
- 1button按钮的一些样式效果_button样式
- 2PyTorch 深度学习(GPT 重译)(一)
- 37.6:Python如何在文件中查找指定的内容?_python在文件中查找指定数据
- 4android studio gradle 切换国内源的方法_android studio换国内源
- 5linux 用户、用户组和权限_linux用户属组权限
- 6CAS实现原⼦操作的三⼤问题,该如何解决?_cas操作存在的问题
- 7python for windbg_wnkbqpy
- 8C++异常处理,标准库中异常_c++使用标准库错误
- 9错误已解决:java.net.ConnectException: Failed to connect to localhost/127.0.0.1
- 10【AIGC】一款离线版的AI智能换脸工具V2.0分享(支持图片、视频、直播)_ai人脸替换工具离线版v2.0
EM算法详解+通俗例子理解_em算法实例
赞
踩
1、总述
期望最大(Expectation Maximization)算法是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。EM算法是机器学习十大算法之一,或许确实是因它在实际中的效果很好吧。
2、定义
EM算法,全称Expectation Maximization Algorithm,译作最大期望化算法或期望最大算法,它是一种迭代算法,用于含有隐变量(hidden variable)的概率参数模型的最大似然估计或极大后验概率估计。
3、感性例子:
例子简介:
假设现在有两枚硬币1和2,,随机抛掷后正面朝上概率分别为 P 1 P_1 P1, P 2 P_2 P2。为了估计这两个概率,做实验,每次取一枚硬币,连掷5下,记录下结果,如下:
| 硬币 | 结果 | 统计 |
|---|---|---|
| 1 | 正正反正反 | 3正-2反 |
| 2 | 反反正正反 | 2正-3反 |
| 1 | 正反反反反 | 1正-4反 |
| 2 | 正反反正正 | 3正-2反 |
| 1 | 反正正反反 | 2正-3反 |
可以很容易地估计出 P 1 P_1 P1和 P 2 P_2 P2,(硬币1实验15次正面6次,硬币2实验10次正面5次)如下:
P
1
=
(
3
+
1
+
2
)
/
15
=
0.4
P
2
=
(
2
+
3
)
/
10
=
0.5
到这里,一切似乎很美好,下面我们加大难度。
加入隐变量z
还是上面的问题,现在我们抹去每轮投掷时使用的硬币标记,如下:
| 硬币 | 结果 | 统计 |
|---|---|---|
| Unknown | 正正反正反 | 3正-2反 |
| Unknown | 反反正正反 | 2正-3反 |
| Unknown | 正反反反反 | 1正-4反 |
| Unknown | 正反反正正 | 3正-2反 |
| Unknown | 反正正反反 | 2正-3反 |
好了,现在我们的目标没变,还是估计 P 1 P_1 P1和 P 2 P_2 P2,要怎么做呢?
显然,此时我们多了一个隐变量 z z z,可以把它认为是一个5维的向量 ( z 1 , z 2 , z 3 , z 4 , z 5 ) (z_1,z_2,z_3,z_4,z_5) (z1,z2,z3,z4,z5),代表每次投掷时所使用的硬币,比如 z 1 z_1 z1,就代表第一轮投掷时使用的硬币是1还是2。但是,这个变量 z z z不知道,就无法去估计 P 1 P_1 P1和 P 2 P_2 P2,所以,我们必须先估计出 z z z,然后才能进一步估计 P 1 P_1 P1和 P 2 P_2 P2。
但要估计 z z z,我们又得知道 P 1 P_1 P1和 P 2 P_2 P2,这样我们才能用最大似然概率法则去估计 z z z,这不是鸡生蛋和蛋生鸡的问题吗,如何破?
答案就是先随机初始化一个 P 1 P_1 P1和 P 2 P_2 P2,用它来估计 z z z,然后基于 z z z,还是按照最大似然概率法则去估计新的 P 1 P_1 P1和 P 2 P_2 P2,如果新的 P 1 P_1 P1和 P 2 P_2 P2和我们初始化的 P 1 P_1 P1和 P 2 P_2 P2一样,请问这说明了什么?
这说明我们初始化的 P 1 P_1 P1和 P 2 P_2 P2是一个相当靠谱的估计!
就是说,我们初始化的 P 1 P_1 P1和 P 2 P_2 P2,按照最大似然概率就可以估计出 z z z,然后基于 z z z,按照最大似然概率可以反过来估计出 P 1 P_1 P1和 P 2 P_2 P2,当与我们初始化的 P 1 P_1 P1和 P 2 P_2 P2一样时,说明是 P 1 P_1 P1和 P 2 P_2 P2很有可能就是真实的值。这里面包含了两个交互的最大似然估计。
如果新估计出来的 P 1 P_1 P1和 P 2 P_2 P2和我们初始化的值差别很大,怎么办呢?就是继续用新的 P 1 P_1 P1和 P 2 P_2 P2迭代,直至收敛。
这就是下面的EM初级版。
EM初级版
我们不妨这样,先随便给
P
1
P_1
P1和
P
2
P_2
P2赋一个值,比如:
P
1
=
0.2
P
2
=
0.7
P_1 = 0.2\\ P_2 = 0.7
P1=0.2P2=0.7
然后,我们看看第一轮抛掷最可能是哪个硬币。
如果是硬币1,得出正正反正反的概率为(注意这里是有先后顺序的)
0.2
∗
0.2
∗
0.2
∗
0.8
∗
0.8
=
0.00512
0.2*0.2*0.2*0.8*0.8 = 0.00512
0.2∗0.2∗0.2∗0.8∗0.8=0.00512
如果是硬币2,得出正正反正反的概率为
0.7
∗
0.7
∗
0.7
∗
0.3
∗
0.3
=
0.03087
0.7*0.7*0.7*0.3*0.3=0.03087
0.7∗0.7∗0.7∗0.3∗0.3=0.03087
然后依次求出其他4轮中的相应概率。做成表格如下:
| 轮数 | 若是硬币1 | 若是硬币2 |
|---|---|---|
| 1 | 0.00512 | 0.03087 |
| 2 | 0.02048 | 0.01323 |
| 3 | 0.08192 | 0.00567 |
| 4 | 0.00512 | 0.03087 |
| 5 | 0.02048 | 0.01323 |
按照最大似然法则:
第1轮中最有可能的是硬币2
第2轮中最有可能的是硬币1
第3轮中最有可能的是硬币1
第4轮中最有可能的是硬币2
第5轮中最有可能的是硬币1
我们就把上面的值作为 z z z的估计值。然后按照最大似然概率法则来估计新的 P 1 P_1 P1和 P 2 P_2 P2。
P
1
=
(
2
+
1
+
2
)
/
15
=
0.33
P
2
=
(
3
+
3
)
/
10
=
0.6
设想我们是全知的神,知道每轮抛掷时的硬币就是如前面例子中的那样,
P
1
P_1
P1和
P
2
P_2
P2的最大似然估计就是0.4和0.5(下文中将这两个值称为
P
1
P_1
P1和
P
2
P_2
P2的真实值)。那么对比下我们初始化的
P
1
P_1
P1和
P
2
P_2
P2和新估计出的
P
1
P_1
P1和
P
2
P_2
P2:
| 初始化的P1 | 估计出的P1 | 真实的P1 | 初始化的P2 | 估计出的P2 | 真实的P2 |
|---|---|---|---|---|---|
| 0.2 | 0.33 | 0.4 | 0.7 | 0.6 | 0.5 |
看到没?我们估计的 P 1 P_1 P1和 P 2 P_2 P2相比于它们的初始值,更接近它们的真实值了!
可以期待,我们继续按照上面的思路,用估计出的 P 1 P_1 P1和 P 2 P_2 P2再来估计 z z z,再用 z z z来估计新的 P 1 P_1 P1和 P 2 P_2 P2,反复迭代下去,就可以最终得到 P 1 = 0.4 P_1 = 0.4 P1=0.4, P 2 = 0.5 P_2=0.5 P2=0.5,此时无论怎样迭代, P 1 P_1 P1和 P 2 P_2 P2的值都会保持0.4和0.5不变,于是乎,我们就找到了 P 1 P_1 P1和 P 2 P_2 P2的最大似然估计。
这里有两个问题:
1、新估计出的
P
1
P_1
P1和
P
2
P_2
P2一定会更接近真实的
P
1
P_1
P1和
P
2
P_2
P2?
答案是:没错,一定会更接近真实的
P
1
P_1
P1和
P
2
P_2
P2,数学可以证明,但这超出了本文的主题,请参阅其他书籍或文章。
2、迭代一定会收敛到真实的
P
1
P_1
P1和
P
2
P_2
P2吗?
答案是:不一定,取决于
P
1
P_1
P1和
P
2
P_2
P2的初始化值,上面我们之所以能收敛到
P
1
P_1
P1和
P
2
P_2
P2,是因为我们幸运地找到了好的初始化值。
EM进阶版
下面,我们思考下,上面的方法还有没有改进的余地?
我们是用最大似然概率法则估计出的 z z z值,然后再用 z z z值按照最大似然概率法则估计新的 P 1 P_1 P1和 P 2 P_2 P2。也就是说,我们使用了一个最可能的 z z z值,而不是所有可能的 z z z值。
如果考虑所有可能的 z z z值,对每一个 z z z值都估计出一个新的 P 1 P_1 P1和 P 2 P_2 P2,将每一个 z z z值概率大小作为权重,将所有新的 P 1 P_1 P1和 P 2 P_2 P2分别加权相加,这样的 P 1 P_1 P1和 P 2 P_2 P2应该会更好一些。
所有的 z z z值有多少个呢?显然,有 2 5 = 32 2^5=32 25=32种,需要我们进行32次估值?
不需要,我们可以用期望来简化运算。
| 轮数 | 若是硬币1 | 若是硬币2 |
|---|---|---|
| 1 | 0.00512 | 0.03087 |
| 2 | 0.02048 | 0.01323 |
| 3 | 0.08192 | 0.00567 |
| 4 | 0.00512 | 0.03087 |
| 5 | 0.02048 | 0.01323 |
利用上面这个表,我们可以算出每轮抛掷中使用硬币1或者使用硬币2的概率。比如第1轮,使用硬币1的概率是:
0.00512
/
(
0.00512
+
0.03087
)
=
0.14
0.00512/(0.00512+0.03087)=0.14
0.00512/(0.00512+0.03087)=0.14
使用硬币2的概率是
1
−
0.14
=
0.86
1-0.14=0.86
1−0.14=0.86
依次可以算出其他4轮的概率,如下:
| 轮数 | z i z_i zi=硬币1 | z i z_i zi=硬币2 |
|---|---|---|
| 1 | 0.14 | 0.86 |
| 2 | 0.61 | 0.39 |
| 3 | 0.94 | 0.06 |
| 4 | 0.14 | 0.86 |
| 5 | 0.61 | 0.39 |
上表中的右两列表示期望值。看第一行,0.86表示,从期望的角度看,这轮抛掷使用硬币2的概率是0.86。相比于前面的方法,我们按照最大似然概率,直接将第1轮估计为用的硬币2,此时的我们更加谨慎,我们只说,有0.14的概率是硬币1,有0.86的概率是硬币2,不再是非此即彼。这样我们在估计 P 1 P_1 P1或者 P 2 P_2 P2时,就可以用上全部的数据,而不是部分的数据,显然这样会更好一些。
这一步,我们实际上是估计出了
z
z
z的概率分布,这步被称作E步。
结合下表:
| 硬币 | 结果 | 统计 |
|---|---|---|
| Unknown | 正正反正反 | 3正-2反 |
| Unknown | 反反正正反 | 2正-3反 |
| Unknown | 正反反反反 | 1正-4反 |
| Unknown | 正反反正正 | 3正-2反 |
| Unknown | 反正正反反 | 2正-3反 |
我们按照期望最大似然概率的法则来估计新的 P 1 P_1 P1和 P 2 P_2 P2:
以 P 1 P_1 P1估计为例,这里我们要做的事情是在之前推算出来的使用硬币1的概率下,去计算出现现在这种抛掷情况的可能性,就是说计算一下期望看看有多少次等价的硬币1抛出来为正,多少次抛出来为负,以第一轮为例,硬币1在第一轮中被使用的该概率是0.14,现在出现了三次正面两次反面。
第1轮的3正2反相当于
0.14
∗
3
=
0.42
0.14*3=0.42
0.14∗3=0.42正
0.14
∗
2
=
0.28
0.14*2=0.28
0.14∗2=0.28反
依次算出其他四轮,列表如下:
| 轮数 | 正面 | 反面 |
|---|---|---|
| 1 | 0.42 | 0.28 |
| 2 | 1.22 | 1.83 |
| 3 | 0.94 | 3.76 |
| 4 | 0.42 | 0.28 |
| 5 | 1.22 | 1.83 |
| 总计 | 4.22 | 7.98 |
P 1 = 4.22 / ( 4.22 + 7.98 ) = 0.35 P_1=4.22/(4.22+7.98)=0.35 P1=4.22/(4.22+7.98)=0.35
可以看到,改变了 z z z值的估计方法后,新估计出的 P 1 P_1 P1要更加接近0.4。原因就是我们使用了所有抛掷的数据,而不是之前只使用了部分的数据。
这步中,我们根据E步中求出的
z
z
z的概率分布,依据最大似然概率法则去估计
P
1
P_1
P1和
P
2
P_2
P2,被称作M步。
例子总结
以上,我们用一个实际的小例子,来实际演示了EM算法背后的idea,共性存于个性之中,通过这个例子,我们可以对EM算法究竟在干什么有一个深刻感性的认识,掌握EM算法的思想精髓。
4、Jensen不等式
在完善EM算法之前,首先来了解下Jensen不等式,因为在EM算法的推导过程中会用到。
Jensen不等式在优化理论中大量用到,首先来回顾下凸函数和凹函数的定义。假设 f f f是定义域为实数的函数,如果对于所有的 x x x, f ( x ) f(x) f(x)的二阶导数大于等于0,那么 f f f是凸函数。当 x x x是向量时,如果hessian矩阵 H H H是半正定(即 H > = 0 H>=0 H>=0),那么 f f f是凸函数。
如果, f ( x ) f(x) f(x)的二阶导数小于0或者 H > 0 H>0 H>0,那么f就是凹函数。
Jensen不等式描述如下:
- 如果 f f f是凸函数, X X X是随机变量,则 E [ f ( X ) ] > = f ( E [ X ] ) E[f(X)]>=f(E[X]) E[f(X)]>=f(E[X]),当 f f f是严格凸函数时,则 E [ f ( X ) ] > f ( E [ X ] ) E[f(X)]>f(E[X]) E[f(X)]>f(E[X]);
- 如果 f f f是凹函数, X X X是随机变量,则 f ( E [ X ] ) < = E [ f ( X ) ] f(E[X])<=E[f(X)] f(E[X])<=E[f(X)],当 f f f是(严格)凹函数当且仅当 − f −f −f是(严格)凸函数。
通过下面这张图,可以加深印象:
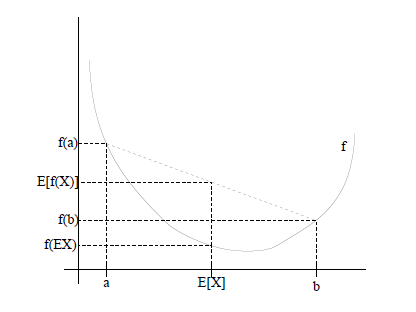
上图中,函数 f f f是凸函数, X X X是随机变量,有0.5的概率是 a a a,有0.5的概率是 b b b。 X X X的期望值 E ( x ) E(x) E(x)就是 a a a和 b b b的中值 a + b 2 \frac{a+b}{2} 2a+b了,图中可以看到 E [ f ( X ) ] > = f ( E [ X ] ) E[f(X)]>=f(E[X]) E[f(X)]>=f(E[X])成立。
5、EM思想
EM算法推导过程中,会使用到极大似然估计法估计参数,所以,首先给出一个求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
关于极大似然估计的实例,这里就不再提及了,下面介绍EM算法。
给定 m m m个训练样本 { x 1 , x 2 , … , x m } \{x_1,x_2,\ldots,x_m\} {x1,x2,…,xm},假设样本间相互独立,我们想要拟合模型 p ( x , z ) p(x,z) p(x,z)到数据的参数, z j ( i ) z_j^{(i)} zj(i)为在 x i x_i xi的情况下不同 z z z的可能 { z 1 ( i ) , z 2 ( i ) , … , z j ( i ) } \{z_1^{(i)},z_2^{(i)},\ldots,z_j^{(i)}\} {z1(i),z2(i),…,zj(i)}。根据分布,我们可以得到如下这个似然函数:
ℓ
(
θ
)
=
∑
i
=
1
m
log
p
(
x
i
;
θ
)
=
∑
i
=
1
m
log
∑
j
p
(
x
i
,
z
j
(
i
)
;
θ
)
注:之后的公式中 z j ( i ) z_j^{(i)} zj(i)不在带上标 ( i ) ^{(i)} (i)的原因为:之后所有的 x i x_i xi发生都将所有的 z j z_j zj进行求和,因为任意 x i x_i xi的情况下 z j z_j zj总数是不变的,即使有变化,某种 z j z_j zj在 x i x_i xi情况下不可能发生那即认为 p ( x i , z j ( i ) ; θ ) = 0 p(x_i, z_j^{(i)} ; \theta)=0 p(xi,zj(i);θ)=0即可。
公式解析:1、联合概率分布不同样本之间相互独立,所以可以写成概率连乘,即为发生如下样本的概率 2、在例子中所叙述的进阶版思想合理利用所有z的可能不同的z不同的可能性相加最后的期望才是最后的似然可能性。
第一步是对极大似然函数取对数第二步是对每个样本实例的每个可能的类别z求联合分布概率之和。然而,直接求这个参数 θ \theta θ会比较困难,因为上式存在一个隐含随机变量(latent random variable) z z z。如果 z z z是个已知的数,那么使用极大似然估计来估算会很容易。在这种 z z z不确定的情形下,EM算法就派上用场了。
EM算法是常用的估计参数隐变量的利器。对于上述情况,由于存在隐含变量,不能直接最大化 l ( θ ) l(θ) l(θ),所以只能不断地建立 l l l的下界(E-step),再优化下界(M-step),依次迭代,直至算法收敛到局部最优解。这就是EM算法的核心思想,简单的归纳一下:
EM算法通过引入隐含变量,使用MLE(极大似然估计)进行迭代求解参数。通常引入隐含变量后会有两个参数,EM算法首先会固定其中的第一个参数,然后使用MLE计算第二个变量值;接着通过固定第二个变量,再使用MLE估测第一个变量值,依次迭代,直至收敛到局部最优解。
E-Step和M-Step。
- E-Step:通过observed data和现有模型估计参数估计值 missing data;
- M-Step:假设missing data已知的情况下,最大化似然函数。
是否会收敛:由于算法保证了每次迭代之后,似然函数都会增加,所以函数最终会收敛(最后有推到)。
6、EM推导
下面来推导EM算法:
对于每个实例 x i x_i xi,用 Q i Q_i Qi表示样本实例隐含变量 z z z的某种分布,且 Q i Q_i Qi满足条件 ∑ j Q i ( z j ) = 1 , Q i ( z j ) > = 0 , ∀ j \sum_{j}Q_i(z_j)=1,Q_i(z_j)>=0,\forall j ∑jQi(zj)=1,Qi(zj)>=0,∀j,如果 Q i Q_i Qi是连续性的,则 Q i Q_i Qi表示概率密度函数,需要将求和符号换成积分符号。
对于上面的式子,做如下变换:
∑
i
log
p
(
x
i
;
θ
)
=
∑
i
log
∑
j
p
(
x
i
,
z
j
;
θ
)
(
1
)
=
∑
i
log
∑
j
Q
i
(
z
j
)
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
(
2
)
≥
∑
i
∑
j
Q
i
(
z
j
)
log
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
(
3
)
上面三个式子中,式(1)是根据联合概率密度下某个变量的边缘密度函数求解的(这里把 z z z当作是随机变量)。对每一个样本i的所有可能类别 z z z求等式右边的联合概率密度函数和,也就得到等式左边为随机变量 x x x的边缘概率密度。由于对式(1)直接求导非常困难,所以将其分子分母都乘以一个相等的函数 Q i ( z j ) Q_i(z_j) Qi(zj),转换为式(2)。而在式(2)变为式(3)的过程,采用的是上面提到的Jensen不等式。分析过程如下:
首先,把(1)式中的log函数体看成是一个整体,由于log(x)的二阶导数为 − 1 x 2 −\frac{1}{x^2} −x21,小于0,为凹函数。所以使用Jensen不等式时,应用第二条准则: f ( E [ X ] ) > = E [ f ( x ) ] f(E[X])>=E[f(x)] f(E[X])>=E[f(x)]。
到这里,问题简化为如何求解随机变量的期望。还记得当年读大学的时候,概率论中的随机变量的期望计算方法么,不记得也没关系,下面这张图比较详细:

因此,结合上面的知识点,我们可以把(2)式当中的
Q
i
(
z
j
)
Q_i(z_j)
Qi(zj)看成相应的概率
p
z
j
p_{z_j}
pzj,把
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
\frac{p(x^i,z_j;\theta)}{Q_i(z_j)}
Qi(zj)p(xi,zj;θ)看作是
z
j
z_j
zj的函数
g
(
z
j
)
g(z_j)
g(zj),类似地,根据期望公式
E
(
x
)
=
∑
x
∗
p
(
x
)
E(x)=\sum{x∗p(x)}
E(x)=∑x∗p(x)可以得到:
E
(
z
)
=
∑
j
p
(
z
j
)
∗
g
(
z
j
)
=
∑
j
Q
i
(
z
j
)
[
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
]
E(z)=\sum_j{p(z_j)*g(z_j)}=\sum_j{Q_i({z_j})}[\frac{p(x^i,z_j;\theta)}{Q_i(z_j)}]
E(z)=j∑p(zj)∗g(zj)=j∑Qi(zj)[Qi(zj)p(xi,zj;θ)]
其实就是
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
\frac{p(x^i,z_j;\theta)}{Q_i(z_j)}
Qi(zj)p(xi,zj;θ)的期望,再根据凹函数对应的Jensen不等式性质:
f
(
E
z
j
∼
Q
i
[
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
]
)
≥
E
z
j
∼
Q
i
[
f
(
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
)
]
f(E_{z_j\sim Q_i}[\frac{p(x^i,z_j;\theta)}{Q_i(z_j)}])\geq E_{z_j\sim Q_i}[f(\frac{p(x^i,z_j;\theta)}{Q_i(z_j)})]
f(Ezj∼Qi[Qi(zj)p(xi,zj;θ)])≥Ezj∼Qi[f(Qi(zj)p(xi,zj;θ))]
因此便得到了公式(3)。OK,现在我们知道上面的式(2)和式(3)两个不等式可以写成:似然函数
L
(
θ
)
>
=
J
(
z
,
Q
)
L(\theta)>=J(z,Q)
L(θ)>=J(z,Q)的形式(
z
z
z为隐含变量),那么我们可以通过不断的最大化
J
J
J的下界,来使得
L
(
θ
)
L(\theta)
L(θ)不断提高,最终达到它的最大值。使用下图会比较形象:

这里来说说上图的内在含义:首先我们固定 θ \theta θ,调整 Q ( z ) Q(z) Q(z)使下界 J ( z , Q ) J(z,Q) J(z,Q)上升至与 L ( θ ) L(\theta) L(θ)在此点 θ \theta θ处相等(绿色曲线到蓝色曲线),然后固定 Q ( z ) Q(z) Q(z),调整 θ \theta θ使下界 J ( z , Q ) J(z,Q) J(z,Q)达到最大值( θ t \theta_t θt到 θ t + 1 \theta_{t+1} θt+1),然后再固定 θ \theta θ,调整Q(z)……直到收敛到似然函数 L ( θ ) L(\theta) L(θ)的最大值处的 θ \theta θ。
这里有两个问题:
- 什么时候下界 J ( z , Q ) J(z,Q) J(z,Q)与 L ( θ ) L(\theta) L(θ)在此点 θ \theta θ处相等?
- 为什么一定会收敛?
首先来解释下第一个问题(1.什么时候下界
J
(
z
,
Q
)
J(z,Q)
J(z,Q)与
L
(
θ
)
L(\theta)
L(θ)在此点
θ
\theta
θ处相等?)。在Jensen不等式中说到,当自变量
X
=
E
(
X
)
X=E(X)
X=E(X)时,即为常数的时候,等式成立。而在这里,为:
p
(
x
i
,
z
j
;
θ
)
Q
i
(
z
j
)
=
c
\frac{p(x_i,z_j;\theta)}{Q_i(z_j)}=c
Qi(zj)p(xi,zj;θ)=c
对该式做个变换,并对所有的
z
z
z求和,得到
∑
j
p
(
x
i
,
z
j
;
θ
)
=
∑
j
Q
i
(
z
j
)
c
\sum_jp(x_i,z_j;θ)=\sum_jQ_i(z_j)c
j∑p(xi,zj;θ)=j∑Qi(zj)c
因为前面提到
∑
j
Q
i
(
z
j
)
=
1
\sum_j Q_i(z_j)=1
∑jQi(zj)=1(概率之和为1),所以可以推导出:
∑
j
p
(
x
i
,
z
j
;
θ
)
=
c
\sum_jp(x_i,z_j;θ)=c
j∑p(xi,zj;θ)=c
因此也就可以得到下面的式子:
Q
i
(
z
j
)
=
p
(
x
i
,
z
j
;
θ
)
∑
j
p
(
x
i
,
z
j
;
θ
)
=
p
(
x
i
,
z
j
;
θ
)
p
(
x
i
;
θ
)
=
p
(
z
j
∣
x
i
;
θ
)
至此,我们推出了在固定参数 θ \theta θ后,使下界拉升的 Q ( z ) Q(z) Q(z)的计算公式就是后验概率(条件概率),一并解决了 Q ( z ) Q(z) Q(z)如何选择的问题。此步就是EM算法的E-step,目的是建立 L ( θ ) L(\theta) L(θ)的下界。接下来的M-step,目的是在给定 Q ( z ) Q(z) Q(z)后,调整 θ \theta θ,从而极大化 L ( θ ) L(θ) L(θ)的下界 J J J(在固定 Q ( z ) Q(z) Q(z)后,下界还可以调整的更大)。到此,可以说是完美的展现了EM算法的E-step & M-step,完整的流程如下:
第一步,初始化分布参数
θ
θ
θ;
第二步,重复E-step 和 M-step直到收敛:
- E步骤:根据参数的初始值或上一次迭代的模型参数来计算出的隐性变量的后验概率(条件概率),其实就是隐性变量的期望值。作为隐藏变量的现有估计值:
Q i ( z j ) = p ( z j ∣ x i ; θ ) Q_i(z_j)=p(z_j|x_i;\theta) Qi(zj)=p(zj∣xi;θ)
- M步骤:最大化似然函数从而获得新的参数值:
θ = a r g max θ ∑ i ∑ j Q i ( z j ) log p ( x i , z j ; θ ) Q i ( z j ) \theta = arg\max_\theta{\sum_i\sum_{j}{Q_i (z_j)\log{\frac{p(x_i,z_j;\theta)}{Q_i(z_j)}}}} θ=argθmaxi∑j∑Qi(zj)logQi(zj)p(xi,zj;θ)
通过不断的迭代,然后就可以得到使似然函数 L ( θ ) L(\theta) L(θ)最大化的参数 θ \theta θ了。
上面多次说到直至函数收敛,那么该怎么确保EM收敛呢?(②为什么一定会收敛?),下面进入证明阶段.
假定
θ
(
t
)
θ^{(t)}
θ(t)和
θ
(
t
+
1
)
θ^{(t+1)}
θ(t+1)是EM第t次和t+1次迭代后的结果。如果我们证明了
l
(
θ
(
t
)
)
<
=
l
(
θ
(
t
+
1
)
)
l(\theta^{(t)})<=l(\theta^{(t+1)})
l(θ(t))<=l(θ(t+1)),也就是说极大似然估计单调增加,那么最终我们就会得到极大似然估计的最大值。下面来证明,选定
θ
(
t
)
\theta(t)
θ(t)之后,我们得到E步:
Q
i
(
t
)
(
z
j
)
=
p
(
z
j
∣
x
i
;
θ
(
t
)
)
Q_i^{(t)}(z_j)=p(z_j|x^{i};\theta^{(t)})
Qi(t)(zj)=p(zj∣xi;θ(t))
这一步保证了在给定
θ
(
t
)
\theta(t)
θ(t)时,Jensen不等式中的等式成立,也就是
l
(
θ
(
t
)
)
=
∑
i
∑
j
Q
i
(
t
)
(
z
j
)
log
p
(
x
i
,
z
j
;
θ
(
t
)
)
Q
i
(
z
j
)
l(\theta^{(t)}) = {\sum_i\sum_{j}{Q_i^{(t)} (z_j)\log{\frac{p(x_i,z_j;\theta^{(t)})}{Q_i(z_j)}}}}
l(θ(t))=i∑j∑Qi(t)(zj)logQi(zj)p(xi,zj;θ(t))
然后进行M步,固定
Q
i
(
t
)
z
j
Q_i^{(t)}{z_j}
Qi(t)zj,并将
θ
(
t
)
\theta^{(t)}
θ(t)试作变量,对上面的式子求导,得到
θ
(
t
+
1
)
θ^{(t+1)}
θ(t+1),这样经过一些推导会有以下式子成立:
l
(
θ
(
t
+
1
)
)
≥
∑
i
∑
j
Q
i
(
t
)
(
z
j
)
log
p
(
x
i
,
z
j
;
θ
(
t
+
1
)
)
Q
i
(
t
)
(
z
j
)
(
4
)
≥
∑
i
∑
j
Q
i
(
t
)
(
z
j
)
log
p
(
x
i
,
z
j
;
θ
(
t
)
)
Q
i
(
t
)
(
z
j
)
(
5
)
=
l
(
θ
(
t
)
)
(
6
)
在公式(4)中,得到
θ
(
t
+
1
)
\theta^{(t+1)}
θ(t+1),只是最大化
l
(
θ
(
t
)
)
l(\theta^{(t)})
l(θ(t)),也就是
l
(
θ
(
t
+
1
)
)
l(\theta^{(t+1)})
l(θ(t+1))的下界,并没有使等式成立,等式成立只有在固定
θ
θ
θ,并按E步得到
Q
i
Q_i
Qi时才能成立。
这样就证明了 l ( θ ) l(\theta) l(θ)会单调增加。如果要判断收敛情况,可以这样来做:一种收敛方法是 l ( θ ) l(\theta) l(θ)不再变化,还有一种就是变化幅度很小,即根据 l ( θ ) ( t + 1 ) − l ( θ ) ( t ) l(\theta)^{(t+1)}−l(θ)^{(t)} l(θ)(t+1)−l(θ)(t)的值来决定。
EM算法类似于坐标上生法(coordinate ascent):E步:固定 θ \theta θ,优化Q;M步:固定 Q Q Q,优化 θ \theta θ;交替将极值推向最大。
7、应用
8、参考文献
http://cs229.stanford.edu/notes/cs229-notes8.pdf



{kind=link}