
- 1大模型LLM在Text2SQL上的应用实践
- 2VMware虚拟机克隆ubuntu20.04系统IP相同_vmware克隆虚拟机后ip地址一样吗
- 3Linux — 进程控制_linux之进程管理一头歌答案
- 4CPU、GPU、DPU、TPU、NPU的区别_gpu、npu、dpu任选,国产、通用
- 5ChatGLM-6B does not appear to have a file named config.json._oserror does not appear to have a file named confi
- 6小白在虚拟环境下安装transformers_pycharm 安装transformer
- 7机器学习与神经网络的本质(高屋建瓴)_基于神经网络的算法和最小二乘法比较
- 8虚假IP地址攻击如何溯源?_溯源ip地址
- 9《Java高级程序设计》复习题_使用反射机制获取一个类的属性时,下列关于getfields()方法的说法中正确的是()
- 10基于遥感图像深度学习的海洋测深_深度学习识别水的深度
AI绘画之三_StableDiffusion_界面操作_sd-webui-roop 换脸不生效
赞
踩
1 介绍
首先,介绍界面中的重要元素,如图所示:
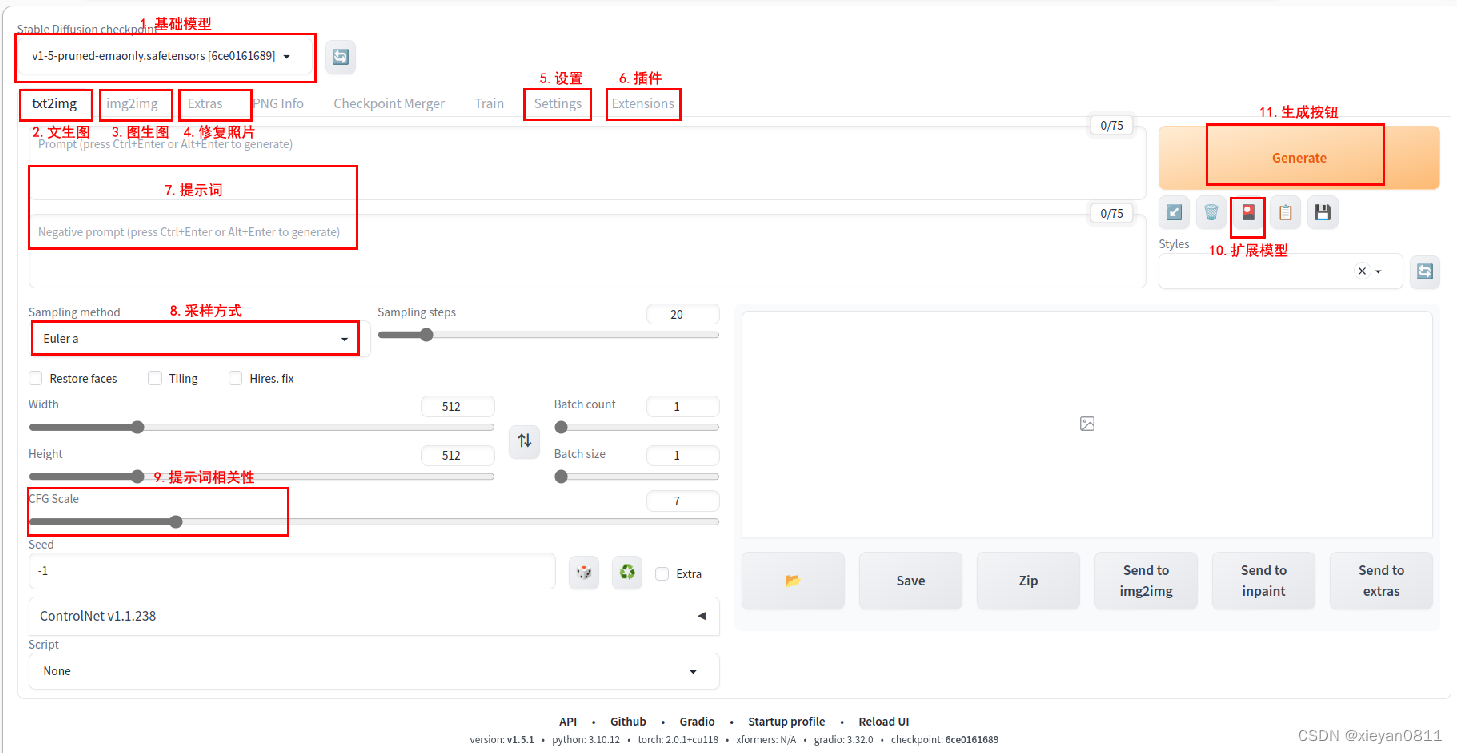
- 基础模型:基础模型是最重要的设置项
- 文生图:选项卡列出了各大功能,文生图指通过文字生成图片
- 图生图:图生图指通过图片和文字生成图片
- 修复照片:用于优化图片,提升精度,常用来修复旧照片
- 设置:软件设置,VAE模型可在此设置
- 插件:用于安装和管理插件,注意命令行启动时应允许安装插件
- 提示词:提示词分为正向提示和负向提示,负向提示用于限制可能的问题
- 采样方式:常用 Euler a ,DPM2++2M Karras
- 提示词相关性:设置画面与提示词的相关性,一般设为5-10,如果太高,色彩会过于饱和
- 扩展模型:设置基础模型的附加模型,Embedding和LoRA模型就在此设置
- 生成按钮:按此按钮生成图片
2 文生图 & 图生图
文生图和图生图是 SD 的核心功能,其中图生图也支持识别文字描述,故可将文生图看作图生图的一部分。相对来说图生图功能也更丰富。本部分以图生图为主,讲解具体用法。
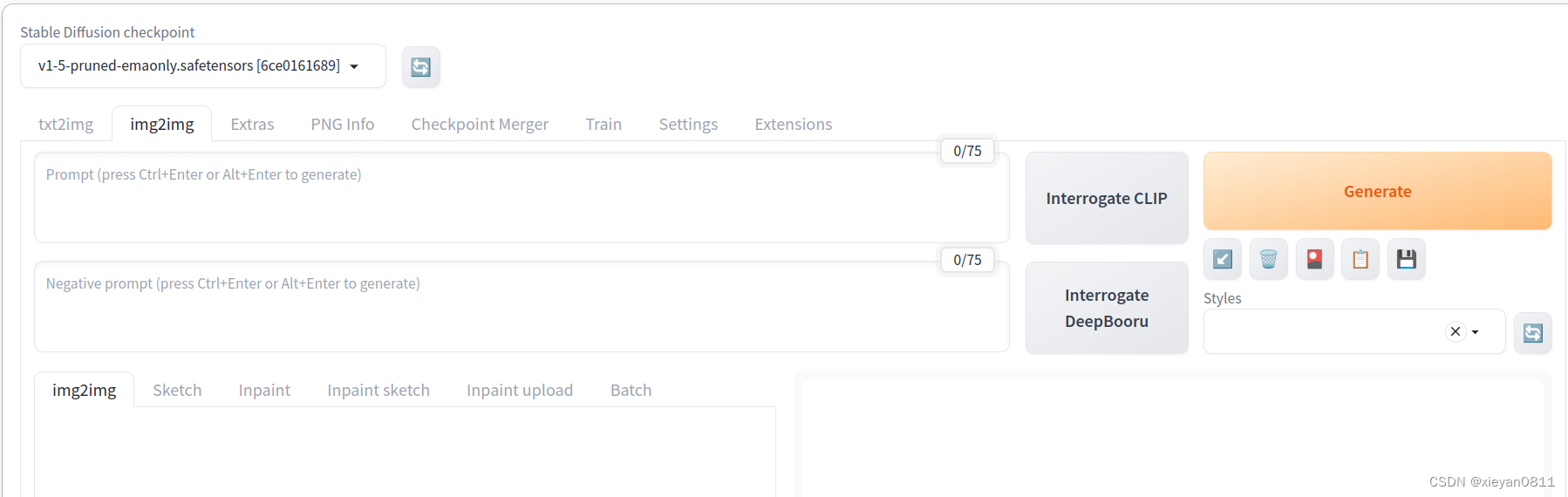
2.1 图生图与文生图的差别
可以看到图生图界面比文生图多了一些控件,主要差别如下:
- 生成图片之前首先要上传一张基础图片。
- 反推咒语:Interrogate CLIP / Interrogate DeepBooru 按钮分别支持两种方法从图片中提取提示词,第一次使用时在后台下载模型,时间较长。
- 子功能又细分为以下六种:
- img2img:基础的图生图功能,常用于整图风格的改变,比如将相片改成2D效果
- Sketch:涂鸦功能,可在基础图上绘制颜色,画好主色后,细节直接交给 AI 绘制
- Inpaint:修改部分图,常用于换衣服,换脸等局部修改
- Inpaint sketch:用涂鸦方式修改部分图
- Inpaint upload:上传部分图蒙板,以便更精确地改图
- Batch:批量改图
- 重绘幅度(Denosing strength):设置值越大表示对原图重绘幅度越大,相对的提示词影响也越大,0.5为分界点,一般设为 0.5 以上就与原图不太像了。
2.2 提示词
2.2.1 提示词格式
- 提示词用于描述待生成的图像内容
- 提示词可支持中文,但不如英文理解的好
- 多个提示词可用逗号隔开,无需适合英文语法
- 对提示词加权重:用小括号把关键词括起来(curly hair),这样括号一次就是1.1倍权重,那括两次((curly hair))就是1.1×1.1=1.21倍,以此类推;
- 对提示词减权重:用中括号把单词括起来,如:[curly hair]
- 指定权重数值 (关键词:数值):(curly hair:1.3)
2.2.2 正向提示词
- 设定画质:masterpiece, best quality, Highly detailed,
- 设定人物:性别,年龄,发型,衣服颜色,样式,身材
- 设定人物表情&动作:微笑,大笑,酷
- 设定人物关系:如母亲和女儿
- 设定画面内其它物品
- 设定方向:如人物背面
- 设定背景:背景内容,背景风格
- 设定风格:水彩画 water painting art,水墨画 ink drawing,漫画风 Anime, 鲜艳 Vivid Colors, 前景实背景虚 Bokeh,素描 Sketch,线图 a line drawing
- 光感镜头:rayonism,perfect lighting, sharp focus
2.2.3 负向提示词
- 手指问题,手型问题:bad hands, missing fingers, (too many fingers:1.2)
- 五官问题:(unclear eyes:1.2)
- 多出来的胳膊和腿:(missing arms:1.2), (extra legs:1.2),(missing legs:1.2), (extra arms:1.2)
- 画质问题:(worst quality:2), (low quality:2), blurry
2.2.4 注意
- 上述提示词只是举例,具体请看参考部分的《提示词词缀使用指南》
- 从 https://civitai.com/ 点击模型生成的图,可以看到提示和参数,用于参考
- 虽然可以指定风格,但是生成的具体画质和风格主要看 基础模型 和 LoRA模型 的能力
- 手指问题如果比较严重,建议使用 ControlNet 的 Openpose+Depth,负向提示词,或者After Detailer插件
3 插件
3.1 sd-webui-controlnet
ControlNet 让用户更精确地绘制姿势动作、面部特征、风格等元素。是 SD 中最重要的插件,没有之一,之前文档里已经介绍了,不再缀述。
3.2 sd-webui-tagcomplete
TagComplete 提供了提示词补全功能。当开始输入提示词时,它会列出与输入相关提示词,也可用’<'呼出Lora等提示词。
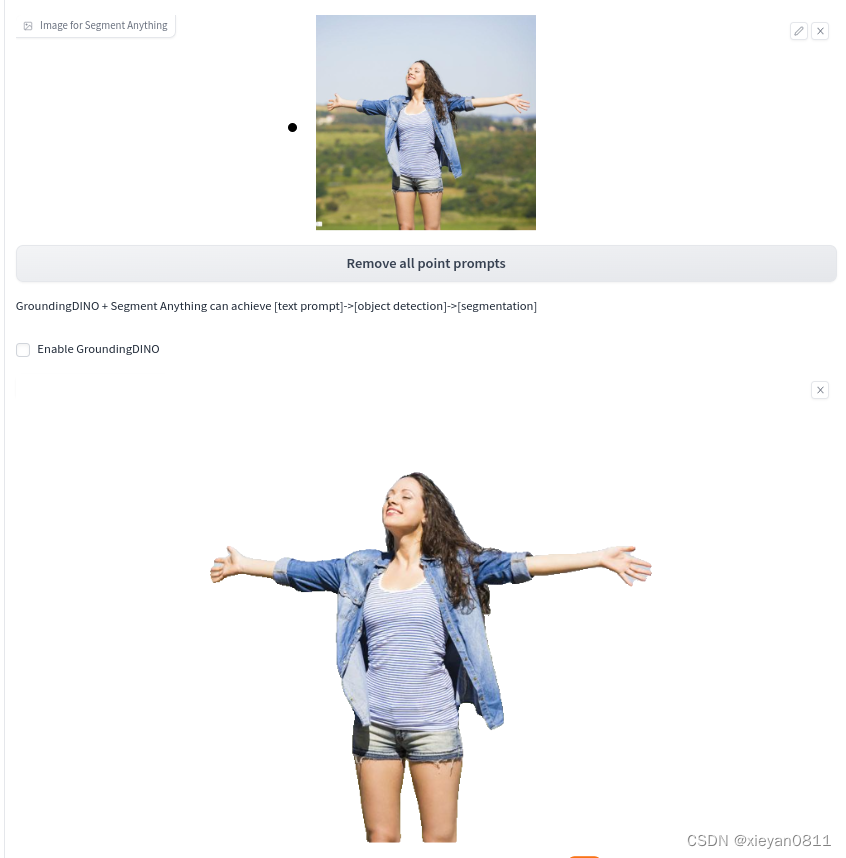
3.3 sd-webui-segment-anything
Segment-anything 用于自动抠图,效果非常好,它基于人对世界的认知抠图,而非只考虑颜色,能一键抠出整个人。其用法类似ControlNet,安装之后,在Inpaint界面的下方出现 Segment Anything 折叠界面。
需要下载模型:https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
大小为 2.4G,复制到 extensions/sd-webui-segment-anything/models/sam/ 后即可使用,效果如下:
3.4 adetailer
After Detailer 是一种后处理,可选择不同模型对手和脸精调。一般的操作是:利用随机种子生成图片,当遇到一张图片其它方面都比较满意,但手或脸的细节有问题时,固定该种子,打开 After Detailer 功能,重新生成即可。我试了一下,修手一般,修脸效果不错,具体使用的是 face_yolov8n.pt 模型。
3.5 sd-webui-roop
Roop提供换脸功能,由于我的 SD 安排在 Linux 服务器上,可以"科学",整个操作下来,除了一开始网络不好,进入虚拟环境中安装了一下依赖(requirements.txt),后面安装软件下载模型都是自动完成的,比Windows系统简单得多。
其核心使用了 insightface 模型,具体也在 img2img 的左下方操作。
注意:如果换脸不成功,需要关注一下服务后台的提示信息,可能是网络连接问题,可能是 CodeFormer 问题(如果是CodeFormer问题,将Restore Face设成None即可)。
4 实际应用
下面列举几个最常用的使用场景,以介绍具体的使用方法。
4.1 真人相片变卡通形象
4.1.1 准备
- 一张照片
4.1.2 SD 操作
- 大模型选二次元风格模型: Kakigori_V2
- 选择 img2img->img2img 子类别
- 上传一张真实照片
- 点 Interrogate CLIP 按钮,用模型分析图片对应的提示词(此步可省略)
- 根据自己的对图片的理解和目标修改提示词,尽量用英文
- 修改 denosing 参数为 0.5(根据效果调整)
- 多生成几张图片,选取喜欢的
- 注意:生成图片的风格主要看选择的基础模型风格及提示词
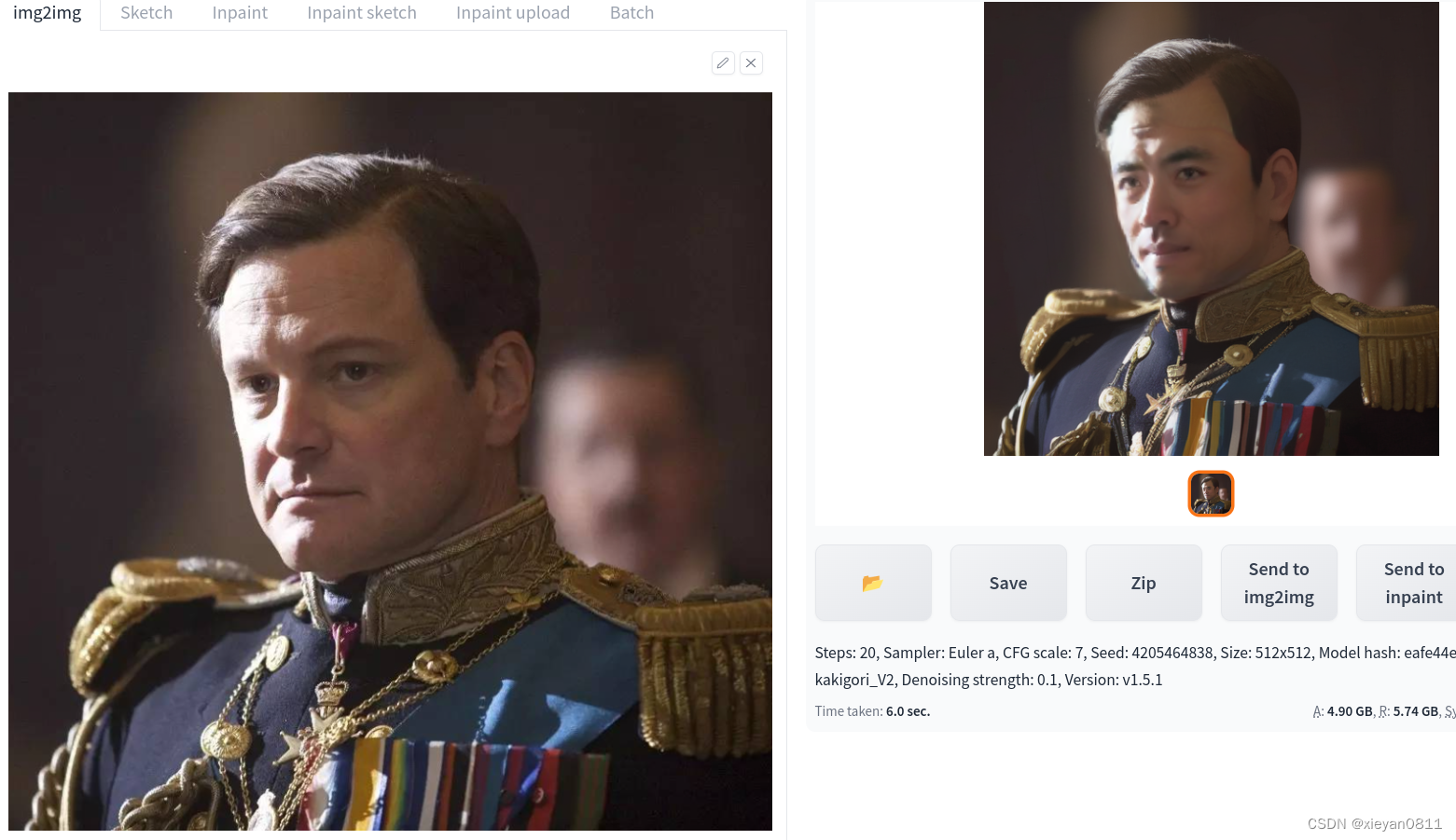
4.2 换头&换衣服&换背景
4.2.1 准备
- 一张照片
4.2.2 SD 操作
- 大模型选择真实场景模型: v1-5-pruned-emaonly
- 选择 img2img->inpaint sketch 子类别
- 上传一张真实照片
- 切换颜色,绘制需要修改的区域
- 填写提示词,比如把衣服换成旗袍:cheongsam(一定要填写)
- 修改 denosing 参数为 0.5(根据效果调整)
- 多生成几张图片,选取喜欢的
4.3 老照片修复
4.3.1 准备
- 模糊的图片
4.3.2 SD 操作
- 修复二次元的照片选“R-ESRGAN 4x+Anime68”,实物照片选“R-ESRGAN 4x+”
- 反复测试,如果不清楚,把 GFPGAN 强度拉大
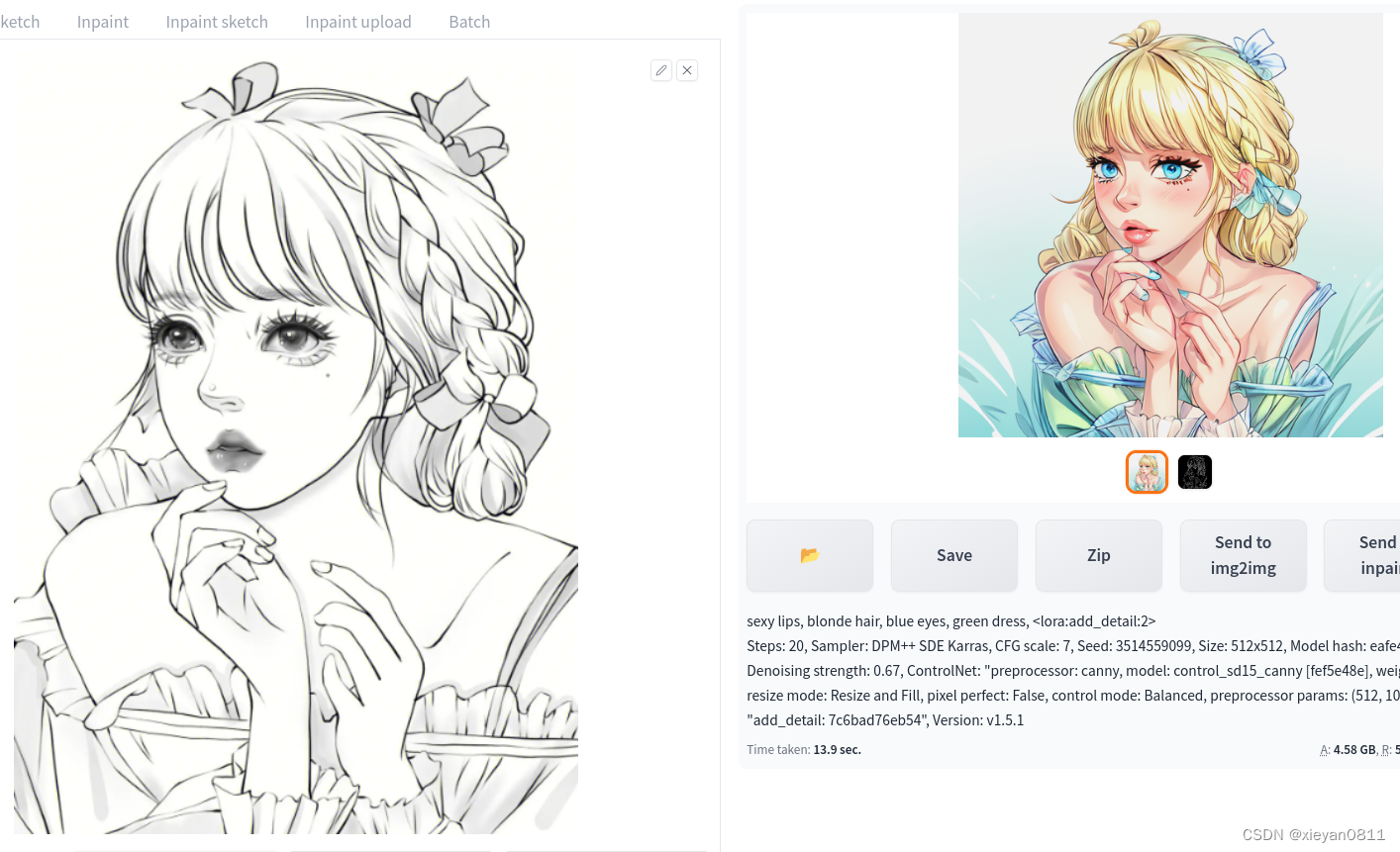
4.4 线稿上色
4.4.1 准备
- 签字笔画稿
- PhotoShop简单上色
4.4.2 SD操作
- 大模型选: kakigori_V2.safetensors
- 选择 img2img->img2img 子类别
- 正向提示:sexy lips, blonde hair, blue eyes, green dress, lora:add_detail:2
引处使用了 Lora:add_detail 用于添加细节 - 导入待上色的画稿作为基础图
- Sampling method: DPM++ SDE Karras (更为细腻)
- Donose strength:0.67
- 打开 ControlNet 折叠
- Scribble(Enable)
- Preprocessfor:canny
- Model:control_sd15_canny
- 其它项都使用默认值,生成即可
- 说明:效果主要依靠大模型和两个Lora模型比较给力,另外使用了 ControlNet 的涂鸦模型,它是自由度最高的填色工具,加入了很多细节。
4.5 原理分析
这是目前很喜欢的一组参数,用于将真人图片转成动漫风格,替换背景,保持表情和动作:
a handsome Asia young man in the forest <lora:add_detail:1> <lora:Pyramid lora_Ghibli_n3_0.7+Pyramid lora_Ghibli_v2_0.3:0.57> rayonism
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1672545665, Size: 512x512, Model hash: 8eccdfe4b6, Model: deepboys25D_v30, Denoising strength: 0.63, ControlNet 0: "preprocessor: scribble_xdog, model: control_sd15_scribble [fef5e48e], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 32, 200)", Lora hashes: "add_detail: 7c6bad76eb54, Pyramid lora_Ghibli_n3_0.7+Pyramid lora_Ghibli_v2_0.3: 895eb832de9d", Version: v1.5.1
- 1
- 2
其核心点如下(按重要性排序):
- 选了一个2.5D风格的底模,能很好地还原人物,人物形象有特色、统一、稳定,明度精细度均不错
- 使用了 ControlNet 的 scribble 涂鸦功能 scribble_xdog,这样既可以将 denosing 设大,让画面变化更加丰富,又有效地控制了人物的轮廓和表情变化
- 提示词对年龄、性别、人种、背景起到了简单的限制作用
- 使用了光照提示词 rayonism,外加 LoRA: add detail,精细刻画提升了画面质感
- 背景使用 LoRA:Ghibli 吉卜力风格(类似宫崎骏动画风格)

5 参考
Stable Diffusion 提示词词缀使用指南(Prompt)
Stable Diffusion 图生图(img2img)干货技巧,值得收藏
stable diffusion插件
Stable Diffusion-采样器篇


