
- 1自主系统的未来发展趋势
- 2利用手机热点(手机网络共享)+IPv6+DDNS实现外部网络访问家中电脑等设备_手机热点ipv6
- 3AGI:人工智能大模型领域实战篇—设计一个类似GPT-3.5/GPT-4的大模型从开发→部署→应用需要经过的八大步骤、为什么只有少数公司和机构能够承担这样的训练成本之详细介绍_大模型实战
- 4RK3588上部署yoloV5_rk3588 yolov5
- 5SCDN是什么?
- 6Spark Streaming 编程新手入门指南_spark streaming是核心spark apl 的扩展,支持可扩展,实时数据流的
- 7AI 的架构与核心
- 8利用python中GDAL读写tif文件_python gdal 读取 超大图片
- 9阿里张勇:所有行业都值得用大模型重新做一遍!
- 10[转载]uni-app 换肤实现-原生导航栏、tabbar和页面全部替换_uniapp 用一个组件替换当前页所有内容
图解Kafka架构学习笔记(二)
赞
踩
kafka的存储机制
-
https://segmentfault.com/a/1190000021824942
-
https://www.lin2j.tech/md/middleware/kafka/Kafka%E7%B3%BB%E5%88%97%E4%B8%83%E5%AD%98%E5%82%A8%E6%9C%BA%E5%88%B6.html
-
https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
-
https://feizichen.me/2019/12/KafkaFileMessage/
-
https://juejin.cn/post/6965401216599736351
存储文件结构
topic: 可以理解为一个消息队列的名字partition:为了实现扩展性,一个非常大的topic可以分布到多个 broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列segment:partition物理上由多个segment组成message:每个segment文件中实际存储的每一条数据就是messageoffset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中,partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息
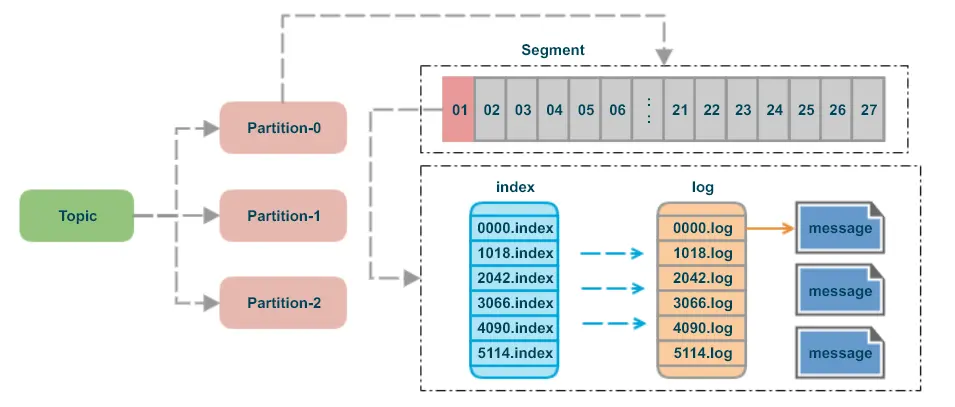
Partition分区
假设topic名称为test-topic,默认设置partition为3,topic创建成功后默认的存储位置在:/tmp/kafka-logs下,分区分别以topic名称-分区数命名,(不考虑副本的情况)如下:
//分布在不同的broker节点上
test-topic-0
test-topic-1
test-topic-2
- 1
- 2
- 3
- 4
疑问一:为什么要分区呢?
为了性能考虑,如果不分区每个topic的消息只存在一个broker上,那么所有的消费者都是从这个broker上消费消息,那么单节点的broker成为性能的瓶颈,如果有分区的话生产者发过来的消息分别存储在各个broker不同的partition上,这样消费者可以并行的从不同的broker不同的partition上读消息,实现了水平扩展。
疑问二:分区文件下到底存了那些东西?
如下,其实每个分区下保存了很多文件,而概念上我们把他叫segment,即每个分区都是又多个segment构成的,其中index(索引文件),log(数据文件),time index(时间索引文件)统称为一个segment。
test-topic-0
├── 00000000000000000001.index
├── 00000000000000000001.log
├── 00000000000000000001.timeindex
├── 00000000000000001018.index
├── 00000000000000001018.log
├── 00000000000000001018.timeindex
├── 00000000000000002042.index
├── 00000000000000002042.log
├── 00000000000000002042.timeindex
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Segment File组成:由2大部分组成,分别为.log和.index文件,此 2 个文件一一对应,成对出现。Segment File命名规则:Partion全局的第一个Segment 从0开始,后续每个Segment文件名为上一个Segment文件最后一条消息的offset值。
index 文件为 log 文件的消息提供了索引,具体是提供某条消息所在的位置。
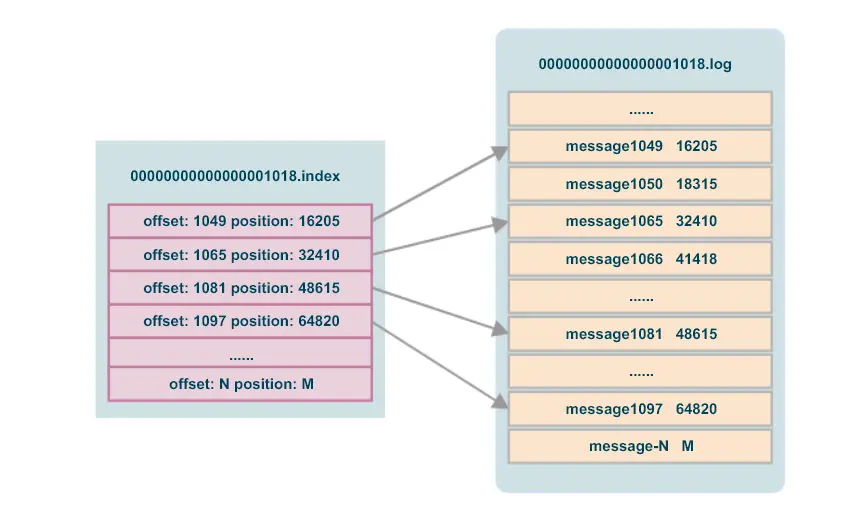
疑问三: 为什么有了partition还需要segment ?
通过上面目录显示存在多个segment的情况,既然有分区了还要存多个segment干嘛?如果不引入segment,那么一个partition只对应一个文件(log),随着消息的不断发送这个文件不断增大,由于kafka的消息不会做更新操作都是顺序写入的,如果做消息清理的时候只能删除文件的前面部分删除,不符合kafka顺序写入的设计,如果多个segment的话那就比较方便了,直接删除整个文件即可保证了每个segment的顺序写入
Segment存储
Segment中核心文件是index索引文件和log数据文件,既然是索引文件当然是为了更高效的定位到数据,那么索引文件和数据文件中到底是存了那些数据?又是如何快速找到消息数据呢?
使用kafka自带脚本发送测试数据
sh kafka-producer-perf-test.sh --topic test-topic --num-records 50000000 --record-size 1000 --throughput 10000000 --producer-props bootstrap.servers=192.168.60.201:9092
- 1
使用kafka自带脚本Dump index
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-topic-0/00000000000000001018.index --print-data-log
- 1
offset: 1049 position: 16205
offset: 1065 position: 32410
offset: 1081 position: 48615
offset: 1097 position: 64820
offset: 1113 position: 81025
offset: 1129 position: 97230
- 1
- 2
- 3
- 4
- 5
- 6
通过dump index我们发现其实索引文件中其实就保存了offset和position,分别是消息的offset也就是具体那一条消息,position表示具体消息存储在log中的物理地址。
疑问一:通过上面数据可以看出,kafka并不是每个offset都保存了,为什么在index文件中这些offset编号不是连续的呢?
因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
使用kafka自带脚本Dump log
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-topic-0/00000000000000001018.log --print-data-log
- 1

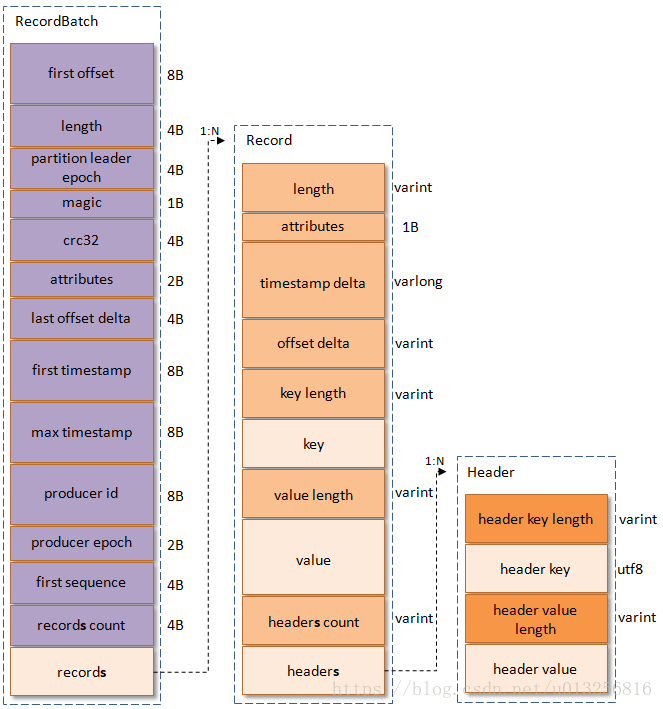
log数据文件中并不是直接存储数据,而是通过许多的message组成,message包含了实际的消息数据。
Message字段
kafka从0.11.0版本开始所使用的消息格式版本为v2,参考了Protocol Buffer而引入了变长整型(Varints)和ZigZag编码。 Varints是使用一个或多个字节来序列化整数的一种方法,数值越小,其所占用的字节数就越少。ZigZag编码以一种锯齿形(zig-zags)的方式来回穿梭于正负整数之间, 以使得带符号整数映射为无符号整数,这样可以使得绝对值较小的负数仍然享有较小的Varints编码值,比如-1编码为1,1编码为2,-2编码为3。
未完待续。。。

