
热门标签
热门文章
- 1【项目】数仓项目(五)_gmall2020-03-16.sql
- 2人工智能AI:细粒度动物识别(8000种动物)
- 3spring security oauth2.x迁移到spring security5.x - 客户端(单点登录)_enableoauth2sso弃用
- 4HADOOP HDFS详解_hadoop详细
- 5前端工程师的成长之路:技术探索与职业发展_前端技术成长方案
- 6edge-tts简单例子_edge-tts 字幕
- 7hive的hive-site.xml
- 8软件测试工程师-面试如何使用代码进行接口测试?_软件测试调用接口代码
- 9数据结构 第五章(树和二叉树)【下】
- 10一文搞定 Appium 环境配置_windowsappium环境设置
当前位置: article > 正文
信息提取的一般方法
作者:笔触狂放9 | 2024-04-10 04:06:57
赞
踩
信息提取
方法一:
完整解析信息的标记形式,,再提取关键信息
XML JSON YAML
需要标记解析器 如bs库的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐
方法二:无标记形式,直接搜索关键信息
搜索
对信息的文本查找函数即可
优点,过程简洁,速度较快
缺点,提取结果准确性与内容相关
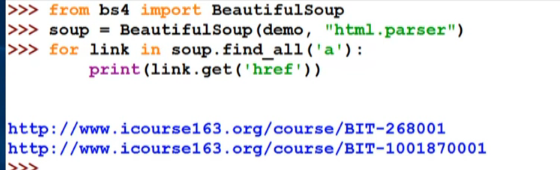
其中的方法
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,储存查找的结果。
name:对标签名称的检索字符串。
attrs:对标签属性值的检索字符串,可标注属性检索。
recursive:是否对子孙全部检索,默认True。布尔型。
string:<>…</>中字符串区域的检索字符串
**kawargs:
(…) 等价于 .find_all(…)
soup(…) 等价于soup.find_all(…)
<>.find 拓展方法

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/396531
推荐阅读