
- 1手撕 HashMap_手撕hashmap
- 2RAM、ROM、FLASH的存储原理及区别
- 3Android源码编译完重启电脑后emulator命令报错_build完android11源码启动emulator崩溃
- 4python|随机森林(RandomForestClassifier)_python randomforestclassifier
- 5Android布局之屏幕自适应_android自定义布局如何能不随系统显示大小而变化
- 6动态内存管理----calloc和realloc
- 7Python类的定义和使用_python 类的定义
- 8Mac office 2011 打开word有中文乱码问题解决_mac打开word文档缺字
- 9深度复盘GitHub发展史:如何在短短10年内改变了人们的编程方式?_github2008年
- 10YOLOv5的详细使用教程,以及使用yolov5训练自己的数据集_yolo5训练集
深度学习常用库
赞
踩
深度学习常用Python库
#####简介·
-
Numpy是python科学计算库的基础。包含了强大的N维数组对象和向量运算
-
Panddas是建立在Numpy基础上的高效数据分析库,是Python的重要数据分析库
-
Matplotlib是一个主要用于绘制二维图形的Python库。用途:绘画、可视化
-
PIL库是一个具有强大数据处理能力的第三方库。用途:图像处理
- 数组创建
1. 使用array函数,它接受一切序列型的对象,然后产生一个新的含有传入数组的numpy数组。其中嵌套数组将会被转化为一个多维数组
```
import numpy as np
#将列表转换为数组
array = np.array([[1,2,3],
[4,5,6]])
print(array)
```
2. 使用arange函数
```
import numpy as np
array = np.arange(3,8,2)
print(arange) #结果是[3 5 7]
```
3. 使用ones函数
```
arr = np.ones([2,3],dtype=np.int64)
```
- 数组的参数
1. array.ndim:数组维度
2. array.shape:数组形状
3. array.size:元素个数
4. array.dtype:数组元素类型
- 重新定义数组形状
array1 = np.arange(6).reshape([2,3])
print(array1)
array2 = np.array([[1,2,3],[4,5,6]],dtype=np.int64).reshape([3,2])
print(array2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 数组计算
数组很重要,因为它可以使我们不用编写循环即可对数据执行批量运算。这通常叫做矢量化(vectorization)。
大小相等的数组之间的任何算术运算都会将运算应用到元素级。同样,数组与标量的算术运算也会将那个标量值传播到各个元素.
- 基础运算
1. +
2. -
3. *
4. /
5. **:求次方
6. 以上都是应用到元素级别
- 矩阵乘法
1. np.dot(arr1,arr2)
- 其他运算
1. np.sum(arr3,axis=1):
1. axis=1时,对每一行求和
2. axis=0时,对每一列求和
2. np.max(array):求最大值
3. np.min(array):求最小值
4. np.mean(array):求中位数
- 数组索引与切片
1. 与matlab基本一致
pandas是python第三方库,提供高性能易用数据类型和分析工具。
pandas基于numpy实现,常与numpy和matplotlib一同使用
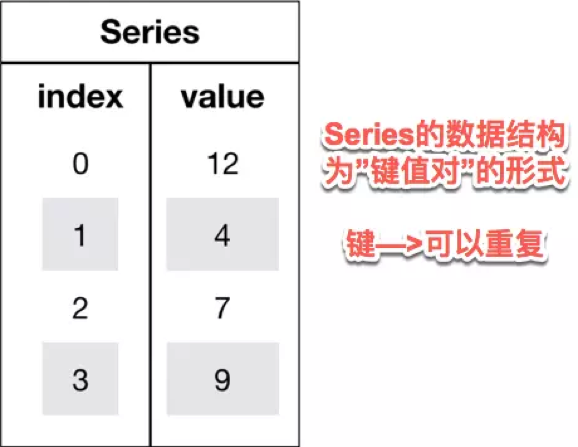
- Series
Series是一种类似于一维数组的对象,它由一维数组(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成.
可理解为带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。
import pandas as pd import numpy as np s = pd.Series(['a','b','c','d','e']) print(s) /* 结果是: 0 a 1 b 2 c 3 d 4 e dtype: object */

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- Series可以使用index设置索引列表。与字典不同的是,Series允许索引重复
#与字典不同的是:Series允许索引重复 import pandas as pd s = pd.Series(['a','b','c','d','e'],index=[100,200,100,400,500]) print(s) print(s.index) /* 100 a 200 b 100 c 400 d 500 e dtype: object Int64Index([100, 200, 100, 400, 500], dtype='int64') */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- Series可以用字典实例化
d = {'b': 1, 'a': 0, 'c': 2}
pd.Series(d)
- 1
- 2
- 3
- 4
- 5
- 可以通过Series的values和index属性获取其数组表示形式和索引对象
print(s.values)
print(s.index)
- 1
- 2
- 3
- 4
- 5
- 与普通numpy数组相比,可以通过索引的方式选取Series中的单个或一组值
print(s)
print(s[100])
print(s[[400, 500]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 对应元素运算
import pandas as pd s = pd.Series(np.array([1,2,3,4,5]), index=['a', 'a', 'c', 'd', 'e']) print(s) #对应元素求和 print(s+s) #对应元素乘 print(s*3) /* a 1 a 2 c 3 d 4 e 5 dtype: int64 a 2 a 4 c 6 d 8 e 10 dtype: int64 a 3 a 6 c 9 d 12 e 15 dtype: int64 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- Series中最重要的一个功能是:它会在算术运算中自动对齐不同索引的数据
Series 和多维数组的主要区别在于, Series 之间的操作会自动基于标签对齐数据。因此,不用顾及执行计算操作的 Series 是否有相同的标签。
obj1 = pd.Series({"Ohio": 35000, "Oregon": 16000, "Texas": 71000, "Utah": 5000}) obj2 = pd.Series({"California": np.nan, "Ohio": 35000, "Oregon": 16000, "Texas": 71000}) print(obj1 + obj2) /* California NaN Ohio 70000.0 Oregon 32000.0 Texas 142000.0 Utah NaN dtype: float64 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
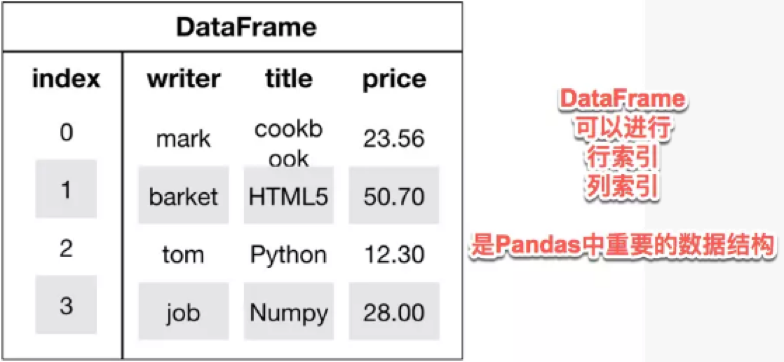
- DataFrame
DataFrame是一个表格型的数据结构,类似于Excel或sql表
它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
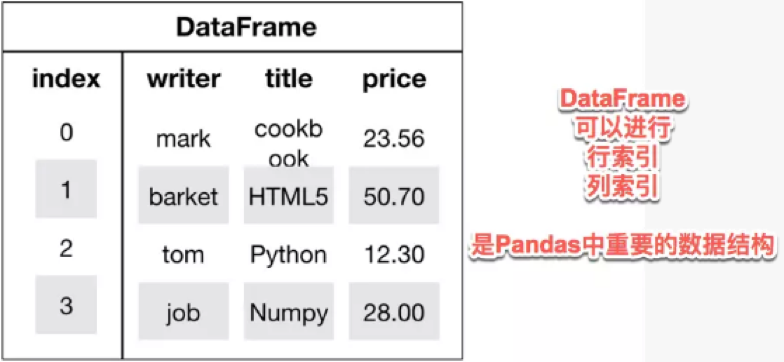
- 用多维数组字典、列表字典生成 DataFrame
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9]} frame = pd.DataFrame(data) print(frame) /* state year pop 0 Ohio 2000 1.5 1 Ohio 2001 1.7 2 Ohio 2002 3.6 3 Nevada 2001 2.4 4 Nevada 2002 2.9 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 如果指定了列顺序,则DataFrame的列就会按照指定顺序进行排列
frame1 = pd.DataFrame(data, columns=['year', 'state', 'pop']) print(frame1) /* year state pop 0 2000 Ohio 1.5 1 2001 Ohio 1.7 2 2002 Ohio 3.6 3 2001 Nevada 2.4 4 2002 Nevada 2.9 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 跟原Series一样,如果传入的列在数据中找不到,就会产生NAN值
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five']) print(frame2) /* year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 NaN three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 NaN five 2002 Nevada 2.9 NaN */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 用 Series 字典或字典生成 DataFrame
#通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series,返回的Series拥有原DataFrame相同的索引 frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five']) print(frame2) print(frame2['state']) /* year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 NaN three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 NaN five 2002 Nevada 2.9 NaN one Ohio two Ohio three Ohio four Nevada five Nevada Name: state, dtype: object */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 列可以通过赋值的方式进行修改,例如,给那个空的“delt”列赋上一个标量值或一组值
frame2['debt'] = [16,1,2,2,4] #或 frame2['debt'] = np.arange(5.) print(frame2) /* year state pop debt one 2000 Ohio 1.5 16 two 2001 Ohio 1.7 1 three 2002 Ohio 3.6 2 four 2001 Nevada 2.4 2 five 2002 Nevada 2.9 4 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 元素运算
frame2['new'] = frame2['debt' ]* frame2['pop']
- 1
- 2
- 3
PIL库是一个具有强大图像处理能力的第三方库。
图像的组成:由RGB三原色组成,RGB图像中,一种彩色由R、G、B三原色按照比例混合而成。0-255区分不同亮度的颜色。
图像的数组表示:图像是一个由像素组成的矩阵,每个元素是一个RGB值
- 展示图片,并获取图像的模式、长宽
from PIL import Image import matplotlib.pyplot as plt import numpy as np #显示matplotlib生成的图形 %matplotlib inline #读取图片 img = Image.open('data/data37255/yushuxin.jpg') print(img) # img = Image.open('work/smile01.jpg') img_array = np.array(img).astype('float32') #将一个PIL的图像对象,转换为numpy.array #print(img_array) print(img_array.shape) #显示图片 #img.show() #自动调用计算机上显示图片的工具 plt.imshow(img) plt.show() #获得图像的模式 img_mode = img.mode print(img_mode) width,height = img.size print(width,height)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 图片旋转
from PIL import Image import matplotlib.pyplot as plt #显示matplotlib生成的图形 %matplotlib inline #读取图片 img = Image.open('data/data37255/yushuxin.jpg') #显示图片 plt.imshow(img) plt.show() #将图片旋转45度 img_rotate = img.rotate(45) #显示旋转后的图片 plt.imshow(img_rotate) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 图片剪切
from PIL import Image #打开图片 img1 = Image.open('data/data37255/yushuxin.jpg') #剪切 crop()四个参数分别是:(左上角点的x坐标,左上角点的y坐标,右下角点的x坐标,右下角点的y坐标) img1_crop_result = img1.crop((139,11,379,225)) #保存图片 img1_crop_result.save('/home/aistudio/work/yushuxin_crop_result.jpg') #展示图片 plt.imshow(img1_crop_result) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 图片缩放
from PIL import Image #打开图片 img2 = Image.open('data/data37255/yushuxin.jpg') width,height = img2.size #缩放 img2_resize_result = img2.resize((int(width*0.6),int(height*0.6)),Image.ANTIALIAS) print(img2_resize_result.size) #保存图片 img2_resize_result.save('/home/aistudio/work/yushuxin_resize_result.jpg') #展示图片 plt.imshow(img2_resize_result) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 镜像效果
from PIL import Image #打开图片 img3 = Image.open('data/data37255/yushuxin.jpg') #左右镜像 img3_lr = img3.transpose(Image.FLIP_LEFT_RIGHT) #展示左右镜像图片 plt.imshow(img3_lr) plt.show(img3_lr) #上下镜像 img3_bt = img3.transpose(Image.FLIP_TOP_BOTTOM) #展示上下镜像图片 plt.imshow(img3_bt) plt.show(img3_bt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
Matplotlib库由各种可视化类构成,内部结构复杂。
matplotlib.pylot是绘制各类可视化图形的命令字库
- 绘制折线图
import matplotlib.pyplot as plt import numpy as np #显示matplotlib生成的图形 %matplotlib inline x = np.linspace(-1,1,50) #等差数列 y = 2*x + 1 #传入x,y,通过plot()绘制出折线图 plt.plot(x,y) #显示图形 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 生成多个图
import matplotlib.pyplot as plt import numpy as np x = np.linspace(-1,1,50) #等差数列 y1 = 2*x + 1 y2 = x**2 plt.figure() plt.plot(x,y1) plt.figure(figsize=(7,5)) plt.plot(x,y2) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 设置颜色、线条宽度、标签等
import matplotlib.pyplot as plt import numpy as np l1, = plt.plot(x,y1,color='red',linewidth=1) l2, = plt.plot(x,y2,color='blue',linewidth=5) plt.legend(handles=[l1,l2],labels=['aa','bb'],loc='best') plt.xlabel('x') plt.ylabel('y') # plt.xlim((0,1)) #x轴只截取一段进行显示 # plt.ylim((0,1)) #y轴只截取一段进行显示 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 散点图
dots1 =np.random.rand(50)
print(dots1)
dots2 =np.random.rand(50)
plt.scatter(dots1,dots2,c='red',alpha=0.5) #c表示颜色,alpha表示透明度
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

