
- 1testbench仿真赋值时,为符合真实情况,时序逻辑应延迟一拍_vivado testbench延迟
- 2漏洞挖掘技术综述与人工智能应用探索:从静态分析到深度学习,跨项目挑战与未来机遇_机器学习与人工智能算法在超深基坑监测中的应用(1)
- 3HDFS读写流程(最新史上最详细)
- 4Java-序列化和反序列化_java序列化和反序列化
- 5yolov5旋转目标检测遥感图像检测-无人机旋转目标检测(代码和原理)_yolov5可以实现什么功能
- 6mysql学习--使用navicat查看数据库密码_navicat查看mysql密码
- 7C++操作xlsx初体验:OpenXLSX(建议使用)、libxl
- 8HarmonyOS应用开发者初级认证试题库(鸿蒙)_华为初级考试题库
- 9navicat连接MySQL数据库创建数据库的字符集和排序规则配置_用navicat运行sql文件时排列规则选什么
- 10layerNorm和batchNorm
基于Web日志的Web应用恶意用户行为异常检测(Anomaly Detection of Malicious Users Behaviors for Web Applications Based o)_基于主机日志的恶意登录异常检测方法研究
赞
踩
Anomaly Detection of Malicious Users Behaviors for Web Applications Based on Web Logs
基于Web日志的Web应用恶意用户行为异常检测
摘要:随着越来越多的在线服务发展成为web应用,基于web应用的安全问题也越来越严重。大多数入侵检测系统都是基于每一个请求来发现网络攻击,而不是用户行为,这些系统只能保护web应用程序免受已知漏洞的攻击,而不是一些零日攻击。为了检测新出现的攻击,我们对web服务器的web日志进行分析,定义用户行为,将用户行为分为正常行为和恶意行为。结果表明,利用web资源的特征定义用户行为,可以获得较高的入侵检测正确率和较低的误报率。
关键词:web日志;入侵检测;异常检测;用户行为;
1. 背景
(1)会议/刊物级别
Published in: 2017 IEEE 17th International Conference on Communication Technology (ICCT)
CCF None
(2)作者团队
高阳,马严:北京邮电大学网络技术研究院,北京,中国
(3)研究背景
目前,越来越多的在线服务(包括web页面)以及一些基于web服务的客户端应用程序使用HTTP协议进行开发。不幸的是,这些服务的漏洞也会迅速增加,因为用户可以向web服务器发送任何数据。[1]的一项调查显示,几乎84%的web应用程序有至少一个中等严重程度的漏洞,55%的web应用程序有至少一个高严重程度的漏洞。因此,有必要加强基于web服务的应用程序的安全性。当用户访问网站时,他们会遵循正常的行为模式,如单击超链接,提交表单或触发网页上的一些交互脚本。但是,恶意用户不这样做,而是利用攻击工具寻找服务器的漏洞,收集敏感的个人信息。一些系统管理员使用入侵检测系统(即IDS),如web应用程序防火墙,它可以设置特定的规则来拒绝包含某些特定字符串的请求,这些字符串被怀疑是恶意的,以保护他们的应用程序。
IDS一般分为误用检测和异常检测两类。误用检测方法使用预定义的攻击签名,通常是正则表达式来检测入侵。但是误用检测无法检测到新的攻击。异常检测通常是对合法用户的行为和系统进程的状态进行建模,而不是将正常的访问模型视为入侵。检测入侵有很多工作要做。研究[3]采用了一种混合入侵检测模型,该模型结合了误用检测和基于k-means算法的异常检测。研究[4]使用K-nearest neighbor classifier检测入侵。本文对机器学习技术在网络入侵检测中的应用进行了综述。作者[6]提出了一种无监督异常检测的聚类方法。
本文提出了一种基于用户行为分析模型的入侵检测方法。该模型的灵感来自于在线评级系统[7]的恶意行为检测。我们可以将常见的攻击按用户行为分为主动攻击和被动攻击两种类型。主动攻击是指攻击者使用扫描脚本来测试一些新发布的漏洞。被动攻击是指一些用户在访问网页时发现一些敏感信息,并利用这些信息构建恶意脚本进行攻击的攻击。主动攻击和被动攻击都可能对用户请求顺序产生显著影响。因此,我们关注用户行为,试图找出普通用户和恶意用户之间的区别。
2.相关工作
当用户访问网站时,足迹会以web日志的形式留在web服务器上。我们可以从web日志中提取用户的IP地址、用户的浏览器代理类型、响应时间、用户请求的web资源、状态码、响应的内容长度、请求的引用者等信息。图1显示了Nginx日志格式的一个例子,以及单个日志的实际一行。

本文收集了北邮一些学校的网站日志。这些网站使用Nginx做反向代理。该数据集包含4877个用户序列,这些序列是由3月16日收集的访问日志构建的。2017 - 20 th.mar。2017年总共5天。并从MACCDC2012[8]中下载52713条攻击日志,测试其检测率和虚警率。
2.1 请求参数
网站的日志每时每刻都在快速增长,每一行日志都有大量的信息,因此有必要对信息进行分析和标准化。因为我们选择IP地址和用户代理字段来识别特定的用户,所以我们使用其他字段来描述用户的行为。下面对Web资源、状态码、内容长度和referrer字段进行分析。
1)web资源
web上的所有内容都有一个标准化的名称,称为URL (Uniform Resource locator),因此如果我们考虑URL中的所有字符,web资源的特性可能并不重要。提取网络资源特征的方法有很多种。[9]研究将所有的数字和拉丁字母视为同一个字符。研究[10]使用一些特定的字符,如@来替换请求URL中的字符。本文在不丢失目录结构信息的前提下,使用不同的数字来替换数字、拉丁字母和不可显示字符。
2)状态码
HTTP状态码分为五大类[11]。但在实践中,我们不会使用整个HTTP状态代码集。在本文中,我们认为一些状态码是敏感的,如4xx码、5xx码,其余的状态码是不敏感的,我们认为它们是相同的,即它们具有相同的特征值。
3) 内容长度
内容长度是数字,但是,长度范围可能太大。我们将内容长度除以一些用户定义的变量来缩小长度的范围,这样我们就可以得到一个合理的长度范围。
4)referrer字段
HTTP请求中的referrer总是用来判断请求来自哪里。它也是一个URL,所以我们可以使用与计算web资源特征值相同的方法。
5) 用户序列
对于web应用,用户行为的描述是用户访问序列,即同一主机在特定时间窗口内发出的请求序列。我们选择IP地址和用户代理来识别不同的用户。也就是说,同一用户在同一时间段内具有相同的IP地址和用户代理。每个序列中的请求按响应时间排序。我们使用vectorܵ来定义用户序列。
3. 方法论
从每个日志中提取特征并计算特征值,构造每个用户序列,得到一个L X N 的用户特征矩阵来描述用户的行为。
3.1 描述用户行为的模型
用户的行为总是在合法范围内,这意味着行为几乎不会偏离常规。但恶意用户破坏了程序。因此,我们计算每个用户的行为熵,因为熵显示了分散或集中的程度。我们认为恶意用户具有较高的熵。我们使用熵方程(5)来计算它的熵,熵描述了用户的行为。
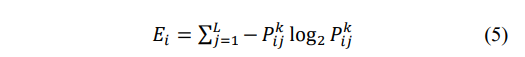
3.2 用户行为分类模型
不同的用户有不同的行为,我们可以应用kmeans技术对用户行为进行分类。K-means是数据挖掘中的一种无监督聚类分析方法,它通过减小每个向量到聚类中心的和距离来实现。K-Means算法因其复杂度低、处理速度快而被广泛应用于很多场合。但在使用k-means算法时也存在一些缺点,如初始化中心对最终结果有影响,且对异常数据敏感。但是,我们的目的是寻找异常数据,所以我们在研究[3]中对模型进行了修改,使其成为一个可以应用用户行为的模型。
所有用户行为可以聚集成k集群可以表示为C1, C2, C3…, CK。因为我们分类用户行为正常行为和恶意行为,所以将会有一个主要的集群,包括主要的用户行为和许多小集群远离主集群。利用式(6)计算点到簇中心的距离。我们用式(7)将每个点放置到最近的中心。
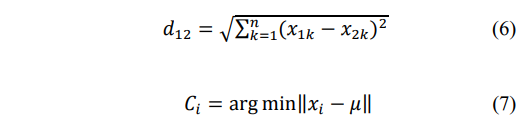
式(7)中的μ是聚类中所有点到中心的平均距离。
我们可以得到主簇的中心,计算出每个向量到主簇中心的距离。在距离的帮助下,我们可以设置一个阈值来确定它是否为攻击。
4. 实验结果
首先,我们使用熵作为3.2节中描述的k-means模型的特征值,计算不同用户到聚类中心的距离。图2显示了不同用户的不同特征到集群中心的距离。从图中可以看出,URL特性的距离远低于其他特性。因此我们选择URL特征来计算其误报率和检测率。
我们设置了不同的距离阈值来区分普通用户和恶意用户。结果如表一所示。我们可以看到,当距离在1.5到1.6之间时,检测率为100%,即12个恶意用户全部检测到,误报率为1.68%。当距离在1.7 ~ 2.0之间时,检测率为96.67%,即12个恶意用户中检测到11个,误报率为1.33%。

总而言之,当用户访问一个网页时,他们的输入比服务器的响应更容易得到恶意行为。因此,这意味着许多攻击特征对他们所请求的网络资源是重要的。
5.总结
本文在提取特征的基础上,对网络日志信息和用户行为信息进行分析。首先从日志中提取4个重要特征,构建用户访问序列进行用户行为建模。然后我们使用两种算法来检测基于用户行为的网络攻击。一种是简单的计算用户序列熵的方法,另一种是使用机器学习的方法对不同的用户行为进行聚类。最后,我们用实际数据集对该方法进行了测试,结果表明,该方法能够以较高的检测率和较低的虚警率发现恶意用户。
作为未来工作的一部分,许多恶意用户正在用人类正常的行为模式编写攻击工具的脚本。因此,发现恶意用户行为将更加困难。本文分析了一些重要的行为。随着恶意攻击工具的发展,入侵检测系统也需要不断的完善。

