
- 1在linux中默认使用hdmi_linux c编程hdmi
- 2开发者如何通过DevEco Studio编译和上传软件包_deveco studio3.1 编译apk
- 3docker 修改tag和image名称_修改images的tag
- 42022年招投标,最加分的资质证书排行榜!_投标加分证书有哪些
- 5轻松手撕 HashMap_手撕hashmap
- 6GitHub上下载源代码的方法
- 7android studio 无法进行真机调试,连接不到手机的其中一个原因_no android devices detected.
- 8启动注销服务器,window server 2012系统服务器桌面重启关机注销的几种方法
- 9CodeWhisperer安装教导--一步到位!以及本人使用Whisperer的初体验。
- 10condarc(conda 配置文件)_.condarc 默认
LLM大模型x知识图谱2024最新SOTA方案【附开源代码】
赞
踩
大模型LLM与知识图谱KG的结合可以充分发挥两者的优势,例如LLMs的通用知识和语言处理能力,以及KGs的结构化和准确性。这种结合不仅能够提升模型的知识处理能力,还能够在多个层面上优化模型的性能,更好地解决各种现实世界的问题,例如搜索引擎、推荐系统和AI助手等。
今天我就盘点了大模型结合知识图谱最新的35个技术方案,2024年的已经帮同学们分析好了方法和创新点,部分开源代码也都整理了,剩余技术方案和项目代码需要的同学看文末
Evaluating Large Language Models in Semantic Parsing for Conversational Question Answering over Knowledge Graphs
「方法:」通过对不同大小和训练目标的LLMs生成的输出进行系统比较,重点关注优化于对话交互的模型。通过广泛的基准数据集,作者评估了模型在从对话中生成SPARQL查询方面的性能,并讨论了它们的个体能力和限制。作者的贡献包括评估四个LLMs的基准研究,利用自动评估和人工评估来识别生成的图查询中的八种常见错误类型,并详细讨论了用于改善模型性能的提示和微调策略。
「创新点:」
-
本文评估了未经过专门训练的大型语言模型在对话语义解析任务上的性能,通过一系列实验比较了不同大小的模型和不同提示技术的性能,并识别了生成输出中的常见问题类型。
-
与之前的模型不同,本文采用了上下文学习和后处理的方法,实现了端到端的结构化查询生成。本文旨在研究大型语言模型在理解对话、解决词汇问题和生成具有正确语法的SPARQL查询方面的性能。
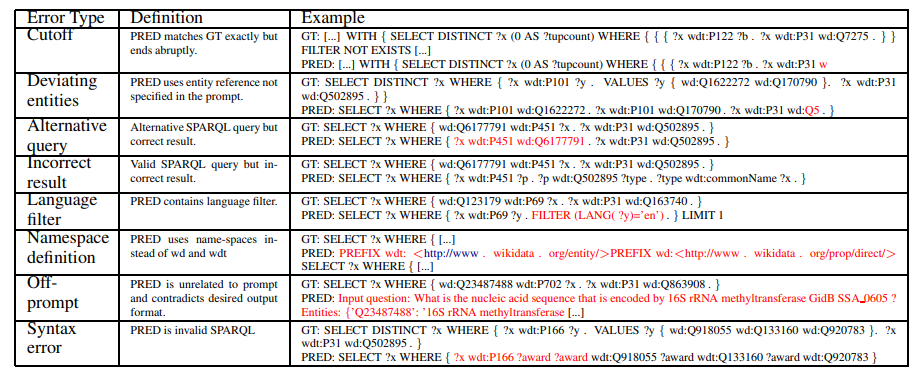
keqing: knowledge-based question answering is a nature chain-of-thought mentor of LLM
「方法:」作者提出了Keqing框架,该框架的主要内容是通过预定义的模板将复杂问题分解为子问题,并在知识图谱上检索候选实体,然后通过推理回答子问题,并生成带有推理路径的回答。实验结果表明,Keqing在知识图谱问答数据集上取得了竞争性的性能,并且能够解释每个问题的回答逻辑。
「创新点:」
-
提出了问题分解模块,将复杂的用户问题根据预定义的问题模板分解为多个子问题。这种设计的思想是,文本形式的问题分解逻辑相对于SQL形式更容易被大型语言模型(LLMs)捕捉到。每个真实世界的问题都可能有多个解决方案(推理路径)来达到潜在的答案候选,而足够的答案候选可以为后续的答案推理过程提供容错能力。
-
提出了候选推理模块,根据分解的子问题的依赖关系,选择正确的实体来回答当前问题,并迭代地得出最终答案。通过问题分解和知识检索,得到了答案候选,然后利用候选推理模块选择正确的实体,并根据子问题的依赖关系逐步得出最终答案。
-
提出了基于知识图谱的检索模块,用于收集相关的三元组,为LLMs提供高质量的上下文信息,以完成知识库问答任务。与基于嵌入的语料库检索方法不同,该方法可以精确地提供高质量的上下文信息,避免了重复或无关的内容对LLMs生成的响应质量的影响。
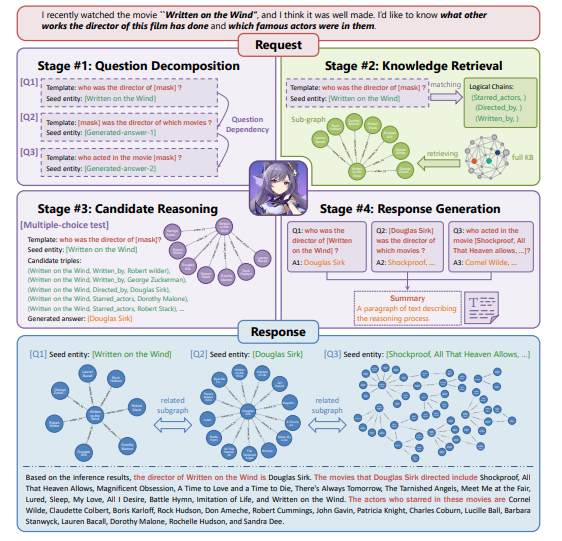
Quartet Logic: A Four-Step Reasoning (QLFR) framework for advancing Short Text Classification
「方法:」作者引入了Quartet Logic: A Four-Step Reasoning(QLFR)框架,该框架将STC任务分解为四个步骤:关键概念识别、常识知识检索、文本重写和分类。通过引导CoT,该框架有效地解决了STC中的语义和句法复杂性问题。作者还提出了CoT-Driven Multi-task learning(QLFR-CML)方法,通过从LLMs中转移任务相关的知识来增强较小模型的性能。
「创新点:」
-
引入了Quartet Logic: A Four-Step Reasoning (QLFR)框架,这是一种基于CoT提示的多步推理方法,用于改进LLM在STC任务中的性能。该框架通过四个步骤的推理来引发内在的知识和能力,然后确定预测的标签。
-
提出了Syntactic and Semantic Enrichment CoT (SSE-CoT)的CoT方法,提供了一个四步推理的方法,用于提高输入文本的清晰度和上下文,并丰富其解释深度。

TechGPT-2.0: A large language model project to solve the task of knowledge graph construction.
「方法:」研究重点是评估具有减少参数的大型模型在知识图谱构建任务中的性能,旨在为中国开源社区提供一个能够构建知识图谱并保留Chat模型整体能力的实用模型。所有模型都是从LLAMA2派生而来,首先在中文上进行预训练,然后使用大量指令进行微调。该报告还介绍了在TechGPT-2.0项目开发过程中遇到的挑战和得出的经验。此外,报告还讨论了模型训练中遇到的问题以及解决长文本挑战的技术解决方案。
「创新点:」
-
作者提出了QLoRA fine-tuning的方法,通过使用位置插值来解决处理长文本时遇到的问题。
-
作者开发了两个7B-scale模型,用于知识图谱构建任务,并针对长文本问题设计了QLoRA权重。
-
作者发现当前小规模大模型在知识图谱构建任务中表现不佳,旨在填补中国开源社区在该领域的空白。
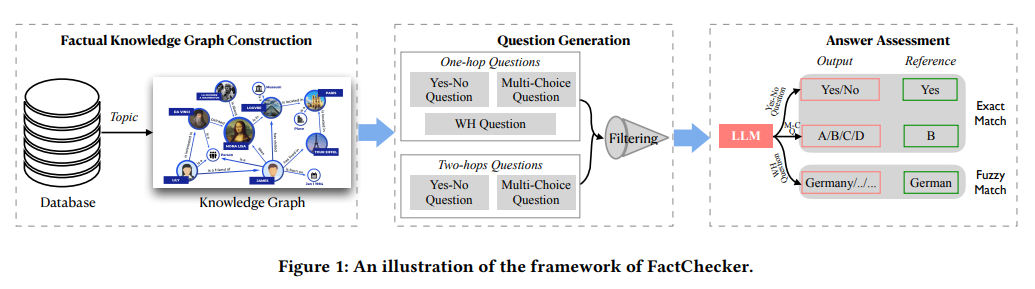
The Earth is Flat? Unveiling Factual Errors in Large Language Models
「方法:」作者设计并实现了FactChecker,这是第一个专门用于系统性发现LLM中事实错误的自动化框架。FactChecker利用结构化的知识图谱自动生成各种主题和关系的问题,通过对LLM的回答进行评估,成功地检测出了大量的事实错误。
「创新点:」
-
FactChecker是第一个自动化框架,用于系统地揭示LLMs中的事实错误。
-
FactChecker可以有效地发现商业和研究LLMs中的大量事实错误。
-
FactChecker可以通过In-Context Learning(ICL)和模型微调方法显著提高LLMs的事实准确性。
-
FactChecker的测试结果表明,通过ICL方法,事实错误的平均改进率为6.5%,通过模型微调方法,事实错误的显著改进率为33.2%。
Chain of History: Learning and Forecasting with LLMs for Temporal Knowledge Graph Completion
「方法:」本文提出了一种新颖的方法,将时间链接预测视为历史事件链中的事件生成任务,以提高语言模型的推理能力。研究通过有效的微调方法,使语言模型适应特定的图文信息和时间线模式。同时,引入基于结构的历史数据增强和逆向知识的整合,以增强语言模型对结构信息的感知能力。
「创新点:」
-
作者通过对三种商业LLM模型在TKGC任务上的测试,探索了多任务指令微调和人类反馈强化学习(RLHF)后的性能差异。
-
作者将TKGC任务建模为在历史事实链上的事件生成过程,并利用LLM的微调来增强其生成时间事件的能力。
-
作者通过结构化的历史数据增强和引入逆向四元组来解决逆转问题,提高了LLM感知图结构的能力。
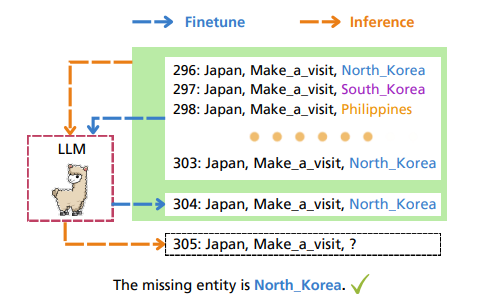
Conversational Question Answering with Reformulations over Knowledge Graph
「方法:」作者提出了一种创造性地将问题改写和强化学习结合在知识图谱上的模型CoRnNet,以实现准确的多轮对话式问答。CoRnNet利用师生蒸馏方法和强化学习从知识图谱中找到答案。实验结果表明,CoRnNet在各种基准数据集上超过了现有方法。
「创新点:」
-
利用现有的LLMs(GPT2和Bart)进行微调,生成高质量的改写,以人类编写的改写作为基准。这一方法提高了ConvQA的性能。
-
提出了一种师生架构,进一步提高了ConvQA的性能。CoRnNet直接使用训练数据中的人类编写改写来训练师傅模型,并使用LLMs生成的改写来间接训练学生模型,以模仿师傅模型的输出,从而接近人类水平的性能。
-
提出了一种基于RL的模型,通过从策略网络中采样动作来引导遍历知识图谱(KG)并定位答案。这一方法在定位答案方面表现出了有效性,并且优于现有的对话式问答基线模型。

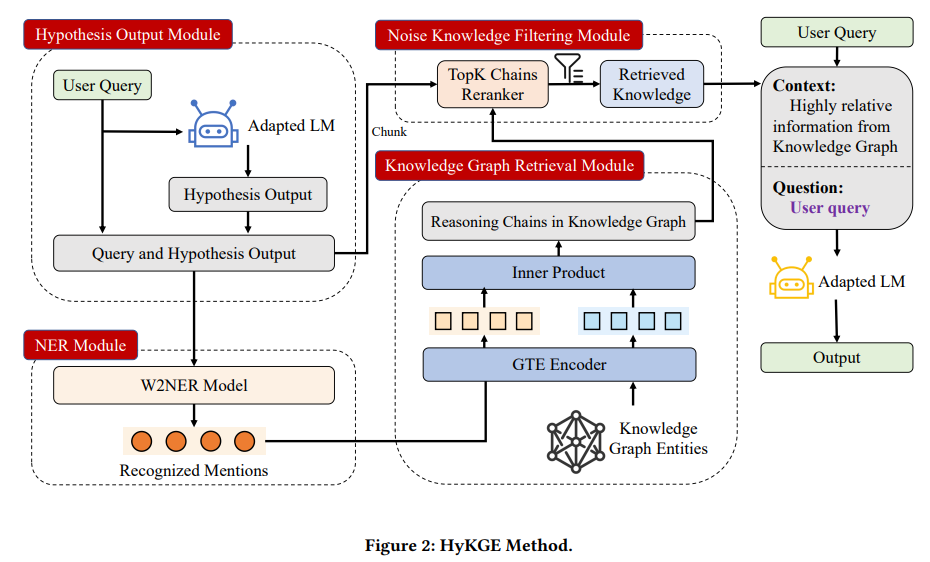
Think and Retrieval: A Hypothesis Knowledge Graph Enhanced Medical Large Language Models
「方法:」本文提出了HyKGE,一种通过整合LLMs和知识图谱来增强医学大型语言模型的假设知识图谱。作者还提出了一个片段重新排序模块,通过分而治之的思想,进一步增强用户查询和外部知识推理路径之间的对齐。通过案例研究,展示了HyKGE模型在使用GPT-3.5 Turbo时的有效性。
「创新点:」
-
我们提出了HyKGE,这是一种融合了大型语言模型和知识图谱的假设知识图增强医学模型,通过整合LLMs和知识图谱,HyKGE在解决准确性和可解释性挑战方面展现出卓越的性能。
-
我们提出了一个片段重新排序模块,通过分而治之的思想,对检索到的知识进行重新排列和整合,进一步增强用户查询和外部知识推理路径之间的对齐。
-
与以往的方法相比,我们让LLMs首先处理用户查询,通过LLMs的理解,获得与用户查询相关的更多医学知识。我们从"H O"和"Q"中提取医学实体。
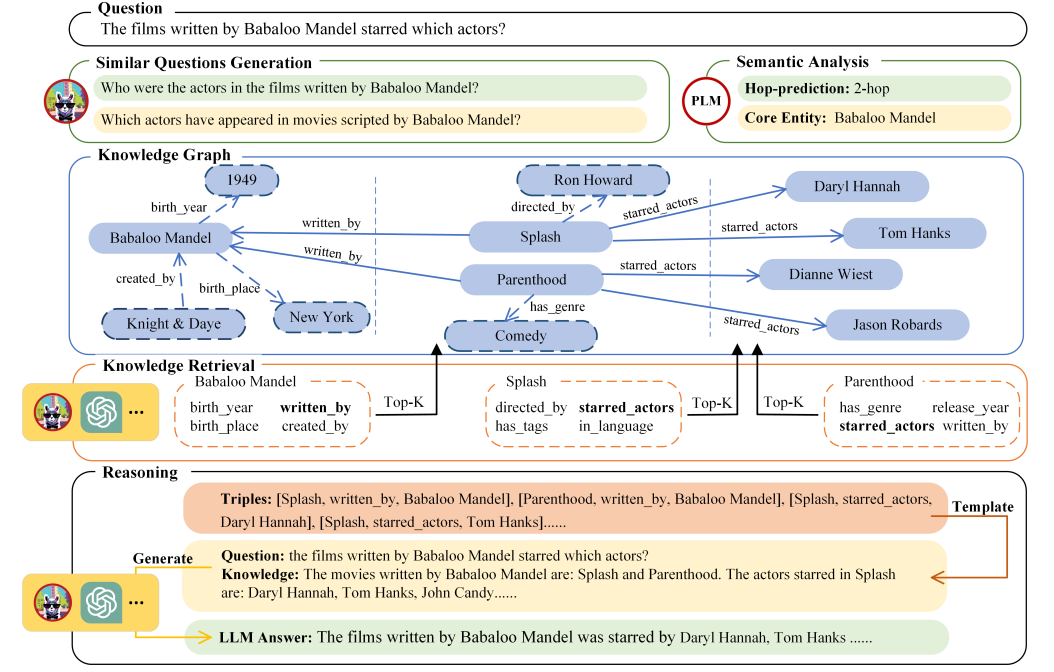
KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph
「方法:」本文研究了LLM中的知识限制挑战,并介绍了一个名为KnowledgeNavigator的框架,以提高LLM在知识图谱上的推理和问答能力。KnowledgeNavigator包括三个阶段:问题分析、知识检索和推理。在问题分析阶段,KnowledgeNavigator首先对问题进行预分析并生成变体,以辅助推理。然后,在LLM的指导下,它迭代地检索和过滤知识图谱中的候选实体和关系,提取相关的外部知识。最后,这些知识被转化为有效的提示,以提高LLM在知识密集型任务上的性能。
「创新点:」
-
知识导航器(KnowledgeNavigator):这是一个新颖的框架,旨在通过从知识图谱中高效准确地检索外部知识来改进LLM的推理能力。知识导航器通过细化问题所隐含的约束条件来引导推理过程,并通过迭代地结合LLM的见解和问题的要求来选择性地从知识图谱中收集支持信息。最后,知识导航器将这些结构化信息准备成LLM友好的提示,增强其推理能力。
-
问题分析:问题分析阶段通过预先分析给定的问题来增强和限制推理过程,从而解决了KGQA任务中的多跳推理问题。这种方法有助于提高检索效率和准确性。
-
案例研究:作者通过一个案例研究展示了知识导航器在KGQA任务中的应用。知识导航器首先基于PLM预测从核心实体“Babaloo Mandel”开始的推理跳数,并为目标问题生成2个类似的问题,以供LLM使用。
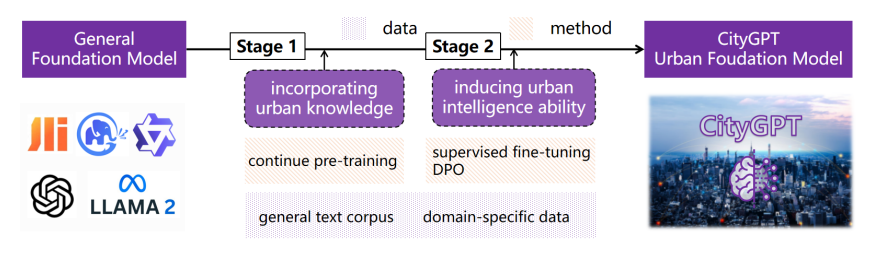
Urban Generative Intelligence (UGI): A Foundational Platform for Agents in Embodied City Environment
「方法:」本文介绍了城市生成智能(UGI)系统的架构和方法。UGI系统旨在利用大型语言模型驱动的智能代理来模拟城市的复杂动态,并支持决策等各种应用。该系统的关键组件包括开放数字基础设施、城市模拟器、城市知识图谱和各种数据流。
「创新点:」
-
建立多学科协作的UGI开发者社区,使得大数据、城市模拟、大型语言模型等领域的研究人员和开发人员能够共享数据集、数据处理方法和数据生成方法,为UGI提供高质量的数据流。
-
引入大型语言模型(LLMs)来增强城市智能代理的能力。通过将多源城市数据训练到基于城市的大型语言模型CityGPT中,UGI能够创建具有人类级智能的具体代理,这些代理能够解决各种城市挑战,并在社会、经济和环境等方面提供洞察和解决方案。
-
UGI平台提供了一个开放的数字基础设施,集成了城市模拟器、城市知识图谱和各种数据流。这个基础设施不仅能够收集大量的空间-时间数据,模拟城市系统的复杂交互,还能够提供标准的语言接口,方便大型语言模型和生成代理的插件。
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

