3分钟人工反馈对Diffusion模型进行审查采样
内容:Diffusion模型最近在高质量图像生成方面取得了显著成功,但是,预训练的diffusion模型有时会表现出一定的失准,可以生成好的图像,但有时也会输出不可取的图像。如果出现这种情况,我们只需要阻止生成bad images,这就是审查(censoring)。在本文中,作者提出了一种方法,使用在极少人工反馈上训练的奖励模型来进行预训练diffusion模型的审查生成。结果表明,这种审查方式可以以极高的人工反馈效率实现,仅几分钟的人工反馈生成的标签就足以完成此任务。

5.Synthetic CT Generation from MRI using 3D Transformer-based Denoising Diffusion Model
标题:使用基于3D变压器的去噪扩散模型从MRI生成合成CT
内容:本文提出了一种MRI到CT的基于变压器的去噪扩散概率模型(MC-DDPM),将MRI转换为高质量的sCT,以促进放射治疗计划。MC-DDPM通过带移位窗口的变压器网络实现了从MRI到sCT的扩散过程。该模型由两个过程组成:正向过程是在真实CT上添加高斯噪声以创建噪声图像,反向过程是Swin-Vnet去噪被输入MRI对应患者的噪声CT,以产生无噪声CT。通过优化训练的Swin-Vnet,反向扩散过程用于生成与MRI解剖匹配的sCT。
6.Detecting Images Generated by Deep Diffusion Models using their Local Intrinsic Dimensionality
标题:使用局部内在维度检测深度扩散模型生成的图像
内容:本文提出使用最初为检测对抗样本而开发的轻量级多局部内在维度(multiLID)来自动检测合成图像和识别对应的生成器网络。与许多只能检测GAN生成的图像的现有检测方法不同,该方法在许多实际使用场景中可以实现接近完美的检测结果。大量实验在已知和新创建的数据集上表明,所提出的multiLID方法在扩散检测和模型识别方面展现出优越性。

7.DiffFlow: A Unified SDE Framework for Score-Based Diffusion Models and Generative Adversarial Networks
标题:DiffFlow: 统一的SDE框架,适用于基于得分的扩散模型和对抗生成网络
内容:本文提出了一个统一的理论框架来描述SDMs和GANs。表明:SDMs和GANs的学习动力学可以用一种新提出的名为歧视器去噪扩散流(DiffFlow)的SDE来描述;通过调整不同分数术语之间的相对权重,可以获得SDMs和GANs之间的平滑过渡,而SDE的边缘分布保持不变;作者证明了DiffFlow动力学的渐近最优性和最大似然训练方案;在统一理论框架下,作者提出了几个 DiffFlow的具体实现,它们提供了精确似然推理和在高样本质量与快速采样速度之间进行平衡的新算法。本文为GANs和SDMs提供了一个统一的理论框架,并基于此提出新的生成模型算法。
8.Training Energy-Based Models with Diffusion Contrastive Divergences
标题:使用扩散对比散度训练能量基模型
内容:本文将CD解释为我们提出的扩散对比散度(DCD)家族的一个特例。通过用其他不依赖EBM参数的扩散过程替换CD中使用的Langevin动力学,作者提出了一种更高效的散度,证明所提出的DCD相较CD既更高效又不受非可忽略梯度项的限制。作者进行了大量实验,包括合成数据建模、高维图像降噪和生成,来展示所提出DCD的优势。在合成数据学习和图像降噪实验中,作者提出的DCD明显优于CD。在图像生成实验中,所提出的DCD能够训练出一个生成Celab-A 32x32数据集的能量基模型,与现有EBM可比。

9.DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models
标题:DragonDiffusion: 在扩散模型上实现拖拽式操作
内容:本文提出了一种新颖的图像编辑方法DragonDiffusion,在扩散模型上实现拖拽式操作。具体来说,通过扩散模型中间特征的强对应关系构建分类器指导。它可以通过特征对应损失将编辑信号转换为渐变,以修改扩散模型的中间表示。在此指导策略的基础上,还构建了多尺度指导,同时考虑语义和几何对齐。此外,添加了跨分支自注意力以维持原始图像和编辑结果之间的一致性。通过高效设计,作者的方法实现了对生成或真实图像的各种编辑模式,如对象移动、调整大小、外观替换和内容拖拽。值得注意的是,所有编辑和内容保留信号都来自图像本身,模型不需要微调或额外模块。

10.Synchronous Image-Label Diffusion Probability Model with Application to Stroke Lesion Segmentation on Non-contrast CT
标题:非对比CT图像脑梗塞灶分割的同步图像标签扩散概率模型
内容:本文提出了一种新颖的同步图像标签扩散概率模型(SDPM),用于在非对比CT上分割脑梗塞灶,基于马尔可夫扩散过程。作者提出的SDPM完全基于潜变量模型(LVM),提供了完整的概率推断。引入额外的网状流并行噪声预测流,以高效推断最终标签。通过优化变分边界,训练好的模型可以在输入带噪声图像时推断多个参考标签。在公开和私有三个脑梗塞灶数据集上评估了该模型,与若干U-Net和Transformer基础分割模型相比,作者提出的SDPM模型能够达到最先进的性能。
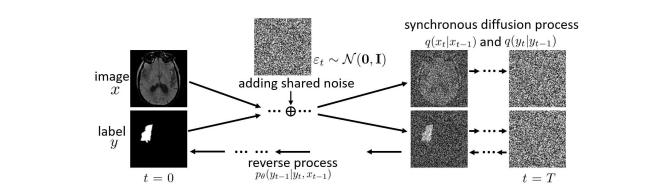
11.SwinGNN:Rethinking Permutation Invariance in Diffusion Models for Graph Generation
标题:SwinGNN:重新思考图生成扩散模型中的排列不变性
内容:基于排列等变网络的扩散模型可以为图数据学习排列不变的分布,然而与非不变模型相比,这些不变模型的学习面临更大挑战,因为它们的有效目标分布展现更多模态,最优一步去噪分数是具有更多成分的高斯混合的分数函数。为此,作者提出了一个非不变的扩散模型SwinGNN,它采用高效的边到边2-WL消息传递网络,并利用Swin Transformers启发的移位窗口自注意力。此外,通过系统的分析,作者确定了几个关键的训练和采样技术,这显著提高了图生成的样本质量。最后,作者引入了一个简单的后处理技巧,即随机排列生成的图,这可以证明任何图生成模型都可以转换为排列不变的。

其他论文
-
TomatoDIFF On-plant Tomato Segmentation with Denoising Diffusion Models
-
Unsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations
-
Squeezing Large-Scale Diffusion Models for Mobile
-
ACDMSR :Accelerated Conditional Diffusion Models for Single Image Super-Resolution
-
ON A CHEMOTAXIS-HAPOTAXIS MODEL WITH NONLINEAR DIFFUSION MODELLING MULTIPLE SCLEROSIS
-
MissDiff:Training Diffusion Models on Tabular Data with Missing Values
-
Spiking Denoising Diffusion Probabilistic Models
-
DiffusionSTR:Diffusion Model for Scene Text Recognition
-
DiffSketcher:Text Guided Vector Sketch Synthesis through Latent Diffusion Models
-
Diffusion Model Based Low-Light Image Enhancement for Space Satellite
-
HumanDiffusion:diffusion model using perceptual gradients
-
EMoG:Synthesizing Emotive Co-speech 3D Gesture with Diffusion Model
-
Diffusion model based data generation for partial differential equations
-
Drag-guided diffusion models for vehicle image generation
-
Diffusion Models for Zero-Shot Open-Vocabulary Segmentation
-
On the Robustness of Latent Diffusion Models
-
Diffusion Models for Black-Box Optimization
-
Fast Diffusion Model
-
DiffusionShield:A Watermark for Copyright Protection against Generative Diffusion Models
-
Faster Training of Diffusion Models and Improved Density Estimation via Parallel Score Matching
CVPR 2023
-
Imagic: Text-Based Real Image Editing with Diffusion Models
-
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
-
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
-
On Distillation of Guided Diffusion Models
-
Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
-
Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models
-
Null-text Inversion for Editing Real Images using Guided Diffusion Models
-
How to Backdoor Diffusion Models
-
DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
-
SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
ICLR 2023
-
Diffusion Posterior Sampling for General Noisy Inverse Problems
-
Diffusion probabilistic modeling of protein backbones in 3D for the motif-scaffolding problem
-
Diffusion Adversarial Representation Learning for Self-supervised Vessel Segmentation
-
DreamFusion: Text-to-3D using 2D Diffusion
-
Diffusion-GAN: Training GANs with Diffusion
-
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
-
Blurring Diffusion Models
-
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
-
Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

