
热门标签
热门文章
- 1使用vim编写golang_vim中编译go语言文件的命令
- 2深度学习基础-基于Numpy的前馈神经网络(FFN)的构建和反向传播训练
- 32018蓝桥杯国二感想_蓝桥杯国二难吗
- 4SpringBoot整合Druid,开启druid监控平台_druid控制台在哪里看
- 5ubuntu安装配置samba(适合多数老版本)_ubuntu 多版本samba
- 6【yolov5小技巧(1)】---可视化并统计目标检测中的TP、FP、FN
- 7自然语言处理文本分析_通过自然语言处理释放文本分析的力量
- 8uniapp---安卓真机调试提示检测不到手机【解决办法】_uniapp 没有检测到设备
- 9什么是微服务体系架构?读完这篇文章你就明白了_微服务架构是什么
- 10周报(20240218)_mamba-unet
当前位置: article > 正文
毕设日记(基于微博的大学生情感分析系统)——python学习之正则表达式_python微博评论情感分析能做毕设嘛
作者:笔触狂放9 | 2024-04-04 15:18:12
赞
踩
python微博评论情感分析能做毕设嘛
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
今天继续学习了python的基础知识,感觉毕设拖拖拉拉的进度好慢哦
一、正则表达式是什么?
就好像我们当时学计算机基础时学的通配符,(什么?代表一个字符,*代表多个字符)。
主要就用来测试字符串内的模式,替换文本,提取子字符。
二、使用步骤
1.引入库
有好几种引入的方式,但最推荐import re ,因为这样子引入后以后再使用正则表达式都要(re.巴拉巴拉 )这样子可能看起来麻烦一点点,但是在实际开发大工程的时候可以方便我们分清哪个是正则表达式,不容易混。

2.常用方法与符号


.是一个占位符 几个点就表示几个符号

*表示匹配0次或者无限次

这些里面最常用的符号就是
① .* ( * 当成是一个大肚子 .*就是一个大胖叽吃得多,因此.*是贪心算法)
② .*? (?当成是一个奶瓶 .*?就是一个婴儿少食多餐,因此是非贪心算法)
import re
code='dsadxxQxxdewfcxxXxxcdwsfxxTxxcds'
#.*使用举例
a=re.findall('xx.*xx',code)
#i*?使用举例
b=re.findall('xx.*?xx',code)
#使用括号和不使用括号 使用括号只会输出括号中的字符
c=re.findall('xx(.*?)xx',code)
print(a)
print(b)
print(c)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行结果
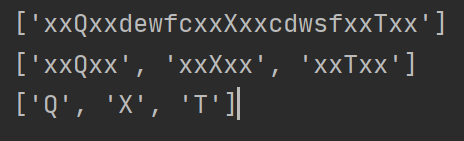
如果code这个字符串里含有换行,情况就不同
如
code='''dsadxxQ
xxdewfcxxXxxcdwsfxxTxxcds'''
- 1
- 2
再执行上面程序得
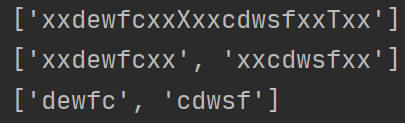
可知在第一行没有找的匹配的xx.xx时 ,会从第二行重新开始寻找
因此:✨注意 . 号可以匹配任何字符但换行符除外
如果想要.匹配换行符的话 要使用re.S
代码如下
#.*使用举例
a=re.findall('xx.*xx',code,re.S)
#i*?使用举例
b=re.findall('xx.*?xx',code,re.S)
#使用括号和不使用括号 使用括号只会输出括号中的字符
c=re.findall('xx(.*?)xx',code,re.S)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果如下
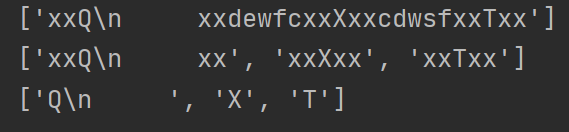
下面来看看search的用法
d=re.search('xx(.*?)xxdewfcxx(.*?)xx',code,re.S).group(1)
- 1
运行结果

如果是 group(2),运行结果是 T
如果是 group(3),运行会报错
最后是sub的用法啦
#sub使用举例
e=re.sub('xx(.*?)xx','love',code)#这里我把code改成了没有换行的状态,现在还不知道有换行怎么操作
- 1
- 2
运行结果:

啊等等还没完
匹配纯数字

三、注意
常用:

技巧:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/359456
推荐阅读
相关标签

