- 1基于opencv与mediapipe的民族舞舞蹈动作识别
- 23、【AI技术新纪元:Spring AI解码】AI概念
- 3YOLO目标检测——电力绝缘子缺陷检测数据集【含对应voc、coco和yolo三种格式标签集】
- 4深度学习部署-tensorflow 部署方法_“tensorflow部署
- 5建模实训报告总结_模型实训的心得体会
- 6网络安全简答题
- 7嵌入式设备和固件中的自动漏洞检测(三):静态分析技术_二进制固件检测误报率
- 8python图片鉴黄_鉴黄师专用 Python 轮子之 PornDetective
- 9鸿蒙系统--搭建Ubuntu环境_鸿蒙ubuntu环境搭建
- 10Flutter 3的使用记录_got socket error trying to find package flutter_li
LMDeploy 大模型量化部署实践
赞
踩
LMDeploy 大模型量化部署实践
视频地址:https://www.bilibili.com/video/BV1iW4y1A77P
文档:https://github.com/InternLM/tutorial/blob/vansin-patch-4/lmdeploy/lmdeploy.md
LMDeploy Repo: https://github.com/InternLM/lmdeploy.git
主要内容
包括三个部分,1. 背景,2. LMDeploy 简介,3. 动手实践

大模型部署背景

7B 模型参数内存:7 * 1B * 2 (fp16) = 7 * 1G * 2 Byte = 14G Byte

LMDeploy 简介

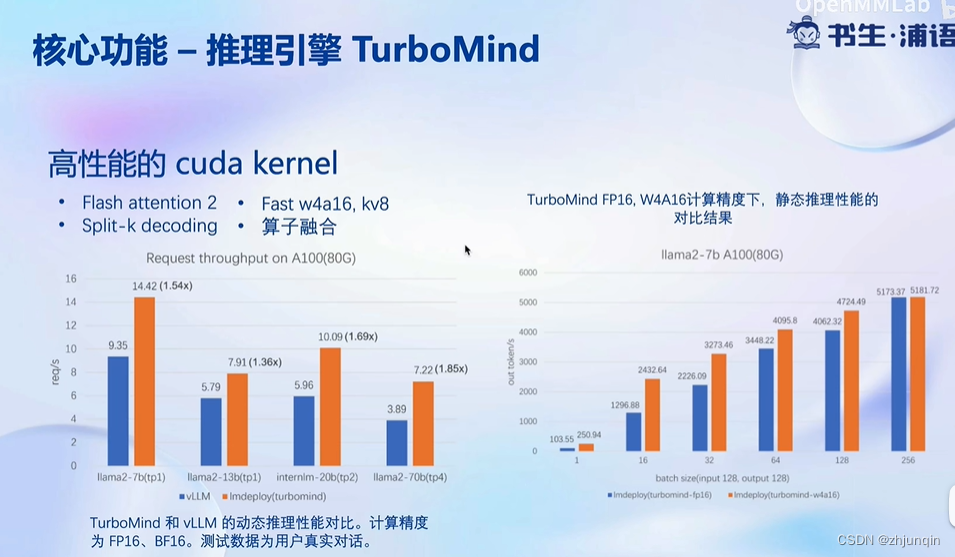
下图中,左边主要对比 LMDeploy 自身在量化前后的性能;右边主要对比 vLLM 和 LMDeploy 的性能对比。
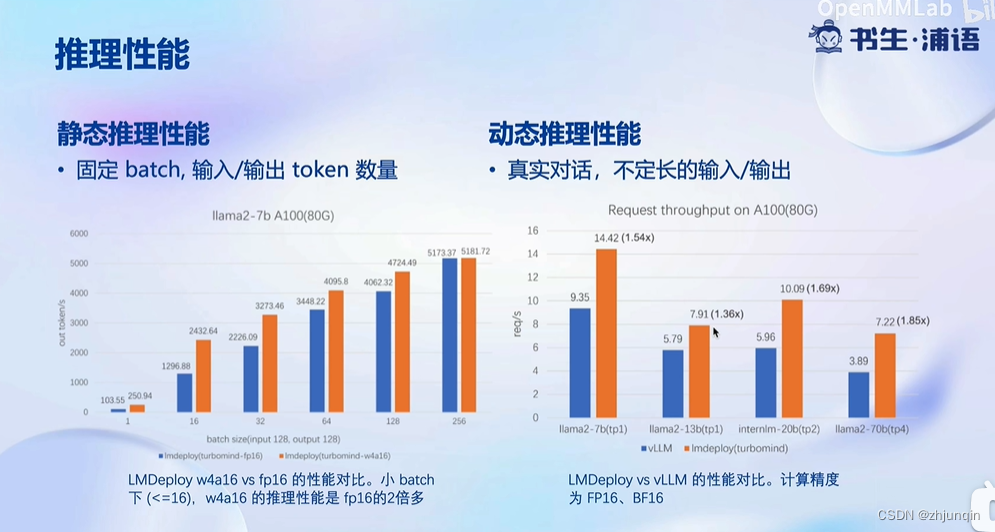
量化后,显存占用量显著减少,其中包括权重和 KV Cache。
由于 GPU 的计算需要将权重从 GPU 主存 -> GPU 共享内存,因此量化显著减少了数据的传输量,提高了整体效率。

AWQ 算法全称:Activation-aware Weight Quantization
GPTQ 算法全称:Accurate Post-Training Quantization for Generative Pre-trained
AWQ 和 GPTQ 作为方法有几个不同之处,但最重要的是 AWQ 假设并非所有权重对 LLM 的性能都同等重要。
也就是说在量化过程中会跳过一小部分权重,这有助于减轻量化损失。所以他们的论文提到了与 GPTQ 相比的可以由显著加速,同时保持了相似的,有时甚至更好的性能。

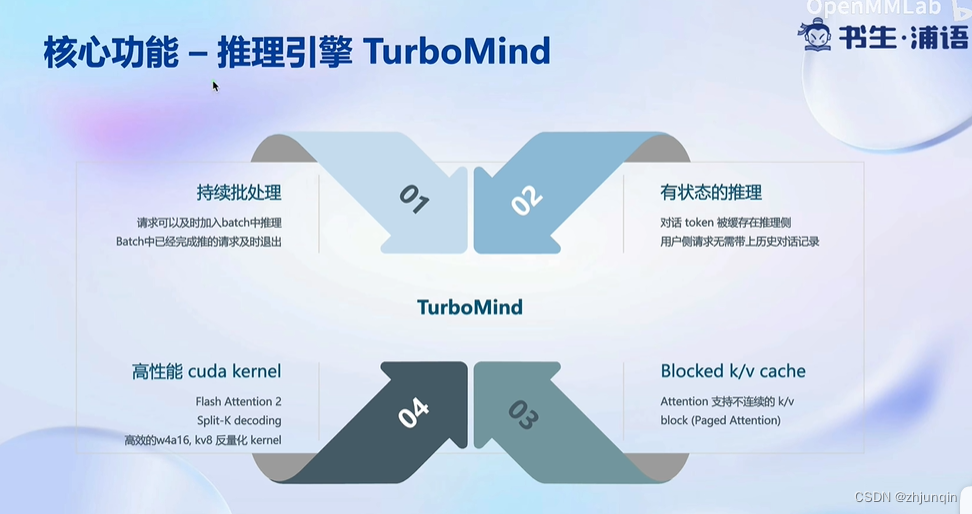
持续批处理

有状态的推理
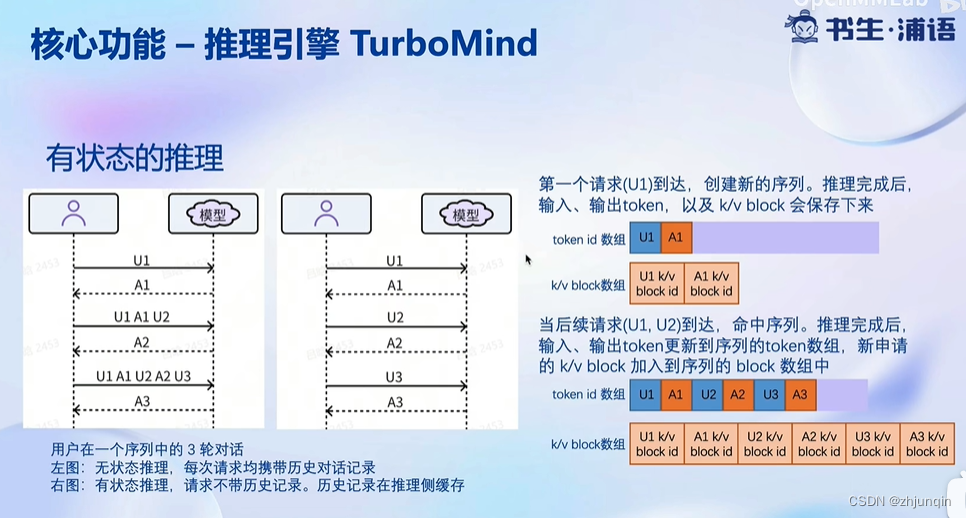
Blocked KV Cache
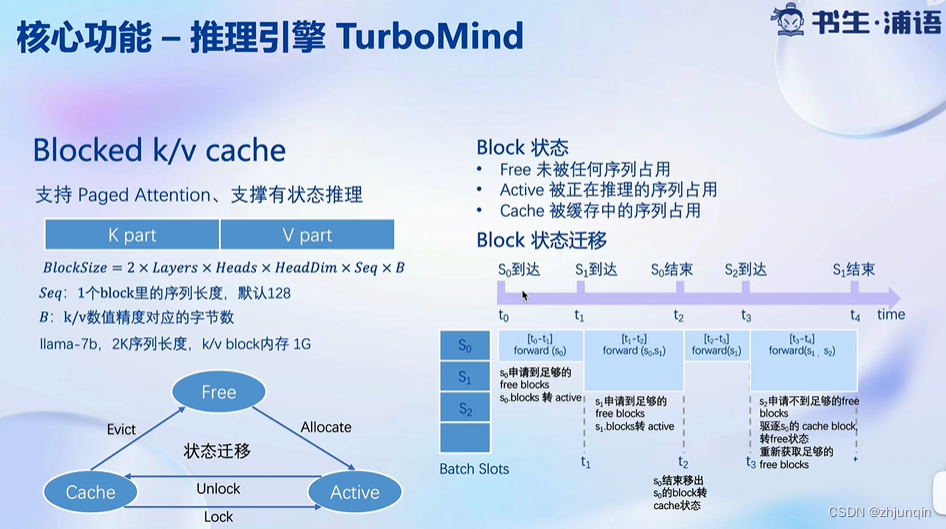
高性能 Cuda Kernel
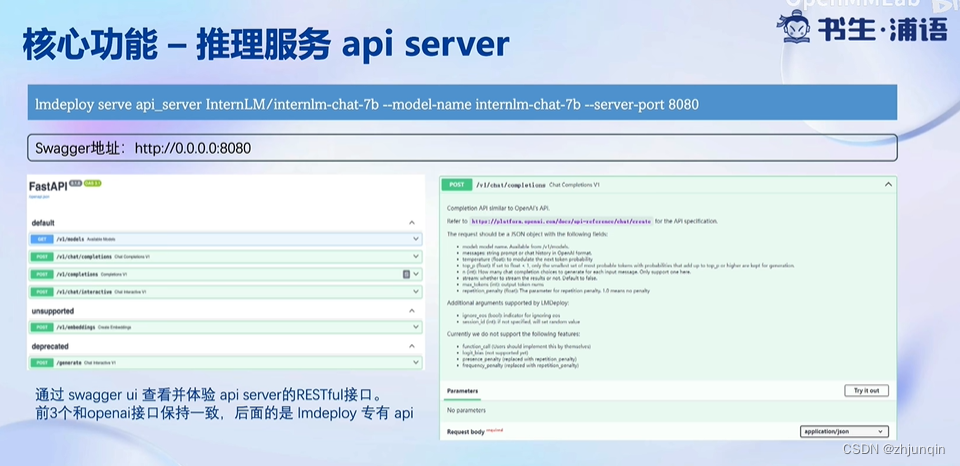
推理服务 API Server
动手实践
推理部署架构
把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务:主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API 等多种方式提供。
- API Server:一般作为前端的后端,提供与产品和服务相关的数据和功能支持。
- Client:可以理解为前端,与用户交互的地方。
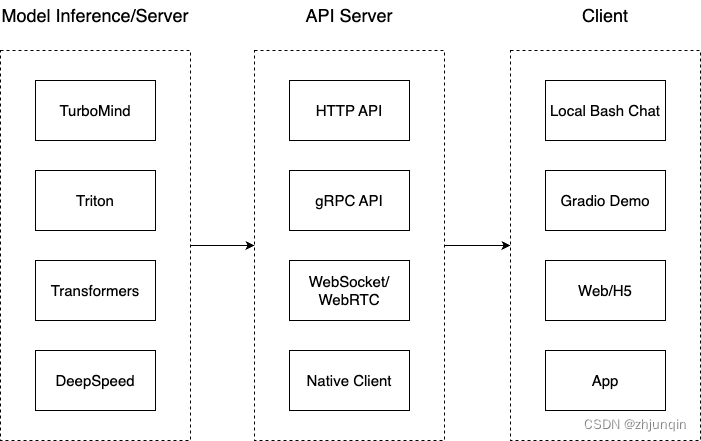
支持的部署方式
- 直接启动 Huggingface 模型
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b
- 1
- 转换成 lmdeploy TurboMind 的格式,后命令行本地对话
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
lmdeploy chat turbomind ./workspace
- 1
- 2
- 3
- 4
- TurboMind 推理 + API 服务
先启动 API Server
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
- 1
- 2
- 3
- 4
- 5
- 6
然后启动 API Client
lmdeploy serve api_client http://localhost:23333
- 1
- 2
- API Server + Gradio
先启动 API Server
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
- 1
- 2
- 3
- 4
- 5
- 6
然后启动 Gradio
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True
- 1
- 2
- 3
- 4
- 5
- TurboMind 推理 + Gradio 直接作为后端
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspace
- 1
- 2
- TurboMind 推理 + Python 代码集成
from lmdeploy import turbomind as tm # load model model_path = "/root/share/temp/model_repos/internlm-chat-7b/" tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b') generator = tm_model.create_instance() # process query query = "你好啊兄嘚" prompt = tm_model.model.get_prompt(query) input_ids = tm_model.tokenizer.encode(prompt) # inference for outputs in generator.stream_infer( session_id=0, input_ids=[input_ids]): res, tokens = outputs[0] response = tm_model.tokenizer.decode(res.tolist()) print(response)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
性能对比
Huggingface 和 lmdeploy 的性能对比,下面为不同的加载代码:
if engine == "hf":
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, trust_remote_code=True)
model.to(device).eval();
gen_func = gen_transformers
else:
tm_model = tm.TurboMind.from_pretrained("./workspace/")
model = tm_model.create_instance()
gen_func = gen_lmdeploy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
engine == “hf” :
# python infer_compare.py hf
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:34<00:00, 4.29s/it]
hf 耗时 27.97秒 43 字/秒
- 1
- 2
- 3
engine == “lmdeploy”:
# python infer_compare.py lmdeploy
model_source: workspace
WARNING: Can not find tokenizer.json. It may take long time to initialize the tokenizer.
[TM][WARNING] [LlamaTritonModel] `max_context_token_num` = 2056.
[TM][WARNING] [LlamaTritonModel] `num_tokens_per_iter` is not set, default to `max_context_token_num` (2056).
[WARNING] gemm_config.in is not found; using default GEMM algo
。。。省略
[TM][INFO] [Interrupt] slot = 0, id = 0
[TM][INFO] [forward] Request complete for 0, code 0
lmdeploy 耗时 8.08秒 140 字/秒
[TM][INFO] ~LlamaBatch()
[TM][INFO] [InternalThreadEntry] stop requested.
[TM][INFO] [OutputThreadEntry] stop requested.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
27.97秒 / 8.08秒 = 3.46,LMDeploy 的速度是 Hugging Face 的 3.46 倍。
模型量化
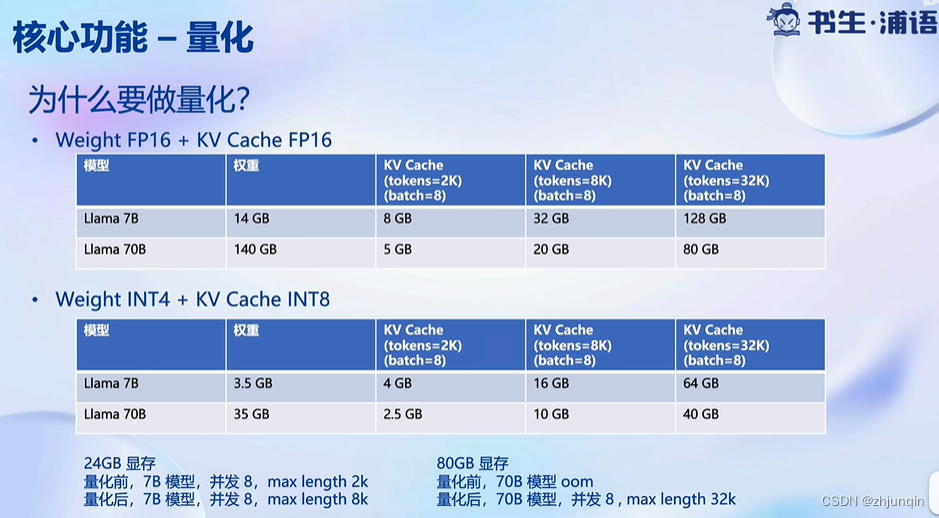
可以使用 KV Cache 量化和 4bit Weight Only 量化(W4A16)。
- KV Cache 量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。4bit Weight 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。
- Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
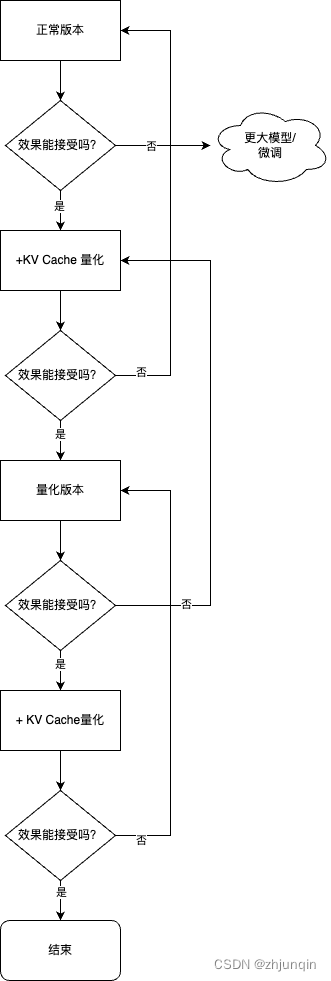
模型量化最佳实践:
Step1:优先尝试正常(非量化)版本,评估效果。
如果效果不行,需要尝试更大参数模型或者微调。
如果效果可以,跳到下一步。
Step2:尝试正常版本+KV Cache 量化,评估效果。
如果效果不行,回到上一步。
如果效果可以,跳到下一步。
Step3:尝试量化版本,评估效果。
如果效果不行,回到上一步。
如果效果可以,跳到下一步。
Step4:尝试量化版本+ KV Cache 量化,评估效果。
如果效果不行,回到上一步。
如果效果可以,使用方案。
简单流程如下图所示。