
- 1超实用的30个 Python 案例,建议收藏_python学习案例
- 2Python小白(python数据分析与可视化)从入门到精通_python小白(python数据分析与可视化)从入门到精通-csdn博客
- 3meanshift算法图解以及在图像聚类、目标跟踪中的应用_灰度图像聚类算法
- 4深度学习算法中的深度强化学习(Deep Reinforcement Learning)_deep reinforcement learning for strate
- 5Logback快速实践_ch.qos.logback.core.rolling
- 6微信小程序使用wxs实现购物车贝塞尔曲线_小程序贝塞尔曲线广告
- 7数据结构试卷及答案(七)
- 8Linux和Hadoop常用命令操作_linux删除hdfs中的文件命令
- 9后台语言返回的二进制流音频文件在微信浏览器兼容性问题_html5的audio标签播放二进制文件流
- 10树的高度与深度
【http】协议/域名/url/请求和响应/状态码/重定向
赞
踩
0.应用层协议
协议是一种 “约定”. socket api的接口, 在读写数据时, 都是按 “字符串” 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢?
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端.
约定方案一:
客户端发送一个形如"1+1"的字符串;
这个字符串中有两个操作数, 都是整形;
两个数字之间会有一个字符是运算符, 运算符只能是 + ;
数字和运算符之间没有空格;
…
约定方案二:
定义结构体来表示我们需要交互的信息;
发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
这个过程叫做 “序列化” 和 “反序列化”
- 无论我们采用方案一, 还是方案二, 还是其他的方案, 只要保证, 一端发送时构造的数据, 在另一端能够正确的进行解析, 就是ok的. 这种约定, 就是 应用层协议
0.1HTTP协议
虽然我们说, 应用层协议是我们程序猿自己定的. 但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议)就是其中之一。

urlencode和urldecode线上转码工具
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现. 比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
1.域名
域名(Domain Name)是互联网上某一台计算机或计算机组的名称,由一串用点分隔的名字组成,用于在数据传输时标识计算机或计算机组的电子方位。人们设计域名的初衷是为了方便记忆和沟通,避免直接使用不便于记忆的IP地址数串。通过域名系统(DNS,Domain Name System),域名和IP地址可以相互映射,使得用户可以更方便地访问互联网资源。
IP地址(Internet Protocol Address)是一串数字,用于向Internet上的计算机提供标识。它与域名存在映射关系,但不同于域名,IP地址是机器直接读取的数字标识。IP地址和域名之间是一对多的关系,即一个IP地址可以对应多个域名,但一个域名通常只对应一个IP地址。
客户端(Client)则是指用户使用的电脑、手机等设备,它是用户与互联网进行交互的终端。在访问网站时,客户端(即用户的设备)会向DNS系统查询域名对应的IP地址,然后通过这个IP地址与服务器进行通信,从而获取或发送数据。
因此,域名、IP地址和客户端之间存在紧密的关系。域名提供了用户友好的访问方式,使得用户无需记住复杂的IP地址;IP地址则是互联网通信的基础,确保信息能够准确地发送到目标计算机;而客户端则是用户与互联网交互的桥梁,通过它用户可以访问网站、发送电子邮件等。这三者共同构成了互联网访问和通信的基础架构。
2.DNS
DNS是域名系统(Domain Name System)的缩写,是互联网的一项核心服务。DNS主要由解析器和域名服务器组成,其作用是将域名(网址)解析为IP地址,从而使人更方便地访问互联网,而无需记住机器直接读取的IP地址数串。简单来说,DNS相当于互联网上的电话簿,记录了IP地址及对应域名信息,便于用户进行查询并访问。
DNS服务器层级结构包括根域名服务器、顶级域名服务器、权限域名服务器和本地域名服务器。当用户在浏览器中输入一个域名时,本地DNS服务器会首先检查自身的缓存中是否有相应的IP地址。如果没有,它会向根域名服务器发送查询请求,然后依次通过顶级域名服务器和权限域名服务器进行解析,最终返回对应的IP地址。
DNS的架构是一个分层的分布式数据库和一组相关的协议,它定义了查询和更新数据库的机制,以及服务器之间复制数据库中信息的机制。这种设计使得主机名可以驻留在多个服务器上,从而减少了任何一台服务器上的负载,并提供了按分区管理命名系统的能力。
3.访问浏览器
windows cmd :ping baidu.com得到百度的ip
- xshell :telnet ip 80(端口)或者telnet www.baidu.com 80
- 直接在浏览器搜索ip
- 没有指明端口号,怎么能够成功访问?访问浏览器时自动添加端口号;在【直接在浏览器搜索ip】这里,ip后添加
:80也可以访问
知名服务器的端口一般不变
得让大家都知道才能访问你 如果变了 大家就找不到你了
http与https
HTTP和HTTPS是两种不同的网络协议,它们在多个方面存在显著差异。
首先,从安全性角度来看,HTTP使用的是明文传输,这意味着在传输过程中数据可能被截获或篡改。相反,HTTPS则通过SSL/TLS协议进行加密传输,从而保护数据在传输过程中的安全,防止数据被窃取或篡改。此外,HTTPS在连接过程中始终保持加密状态,即使连接被截断,也不会影响数据的加密状态。
其次,两者的证书管理也有所不同。HTTPS需要使用CA(证书颁发机构)颁发的证书来进行加密和解密操作,而HTTP则不需要证书。这意味着在使用HTTPS时,需要进行证书的配置。
再次,HTTP和HTTPS使用的端口号也不同。HTTP通常使用端口80,而HTTPS则使用端口443。
此外,从性能角度来看,由于HTTPS使用了加密和解密操作,因此在数据传输过程中需要消耗更多的计算资源,可能导致一些性能上的损失。
最后,从应用场景来看,HTTP协议主要用于传输HTML数据以及其他网络资源,如图片、音频、视频等。它通常被用于不需要加密传输数据的场景,如浏览网页、下载资源、使用API接口等。而HTTPS则由于其加密特性,更适用于需要保护用户隐私和数据安全的场景,如在线购物、银行交易等。
总结来说,HTTP和HTTPS各有其特点和适用场景,用户可以根据具体需求选择使用哪种协议。如需更多信息,建议查阅计算机或网络技术的专业书籍,或访问相关论坛。
4.URL
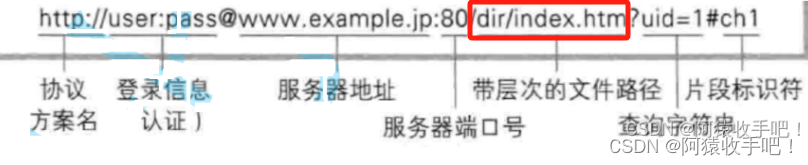

URL(Uniform Resource Locator,统一资源定位符)是用于标识互联网上的资源的字符串。它提供了一种方便的方式来指定和定位互联网上的各种资源,如网页、图片、视频、文件等。URL的结构通常包括协议、域名、端口号、路径、查询字符串和片段标识符等部分。为什么具有唯一性?这是服务器某个路径下的资源!
URL的结构:
协议:指定了如何访问资源,常见的协议有http、https、ftp等。例如,http://表示使用HTTP协议进行访问。
域名:即网站的地址,是互联网上的一个唯一标识。它可以是IP地址的易记形式,如www.example.com。
端口号:指定了服务器用于接收请求的端口。大多数协议都有默认的端口号,如HTTP的默认端口是80,HTTPS的默认端口是443。如果省略端口号,浏览器会使用默认的端口号。
路径:指定了服务器上资源的具体位置。它可以是目录路径或文件名,如/index.html。
查询字符串:用于传递参数给服务器,通常跟在路径后面,并以问号(?)开始。例如,?name=John&age=30。
片段标识符:用于指定资源中的特定部分,通常用于HTML页面中的某个元素。它以井号(#)开始,如#section1。
URL的例子:
假设我们有一个网站www.example.com,它上面有一个名为index.html的页面,并且这个页面有一个名为section1的片段。同时,这个页面需要传递两个参数给服务器:name和age。那么,对应的URL可能是这样的:
http://www.example.com/index.html?name=John&age=30#section1
在这个例子中:
http:// 是协议部分,表示使用HTTP协议。
www.example.com 是域名部分。
/index.html 是路径部分,指向服务器上的具体页面。
?name=John&age=30 是查询字符串部分,用于传递参数。
#section1 是片段标识符部分,用于指定页面中的特定部分。
URL的标准化和正确构造对于网页的访问、资源的定位以及搜索引擎优化(SEO)都非常重要。错误的URL可能导致资源无法正确访问或搜索引擎无法正确索引网页内容。
通常在服务端获得的客户端请求的url只显示一部分

搜索特殊字符如#&~



5.万维网
万维网(Web或WWW)、互联网、因特网(Internet)和以太网是网络技术中常用的术语,它们各自具有不同的含义和功能:
万维网(Web或WWW):
万维网是一个资料空间,其中的有用事物被称为“资源”,并由一个全域“统一资源标识符”(URL)来标识。
这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给使用者,使用者通过点击链接来获取这些资源。
万维网常被看作是因特网的一个服务,而不是因特网本身。尽管两者常被当作同义词使用,但实际上万维网只是互联网所能提供的服务之一。
互联网(internet):
互联网是一个庞大的网络,由多个网络相互连接而成,这些网络遵循一组通用的协议。
它始于1969年的阿帕网,并逐渐发展成为一个覆盖全球的互联网络。
互联网不仅包括万维网,还包括电子邮件、文件传输、远程登录等多种服务和应用。
因特网(Internet):
因特网是一组全球信息资源的总汇,它由一个庞大的网络互联而成,每个子网中连接着若干台计算机(主机)。
它是基于TCP/IP协议族构建的,这些协议定义了数据如何在计算机之间传输和路由。
因特网提供了各种服务,如万维网浏览、电子邮件、文件共享等。
以太网(Ethernet):
以太网是一种计算机局域网技术,是目前现实世界中最普遍的一种计算机网络。
它使用IEEE 802.3标准,定义了物理层的连线、电子信号和介质访问层协议的内容。
以太网可以是经典以太网或交换式以太网,后者使用交换机连接不同的计算机。
总结来说,这四个术语在网络技术中各有其独特的含义和角色。
万维网是基于超文本链接的全球性系统,提供网页浏览等服务;
互联网是一个由多个网络组成的庞大网络,提供了各种网络服务;
因特网是一个基于TCP/IP协议族构建的信息资源总汇;
以太网则是一种局域网技术,用于连接计算机和其他设备。
这些技术共同构成了我们今天的数字化世界。
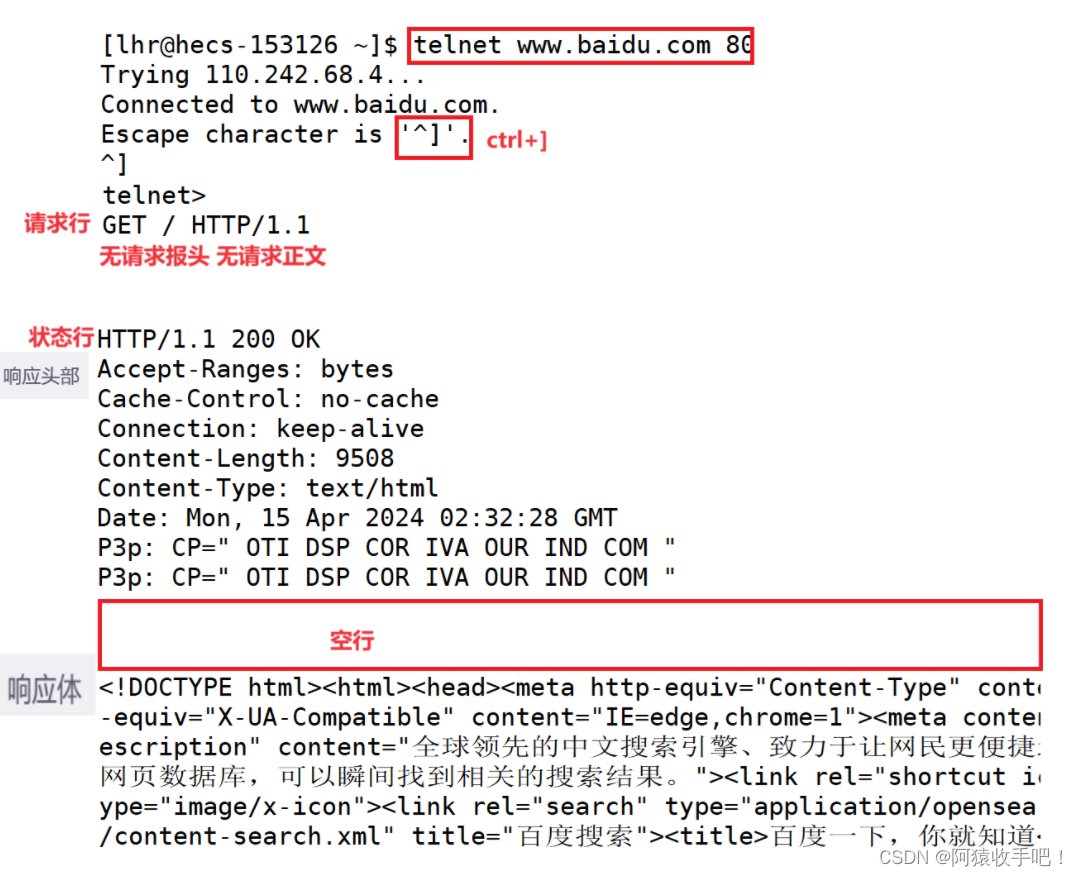
6.http请求和响应的格式
HTTP请求和响应的格式在HTTP协议中都有明确的规定,它们通常遵循一定的结构,以确保客户端和服务器之间的正确通信。以下是HTTP请求和响应的基本格式:
6.1HTTP请求格式
存储一行 打印多行

请求行(Request Line):
- 方法(Method):如GET、POST、PUT、DELETE等。
- 请求的URI(Uniform Resource Identifier):指定请求的资源位置。
- HTTP版本:如HTTP/1.0 1.1 2.0
例如:GET /index.html HTTP/1.1【空格分隔】
请求头部(Request Headers):
- 包含关于请求的各种元数据,如User-Agent(客户端类型【识别客户端用的什么机器:win/Android/macos或者如果请求中没有这个字段,可能是爬虫,反爬!】)、Accept-Language(接受的语言)、Content-Type(发送数据的类型)、Content-Length(发送数据的长度)等。
- 每行包含一个头部字段名和字段值,用冒号分隔。【KV模型】
例如:
User-Agent: Mozilla/5.0
Accept-Language: en-US,en;q=0.5
Content-Type: application/x-www-form-urlencoded
Content-Length: 15
- 1
- 2
- 3
- 4
请求体(Request Body):
对于某些请求方法(如POST或PUT),请求体包含要发送到服务器的数据。
数据可以是文本、JSON、XML或其他格式,取决于Content-Type头部。
区分三部分:请求行只有一行 报头和有效载荷做分离
- 每一部分的行都以\r\n做行分隔符 那么每一部分的内容里就没有\r\n
- 报头和正文间有一行空行
- 读请求时读到空行 即为读到有效报头
- 报头里有一个属性记录了正文的长度 依据这个属性读正文(正文可以没有)
6.2HTTP响应格式
HTTP响应通常由以下部分组成:
状态行(Status Line):
- HTTP版本。[请求和相应都有版本,服务器根据版本向客户端发送客户端当前版本能够接受的消息]
- 状态码(Status Code):如200(OK)、404(Not Found)、500(Internal Server Error)等。
- 状态消息(Reason-Phrase):对状态码的简短描述。
例如:HTTP/1.1 200 OK
响应头部(Response Headers):
与请求头部类似,包含关于响应的元数据,如Content-Type(返回数据的类型)、Content-Length(返回数据的长度)、Set-Cookie(设置Cookie)等。
例如:
Content-Type: text/html; charset=UTF-8
Content-Length: 1234
Set-Cookie: name=value; expires=Wed, 21 Oct 2015 07:28:00 GMT
响应体(Response Body):
服务器返回给客户端的数据,如HTML页面、JSON对象、图片等。
数据的格式取决于Content-Type头部。
6.3示例
一个完整的HTTP请求和响应可能如下所示:
请求:
GET /example HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Connection: keep-alive
- 1
- 2
- 3
- 4
- 5
- 6
(注意:GET请求通常不包含请求体)
响应:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2020 12:28:53 GMT
Server: Apache/2.4.18 (Ubuntu)
Last-Modified: Tue, 13 Jun 2016 07:18:22 GMT
ETag: "359670651"
Accept-Ranges: bytes
Content-Length: 55
Co ntent-Type: text/html
<html>
<body>
<h1>Hello, World!</h1>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在这个示例中,客户端发送了一个GET请求到服务器的/example路径,并收到了一个包含简单HTML页面的200 OK响应。实际的HTTP请求和响应可能会更复杂,包含更多的头部和/或请求体/响应体内容。
6.3模拟HTTP【框架】
#include <iostream>
#include <cstring>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
// 监听端口
const int PORT = 8080;
// 解析HTTP请求的方法(需要根据HTTP协议详细实现)
void parseHttpRequest(const char *request)
{
// TODO: 解析请求行、请求头、请求体
std::cout << "Received HTTP request: " << request << std::endl;
}
// 生成HTTP响应的方法(需要根据HTTP协议详细实现)
std::string generateHttpResponse(const char *request)
{
// TODO: 根据请求内容生成响应行、响应头、响应体
std::string response = "HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\n\r\nHello, World!";
return response;
}
int main()
{
const char *hello = "HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\n\r\nHello, World!";
// 创建socket文件描述符
int server_fd;
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0)
{
perror("socket failed");
exit(EXIT_FAILURE);
}
// 设置套接字选项,允许端口重用
int opt = 1;
if (setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt)))
{
perror("setsockopt");
exit(EXIT_FAILURE);
}
struct sockaddr_in address;
int addrlen = sizeof(address);
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
// 绑定socket到给定的IP地址和端口
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address)) < 0)
{
perror("bind failed");
exit(EXIT_FAILURE);
}
// 开始监听连接
if (listen(server_fd, 3) < 0)
{
perror("listen");
exit(EXIT_FAILURE);
}
std::cout << "Server is listening on port " << PORT << std::endl;
char buffer[1024] = {0};
int new_socket;
while (true)
{
// 接受一个新的连接
if ((new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t *)&addrlen)) < 0)
{
perror("accept");
exit(EXIT_FAILURE);
}
// 读取请求数据
int valread = read(new_socket, buffer, 1024);
parseHttpRequest(buffer);
// 生成响应数据
std::string response = generateHttpResponse(buffer);
// 发送响应数据
send(new_socket, response.c_str(), response.size(), 0);
std::cout << "Sent HTTP response" << std::endl;
// 关闭连接
close(new_socket);
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
6.4查看请求或响应的工具
Fiddler
Fiddler是一款强大的Web调试工具,位于客户端和服务端之间的HTTP代理。它的主要功能包括监控浏览器所有的HTTP/HTTPS流量,查看、分析请求内容细节,伪造客户端请求和服务器请求,测试网站的性能,解密HTTPS的Web会话等。此外,Fiddler还提供了全局、局部断电功能,以及支持第三方插件。
Fiddler的使用场景非常广泛,包括接口调试、接口测试、线上环境调试、Web性能分析等。它也可以用来判断全后端bug、开发环境hosts配置、mock测试以及弱网断网测试。对于开发人员来说,Fiddler特别有用。前端开发人员可以通过Fiddler代理来调试JS、CSS、HTML样式,后端开发人员则可以通过Fiddler查看请求和响应,从而定位问题。
在使用Fiddler时,用户可以通过其界面查看HTTP请求和响应的详细信息,包括请求行、请求头、请求体以及响应行、响应头、响应体等。这些信息对于分析和调试Web应用非常有帮助。
总的来说,Fiddler是一款功能强大且易于使用的Web调试工具,无论是前端还是后端开发人员,都可以通过它来提升工作效率和解决问题的能力。如果你需要下载和使用Fiddler,可以访问其官方网站进行下载,并按照提供的教程进行安装和使用。
如需更深入地了解Fiddler的使用方法和技巧,建议查阅相关的官方文档或在线教程,这些资源通常会提供更详细和具体的指导。同时,也可以参考其他开发者的经验分享,以便更好地利用Fiddler来解决实际问题。
Postman
Postman是一个接口测试工具,在做接口测试的时候,Postman相当于一个客户端,它可以模拟用户发起的各类HTTP请求,将请求数据发送至服务端,获取对应的响应结果,从而验证响应中的结果数据是否和预期值相匹配,并确保开发人员能够及时处理接口中的bug,进而保证产品上线之后的稳定性和安全性。
Postman的主要功能包括:
构建请求参数:在Postman中可以方便地设置请求的参数,包括查询参数、请求体和头部信息等。
管理环境变量:Postman允许创建和管理环境变量,以便在不同的请求中重复使用。
自动化测试集合:Postman允许创建测试集合,用于自动化测试API的各种方面。
共享和协作:Postman允许用户共享他们的API请求和测试集合给团队中的其他成员,以便共同协作。
监视API性能:Postman提供了API监视功能,可以定期发送请求并监视API。
此外,Postman还有丰富的界面功能,包括新建请求、集合、环境等,导入请求集,运行请求集,邀请团队成员协作,设置功能,查看消息和通知,管理账户等。
总的来说,Postman是一个功能强大、易于使用的接口测试工具,无论是前端还是后端开发人员,都可以通过它来提升工作效率和解决问题的能力。
7.网页
7.0对访问网页的认识
- 可以手动编写服务端响应,在响应的正文可以是字符串,可以是网页字符串(html),可以是网页文件
- 客户端把想要访问的资源写在url处,服务端就可以按照这个路径去寻找并响应。
- WEB根目录可以是Linux根目录,也可以是指定的某个目录
- 网页文件放在服务器资源部分。
7.1wget
wget+www.baidu.com:将百度首页的网页内容拷贝到当前index.html(自动创建)文件中
wget 是一个在命令行界面下工作的网络文件下载工具,它支持通过 HTTP、HTTPS、FTP 等协议下载文件,并可以将文件保存在本地。wget 是 “World Wide Web Get” 的缩写,字面上理解就是“从网上获取”的意思。
使用 wget 下载文件的基本语法是:
bash
wget [选项] [URL]
其中,[URL] 是你想要下载的文件的网址,[选项] 是你可以用来定制下载行为的参数。
以下是一些常用的 wget 选项:
-P, --directory-prefix=目录:指定保存文件的目录。
-r, --recursive:递归下载,下载指定 URL 下的所有文件。
-np, --no-parent:递归下载时不进入父目录。
-A, --accept=LIST:只下载 LIST 中列出的文件类型。
-R, --reject=LIST:排除 LIST 中列出的文件类型。
-l, --level=深度:递归下载的深度。
-nc, --no-clobber:如果文件已存在,则不下载新文件。
-N, --timestamping:只下载比本地文件新的文件。
-c, --continue:断点续传。
-q, --quiet:安静模式,不显示下载信息。
-O, --output-document=文件:将文件保存到指定名称。
–limit-rate=速率:限制下载速度。
这只是 wget 的一部分选项,实际上它还有许多其他功能和选项。你可以通过 man wget 或 wget --help 命令查看完整的帮助文档和选项列表。
例如,如果你想下载一个名为 example.zip 的文件,并将其保存到本地的 downloads 文件夹中,你可以使用以下命令:
bash
wget -P downloads http://example.com/example.zip
7.2新的认识
- 自己编写了http服务端 运行后 在windows下的浏览器通过:服务端ip:端口号的形式可以访问
- 平时访问百度,实际上就是ip+端口,只不过访问的时候用的是域名,当你在浏览器访问百度时,实际上就是浏览器作为客户端向百度服务器发送http请求,百度服务器含有诸多html代码,把你要访问的资源返回给你的界面。
7.3GET/POST
HTTP中的GET和POST方法都是用于向服务器发送请求的基本HTTP方法,但它们之间存在一些重要的区别。以下是它们之间的主要区别与联系:
区别:
请求的目的:
GET方法主要用于请求数据。它通常用于从服务器检索信息,例如获取网页内容或查询数据库。
POST方法主要用于提交数据。它通常用于向服务器发送数据,例如提交表单数据或上传文件。
安全性:
GET请求的参数直接附加在URL后面,并且可以在浏览器的历史记录、网络日志等地方被看到,因此不适合传输敏感信息。
POST请求的参数在请求体中,不会在URL中显示,相对更安全一些。但请注意,仅仅使用POST并不足以保证安全性,还需要其他安全措施(如HTTPS)来确保数据在传输过程中的安全。

post只是相对安全,因为它不会直接显示在url后,实际上二者都不安全,安全问题需要加密----https中会讲
缓存:
GET请求可以被缓存,而POST请求则不会。这意味着如果你多次发送相同的GET请求,浏览器或代理服务器可能会返回缓存的结果,而不是每次都从服务器获取新数据。
数据长度限制:
GET请求由于将参数附加在URL中,因此受到URL长度的限制。不同的浏览器和服务器对URL长度有不同的限制,但通常都不建议过长。
POST请求没有这样的限制,因为数据是放在请求体中的。
幂等性:
GET请求是幂等的,意味着多次执行相同的GET请求应该具有相同的效果(没有副作用)。
POST请求不是幂等的,每次执行都可能有不同的效果(例如,提交表单数据可能会创建新的资源)。
联系:
都是HTTP方法:GET和POST都是HTTP协议中定义的方法,用于与Web服务器进行通信。
都使用HTTP协议:无论是GET还是POST请求,它们都遵循HTTP协议的规定,包括请求行、请求头、请求体等结构。
都可以包含请求头和请求体:虽然GET请求通常不包含请求体(除非使用了某些特殊技术,如查询字符串),但两者都可以包含请求头,用于传递额外的信息,如认证信息、内容类型等。
都可以用于Web开发:在Web开发中,GET和POST都是常用的HTTP方法,用于实现各种功能,如页面跳转、表单提交、数据查询等。
总的来说,GET和POST在HTTP协议中扮演着不同的角色,具有不同的用途和特点。在选择使用哪种方法时,应根据具体的应用场景和需求来决定。
7.4action=/s
在Web开发中,action=“/s” 通常出现在HTML表单的 标签中,用于指定当表单提交时数据应该发送到的URL。这里的 /s 通常是一个相对于当前URL的路径,表示表单数据应该被发送到服务器上的 /s 这个路径。
例如:
html
在这个例子中,当用户填写表单并点击“Submit”按钮时,浏览器会创建一个HTTP POST请求,并将表单中的数据发送到服务器的 /s 路径。服务器上的某个处理程序(通常是一个Web应用框架中的视图函数或控制器方法)会处理这个请求,并根据需要执行相应的操作,比如验证用户输入、存储数据等。需要注意的是,/s 这个路径是相对于当前页面的URL的。如果当前页面的URL是 http://example.com/home,那么表单数据将会发送到 http://example.com/s。如果当前页面在子目录下,比如 http://example.com/subdir/page,那么实际发送的URL将会是 http://example.com/subdir/s,除非使用了绝对路径。
此外,method=“post” 指定了HTTP请求的方法为POST,这意味着表单数据将作为请求体发送,而不是附加在URL后面(像GET请求那样)。使用POST方法通常用于提交可能包含敏感信息(如密码)的表单,因为POST请求不会在浏览器的历史记录或网络日志中留下明显的痕迹。
8.状态码
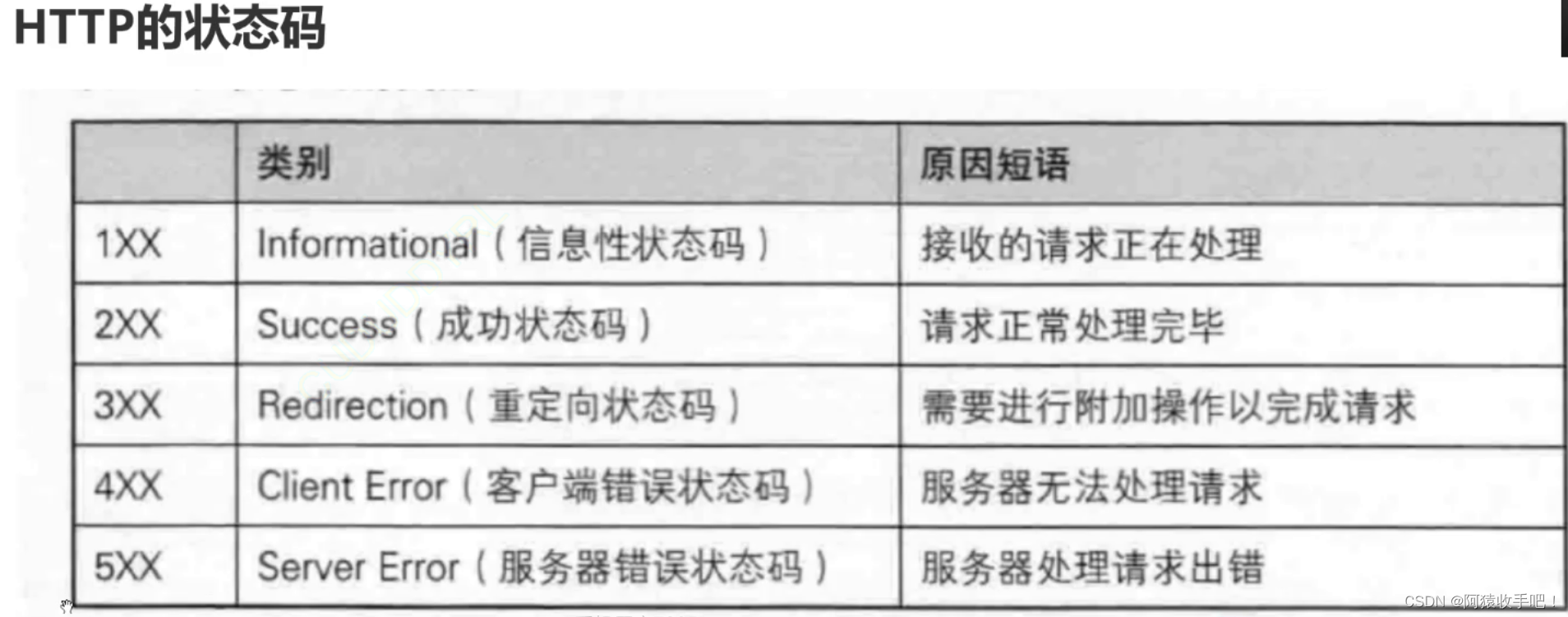
403:没有访问资格/权限
5xx: 服务线程创建错误,连接数据库错误
- 对状态码的要求并不是那么严格,浏览器对状态码的审核就不那么严格,所以在编写时即便有了错的,他也会写成200
- 如果说操作系统的编写难度是T1级别,那么浏览器的编写就是T2级别,浏览器的编写涉及到网络编程,内存管理以及要有较强的容错率。
- 有的可能会对你的get方法进行改写,比如把你的get方法改成post的方法
- 其他的重定向浏览器不一定支持,即便支持了,不同的浏览器对于重定向这一标准所定义的行为也是不一样的,这里我们只简单了解一下临时重定向
- 300:(多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301:(永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302:(临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303:(查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304:(未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305:(使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307:(临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
308:(永久转移)这个请求和以后的请求都应该被另一个URI地址重新发送。307、308和302、301有相同的表现,但是不允许HTTP方法改变。例如,请求表单到一个永久转移的资源将会继续顺利地执行。
- 在早些年间,网民上网必须通过浏览器这个流量入口,先打开浏览器再去搜索引擎搜索,这也是为什么有这么多的浏览器,只要公司创造了浏览器,,那么他们就掌握了流量的入口,就可以赚很多钱
- 各个公司都想通过创造浏览器来获得流量的入口来获得更大的市值,但是浏览器更多就导致标准不那么确定,实际上很多国内的浏览器他们并没有自己独立的浏览器内核,更多的是直接封装了谷歌浏览器的内核,而像微软谷歌,他们是有自己浏览器内核的,而在谷歌和微软之前有一家叫做网景浏览器的公司,网景公司做的浏览器叫做领航员,微软公司想独占浏览器网络接口的这个市场,于是他通过在自己的电脑上绑定一款浏览器软件IE,通过这种方式与网景公司竞争。
- 做后端的同学在测试HTTP服务器的时候,对于状态码不用那么的较真,但是在做前端服务器的同时,在做前端的同学做浏览器页面的时候,对于状态码,他们不仅要在不同的浏览器上测试,还要对每种浏览器的新旧版本上做测试
- 总结一句话就是浏览器的标准是有的,但是不那么的统一
9. 重定向
浏览器向服务器发送了一个请求,但是服务器由于某种原因无法向浏览器提供这种服务,服务器返回了一个状态码和新的地址,告知浏览器可以通过新的地址,去找到他想要的东西。

