
- 1git切换分支,并拉取最新的代码
- 2我的2020年总结_ldc账号分享
- 3LTE下行物理层传输机制(6)-下行资源分配方式(Resource Allocation Type)_lte 资源分配
- 4二维费用的背包问题(背包有体积和重量两个限制)_二维费用背包题目描述有 n 件物品和一个容量是 v 的背包,背包能承受的最大重量是
- 5精简指令集与复杂指令集
- 6静默安装Oracle gateway与多数据源SqlServer配置_oracle gateway 静默安装
- 7element ui logo 举例_南京ui交互设计培训
- 8小梅哥Xilinx ZYNQ学习笔记1——二选一多路器_小梅哥zynq
- 9FANUC机器人启动方式RSR和PNS的比较_rsr和pns的区别
- 10CPU架构简介(ARM、X86/Atom、MIPS、PowerPC)_power处理器架构
算法设计与分析基础知识点_算法设计与分析知识点
赞
踩
前言:全文参考徐承志老师的PPT
适合期末复习,查缺补漏,有缺漏或错误欢迎指正,后面的第九章内容之后会继续补充。
目录
(3)Dijkstra算法(迪杰斯特拉)(时间O(n^2)空间O(n))
一、算法基础概念
课程教学目的:计算机经常遇到的实际问题的解决方法,设计和分析各种算法的基本原理、方法和技术。
算法在计算机软件系统实现中处于核心地位。
数据结构:解决了数据的存放以及检索的问题
算法:解决了用数据结构解决实际问题的流程问题
算法的核心问题:时间、空间
算法的特性:有输入输出、有穷性、确定性、可行性
其它特性:正确性、健壮性、可理解性、抽象性、高效性、可维护性、可扩展性、简洁化、模块化等。
算法的描述方法:自然语言、程序流程图、伪代码、程序设计语言
程序和算法的区别
程序可以不满足算法的性质(有限性)
eg:操作系统是一个在无限循环中执行的程序,所以不是一个算法。
二、算法分析基础
1、概念
算法:在有限步骤内解一个数学问题的过程,步骤中常常包括某一操作的重复(韦氏词典)
解决一个问题或实现某一目标的逐步过程(广义)
算法是有穷规则的集合,规定了一个解决某一类特定类型的问题的运算序列(D.E.Kuth)
2、算法设计的一般过程
(1)算法设计步骤
- 理解问题
- 预测所有可能得输入(数据范围)
- 在精确解和近似解中做选择
- 确定数据结构
- 选择合适的算法策略
- 描述算法(写大纲)
- 分析算法的效率
- 根据算法编写代码
(2)复杂度分析
时间复杂度T(n)+空间复杂度S(n)(次要,硬件技术发展迅速,空间复杂度不需要过多考虑,够用)
(3)算法好坏考虑点
- 时间复杂度T(n)
- 空间复杂度S(n)
- 算法理解难度、编码难易程度、调试难度等
(4)影响程序运行时间的因素
- 输入
- 执行程序的计算机机器指令的性能和速度
- 算法的时间复杂度
3、时间复杂度
1、算法渐进复杂性态

eg:T(n)=40n^3+35n^2+10000n+8
算法渐进性态:T(n)=n^3
2、渐进符号
O---上界
Ω---下界
θ---精确界(上界和下界)
(1)大O符号

eg:n^2+10n=O(n^2)
根据O的定义,它有以下运算法则
- O(f)+O(g)=O(max(f,g));
- O(f)+O(g)=O(f+g);
- O(f)O(g)=O(fg);
- O(Cf(N))=O(f(N));//C是一个正的常数
- f=O(f);
2、 Ω---下界

eg:n^3+10n=Ω(n^2)
3、θ---精确界(上界和下界)

精确界是上界和下界相结合 =上界∩下界
补充: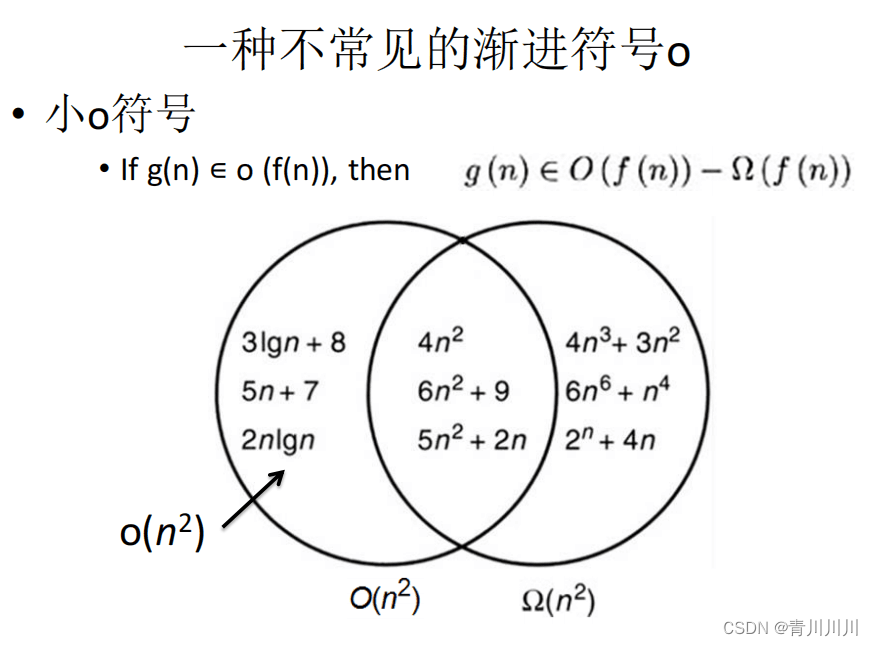
4、几种常见的时间复杂度,从小到大的顺序依次是:
θ(1)<θ(logn)<θ(sqrt(n))<θ(n)<θ(nlogn)<θ(n^2)<θ(n^3)
θ(2^n)θ(n!)
在多项式中,n的最高次质数最主要的决定因素,常数项,低次幂项和系数都是次要的。
4、时间复杂度分析基本规则
1、可执行语句的情况
- 输入、输出、赋值语句都为O(1)
- 顺序结构,采用渐进式O的规则来进行计算
- 选择结构,考虑板顶后所执行语句的执行时间O(max(T(s1),T(s2)))
- 循环结构,采用渐进式O的成绩规则来进行计算
- 复杂算法,先分割,然后采用渐进式O的求和规则和乘法规则来计算整个算法的时间复杂度
- 基本语句,对算法运行时间贡献最大的原操作语句
- 当算法时间复杂性只依赖于问题规模时,选择基本语句执行次数来作为运行时间T(n)建立的依据
2、时间复杂度的7条属性


5、空间复杂度
算法搜占用的储存空间包括:算法自身、输入输出、辅助空间(一般是与深递归相关,特殊情况:1、输入输出本身就带有复杂属性;2、辅助空间中有全局变量)
eg:插入排序需要多少辅助空间
-
- //插入排序
- void insert_sort(int n,int s[])
- {
- int a,i,j;
- for(i=1;i<n;i++)
- {
- a=s[i];
- j=i-1;
- while(j>=0&&s[j]>a)
- {
- s[j+1]=s[j];
- j--;
- }
- s[j+1]=a;
- }
- }

6、递归
1、定义
子程序(或函数)直接调用自己通过一系列调用语句直接或间接调用自己。
2、解题步骤
- 分析问题,找出递归关系
- 找出停止条件
- 构建函数体
3、说明
- 递归必须有终止条件,否则就是永不终止的自我调用
- 递归虽然比一般程序付出的代价高但是有很多数学问题的模型就是递归的。
- 递归优点:结构清晰、程序易读、正确性容易证明
- 递归缺点:运行效率低,花费时间多。
eg:n的阶乘n!{ 1 ,n=0; 停止条件
{n(n-1)! ,n>0; 递推关系
- Long Long func(int n)
- {
- if(n<0)
- {
- cout<<"illegal number!\n"<<endl;
- break;
- }
- else if(n==0)
- return 1;
- else
- return n*func(n-1);
- }
T(0)=1 /T (n)=T(n-1)+1 与直接循环计算比较

例题:一般的n都可以使用2^k来代替,方便计算

4、递归空间复杂度
递归的空间复杂度一般由递归的最大深度决定。
5、递归类型
(1)尾递归
- 定义:一个函数的所有递归形式的调用都出现在函数的末尾或者递归调用时整个函数体中最后执行的语句且它的返回值不属于表达式的一部分,这个递归就是尾递归。
- 特点:尾递归和一般递归的不同点在于对内存的占用,普通递归创建stack积累而后计算收缩,尾递归只会占用恒量的内存(和迭代一样)。
- //伪代码
- def tailrecsum(x,running_total);//第二个参数用来保存计算过程中的累加和
- if x==0;
- return running_total;
- else
- return tailresum(x-1,running_total+x);//内存没有变化,尾递归是吧变化的参数传递给递归函数的变量
(2)双递归
双递归函数Ackerman

6、递归算法的经典实例
---问题定义即为递归定义
- 阶乘(前面有代码)
- 斐波那契函数
- 杨辉三角取值
---问题应用递归算法解决
- 汉诺塔问题 (分治算法有详细介绍)
---部分数据结构也是用递归来定义的
- 树
斐波那契函数
- int fibonacci(int n)
- {
- if(m==1||n==2)//递归终止条件
- return 1;
- else
- return fibonacci(n-1)+fabonacci(n-2);//不断缩小问题规模
- }
杨辉三角
- int getValue(int a,int b)
- {
- if(y<=x&&y>=0)
- {
- if(y==0||x==y)//递归终止条件
- return 1;
- else
- return getValue(x-1,y-1)+getValue(x-1,y);//缩小问题规模,依次递归
- }
- }
三、蛮力法
1、定义
蛮力法(枚举法、穷举法、暴力法):依次处理所有元素,保证处理过的元素不再被处理
蛮力法一般观点:一般来说经过适度的努力都能一定程度上改良算法,改进算法的时间性能,但只能减少系数,数量级不会改变。
2、蛮力法优缺点
优点:
- 逻辑清晰、程序简洁
- 对于需要高正确性的问题(排序、查找、矩阵乘法、字符串匹配等),可以产生一些合理的算法(复杂度高)
- 实例少的问题,代价低
- 适用于规模较小,复杂度要求不高的问题
- 可以作为其它高效算法正确性衡量标准
缺点:效率低,复杂问题代价高
3、解题步骤
- 找出枚举范围(合理的情况)
- 找出约束条件,并用逻辑表达式表示。
4、常见使用蛮力法情况
- 搜索所有的解空间
- 搜索所有的路径
- 直接数学公式计算
- 模拟和仿真
eg:百鸡问题 :公鸡一只5元,母鸡3元,小鸡三只一元,用100元买100只鸡,问公鸡母鸡小鸡个数?
常规方法设公鸡母鸡小鸡的个数为a、b、c列方程求解
- //算法1
- void chicken(int n,int &k,int g[],int m[],int s[])//n为价钱和只数100,k相当于第几次循环在成功算出结果的时候循环结束,k为循环次数,数组gms储存循环结果最后输出正确的答案
- {int a,b,c;
- for(a=0;a<=n;a++)
- {
- for(b=0;b<=n;b++)
- {
- for(c=0;c<=n;c++)
- {
- if((a+b+c==n)&&(5*a+3*b+c/3==n)&&(c%3==0))
- {
- g[k]=a;
- m[k]=b;
- s[k]=c;
- k++;
- }
- }
- }
- }
- }
改进的百鸡问题
- //算法2
- void chicken(int n,int &k,int g[],int m[],int s[])
- {int i,j,a,b,c;
- k=0;
- i=n/5;//限制买了公鸡的范围减少循环次数
- j=n/3;//限制了买母鸡的范围减少循环次数
- for(a=0;a<=i;a++)
- {
- for(b=0;b<=j;b++)
- {
- c=n-a-b;
- if((5*a+3*b+c/3==n)&&(c%3==0))
- {
- g[k]=a;
- m[k]=b;
- s[k]=c;
- k++;
- }
- }
- }
- }
5、蛮力法例题
1、求a^n(n为非负整数)
(1)正常的使用蛮力法计算
- #include<iostream>
- using namespace std;
- double pow(double x, int n);
- int main()
- {
- int n = 4;
- double a = 1.3, s = 1;
- s = pow(a, n);
- cout << s << endl;
- return 0;
- }
- double pow(double x, int n)
- {
- double sum=1;
- for (int i = 0; i < n; i++)
- {
- sum = sum * x;
- }
- return sum;
- }

(2)快速幂(迭代法)

- #include<iostream>
- using namespace std;
-
- double fastExponent(double a, int b)
- {
- double ans = 1;
- while (b > 0)
- {
- if (b & 1)
- ans = ans * a;
- a = a * a;
- b >>= 1;
- }
- return ans;
- }
- int main()
- {
- cout << fastExponent(1.3, 4) << endl;
- return 0;
- }

2、查找问题中的蛮力法
思路:从数据集中依次评价筛选元素。
1、查找问题
- 1、找出枚举范围
- 2、找出约束条件,根据约束条件寻找正确的数据
eg:分数拆分/输入正整数k,找到所有的正整数x>=y,使得:1/k=1/x+1/y
思路:因为x>=y 所以1/x<1/y ;1/k<=1/y+1/y (这里把1/x换成了1/y);y<=2k
2、查找问题中的蛮力法--串的匹配


3、排序问题中的蛮力法
1、选择排序O(n^2)
- void SelectSort(int a[],int n)
- {
- int i,j,index,temp;
- for(i=0;i<n-1;i++) //最外层遍历
- {
- index=i;//无序区的第一位
- for(j=i+1;j<n;j++) //开始找无序区的最小元素
- if(a[j]<a[index] index=j; //记录最小值
- if(index!=i)
- {
- temp=a[i];a[i]=a[index]; a[index]=temp; //将最小值放到有序区中
- }
- }
- }
2、交换排序O(n^2)
- void exchangeSort(int n,int s[])
- {int i,j;//双循环
- for(i=0;i<n-1;i++)
- {
- for(j=i+1;j<n;j++)
- if(s[j]<s[i])
- s[i]<-->s[j];//交换顺序
- }
- }
3、插入排序O(n^2)
插入排序就是从第一个元素开始找有序数组,如果找到第n个数据发现不是按顺序的就插入到前面的有序数组里面。(就像给小朋友排队,先让他们随机站好一排,然后从第一个小朋友开始看,第一个不变,看第二个如果第二个比第一个高就不变,矮的话就让他插到第一个小朋友前面然后看第三个……以此类推……)
- void insertsort(int n,int s[])//将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增1的有序表
- {int i,j,x;//双循环
- for(i=1;i<n;i++)
- {x=s[i];
- for(j=i-1;j>=0&&s[j]>x;j--)
- s[j+1]=s[j];
- s[j+1]=x;
- }
- }
4、冒泡排序
代码1
- void Bubble(int n,int r[])
- {
- for(i=n-1;i>=1;i--)
- for(j=0;j<i;j++)
- if(r[j]>r[j+1])
- {
- int temp//交换顺序
- temp=r[j];
- r[j]=r[j+1];
- r[j+1]=temp;
- }
- }
- //伪代码
- void Bubble(int n,int r[])
- {
- exchange=n-1;//当循环到最后一个的时候exchange=0循环结束
- while(exchange)
- {
- bound =exchange;
- exchange=0;
- for(j=0;j<bound;j++)
- if(r[j]>r[j+1])
- {
- r[j]<-->r[j+1];//交换顺序,可以参考上面一个的代码
- exchange=j;
- }
- }
- }
4、0/1背包问题
直接暴力枚举,把所有的可能都写出来,然后选择最好的一组。
5、组合问题中的蛮力法
6、图问题中的蛮力法
补充:c++中实现字典序枚举方法(比较任意字符串。对于两个字符串,大小关系取决于两个字符串从左到右第一个不同字符的 ASCII 值的大小关系,从左往右依次增大)
- #include<iostream>
- #include<algorithm>
- using namespace std;
-
- int main()
- {
- int arr[5] = { 5,4,3,2,1 };
- sort(arr, arr + 5);
- do {
- for (auto a : arr)
- cout << a << ',';
- cout << endl;
- } while (next_permutation(arr, arr + 5));
- return 0;
- }

四、 分治法
1、思想:
将一个难以解决的大问题分解成规模较小的相同问题,逐个击破,分而治之。让复杂问题、耗时间的问题快速解决。
2、分治法的求解步骤
- 划分。把规模为n的原问题划分为k个规模较小的子问题,尽量使k个子问题的规模大致相同。
- 求解子问题。各个子问题的解决方法与原问题的解法通常是相同的,可以用递归或循环。
- 合并。把子问题的解合并起来,分治算法的有效性很大程度上依赖于合并的实现。
分治算法的求解步骤———递归模板
DivideConquer(P)
{ if(P的规模足够小)
直接求解P;
else
分解为k个子问题P1,P2,P3……Pk;
for(i=1;i<k;i++)
yi=DivideConquer(Pi);//i为下标
return Merge(y1,……yk);
}
3、分治法的复杂度
1、时间复杂度
子问题的输入规模大致相等且分为k份

例题:

2、空间复杂度

4、分治法适用条件
- 问题规模缩小到一定的程度就可以容易得解决
- 问题可以分解成若干个规模比较小的相同的问题,即该问题具有最优子结构性质
- 问题分解出的子问题的解是可以合并为该问题的解
- 问题所分解的子问题是相互独立的,即子问题之间不会有公共的子问题
2是使用分治法的前提;
能否使用分治法取决于第3条,如果具备12不具备3可以考虑贪心算法;
如果子问题不独立,虽然也可以使用分治法,但是一般都会使用动态规划法;
5、分治法例题
1、排序问题中的分治法
(1)二路归并排序(时间复杂度O(nlogn)/空间复杂度O(n))
先将待排序的元素分成两个大小大致相同的两个子序列,再用合并排序法对两个子序列递归的进行排序,最后将排好的子序列进行合并得到排序之后的序列。
- void Merge(int A[],int low,int middle,int high)
- {int i,j,k;
- int *B=new int[high-low+1];
- i=low;
- j=middle+1;
- k=0;
- while(i<=middle&&j<=high)//两个子序列非空
- if(A[i]<=A[j]) B[k++]=A[i++];
- else B[k++]=A[j++];
- while(j<=middle)B[k++]=A[i++];
- while(j<=high) B[k++]=A[j++];
- k=0;
- for(i=low;i<=high;i++)A[i++]=B[k++];
-
- }
递归算法
- void MergeSort(int A[],int low,int high)
- {
- int middle;
- if(low<high)
- {
- middle=(low+high)/2;
- MergeSort(A,low,middle);
- MergeSort(A,middle+1,high);
- MergeSort(A,low,middle,high);//合并
- }
- }
(2)快速排序(O(nlogn))
将待排序的元素分割成独立的三个序列:第一个序列所有的元素均不大于基准元素、第二个序列是基准元素、第三个序列中所有元素均不小于基准元素。
基准元素的选取:
- (a)取第一个元素。
- (b)取最后一个元素。
- (c)取位于中间位置的元素。
- (d)上述三者取中。
- (e)取位于low和high之间的随机数。
算法描述:
- void QuickSort(int R[ ],int low,int high)
- { int pivotpos;
- if(low<high)
- { pivotpos=Partition(R, low, high);
- QuickSort(R, low, pivotpos-1);
- QuickSort(R, pivotpos+1, high);
- }
- }
快速排序的其它应用:有n个不同的奇数,找中位数;查找第K大的数;
(3)全排列(O(n!))
对n个元素进行全排列,转换成n组n-1个元素进行全排列

- void perm(int list[],int k,int m)//普通的全排列,k是起始下标,m是终止下标
- {
- int i;
- if(k==m)//如果起始下标等于终止下标,直接输出list[i]
- {
- for(i=0;i<=m;i++)
- cout<<list[i]<<endl;
- }
- else{
- for(i=k;i<=m;i++){
- swap(&list[k],&list[i]);//交换顺序
- perm(list,k+1,m);
- swap(&list[k],&list[i]);//交换顺序
- }
- }
- }
按照字典序排列(比较任意字符串。对于两个字符串,大小关系取决于两个字符串从左到右第一个不同字符的 ASCII 值的大小关系,从左往右依次增大)

算法描述
- void perm(int list[],int k,int m)//普通的全排列,k是起始下标,m是终止下标
- { int i;
- if(k==m){ //只有一个元素直接输出list[i]
- for(i=0;i<=m;i++)
- cout<<list[i]<<endl;
- }
- else{
- for(i=k;i<=m;i++){
- putAhead(list,k,i);
- perm(list,k+1,m);
- restore(list,k,i);
- }
- }
-
- }
(4)部分全排序
从m个元素之中选出n个元素进行全排列。
(5)组合问题中的分治法
棋盘覆盖问题


算法实现:

五、贪心算法
1、概念:
(1)基本概念
贪心算法:每一步在一组内选择最好的一个解-->优化解(不一定有,而且需要证明)
贪心算法解决的问题必须有最优子结构、贪心选择性质、局部优化选择
(2)解题步骤
- 分解:将原问题分解为若干个互相独立的阶段
- 解决:对每个阶段依据贪心策略进行谈薪选择,求出局部最优解
- 合并:将各个阶段的解合并为原问题的一个可行解
证明:1、先证明最优子结构性质
2、利用最优子结构证明贪心选择性
eg:会场安排问题
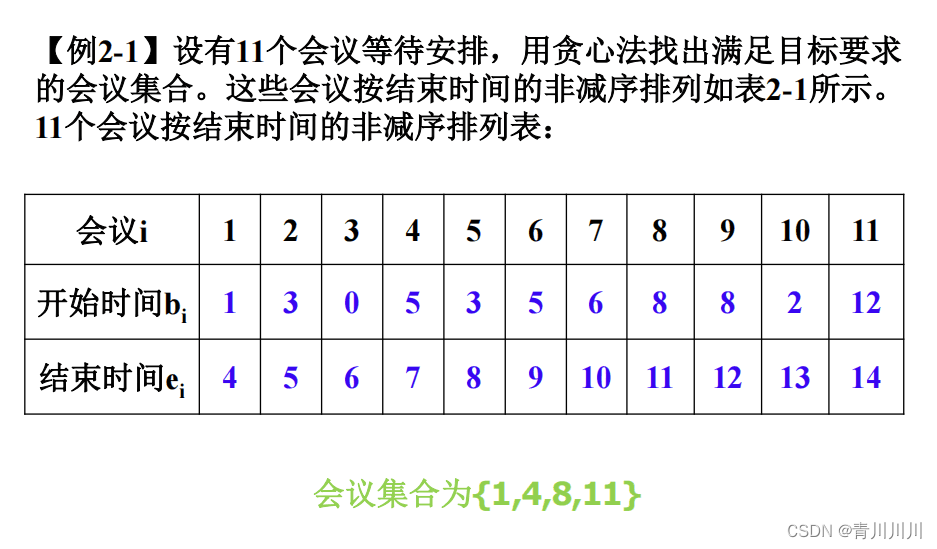
设一共有n个活动,活动集合S={1……n},场地不能够两个活动同时举办,设活动i的活动时间为Si到Fi,要求活动时间[Si,Fi),即活动i、j必须满足条件Si>=Fj,Sj>=Fi;
根据贪心算法,它会选择最早开始且时间最短的活动,第一次选一个安排好,后再用同样的思想选择第二个第三个……第n个。
(3)Dijkstra算法(迪杰斯特拉)(时间O(n^2)空间O(n))
算法:它先求出长度最短的一条路径,再参照这个最短路径求出长度第二短的一条路径,直到求出从源点到其它各个顶点的最短路径。
算法设计:

最小生成树:G=(V,E)的子图是一棵包含G的所有顶点消耗最小的生成树。
(4)Prim算法(普利姆)
算法:在无向连通带权图G的若干个真子集中寻找权值最小的边,并且这些边能构成G的一棵最小生成树

(5)Kruskal算法(克鲁斯卡尔)
算法:G(V,E)是无向连通带权图,Kruskal算法开始是只有n个顶点,然后贪心选择权最小的,如果不是连通的就继续选择第二短的边,直到连通,找到最小生成树。
设计关键:避开环路,Kruskal算法使用集合的性质进行判断,如果所选择的边和起点在同一个连通的分支里面,那就是一定有一个回路。(集合的性质,如果两点在一个集合内,就是包含关系,那么映射到图上就是包含的关系,就是连到了一起形成了回路)

Prim和Kruskal算法的比较
(1)从算法的思想可以看出,如果图G中的边数 较小时,可以采用Kruskal,因为Kruskal算法每次 查找最短的边;边数较多可以用Prim算法,因为它是每次加一个顶点。可见,Kruskal适用于稀疏图, 而Prim适用于稠密图(2)从时间上讲,Prim算法的时间复杂度为O(n2 ),Kruskal算法的时间复杂度为O(eloge)。
(6)哈夫曼编码
算法:任何字符的编码都不能是其它字符编码的前缀,否则编译会产生二义性。所以提出了编码树的概念(二叉树叶子结点左0右1)。保证这样的编码树的总长度最短的算法叫做哈夫曼算法。

- 采用无序的线性结构实现的算法,它的复杂度性为O(n^2)。
- 算法的改进:采用有序的线性结构实现,它的复杂性为O(nlogn)。
2、图问题中的贪心算法
(1)TSP问题
TSP问题是指旅行家要旅行n个城市,要求各个城市都经过且只经过依次,然后回到出发城市,求所走的最短路程。
想法:
- 最近邻点策略:任意城市出发,每次在没有经过的城市选择最近的城市旅游,最后回到出发城市。
- 最短链接策略:每次在所有的城市的距离中选择最短的加入计划路线,如果不能形成回路选第二短的,以此类推,最后形成哈密顿回路(只经过一个点一次的回路)。
(2)图着色问题
给定无向连通图 G =( V , E ) ,求图 G 的最小 色数k ,使得用 k 种颜色对 G 中的顶点着色,可 使任意两个相邻顶点着色不同。
3、组合问题中的贪心算法
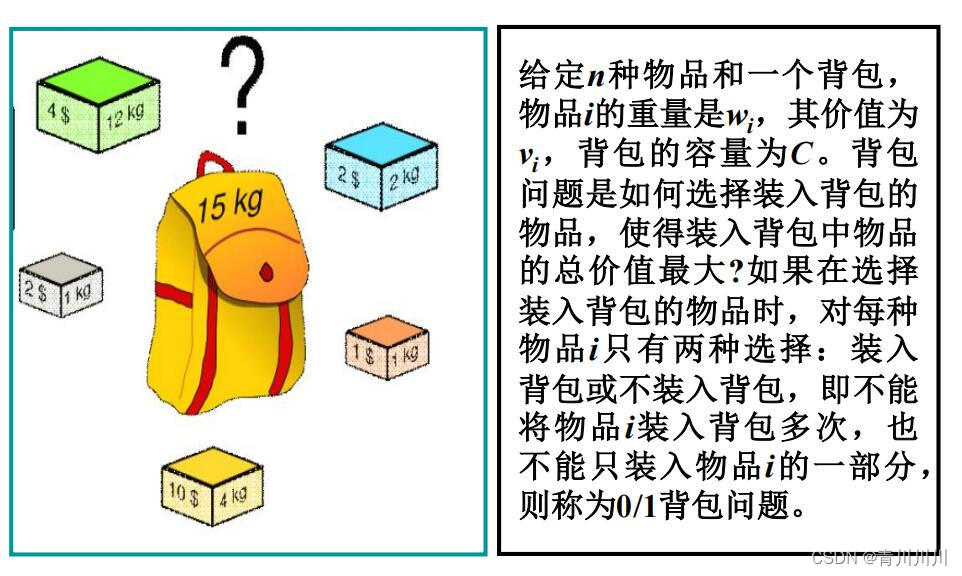
(1)0/1背包问题
给定 n 种物品和一个容量为 C 的背包,物品 i 的 重量是 w i ,其价值为 v i ,背包问题是如何选择装入 背包的物品,使得装入背包中物品的总价值最大 ?

补充: 回文串,是一种特殊的字符串,它从左往右读和从右往左读是一样的。现在给你一个串,它不一定是 回文的,请你计算最少的交换次数使得该串变成一 个完美的回文串,如果无法完成就输出impossible。
交换的定义是:交换两个相邻的字符
六、动态规划法(DP)
1、基本概念
(1)基本概念
动态规划法:将原问题分解成若干个子问题,子问题可以重复,重复子问题求解会保存,后面可以直接使用。
动态规划法核心在于填表,,表填写完毕,最优解也就能找到。
(2)动态规划的基本性质
最优子结构性质-->在某种意义下的最优解
子问题的重叠性
自下向上的求解方式
(3)动态规划的设计思想

(4)动态规划的求解过程
- 划分子问题:将原问题划分为若干个子问题,每个子问题对应一个决策阶段,子问题之间具有重叠性
- 确定动态规划函数/状态转换函数:根据子问题之间的重叠关系找到子问题满足的递推关系式。
- 填写表格:设计表格,以自底向上的方式计算各个子问题的解并且填表,实现动态规划的过程。
(5)动态规划法与DAG的映射

eg:迭代fibonacci就是一维结构的DP(动态规划法)


2、图问题中的动态规划法
(1)最大子段和问题

该问题有很多解法:

当序列中所有整数均为负整数时,其最大子段和为0。
3、组合问题中的动态规划法
(1)最长公共子序列问题
基本概念( 1 )子序列给定序列 X={x 1 , x 2 , …, x n } 、 Z={z 1 , z 2 , …, z k } ,若 Z 是 X 的子 序列,当且仅当存在一个严格增的下标序列 {i 1 , i 2 , …, i k } , 对 j ∈ {1, 2, …, k} 有 z j =x i j 。( 2 )公共子序列给定序列 X 和 Y ,序列 Z 是 X 的子序列,也是 Y 的子序列,则称 Z 是 X 和 Y 的公共子序列。( 3 )最长公共子序列包含元素最多的公共子序列即为最长公共子序列。

算法设计:

eg:实例
给定序列 X={A, B, C, B, D, A, B} 和 Y={B,D, C, A, B, A} ,求它们的最长公共子序列。1. m=7 , n=6 ,将停止条件填入数组 c 中,即 c[i][0] = 0, c[0][j]=0 ,其中 0≤i≤m , 0≤j≤n 。2. 当 i=1 时, X 1 ={A} ,最后一个字符为 A ; Y j 的规模从 1 逐 步放大到 6 ,其最后一个字符分别为 B 、 D 、 C 、 A 、 B 、 A ;3. 依此类推,直到 i=7


填表的时候如果它的值相等就指向上面,不相等指向大的那个,如果行列对应的字母相等的话就赋左上那个数的值+1
算法:
- int CommonOrder(char x[],int m,char y[],int n,char z[])
- {
- int i,j,k;
- for(j=0;j<=n;j++)
- L[0][j]=0;
- for(i=0;i<=mi++)
- l[i][0]=0;
- for(i=1;i<=m;i++)
- for(j=1;j<==n;j++)
- if(x[i]==y[j]){L[i][j]=L[i-1][j-1]+1;s[i][j]=1;}
- else if(L[i][j-1]>=L[i-1][j]){
- L[i][j]=l[i][j-1];S[i][j]=2;
- }
- else{L[i][j]=L[i-1][j];S[i][j]=3;}
- i=m;
- j=n;
- k=L[m][n];
- while(i>0&&j>0){
- if(S[i][j]==1){z[k]=x[i];k--;i--;j--;}
- else if(s[i][j]==2) j--;
- else i--;
- }
- for(k=0;k<L[m][n];k++)
- cout<<z[k];
- return L[m][n];
- }
(2)0/1背包问题






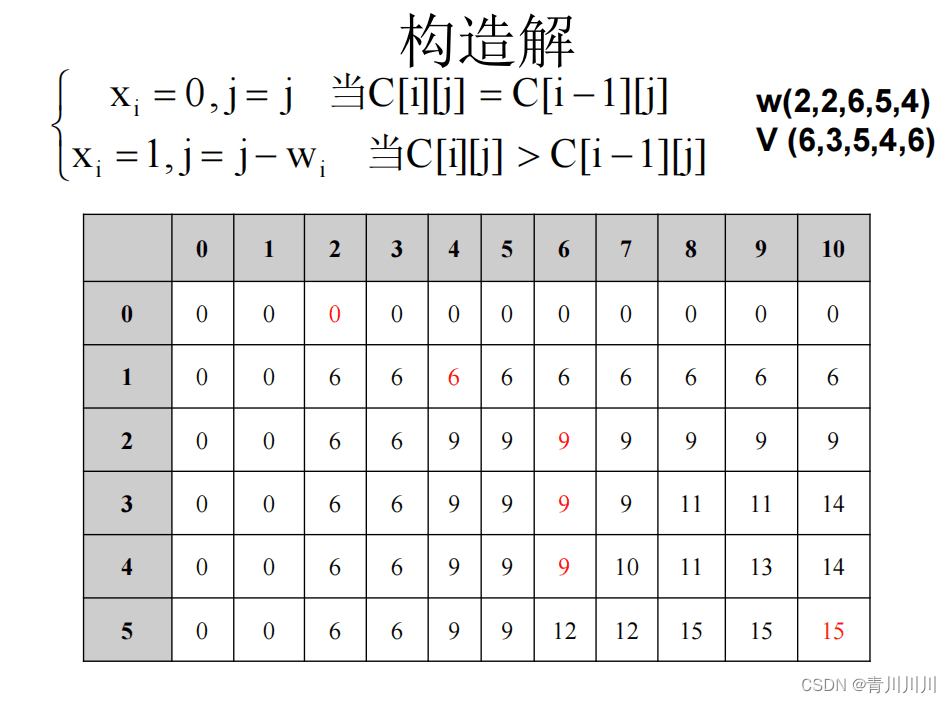

4、小结
(1)适用条件
(2)与其它算法比较
七、回溯法
1、基础概念
(1)回溯法概念:
实际上是一种试探算法,从根节开始一步一步的试探,如果当前的情况不满足需求,就停止,换下一个。
(2)回溯法的算法框架及思想
- 明确搜索范围(定义问题的解空间)。解的形式、范围、空间大小、
- 确定解空间的组织结构。树或者图
- 搜索解空间(隐约束)。题干中显示的约束条件(可行解)、题干中隐藏的限界条件(最优解)
用约束函数剪去不满足约束的子树
用限界函数剪去得不到最优解的子树
(3)深度优先搜索
- bool Visited[n+1]; //标记图中顶点是否被访问过
- for(int i=1;i<=n;i++)
- Visited[i]=0; //用0表示顶点未被访问过
- //从顶点k出发进行深度优先搜索
- Dfsk(int k)
- { Visited[k]=1; //标记顶点k已被访问过
- for(int j=1; j<=n; j++)
- if(c[k][j]==1 && Visited[j]==0) //c[][]是邻接矩阵
- Dfsk(j);
- }
- //深度优先搜索整个图G
- Dfs( )
- { for(int i=1; i<=n; i++)
- if(Visited[i]==0)
- Dfsk(i);
- }
(4)几个名词
- 扩展结点:一个能够产生儿子的结点称为扩展结点
- 活结点:一个自身已生成但其儿子还没有全部生成的节点称做活结点
- 死结点:一个所有儿子已经产生的结点称做死结点
- 搜索树:搜索过程中动态形成的树
2、回溯法递归/非递归模板
(1)递归
- void Bcktrack(int t)
- { if(t>n) //另一种写法是 if( solution(t) ),即可能提前结束
- output(x);
- else
- for(int i=s(n,t);i<=e(n,t);i++) //只是比喻遍历
- { x[t]=d(i); //只是比喻
- if( constraint(t) && bound(t) ) //只是比喻
- Bcktrack(t+1);
- ......//一般这里有“还原”操作,因为x是全局的,
- /*不会在递归结束后还原,如果X是局部变量,就不需要“还原”操作,但是随着递归的深入,
- 局部变量会占据大量内存,所以大多数情况下用全局变量保存X。*/
- }
- }
(2)非递归
- void NBacktrack( )
- { int t=1;
- while(t>0)
- { if( s(n,t)<=e(n,t) ) //只是表明当前是活节点
- for(int i=s(n,t);i<=e(n,t);i++)
- { x[t]=d(i);
- if( constraint(t) && bound(t) )
- if(t>n) output(x); //另一种写法是 if(solution(t))
- else
- t++; //进一步搜索
- }
- else
- t--; //此处省略了改变上层s(n,t)和e(n,t)的语句
- }
- }
3、子集树问题(组合问题)
(1)问题
(2)子集树实例
 (3)子集树递归模板
(3)子集树递归模板
模板1
- void Bcktrack(int t)
- { if(t>n)
- output(x);
- else
- for(int i=1;i>=0;i--)
- { x[t]=i;
- if( constraint(t) && bound(t) )
- Bcktrack(t+1);
- … //一般这里有“还原”操作,因为x是全局的,
- 不会在递归结束后还原
- }
- }
模板2
- void Backtrack (int t)
- { if (t>n) output(x);
- if( constraint(t) && bound(t) ) //判断能否有分支进行扩展
- { 做相关标识的设置;
- Backtrack(t+1);
- 做相关标识的还原;
- }
- if(constraint(t) && bound(t) ) //判断能否有分支进行扩展
- { 做相关标识的设置;
- Backtrack(t+1);
- 做相关标识的还原;
- }
- }
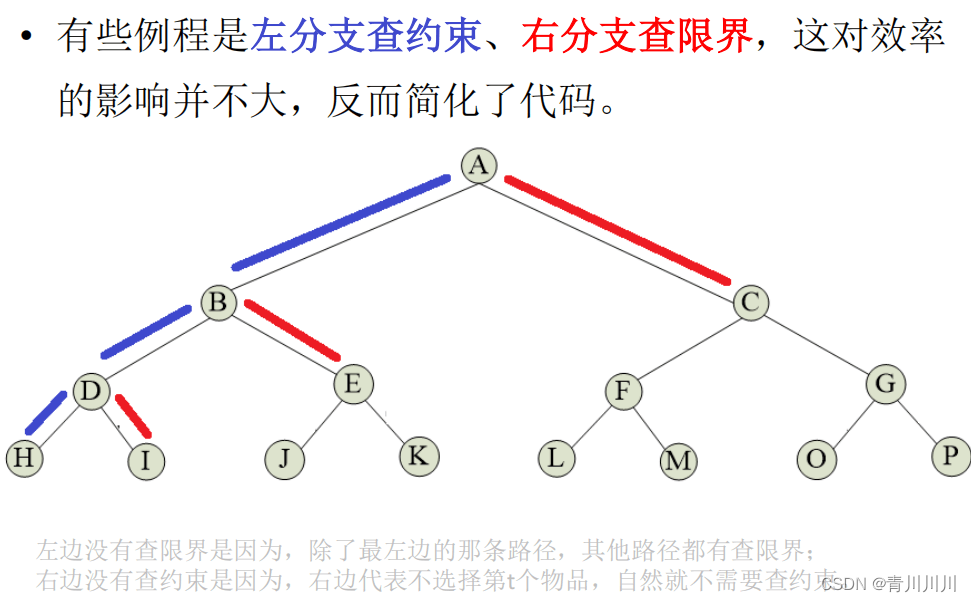
4、排序问题
排列树

5、M选择问题
(1)满m叉树
• 当所给问题的 n 个元素中每一个元素均有 m 种 选择,要求确定其中的一种选择,使得对这n 个元素的选择结果组成的向量满足某种性 质,即寻找满足某种特性的n 个元素取值的一种组合。这类问题的解空间树称为满m 叉树。• 解的形式为 n 元组(x1 ,x 2 ,……,x n), 分量xi (i=1,2,……,n) 表示第 i 个元素的选择为xi

满m叉树问题算法模板
- void Backtrack (int t)
- { if (t>n)
- output(x);
- else
- for (int i=1;i<=m;i++)
- if ( constraint(t) && bound(t) )
- { x[t]=i;
- 做其他相关标识;
- Backtrack(t+1);
- 做其他相关标识的反操作;//退回相关标识
- }
- }
6、回溯法效率分析
7、三类问题的时间复杂性
八、分支限界法
1、基础概念
(1)分支限界法
从根开始,以宽度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树,首先将根结点加入活结点表(用于存放活结点的数据结构),然后取出活结点成为扩展结点,一次性生成它所有结点的孩子,不符合条件舍弃,其余的保存在活结点表内,之后一直重复,直到找到所需的解或者活结点表为空。
(2)宽度优先搜索
先访问下一层所有的孩子结点,然后才会继续搜索下一层。
- bool Visited[n+1]; //标记图中顶点有未被访问过
- for(int i=1;i<=n;i++) Visited[i]=0; //所有顶点未被访问过
- InitQueue(&Q); //初始化空队
- void BFSV0 (int v0) //从v0开始广度优先搜索所在的连通子图
- { visit(v0); Visited[v0]=1;
- InsertQueue(&Q,v0); // v0进队
- while (! Empty(Q))
- { DeleteQueue(&Q, &v); //队头元素出队
- for(int i=1;i<=n;i++) //依次访问v的邻接点
- { if(g[v][i]!=0) w=i;
- if (!Visited(w)) //此处可以加上约束和限界
- { visit(w); Visited[w]=1;
- InsertQueue(&Q, w);
- }
- }
- }
- }
(3)分类(根据活结点表的维护方式)
- 队列式分支限界法
- 优先队列式分支限界法
(4)步骤
- 定义问题的解空间
- 确定问题的解空间组织结构(树/图)
- 搜索解空间。搜索前要定义判断标准(使用约束函数/限界函数),如果使用优先队列式分支限界法,必须先确定优先级。
2、队列式分支限界法

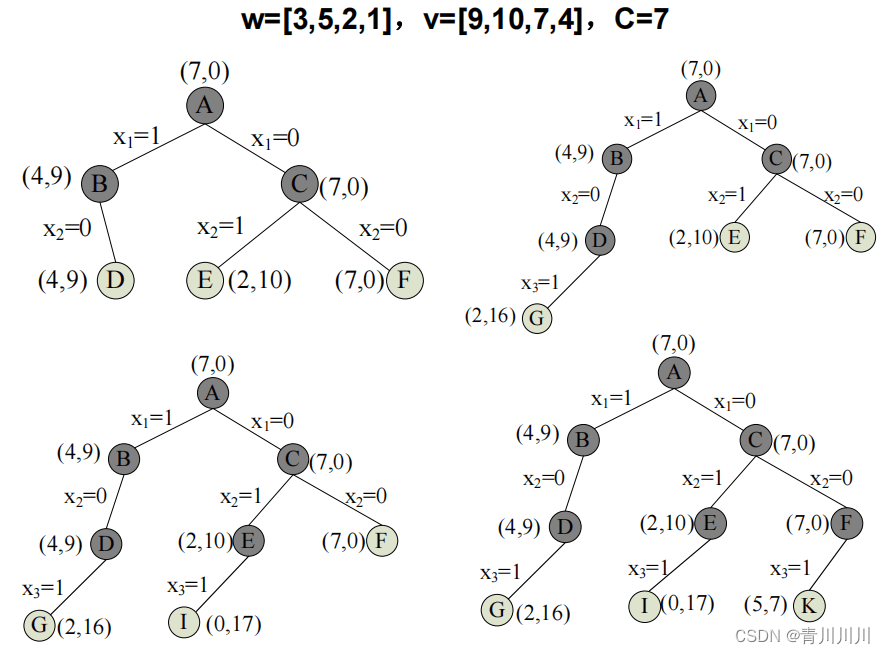
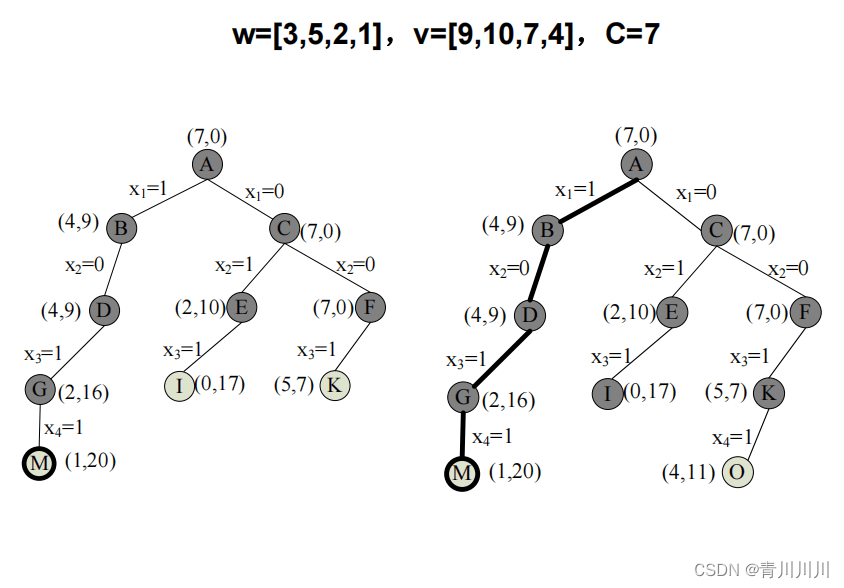
3、优先队列式分支限界法
• 优先级:活结点代表的部分解所描述的装入背包的物品价值上界,该价值上界越大,优先级越高。活结点的价值上界up=cp+rp'。• 约束条件:同队列式• 限界条件:up=cp+rp'>bestp
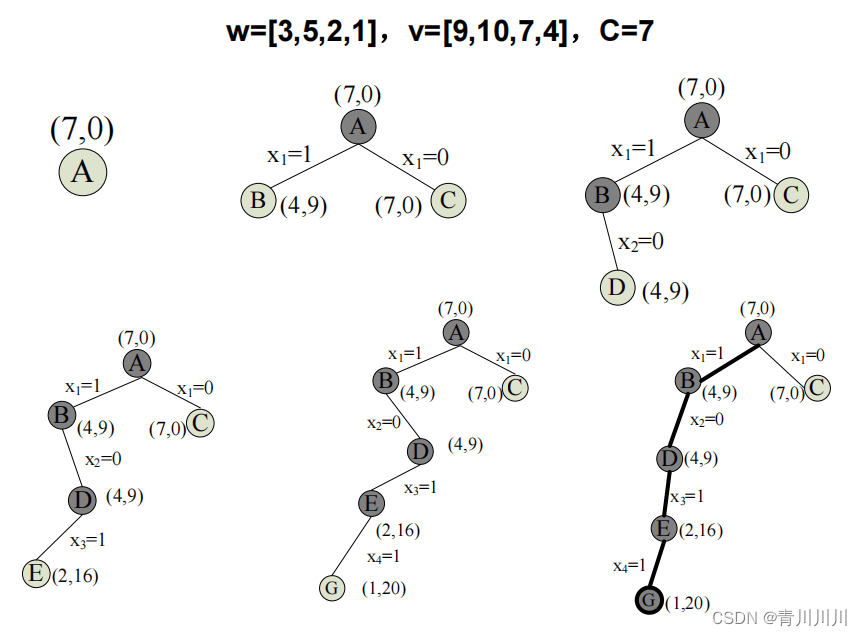
算法描述:
- while (i != n+1)
- { wt = cw + w[i];
- if (wt <= c)
- { if (cp+p[i] > bestp) bestp = cp+p[i]; //左子树
- AddLiveNode(up, cp+p[i], cw+w[i], true, i+1);
- }
- up = Bound(i+1);
- if (up > bestp) //右子树
- AddLiveNode(up, cp, cw, false, i+1);
- /*注意这个函数AddLiveNode,
- 是往队列里加入一个结构体Node。这个结构
- 体包含了当前节点的前序操作的所有历史信息。
- 因为只有知道了所有前序操作,才能进行约束
- 判断与限界判断*/
- //取下一个扩展节点
- ……
- }
4、分支限界法与回溯发的比较
(1)相同点
- 均需要先定义问题的解空间,确定的解空间组织结构一般都是树或图。
- 在问题的解空间树上搜索问题解。
- 搜索前均需确定判断条件,该判断条件用于判断扩展生成的结点是否为可行结点。
- 搜索过程中必须判断扩展生成的结点是否满足判断条件,如果满足,则保留该扩展生成的结点,则舍弃。
(2)不同点
- 搜索目标:回溯法的求解目标是找出解空间树中满足约束条件的所有解,而分支限界法的求解目标通常是找出满足约束条件的一个解,或是在满足约束条件的解中找出在某种意义下的最优解。(这条说法不准确)
- 搜索方式不同:回溯法以深度优先的方式搜索解空间树,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树,因此需要更复杂的数据结构。
- 扩展方式不同:在回溯法搜索中,扩展结点一次生成一个孩子结点,而在分支限界法搜索中,扩展结点一次生成它所有的孩子结点(所以需要额外定义一个数据结构来保存结点的历史状态)
- 如果每层的分支数目过多,则不适合用分支限界,因为存在大量候选节点,且每个节点要保持历史选择,会造成活结点表空间暴涨。
九、随机算法/概率算法
1、基本概念
(1)类型
(2)特点
- 数值随机化算法常用于求数值解(对应的是:求解析解),所得到的解往往都是近似解,而且近解的精度随计算时间的增加不断提高。
- 蒙特卡罗算法能求得问题的一个解,但这个解未必是正确的。求得正确解的概率依赖于算法执时所用的时间,所用的时间越多得到正确解的概率就越高。一般情况下,蒙特卡 罗算法不能有效地确定求得的解是否正确。
- 拉斯维加斯算法不会得到错误解,一旦找到一个解,那么这个解肯定是正确的。但是有时候拉维加斯算法可能找不到解。拉斯维加斯算法得到正确解的概率随着算法执行时间的增加而提高。
- 舍伍德算法不会改变对应确定性算法的求解结果,每次运行都能够得到问题的解,并且所得到解是正确的,但是能改善时间复杂度的实际感受。
2、 n皇后问题
- bool Queen::QueensLV( )
- { RandomNumber rnd;
- int k=1; //下一个放置的皇后编号
- int count=1; //第k个皇后在第k行的有效位置数
- while((k<=n)&&(count>0))
- { count=0;
- for(int i=1;i<=n;i++)
- { x[k]=i;
- if(Place(k))
- //第k个皇后在第k行的有效位置存于y数组
- y[count++]=i;
- }
- //从有效位置中随机选取一个位置放置第k个皇后
- if(count>0)
- x[k++]=y[rnd.Random(count)];
- }
- return (count>0); //count>0表示放置成功
- }
- 先判断,再
- 随机放置
- bool Queen::QueensLV1(void)
- { RandomNumber rnd; //随机数产生器
- int k=1; //下一个放置的皇后编号
- //尝试产生随机位置的最大次数,用户根据需要设置
- int count=maxcout;
- while(k<=n)
- { int i=0;
- for(i=1;i<=count;i++)
- { x[k]=rnd.Random(n)+1;
- if(Place(k))
- break; //第k个皇后在第k行的有效位置存于y数组
- }
- if(i<=count)
- k++;
- else
- break;
- }
- return (k>n); //k>n表示放置成功
- }
十、NP完全理论
(1)难解问题分类
难解问题分为两类:不可判定问题和非决定的难处理问题
(2)基本概念
不可判定问题(不存在求解算法的问题)
- 图灵停机问题 :编译器用来判定程序是否会进入死循环/反证法
- 波斯特对应问题(Post correspondence problem)
- 某些形式语言的word problem
- 决定王氏砖块是否能铺满平面
- 判断标记系统是否停机
- 计算某个字符串的柯氏复杂性
- 希尔伯特第十问题:决定不定方程(又称为丢番图方程)的可解答性。
- 决定上下文有关语言会否生成对应字母表的所有字符串; 或判断其是否有歧义。
- 两个上下文有关语言能否生成同样的字符串,或一个语言生成另一个语言生成的子集,或是否有某个字符串两个语言都生成。
- 给予一个为初始点的有理坐标是周期性,决定位于basin of attraction是否开集,或是否在平分线函数迭代为两个纲比或三个纲比。
- 决定Λ演算方程是否有正则形式。
- …… 病毒检测也是不可判定的。
(3)问题
1、P类问题
定义1:一个算法每一步只有一个确定选择(一个输入对应一个输出),称这个算法为确定性算法。
定义2: 如果对于某个判定问题 ∏’ 存在一个非负整数k,对于输入规模为n的实例,能够以O(nk )的时间运行一个确定性算法,得到是或否的答案,则该判定问题 ∏’ 是一个P类问题(polynomial:多项式的)。
2、NP类问题
定义 3 :设A是问题 ∏ 的一个算法,如果以如下两阶段工作,则称为 不确定算法 。
★定义 4 :如果对于某个判定问题,存在一个非负整数 k ,对于输入规模为n 的实例,能够以 O(n k ) 的时间运行一个 不确定算法 ,得到是或否的答案,则该判定问题是一个 NP 类问题。
3、P类问题和NP类问题的关系
P类问题和NP类问题主要区别在于算法的确定性和不确定性。

4、问题变换与计算复杂性归约
假设问题 Π' 存在一个算法 A ,对于输入实例 I'得到一个输出O',另外一个问题Π 的输入实例是 I ,对应有一个输出 O,则问题Π变换到问题 Π'是一个三步的过程:1. 输入转换:把问题 Π 的输入 I 转换为问题 Π' 的适当输入 I';2. 问题求解:对问题 Π' 应用算法 A 产生一个输出 O ';3.输出转换:把输出 O' 转换为问题Π的正确输出 O 。
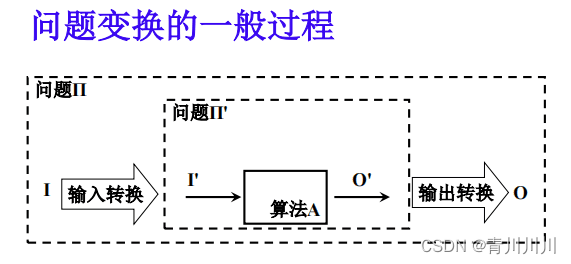
问题变换的主要目的不是给出解决一个问题的算法,而是通过另一个问题理解当前问题的计算时间上下限的一种方式。(相当于用另一个问题来计算要求解的问题的解范围)
5、NP完全问题(NPC)
- NP完全问题是NP类问题的一个子类
- NP完全问题的特性
★定义 5 :令 ∏ 是一个判定问题,如果:– (1) ∏ ∈ NP ,即问题属于 NP 类问题– (2) 对 NP 中的所有问题 ∏ ’ 都有 ∏ ’ ∝ p ∏ 则称该判定问题是一个NP 完全问题,简记为 NPC 。

(4)扩展
1、典型的NP完全问题
2、NP完全问题的计算机处理
3、NP完全问题的近似解法

4、 空间复杂性简介
P-SPACE 定义: 如果问题 Π 存在一些算法,使得它的 运算能被限制在以输入长度大小的多项式为界的空间 内进行,则称 Π 为 P 空间的问题。P-SPACE 完全 定义: 如果某问题是 P-SPACE 的, 并且所有其它 P-SPACE 的问题都可多项式变换到 它,则称它为 P-SPACE 完全的


