
热门标签
热门文章
- 1Homestead切换PHP版本_php 无法将“update-alternatives”项识
- 2使用matlab训练卷积神经网络_matlab卷积神经网络
- 3Java装箱拆箱和重载重写(五)_integer i1 = 40;integer i2 = 40;相等吗
- 4python中常用的序列化模块_Python中的序列化和反序列化
- 5应用(接口)被刷的解决方案(接口防止机器刷数据的处理方案)
- 6SpringBoot 面试题(六)
- 7用python实现SM2数字证书的坑
- 8Python爬虫天津景点数据可视化和景点推荐系统
- 9基于Hadoop的网上购物行为大数据分析及预测系统【flask+echarts+机器学习】前后端交互_基于hadoop的购物行为分析系统
- 10算法工程师的日常工作内容?你想知道的可能都在这里
当前位置: article > 正文
【MATLAB第68期】基于MATLAB的LSTM长短期记忆网络多变量时间序列数据多步预测含预测未来(非单步预测)_lstm区间预测matlab
作者:笔触狂放9 | 2024-04-21 23:25:28
赞
踩
lstm区间预测matlab
【MATLAB第68期】基于MATLAB的LSTM长短期记忆网络多变量时间序列数据多步预测含预测未来(非单步预测)
输入前25个时间,输出后5个时间
一、数据转换
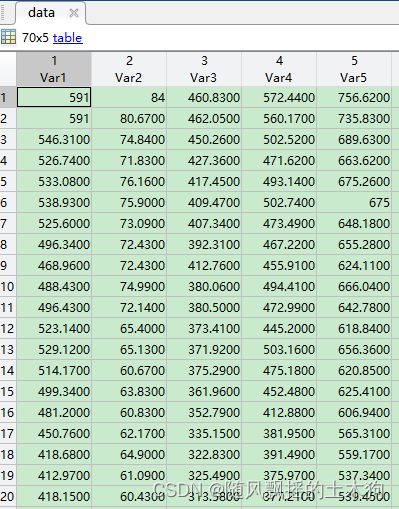
1、原始数据
5列时间序列数据,70行样本
70×5 数据矩阵结构
2、数据转换
将总数据data划分成14×1cell,且每行为5×5的数据
14行cell中,每行代表5个变量的5天数据。
多步预测:根据前25天数据预测后5天数据
即5×1cell 预测 1×1cell
如:1~5行cell 预测第6行(1-25天,预测26-30天)
2~6行cell 预测第7行(6-30天,预测31-35天)
······
9-13行cell 预测第14行(41-65天,预测66-70天)
其次,将data_y弄成5×25,与data_x序列长度一致
data_add(n,1) ={zeros(5,20)};,增添零值
即将data_y 由5×5 变换为 5×25
二、参数设置
%% LSTM网络训练
inputsize =5;
outputsize =5;
layers=[sequenceInputLayer(inputsize);
bilstmLayer(200);
dropoutLayer(0.2);
fullyConnectedLayer(outputsize);
regressionLayer();
];
opts = trainingOptions('adam', ...
'MaxEpochs',2000, ...
'GradientThreshold',1,...
'ExecutionEnvironment','cpu',...
'InitialLearnRate',0.005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',125, ... %2个epoch后学习率更新
'LearnRateDropFactor',0.2, ...
'Shuffle','once',... % 时间序列长度
'L2Regularization',0.005,...%正则项系数初始值。建议一开始将正则项系数λ设置为0,先确定一个比较好的learning rate。然后固定该learning rate,给λ一个值(比如1.0),然后根据validation accuracy,将λ增大或者减小10倍(增减10倍是粗调节,当你确定了λ的合适的数量级后,比如λ = 0.01,再进一步地细调节,比如调节为0.02,0.03,0.009之类。
'SequenceLength',25,...
'MiniBatchSize',10,...%比如mini-batch size设为100,则权重更新的规则为:%也就是将100个样本的梯度求均值,替代online learning方法中单个样本的梯度值
'Verbose',1,...
'Plots','training-progress');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
三、预测
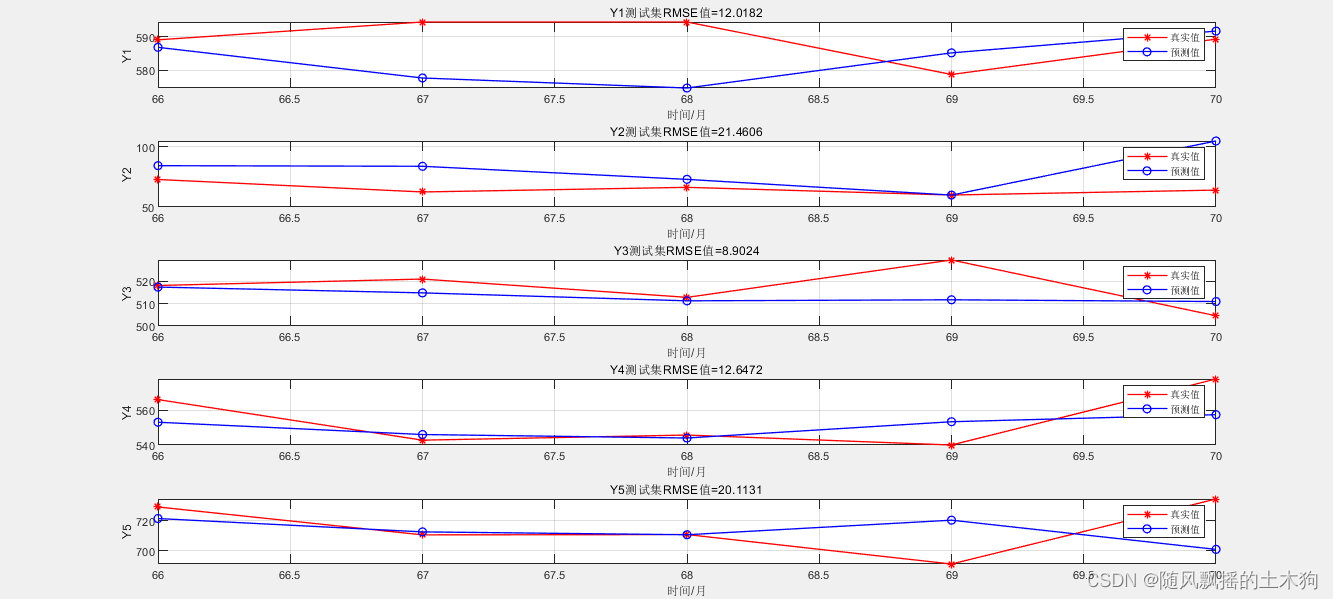
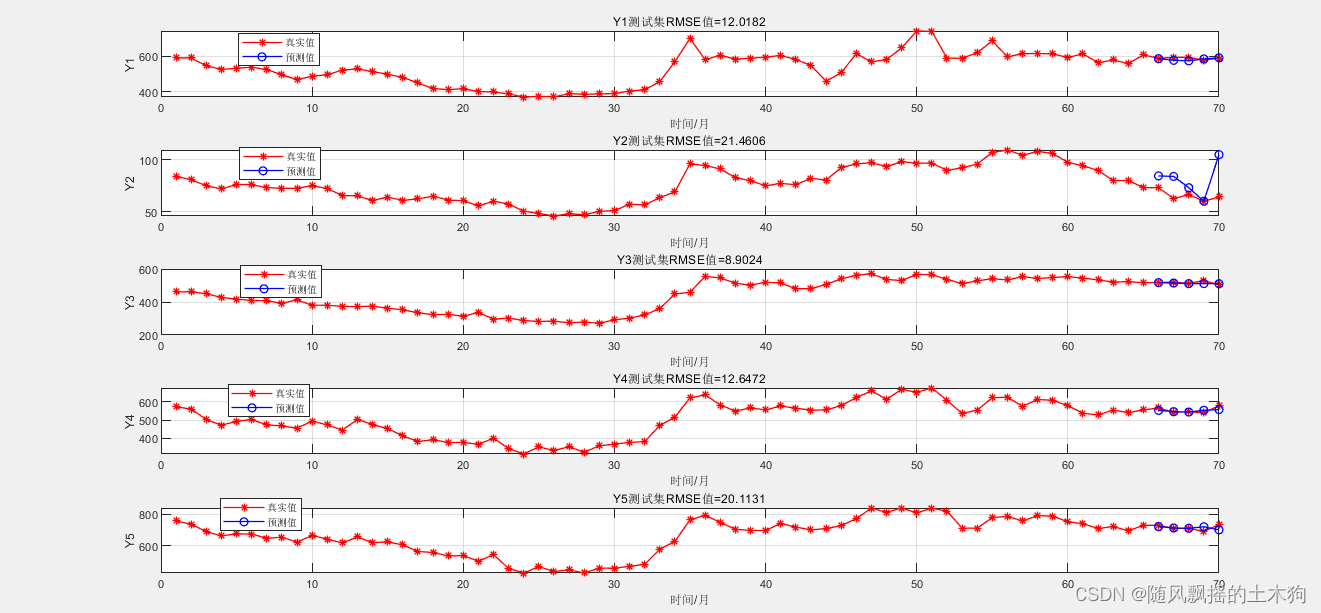
1、测试集效果
输入data_x最后一行数据 ,即41-65天
输出 [1-20构造数据]+ 66-70天数据
筛选后5天数据 。
2、预测未来
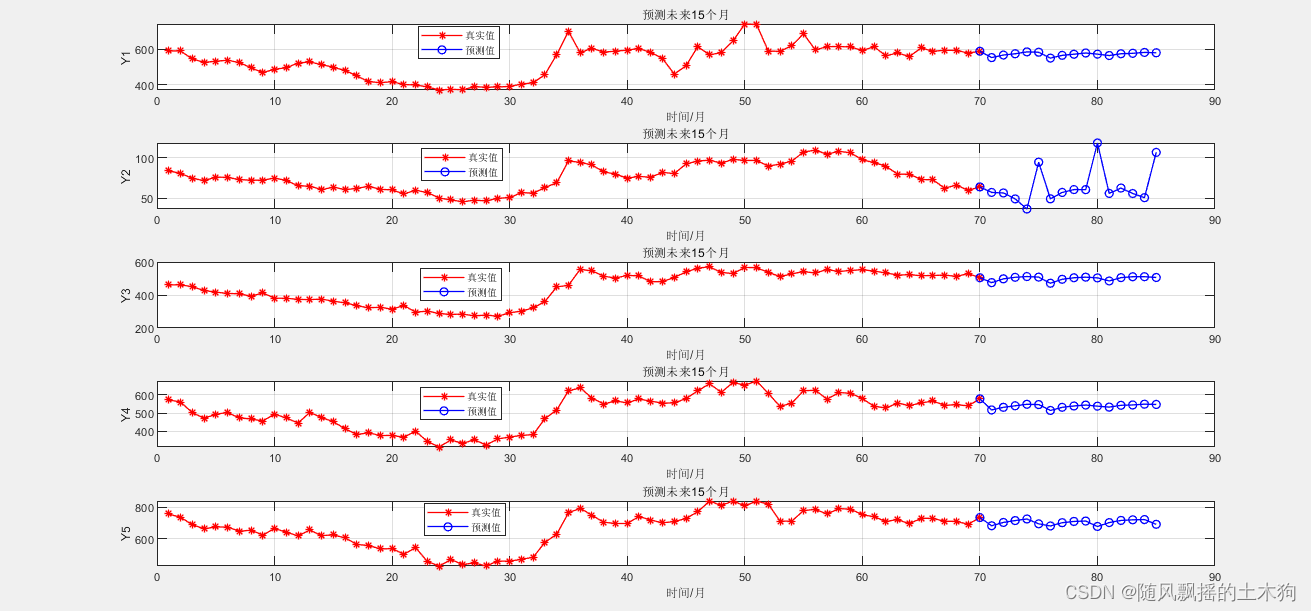
若需要预测未来5天 P1(71-75),则只需要输入
第46-70天 5个变量数据
就会得到 [1*20构造数据]+第71-75天数据
若需要预测未来10天 P2(76-80),则只需要输入
第51-75天 (71-75天数据由P1提供)5个变量数据
就会得到 [1*20构造数据]+第76-80天数据
若需要预测未来15天 P3(81-85),则只需要输入
第56-80天 (76-80天数据由P2提供)5个变量数据
就会得到 [1*20构造数据]+第81-85天数据
四、代码获取
后台私信回复“第68期”可获取下载链接。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/465660?site=


