- 1【前端技术】uni-app 01:快速开始_前端uni-app
- 2北理计算机考研复试经验贴_北理复试上机
- 3SpringSecurity(十七)------CSRF_http.csrf().disable()
- 4BS系统自定义报表插件_bs架构 报表解决方案
- 5编程:不只是工作,是我生活的一部分
- 6第4天:基础入门-30余种加密编码进制&Web&数据库&系统&代码&参数值
- 7vue-router深度解析,全方位搞定路由!_vueroute原理
- 8Jmeter的JSON断言_最新版本jmeter json断言
- 92023年GitHub上最值得关注的10个开源项目_永久github2023
- 10字节跳动nlp算法工程师面试,查漏补缺,带你碾压面试官
Retinexformer One-stage Retinex-based Transformer for Low-light Image Enhancement_retinexformer: one-stage retinex-based transformer
赞
踩
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement
在增强弱光图像时,许多深度学习算法都基于 Retinex 理论。然而,Retinex 模型并没有考虑隐藏在黑暗中或由亮光过程引入的损坏。此外,这些方法通常需要繁琐的多阶段训练管道,并且依赖于卷积神经网络,在捕捉长距离依赖关系方面存在局限性。在本文中,我们提出了一个简单而原则性强的基于 Retinex 的单阶段框架(ORF)。ORF 首先估计照度信息以照亮低照度图像,然后恢复损坏的图像以生成增强图像。我们设计了一个光照引导变换器(IGT),利用光照表征来引导不同光照条件区域的非局部交互建模。通过将 IGT 插入 ORF,我们得到了我们的算法 Retinexformer。全面的定量和定性实验证明,我们的 Retinexformer 在 13 个基准测试中的表现明显优于最先进的方法。用户研究和弱光物体检测应用也揭示了我们方法的潜在实用价值。代码见 https://github. com/caiyuanhao1998/Retinexformer。
我们的贡献可归纳如下-
- 我们提出了首个基于变换器的低照度图像增强算法 Retinexformer。
- 我们提出了一种基于 Retinex 的单阶段低照度增强框架 ORF,该框架具有简单的单阶段训练过程,并能很好地对损坏进行建模。
- 我们设计了一种新的自我关注机制–IG-MSA,它利用光照信息作为关键线索来指导长距离依赖关系的建模。
- 定量和定性实验表明,在 13 个数据集上,我们的 Retinexformer 优于 SOTA 方法。用户研究和弱光检测的结果也表明了我们方法的实用价值。
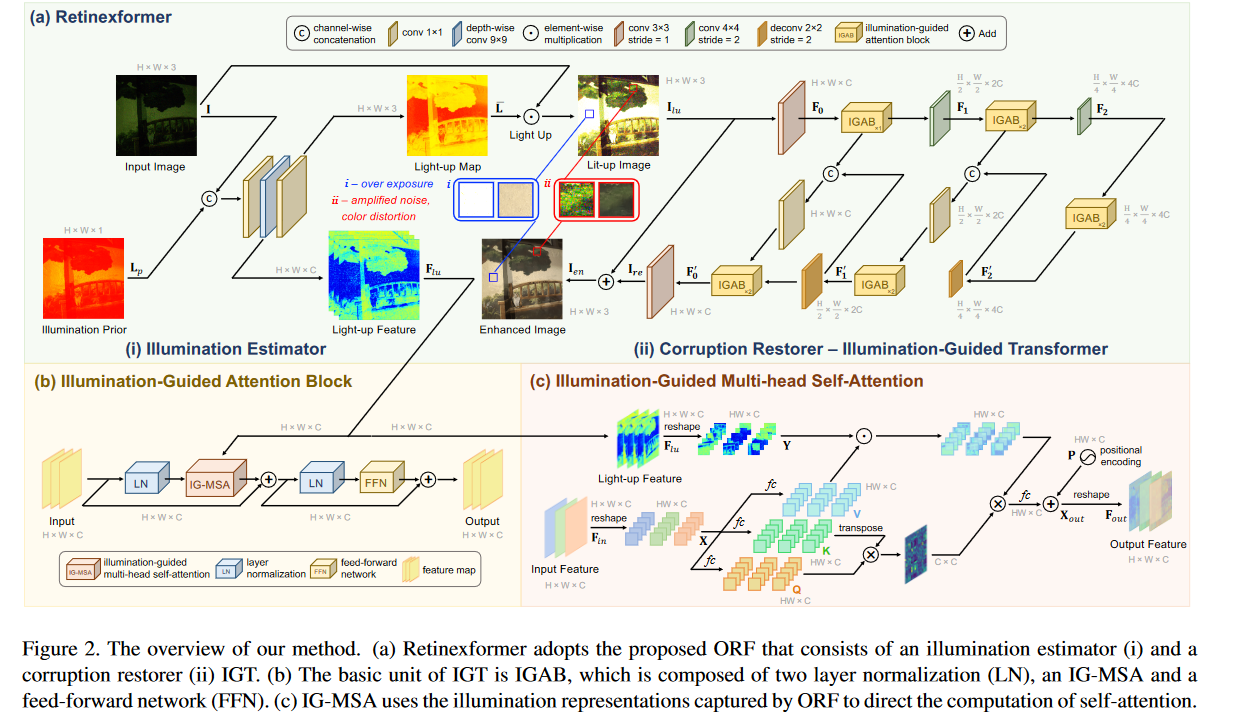
$\varepsilon $ 的结构如图 2 (a) (i) 所示。$\varepsilon $ 首先使用 conv1×1(卷积,核大小 = 1)对 I 和 Lp 进行融合。我们注意到,曝光良好的区域可以为曝光不足的区域提供语义上下文信息。因此,我们采用一个深度可分离的 conv9×9 来模拟不同光照条件下区域之间的相互作用,从而生成亮部特征 Flu。然后,$\varepsilon $ 使用 conv1×1 对 Flu 进行聚合,生成亮度图$\bar{L} $ ∈ RH×W ×3。我们将$\bar{L} $ 设置为三通道 RGB 张量,而不是像 [15, 18] 那样的单通道张量,以提高其在模拟 RGB 通道非线性色彩增强时的表示能力。然后$\bar{L} $ 将用于点亮公式 (3) 中的 I。
讨论(i) 与之前基于 Retinex 的深度学习方法[30, 49, 54, 65, 66]不同,我们的 ORF 估算的$\bar{L} $ 而不是光照图 L,因为如果 ORF 估算 L,那么点亮的图像将通过元素除法(I./L)获得。计算机很容易受到这种操作的影响。张量的值可能非常小(有时甚至等于 0)。除法很容易导致数据溢出问题。此外,计算机随机产生的微小误差也会被这一操作放大,导致估算不准确。因此,建立 ̄ L 模型更为稳健。
(ii) 以往基于 Retinex 的深度学习方法主要侧重于抑制反射图像上的噪声等破坏,即式(2)中的 ˆ R。它们忽略了对照度图的估计误差,即式(2)中的ˆ L,因此容易导致亮灯过程中曝光不足/过度和色彩失真。相比之下,我们的 ORF 会考虑到所有这些损坏,并使用 R 将其全部还原。
3.2. Illumination-Guided Transformer
以前的深度学习方法主要依赖于CNN,在捕获长期依赖性方面显示出局限性。由于全局多头自注意力(MSA)的巨大计算复杂性,一些CNN-变压器混合工作(如SNR-Net [57])仅采用U形CNN最低分辨率的全局变压器层。变压器的潜力尚未得到充分开发。为了填补这一空白,我们设计了一个照明引导变压器(IGT)来扮演公式(5)中腐败恢复器R的角色。
Network Structure.
如图2(a)(ii)所示,IGT采用三尺度U形架构[44]。IGT的输入是亮起的图像Ilu。在下采样分支中,Ilu 经历一个 conv3×3、一个 IGAB、一个跨步 conv4×4(用于缩小特征)、两个 IGAB 和一个跨步 conv4×4 以生成分层特征 Fi ∈ R H 2i × W 2i ×2iC,其中 i = 0, 1, 2。然后 F2 通过两个 IGAB。随后,设计一个对称结构作为上采样分支。利用步幅 = 2 的 deconv2×2 来升级功能。跳过连接是用于缓解下采样分支造成的信息丢失。上采样分支输出残余图像 Ire ∈ RH×W ×3。然后由 Ilu 和 Ire 之和导出增强图像 Ien,即 Ien = Ilu + Ire。
IG-MSA。如图2(c)所示,由E估计的RH×W ×C的点亮特征Flu∈被馈送到IGT的每个IG-MSA中。请注意,图2(c)描述了最大比例的IG-MSA。对于较小的比例,使用步幅 = 2 的 conv4×4 层来缩小 Flu 以匹配空间大小,此图中省略了空间大小。如前所述,全球MSA的计算成本限制了Transformer在微光图像增强中的应用。为了解决这个问题,IG-MSA将单通道特征图视为令牌,然后计算自我注意。
4.4. 消融研究
我们在SDSD-室外数据集上进行消融研究,以获得视网膜前线在其上的良好收敛性和稳定性能。结果在选项卡 4 中报告。分解消融。我们进行分解烧蚀以研究每个组件对更高性能的影响,如选项卡 4a 所示。Baseline-1是通过从Retinexformer中删除ORF和IG-MSA而得出的。当我们分别应用 ORF 和 IG-MSA 时,基线 1 实现了 1.45 和 2.39 dB 的改进。当联合利用这两种技术时,基线1增益为3.37 dB。这一证据表明我们的ORF和IG-MSA的有效性。
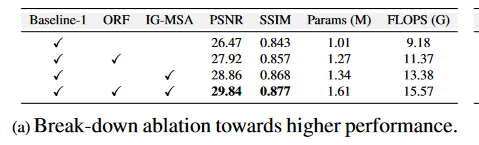
我对这个地方有个问题,baseline-1如何得来的呢,他的结构是啥?有大牛回答一下吗
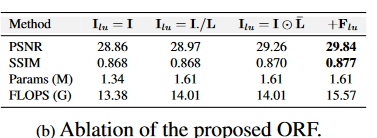
**One-stage Retinex-based Framework.**我们进行消融以研究ORF。结果列在选项卡 4b 中。我们首先从 Retinexformer 中删除 ORF,并将 R 的输入设置为 Ilu = I。该模型产生 28.86 dB。然后我们应用 ORF 但设置 E 来估计照明图 L。R 的输入是 I./L,其中 ./ 表示逐元素除法。为了避免计算机抛出的异常,我们用一个小常数 ε = 1×10−4 添加 L。然而,正如第3.1节所分析的那样,计算机容易受到小值划分的影响。因此,该模型获得了0.11 dB的有限改进。为了解决这个问题,我们估计了发光图̄L,并将R的输入设置为Ilu = I ⊙ ̄ L。该模型增益为 0.40 dB。在使用 Flu 引导 R 后,该模型在 PSNR 中继续实现 0.58 dB 的改进,在 SSIM 中分别实现了 0.007 dB 的改进
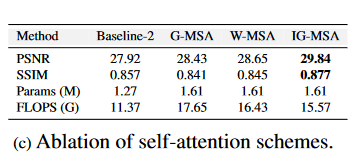
Self-Attention Scheme我们进行消融以研究自我注意计划的效果。结果报告在选项卡4c中。基线-2是通过从Retinexformer中去除IGMSA获得的。为了公平比较,我们插入全局MSA(G-MSA)由以前的CNN-Transformer混合方法转换为R的每个基本单元。G-MSA 的输入特征图缩小为 1/ 4 大小,以避免内存不足。我们还将我们的IG-MSA与Swin Transformer [31]提出的基于本地窗口的MSA(W-MSA)进行了比较。如表4c所示,我们的IG-MSA比G-MSA和W-MSA高出1.41和1.34 dB,而成本低2.08G和0.86G FLOPS。这些结果表明了拟议的IG-MSA的成本效益优势
class IG_MSA(nn.Module):
def __init__(
self,
dim,
dim_head=64,
heads=8,
):
super().__init__()
self.num_heads = heads
self.dim_head = dim_head
self.to_q = nn.Linear(dim, dim_head * heads, bias=False)
self.to_k = nn.Linear(dim, dim_head * heads, bias=False)
self.to_v = nn.Linear(dim, dim_head * heads, bias=False)
self.rescale = nn.Parameter(torch.ones(heads, 1, 1))
self.proj = nn.Linear(dim_head * heads, dim, bias=True)
self.pos_emb = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1, bias=False, groups=dim),
GELU(),
nn.Conv2d(dim, dim, 3, 1, 1, bias=False, groups=dim),
)
self.dim = dim
def forward(self, x_in, illu_fea_trans):
"""
x_in: [b,h,w,c] # input_feature
illu_fea: [b,h,w,c] # mask shift? 为什么是 b, h, w, c?
return out: [b,h,w,c]
"""
b, h, w, c = x_in.shape
x = x_in.reshape(b, h * w, c)
q_inp = self.to_q(x)
k_inp = self.to_k(x)
v_inp = self.to_v(x)
illu_attn = illu_fea_trans # illu_fea: b,c,h,w -> b,h,w,c
q, k, v, illu_attn = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.num_heads),
(q_inp, k_inp, v_inp, illu_attn.flatten(1, 2)))
v = v * illu_attn
# q: b,heads,hw,c
q = q.transpose(-2, -1)
k = k.transpose(-2, -1)
v = v.transpose(-2, -1)
q = F.normalize(q, dim=-1, p=2)
k = F.normalize(k, dim=-1, p=2)
attn = (k @ q.transpose(-2, -1)) # A = K^T*Q
attn = attn * self.rescale
attn = attn.softmax(dim=-1)
x = attn @ v # b,heads,d,hw
x = x.permute(0, 3, 1, 2) # Transpose
x = x.reshape(b, h * w, self.num_heads * self.dim_head)
out_c = self.proj(x).view(b, h, w, c)
out_p = self.pos_emb(v_inp.reshape(b, h, w, c).permute(
0, 3, 1, 2)).permute(0, 2, 3, 1)
out = out_c + out_p
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
class Illumination_Estimator(nn.Module):
def __init__(
self, n_fea_middle, n_fea_in=4, n_fea_out=3): #__init__部分是内部属性,而forward的输入才是外部输入
super(Illumination_Estimator, self).__init__()
self.conv1 = nn.Conv2d(n_fea_in, n_fea_middle, kernel_size=1, bias=True)
self.depth_conv = nn.Conv2d(
n_fea_middle, n_fea_middle, kernel_size=5, padding=2, bias=True, groups=n_fea_in)
self.conv2 = nn.Conv2d(n_fea_middle, n_fea_out, kernel_size=1, bias=True)
def forward(self, img):
# img: b,c=3,h,w
# mean_c: b,c=1,h,w
# illu_fea: b,c,h,w
# illu_map: b,c=3,h,w
mean_c = img.mean(dim=1).unsqueeze(1)
# stx()
input = torch.cat([img,mean_c], dim=1)
x_1 = self.conv1(input)
illu_fea = self.depth_conv(x_1)
illu_map = self.conv2(illu_fea)
return illu_fea, illu_map
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
主要的模块
class Denoiser(nn.Module):
def __init__(self, in_dim=3, out_dim=3, dim=31, level=2, num_blocks=[2, 4, 4]):
super(Denoiser, self).__init__()
self.dim = dim
self.level = level
# Input projection
self.embedding = nn.Conv2d(in_dim, self.dim, 3, 1, 1, bias=False)
# Encoder
self.encoder_layers = nn.ModuleList([])
dim_level = dim
for i in range(level):
self.encoder_layers.append(nn.ModuleList([
IGAB(
dim=dim_level, num_blocks=num_blocks[i], dim_head=dim, heads=dim_level // dim),
nn.Conv2d(dim_level, dim_level * 2, 4, 2, 1, bias=False),
nn.Conv2d(dim_level, dim_level * 2, 4, 2, 1, bias=False)
]))
dim_level *= 2
# Bottleneck
self.bottleneck = IGAB(
dim=dim_level, dim_head=dim, heads=dim_level // dim, num_blocks=num_blocks[-1])
# Decoder
self.decoder_layers = nn.ModuleList([])
for i in range(level):
self.decoder_layers.append(nn.ModuleList([
nn.ConvTranspose2d(dim_level, dim_level // 2, stride=2,
kernel_size=2, padding=0, output_padding=0),
nn.Conv2d(dim_level, dim_level // 2, 1, 1, bias=False),
IGAB(
dim=dim_level // 2, num_blocks=num_blocks[level - 1 - i], dim_head=dim,
heads=(dim_level // 2) // dim),
]))
dim_level //= 2
# Output projection
self.mapping = nn.Conv2d(self.dim, out_dim, 3, 1, 1, bias=False)
# activation function
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x, illu_fea):
"""
x: [b,c,h,w] x是feature, 不是image
illu_fea: [b,c,h,w]
return out: [b,c,h,w]
"""
# Embedding
fea = self.embedding(x)
# Encoder
fea_encoder = []
illu_fea_list = []
for (IGAB, FeaDownSample, IlluFeaDownsample) in self.encoder_layers:
fea = IGAB(fea,illu_fea) # bchw
illu_fea_list.append(illu_fea)
fea_encoder.append(fea)
fea = FeaDownSample(fea)
illu_fea = IlluFeaDownsample(illu_fea)
# Bottleneck
fea = self.bottleneck(fea,illu_fea)
# Decoder
for i, (FeaUpSample, Fution, LeWinBlcok) in enumerate(self.decoder_layers):
fea = FeaUpSample(fea)
fea = Fution(
torch.cat([fea, fea_encoder[self.level - 1 - i]], dim=1))
illu_fea = illu_fea_list[self.level-1-i]
fea = LeWinBlcok(fea,illu_fea)
# Mapping
out = self.mapping(fea) + x
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
这篇文章的实验做的比较充分,对比了大量的数据集,实验结果比较好,的确占的显存不大就可以跑,我用单张3090并没有跑出论文的实验结果