
- 1树莓派4B-Python-使用PCA9685控制舵机云台+跟随人脸转动_树莓派4b pc9685 控制舵机
- 2关于 Llama 2 的一切资源,我们都帮你整理好了
- 3可视化 | (二)视觉编码、图形感知及颜色计算_可视化编码的类型有哪些
- 4SSM框架学习——MyBatis_mybatis框架在ssm框架中负责什么和什么之间的转换
- 5瑞吉&苍穹外卖如何拓展?已经经过不同公司多轮面试。项目中会问到哪些问题?以及问题如何解决?
- 62021-01-14_english bruce lin博客
- 7FlaUI操作微信发消息,报FlaUI.Core.Exceptions.NoClickablePointException异常_flaui.core 微信 公众号
- 8「认识AI:人工智能如何赋能商业」【19】采用sigmoid神经元、添加偏置项
- 9《人工智能》课程作业2_公式集总可以合一
- 10ai聊天助手怎么用?分享在线ai聊天工具用法_ai助手在线使用
数据标注是什么?
赞
踩
关于数据标注您需要了解的一切——专家解答:澳鹏产品管理总监Meeta Dash
人工智能(AI)的质量取决于对其予以训练所使用的数据。由于训练数据的质量和数量直接决定AI算法的成败,因此,对于一个AI项目,平均80%的时间均耗费于训练数据的争论(包括数据标注)上也就不足为奇。
AI模型的构建将从大量未标注数据开始。标注数据是构建AI模型的数据准备和预处理工作不可或缺的一环。但是,在机器学习(ML)背景下,究竟什么是数据标注?数据标注即对数据样本进行检测和标记的过程,对于在ML中进行监督式学习尤为重要。标注数据输入和输出,以丰富AI模型的未来学习时,即出现监督式学习。
整个数据标注工作流程通常包括数据标注、打标签、分类、调整和处理。此外,您还需要建立一套综合的流程来将未标注的数据转换为训练所需的数据,让AI模型学习识别方式并产生预期的结果。
例如,面部识别模型的训练数据可能需要用特定的特征(如眼睛、鼻子和嘴巴)对人脸图像进行标注。另外,如果模型需要执行情绪分析(在需要检测某人的语气是否具有讽刺性的情况下),则需要为音频文件添加各种语气变化的标签。
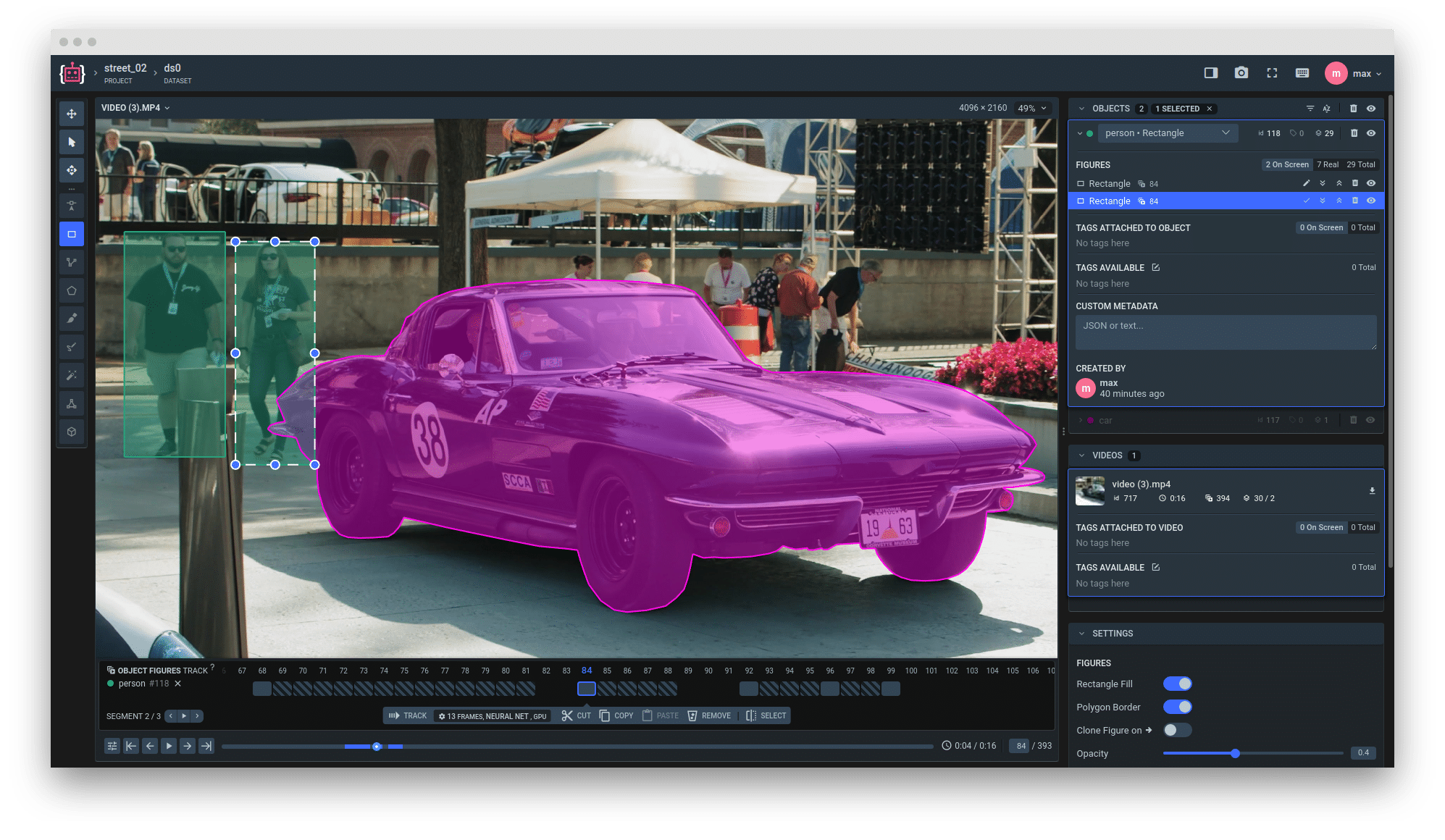
如何获取标注过的数据
数据标签必须高度准确,以便教授模型做出正确的预测。数据标注过程需要若干步骤确保质量和准确性。
数据标注方法
为组织选择适当的数据标注方法非常重要,因为这一环节所需的时间和资源最多。数据标注可以使用许多方法(或方法的组合),其中包括:
- 驻场:使用现有的人员和资源。虽然这种方法能够更好地控制结果,但却可能耗时多,代价高昂,如果需要聘用和从头开始培训标注人员,情况更是如此。
- 外包:聘用临时的自由职业者标注数据。您将能够评估这些承包商的技能,但对工作流组织的控制会减少。
- 众包:您可以选择使用可信的第三方数据合作伙伴来众包您的数据标注需求,如果您缺少内部资源,这将是一个理想的选择。在整个模型构建过程中,数据合作伙伴可以提供专业知识,并可以提供能够快速处理大量数据的标注员。对于那些期待大规模部署AI的公司而言,众包是理想之选。
- 通过机器:数据标注也可通过机器完成。应考虑使用ML辅助数据标注,特别是在必须大规模准备训练数据的情况下。ML还用于需要数据分类的自动化业务流程。
组织要采取的方法将取决于所需解决问题的复杂性、员工的技能水平和预算。
质量保证
质量保证(QA)是数据标注过程中经常被忽视但至关重要的组成部分。如果数据准备工作由内部管理,就一定要进行质量检查。如果与数据合作伙伴一起合作,则他们已具备QA流程。
QA为何如此重要?数据标签必须满足许多特性;它们必须信息丰富、独特并且独立。标签还应反映准确性的真实水平。例如,在为自动驾驶汽车标记图像时,必须在图像中正确标注所有行人、路标和其他车辆,以便让模型成功运作。
训练和测试
数据经标注用于训练数据并通过QA后,就可以使用其训练AI模型了。然后,在一组新的未标注数据上对其进行测试,看看所做预测是否准确。
根据模型的需要,您对准确性会有不同的期望。如果模型用于处理放射学图像以识别感染,其准确性要求就可能需要高于用于识别在线购物体验中产品的模型,因为这可能生死攸关。相应地设置信任阈值。
利用“人机协同”
数据测试过程中,应让人员参与其中,以提供地面实况监控。利用人机协同,您能够:检查模型是否做出正确预测、确定训练数据差距、向模型提供反馈,以及在模型做出不太可信或不正确预测时按需对其进行再训练。
规模化
创建可扩展的灵活的数据标注流程。随着需求和用例的发展,您会期望迭代这些过程。
澳鹏数据标注专家:Meeta Dash
澳鹏依靠我们的专家团队来帮助提供最好的数据标注平台。Meeta Dash是我们的产品管理总监、福布斯技术委员会撰稿人,最近获得VentureBeat的AI导师奖,她帮助确保澳鹏数据标注平台在提供准确的数据标注服务方面超乎行业标准。她对数据标注的三大见解包括;
- 成功的团队通常从用例、目标角色和成功指标的清晰定义开始。这有助于识别训练数据的需求,确保覆盖不同场景,并减轻由于缺乏不同数据集而产生的潜在偏差。此外,在数据标注过程中纳入不同的标注者,能够帮助避免标注过程中的偏见。
- 数据偏差很常见,并超出您的想象。现实世界中,模型所看到的数据每天都在变化,而在一个月前训练的模型可能并不会按照您的预期执行。因此,建立一个可扩展的、自动化的训练数据管道,就要不断地用新信息训练模型,这点至关重要。
- 安全和隐私方面的问题应该直接处理,而不是事后补救。尽可能避免训练最佳模型不需要的敏感数据。使用安全的、企业级的数据标注平台,在使用敏感数据进行数据标注项目时,请选择受过处理此类数据训练的安全标注员。

