
热门标签
热门文章
- 1ToDesk远程控制_pemm.top
- 2Qwen-Agent自定义Tool
- 3python绘制热力图
- 4Elasticsearch报错received plaintext traffic on an encrypted channel, closing connection Netty4TcpChann
- 5【GitHub项目推荐--7个最佳开源免费库存/仓库管理系统(WMS)】【转载】_github 仓库管理系统
- 6手把手教你安装搭建进销存源码|erp软件|仓库出入库登记系统源码(附源码下载)_erp系统仓库管理系统源码
- 7HDFS-HA模式概念_hdfs ha
- 8Linux Ext4文件系统可能引发数据丢失问题
- 9问题描述:无法在vscode中调试python程序。_vscode不能调试python
- 10数据结构PT1——线性表/链表
当前位置: article > 正文
【项目亮点】大厂中分布式事务的最佳实践 问题产生->难点与权衡(偏爱Saga)->解决方案
作者:笔触狂放9 | 2024-04-20 13:32:34
赞
踩
【项目亮点】大厂中分布式事务的最佳实践 问题产生->难点与权衡(偏爱Saga)->解决方案
【项目亮点】大厂中分布式事务的最佳实践 问题产生->难点与权衡->解决方案->底层实现->应用案例
不断有同学问我大厂中实践分布式事务的问题,这里从分布式事务的产生,到强弱一致性与性能的权衡,再到最终落地的解决方案,再到实际的代码实现,再到我工作中实际使用SAGA模式的应用案例,一篇文章讲清楚.
问题的产生
83.7%分布式事务的产生都是因为拆分微服务导致的:
过去: 曾经在单体服务的时代,所有的数据库操作都是单体服务和mysql集群直接交互 比如电商中的下单操作,先更新订单,再扣减库存 订单和库存都在同一个数据库中,可以使用本地事务保证ACID特性 现状: 现在该服务拆分成了一大堆微服务,其中订单服务和库存服务成了两个服务 那么更新订单和扣减库存就成了两个RPC,数据也属于不同的数据库 这时候,如果更新订单成功了,扣减库存失败了(网络问题或者库存不足) 就会出现一致性问题 目标 分布式事务的目标就是让保证订单和库存数据的一致性 至于是 (回滚/补偿 还是重试) (TCC型(又分为本地和远端,一般说的SEATA那种都是远端实现) SAGA型 最大努力通知型 可靠消息型) 我们一会儿再说

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
一句话概括,分布式事务就是RPC和MQ没法像本地事务那样保证ACID的特性,为了(尽可能,最多保证几个9不可能完全)保证数据库操作,RPC,MQ三者混合使用时的原子性与一致性,而引入的解决方案.
难点与权衡 && 为什么大厂更偏爱Saga分布式事务?
分布式事务的权衡本质上是对性能和一致性的权衡.
熟悉CAP理论的小伙伴都知道,P(分区容错性)是一定要保证的,而C(一致性)和A(高可用)就要做一个权衡了. 而在互联网的业务中,对性能的要求是很高的,不可能为了保证强一致性而导致系统性能出问题.
所以分布式事务中强一致性的方案实际应用的很少. 我们常常在保证高性能的同时,保证最终一致性.
我待过的团队都更倾向于使用SAGA模式来解决分布式事务问题.原因如下:
强一致性方案,对性能损耗严重 直接pass(比如2PC,3PC等) 最大努力通知型,一致性太差,连最终一致性都无法保证 直接pass 最终一致性方案 主流的有SAGA和TCC模式 TCC模式,对代码侵入性太大了,需要把流程改造成try->confirm->cancel 的形式,try锁定的资源只有事务完成或者超时才会释放. 而且部分框架TCC的实现需要依赖TM(事务管理)集群,TM集群也是潜在的性能瓶颈的风险. 所以我们更倾向于使用Saga模式来实现分布式事务 Saga模式引入了全局事务和分支事务的概念,每个分支事务除了业务逻辑还有补偿逻辑 如果调用链路 A->B->C->D ,比如执行到C的时候抛了异常,则从C开始逆向执行补偿逻辑 补偿例子: A->B->C(执行抛出异常)->C补偿->B补偿->A补偿 重试例子: A->B->C(执行抛出异常)->D 执行完了,C会一直重试,直到C执行成功或者大于配置的阈值时停止 当然除了补偿,还可以用配置重试保障一致性 一般来说,我们像更新单据这种操作更倾向于重试 而像扣减库存这种操作更倾向于补偿 (因为扣减库存失败绝大多数是因为库存不足,重试没有意义)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里多提一嘴,很多分布式事务解决方案比如TCC或者SAGA都有两种实现方式 :1.引入TM事务协调器来管理协调事务 2.本地建表分布式方式来管理协调事务 个人建议接入的时候最好选择方式2分布式的方式,最好不要依赖TM(事务管理)集群,TM集群也是潜在的性能瓶颈的风险
解决方案
本地事务信息表+定时任务 实现
核心思想: 用本地事务表 驱动 MQ(本地事务能保证一致性与原子性)
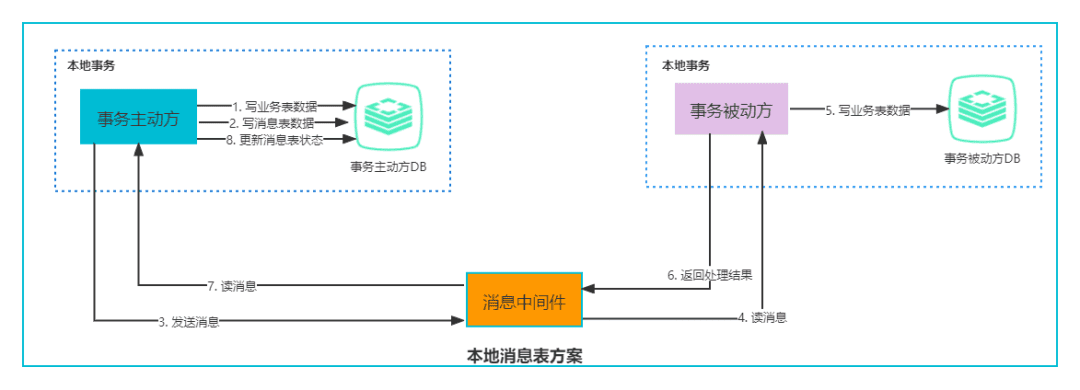
我们知道,之所以会有不一致问题,说白了就是因为MQ和RPC
也就是说如果全部操作都是本地事务,那就能保证ACID,当然也包括一致性与原子性
那把MQ/RPC转成本地事务不就行了?
或者说: 用本地事务表 驱动 MQ/RPC
当然,这种思想好,但实际实现会有严重的性能问题(反射)
那么,我们退而求其次,使用消息队列中间件来让各个分支事务通信(具体见上图),
当各个本地事务之间要通信感知彼此执行成功还是失败时,
这个通信的消息,可以用本地事务表来驱动,
来保证了消息和业务逻辑的一致性.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/457543
推荐阅读
相关标签

