
- 1FastDFS_store_path0
- 2ROS gazebo 机器人仿真,环境与robot建模,添加相机 lidar,控制robot运动_gazebo小车加rgbd相机
- 38266使用AT指令连接onenet平台_用at命令登陆onenet
- 4面试题:Rabbitmq怎么保证消息的可靠性?
- 5[力扣LeetCode] 14最长公共前缀 (C语言)_c语言中最大公共前缀
- 6刷题DAY57 | LeetCode 647-回文子串 516-最长回文子序列
- 7从rsa公钥中提取N和E_python代码读取出公钥的n和e
- 8Vivado Error问题之[DRC NSTD-1] 问题解决
- 9计算机类应届生简历10篇_计算机应届生简历
- 10《2023 大语言模型综合能力测评报告》出炉:以文心一言为代表的国内产品即将冲出重围_大语言模型推理市场规模分析
人体运动轨迹的人工智能动画模拟
赞
踩
作为博客文章的处女秀,我将简要介绍一下我的研究领域。从现在起,我将之命名为“人体运动轨迹的人工智能动画模拟”(Physically-Based Animation ,下文简称PBA)。
译注:
这篇文章最早是在Media看到的,文中,作者将这一方法命名为Physically-Based Animation,但稍后却不知为何删除了Media上的文章,于是我们找到了作者的博客,在上面找到了这篇文章,但在博客中,这一方法被描述为Procedural Animation,即程序性动画。我个人较愿意以最新的名称来命名这一动画,因为Physically,既可以理解为物理反馈式的,也可以理解为人体的,因此更符合目前的研究方向和案例。
一、关于我的一点介绍

PBA非常类似于众所周知的强化学习(RL)领域。我们会创建一个实验对象,并希望它采取一些行动(比如,移动它的身体并创建一个动画)。但是,PBA和RL之间有着巨大的区别。在RL中,最重要的目标是最大化一些累积奖励信号。因此,例如,如果我们希望我们的对象向前推进,它只关心前进这一事实本身,而不关心移动的质量。这就是为什么目前最先进的RL算法也只能生成一些像是疯狂的僵尸一样的动画。作为一个例子,看看PPO算法的输出,PPO是RL领域模拟连续状态和动作的最新技术。
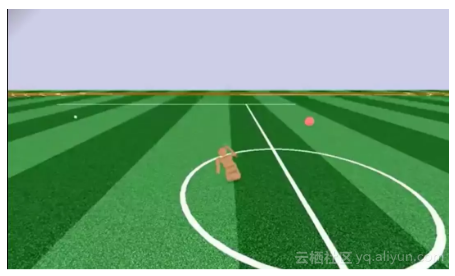
(动画链接:http://t.cn/E2ogZzN)
(动画 Proximal Policy Optimization - Robust knocked over stand up)
如果我们只使用RL方法来制作PBA的话,这已经是我们所能期望的最好的输出效果了。PBA的目标是产生尽可能自然的运动形态。不幸的是,将自然运动轨迹编码成累积奖励信号几乎是不可能的(为此我曾经进行过几个月的尝试,但最终还是放弃了,只是一个简单的击打拳击袋的任务我都没能完成)。这使得使用RL算法求解PBA变得非常困难。
三、关键帧动画的缺陷
有人可能会问,为会要研究PBA,广泛应用的关键帧动画有什么问题么?并不能说使用关键帧动画有什么不好,但它有其自身的局限性。我会在以下几个方面讨论最重要的限制因素:
1、关键帧动画是很昂贵的。我在游戏界工作了一些年,并有机会为伊朗本土市场制作了三款游戏。在所有这些项目中,动画部分始终是开发团队最重要的瓶颈之一。
2、关键帧动画缺乏灵活性。把动画混合在一起很容易,但这不会创造新的动画。因此,每次我们想编辑我们的动画或创建一个新的动画,我们必须为此付出代价。
3、关键帧动画没有响应性。换句话说,它不能自动适应周围环境的变化。我想,任何玩过电子游戏的人,都记得角色动画看起来很愚蠢的各种情况。在这种情况下,动画本身通常是没问题的,只是在错误的时间播放了而已。
一些公司试图突破这些限制,而且也取得了一定程度上的成功,比如FIFA系列就是很好的例子。但是这些限制仍然是游戏动画中最具挑战性的问题之一。
四、PBA与游戏
不难看出,为什么PBA能够有效地解决关键帧动画的局限性。它很便宜,因为我们不需要付钱给动画师。也很灵活,我们可以通过改变角色/环境的力度来获得不同类型的动画。最后,实时运行,实时响应。
有一些游戏已经使用PBA作为其制作技术的一部分。其中,QWOP和Toribash 是最成功的两个例子。(如果有其他的好例子值得一提,也请告诉我)。你可以在互联网上找到很多这些游戏的游戏视频。但是,我强烈建议你自己下载并尝试一下,这样你才能真正感受到游戏中PBA的力量和复杂性。
为了使读者免于搜索和下载之苦,下面这个视频显示了一些Toribash游戏中超级酷的动作:

(动画链接:http://t.cn/E2odeDV)
(动画 Supermoves - Toribash)
五、悬而未决的问题
目前为止我讲的都是好消息。坏消息是,几乎关于PBA的一切都属于悬而未决的问题。在过去的二十年里,在这个领域已经有了很多的研究,但是我们还远没有强大的算法来产生高质量的动画。在这里,我试着列举了这一领域中最重要的几个问题:
1、我们如何找到PBA生成有效方法?
2、我们如何将这些方法的计算开销降到最低,使它们在实时应用程序(特别是游戏)中可用?
3、我们如何评估动画的质量(从流畅性、自然度等方面)?
4、利用这一领域的最新进展可以设计怎样的新的游戏机制?
5、这一领域如何影响增强/混合/虚拟现实技术的发展?
六、进展如何?
了解了PBA的相关问题,下面介绍一下一些最新进展。从SIGGRAPH 2017大会上发表的关于这个问题的技术论文中,我选择了3个视频做为例子(如果会上还有其他例子,也请让我知晓)。我相信,通过观看这些视频,你可以很好地了解这个领域的现状。
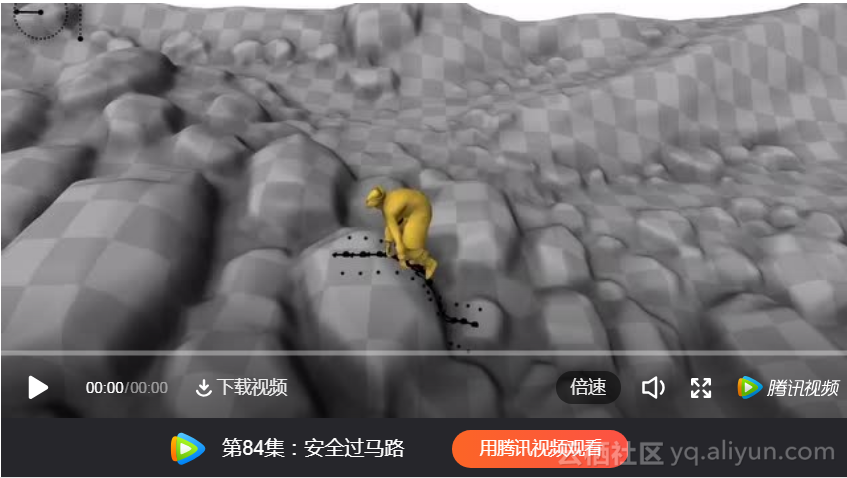
例1:发现和合成类人爬升的运动轨迹。
译注:
这个视频讲解了PBA的路径规划方法和运动优化方法。分别采用CMA-ES和C-PBP算法来控制假人的爬行以对比效果。系统会遍历岩点和墙面,并对运动轨迹进行脱机优化,在CPU时间35秒的时候,找到了第一条到达最终岩点的路径。然后系统开始基于启发式偏好来寻找更多的爬行路径。经过对攀岩地图的探索,系统会根据不同的参数,对所有的路径做排序和显示,这些参数包括最小的扭矩和力量的乘积和,或者最小的移动步数。CMA-ES在此过程中显示了更强大的能力,但收敛过程比较缓慢。两种算法都可以得到相对自然的爬行形态。系统也适用于强调平衡能力的直线路径。系统支持很容易的调整假人的关节力矩来模拟身体机能的强弱,弱化假人将拖慢路径的规划,有些路径的尝试甚至因此失败了。定性的说,越是保守的路径,会有越高的成功率。
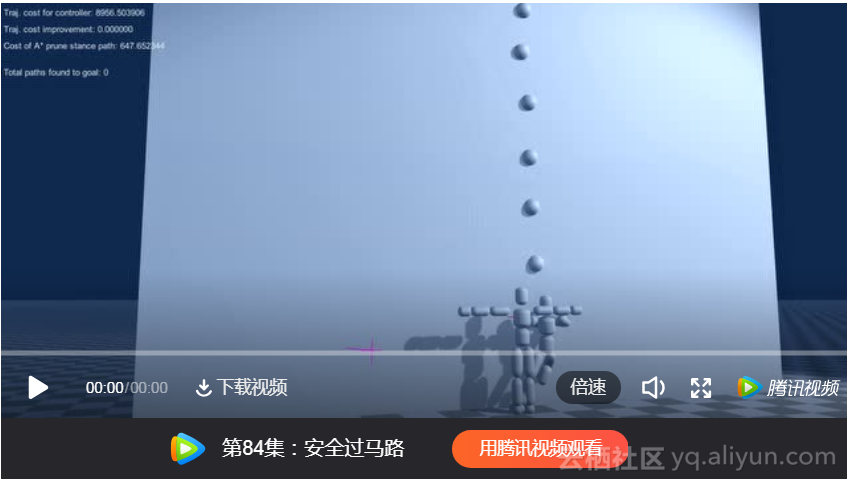
(动画 SIGGRAPH 2017 climbing AI (full video))
例2:用于角色控制的相位函数神经网络
译注:
来自雷锋网(http://t.cn/E2oELqf)。在大多数游戏中,游戏角色的动画是提前通过动作捕捉封装好的,这就意味着一位玩家在游戏中会看到完全相同的动作出现上千次,确实挺无聊的。“我们的系统就完全不同。”来自爱丁堡大学的研究人员 Daniel Holden 在接受采访时说道。
“我们会先准备一个庞大的动画数据库,”他说道。“随后我们会利用机器学习打造一个系统,该系统能直接将用户的输入映射到游戏角色的动作上去。因此,与将所有数据存储起来并根据某些指令进行呈现不同,我们的系统能根据用户输入直接产生相应的动画效果。”
该系统的功效确实显而易见,在演示视频中,即使背景地形相当复杂,那个戴三角帽的游戏角色也能做出许多自由且自然的动作。
在这段演示视频背后,其实是 Holden 和他的同事两小时之内拿到的 1.5GB 动作捕捉数据。在那之后,神经网络利用这些数据自主训练了 30 小时,大体上学会了如何将这些通过动作捕捉获得的动画重新结合并运用在游戏场景中。
“神经网络的加入让角色呈现出了一个姿势该有的组成部分,玩家的输入则随机的让这些组成部分相结合。”Holden 解释道。
这样一来,角色能做出的动作输出就比直接前期封装好的要多得多。就拿跳下窗台这个动作来说,传统的动画系统会直接载入“跳下窗台”的动画文档,但神经网络会通过数据库中类似场景的数据推断四肢的不同动作,并将这些数据进行融合以便完成最终的动作输出。
1.5GB 的训练数据在神经网络中以这种方式存储只需要数十兆的空间,Holden 解释道。“动画数据被压缩进了神经网络的权重,如果数据库中的每个姿势都能被分解成数个组成部分的加权和,神经网络就能轻松学习并大幅压缩数据体积。”
其他的动画处理方式也能混合不同的动作捕捉“场景”并使用在新的环境中。不过,这些方式需要在本地存储大量的数据,因此会拖慢系统速度。一些最新的研究显示,其他以神经网络为基础的动画模型如果没有在混合处理过程中添加周期性阶段进行协助,产出的动画就相当粗糙,而且动作不自然。
利用神经网络改变动作捕捉动画可能会得到一些意想不到的结果,Holden 说道。举例来说,研究人员并未给一个在崎岖地形蹲着行走的角色提供专门的动作捕捉数据,但系统却自己学会了这种情况的处理方式,它将平坦地形上蹲伏的动作与崎岖地形中行走和奔跑的动作进行了结合。
用 AI 来处理角色动画确实有其优势,但 Holden 也遇到了不少困难。首先,30 小时的训练时间就是个大麻烦,尤其是你想补录一些动作的情况下。此外,负责动作设计的艺术家也无法直接对神经网络的输出进行润色,而在传统的方式中,这一步相当重要。最后,虽然神经网络可以实时进行反应,但 1 秒钟的耗时在应用时还是没有预录动画来得快(Holden 认为未来肯定能找到提速的方式)。
(动画 Phase-Functioned Neural Networks for Character Control)
例3:DeepLoco:使用分层深度强化学习的动态运动技能
译注:
(http://t.cn/E2odh3v)学习以物理为基础的运动技能是一个困难的问题,相关解决方案通常利用各种形式的先验知识。视频中介绍的方法,是在以有限的先验知识学习各种环境感知的运动技能。采用两级递阶控制框架.首先,低水平控制器会学习如何在一个良好的时间范畴内,实现稳健的步行步态,并满足步进方向和风格的目标。其次,高阶控制器通过调用低级别控制器建立的理想化的步骤目标,来规划限定时间范围内的步进策略。高级控制器直接基于高维输入做出决策,包括地形图或环境的相关指标。两个级别的控制策略都是使用深度强化学习进行训练的。在模拟的三维双足动物上进行了实验验证。低水平控制器是针对各种运动类型学习的,并且在基于力的扰动、地形变化和样式插值方面表现出了鲁棒性。高级控制器能够跟踪地面轨迹,将足球运抵目标位置,并能在静态或动态障碍之间进行导航。
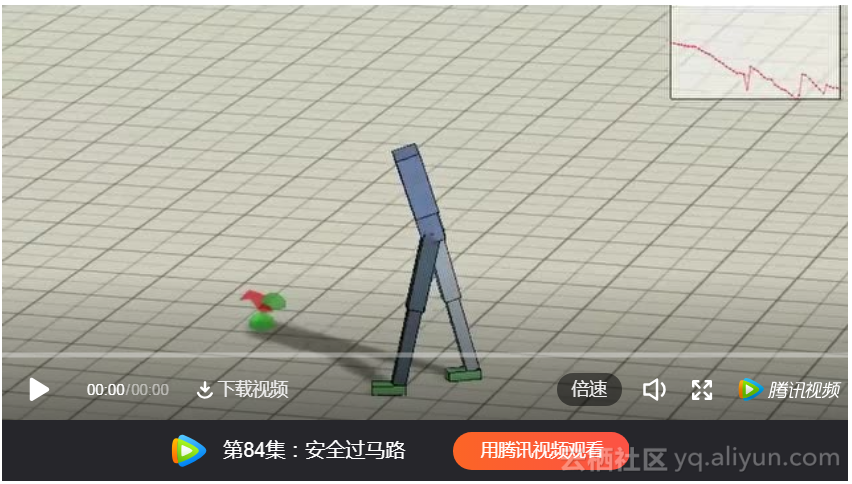
(动画 SIGGRAPH 2017 - DeepLoco paper (main video))
七、结语
在这篇文章中,我试图简要介绍PBA领域及其挑战。我认为了解这一领域与强化学习之间的区别是很重要的,尽管我并不否认两者的相似之处。实际上,我目前的研究很大一部分是在探索在PBA中应用最新的RL技术的可行性。
我必须承认,在写这篇文章之前,我很担心言之无物。但现在我的脑海里已经有了下一篇文章的主题。在我的下一篇文章中,我将尝试解释PBA作为一种职业生涯可能会遇到的问题。因此,如果你正考虑进入这个领域,我的下一篇文章可能会对你有用。
最后,我很想听听读者对游戏AI研究的任何评论或问题。
原文发布时间为:2018-11-23
本文作者:Amin Babadi

