
热门标签
热门文章
- 1云计算常识_简要介绍云计算、人工智能、大数据、和区块链这几个计算机前沿技术的典型特征
- 2鸿蒙如何用JS开发智能手表App_鸿蒙运动手环软工代码
- 3thinkcmf项目部署到阿里云服务器保姆级教程(宝塔面板/thinkphp/试用ECS)_php项目部署到 服务器
- 4JAVA ArrayList,Vector,LinkedList详解(韩顺平)_java linklist vector
- 5本地缓存之王Caffeine 保姆级教程(值得珍藏)_caffeine教程
- 6FPGA认识相关 来自jimfan博客_srhi srlo
- 7leetcode 84 柱状图中最大的矩阵 思路与C Python实现_最大矩阵和 leetcode
- 8bert系列第二篇:几个损失函数_bert的损失函数
- 9CSS @media - 手机和平板适配_@media(device-type:tablet)
- 10通俗易懂的ChatGPT的原理简介_chatgpt原理
当前位置: article > 正文
wordcount单词词频统计_第1关:wordcount词频统计
作者:笔触狂放9 | 2024-04-08 21:11:48
赞
踩
第1关:wordcount词频统计
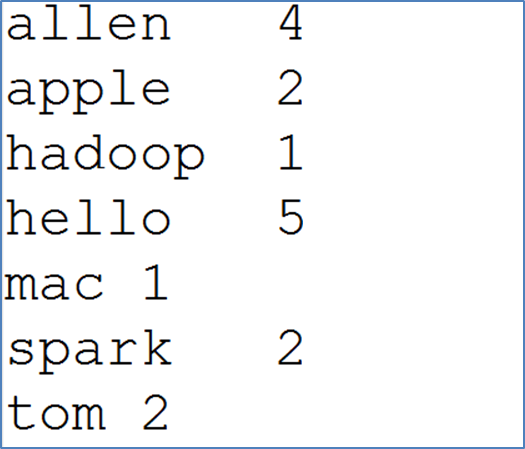
单词出现的总次数
1、WordCount概述
WordCount算是大数据计算领域经典的入门案例,相当于Hello World。
虽然WordCount业务极其简单,但是希望能够通过案例感受背后MapReduce的执行流程和默认的行为机制,这 才是关键。

2、WordCount编程实现思路
map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对。
lreduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是 单词的总次数。

3、WordCount程序提交
上传课程资料中的文本文件1.txt到HDFS文件系统的/input目录下,如果没有这个目录,使用shell创建
hadoop fs -mkdir /input
hadoop fs -put 1.txt /input
准备好之后,执行官方
MapReduce
实例,对上述
文
件进
行
单词
次
数统计 第一个参数
:wordcount
表示执行
单
词统
计
任务;
第二个参数:指定输入文件的路径;
第三个参数:指定输出结果的路径(该路径不能已存在);
h
- [root@node1 mapreduce]# pwd
- /export/server/hadoop-3.3.0/share/hadoop/mapreduce
- [root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount
- /input /output
4、WordCount执行结果
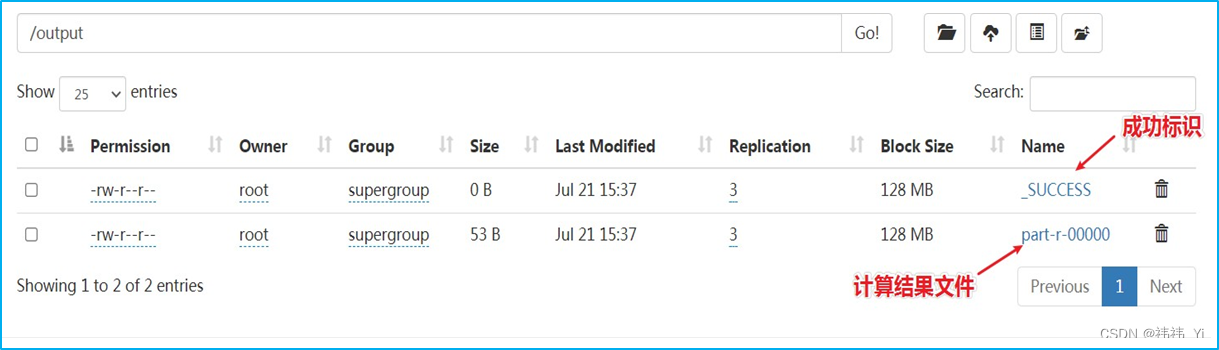
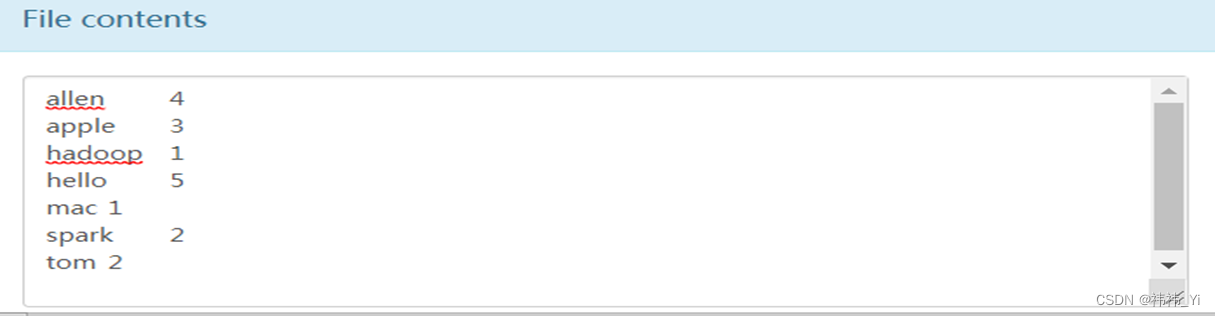
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/388239
推荐阅读

相关标签

