
- 1已解决(pymysqL连接数据库报错)pymysqL.err.ProgrammingError: (1146,“Table ‘test.students‘ doesn‘t exist“)_raise errorclass(errno, errval) pymysql.err.progra
- 2vue 报错this.$Api.sendEmail is not a function 和TypeError: Cannot set property 'pageCode' of undefined_vue this.$api.不存在
- 3自用的8款AI工具!提升学习/工作/赚钱效率,轻松超过99%的人!
- 4数据结构与算法——归并排序_数据结构归并排序
- 5使用 Xcode 运行 python等脚本语言(perl, ruby)_伊织code
- 6深入理解Elasticsearch的索引映射(mapping)_elasticsearch 类型 映射
- 7三分钟掌握PHP操作数据库_php数据库
- 8远程仓库——GitHub
- 9Hadoop之HBase基本简介_hadoop hbase
- 10[深度学习]yolov8+pyqt5搭建精美界面GUI设计源码实现一_yolo pyqt界面设计代码
【AI绘图学习笔记】self-attention自注意力机制_注意力机制画图
赞
踩
台大李宏毅21年机器学习课程 self-attention和transformer
不同模态的输入和输出
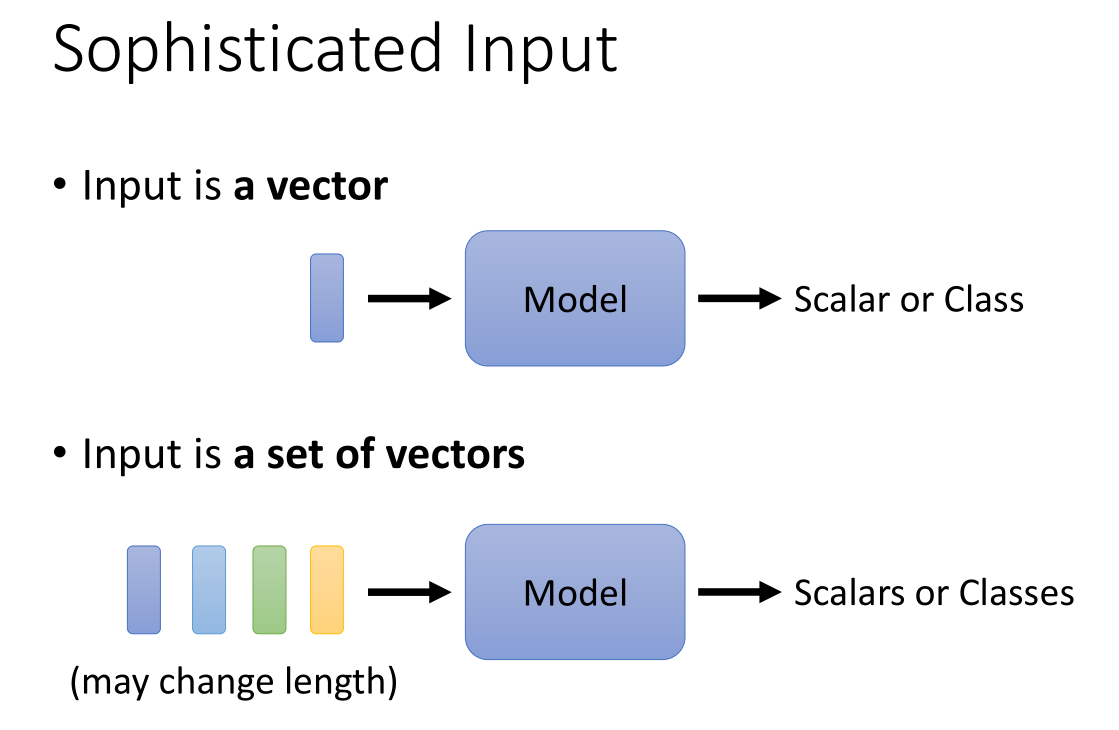
之前我们所讲的一些神经网络,其模式往往是上面这种,也就是往往是一个输入向量(张量),然后给出一个标量(回归问题)或者类(分类问题)来作为输出结果。
在下面的这种模式中,如果输入是一排向量(向量集合),并且输入的长度随时有可能发生改变呢?也就是用于处理可变长度的sequence的model。例如下图给出的一些输入值:
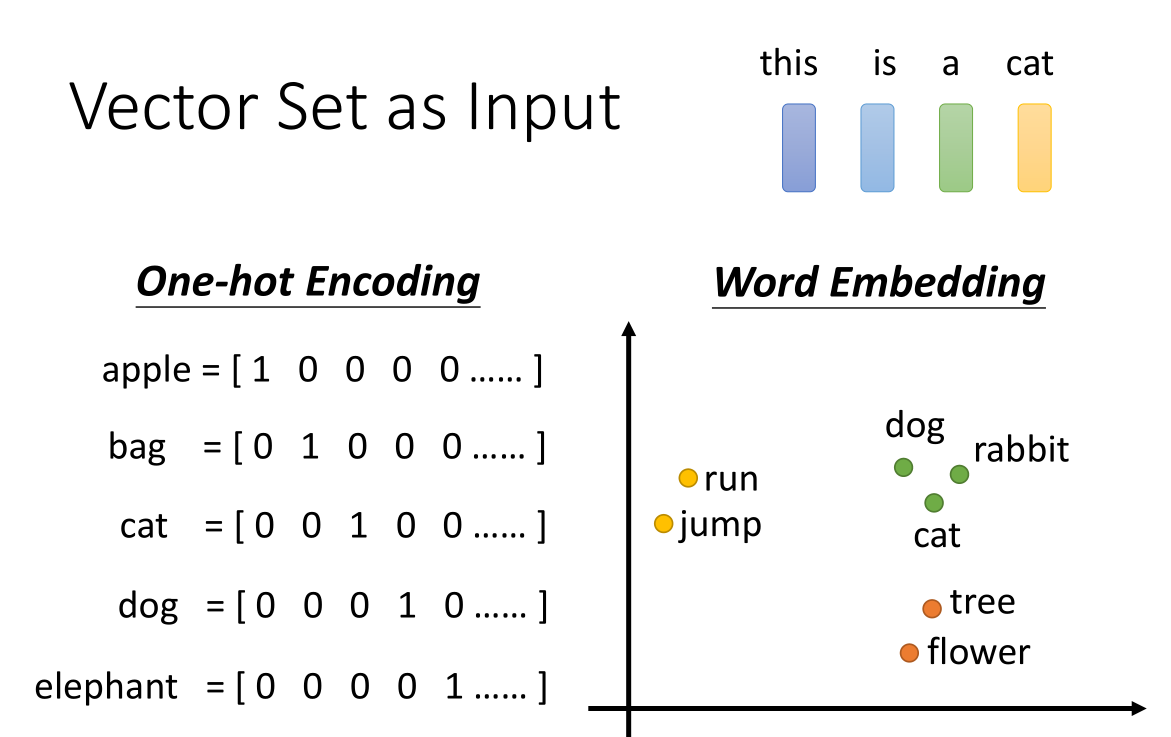
一个句子可以将每一个词汇描述成向量,整个句子就是一个vector set,并且由于句子长度不一样所以输入长度也不一样;一个将词汇变换为向量的方法是使用one-hot Encoding,也就是给出一个很长的向量,向量长度相当于要输入的词汇量(如果需要的话就要包括所有词汇量),向量的每个维度都给到一个词汇,这样无重复地对词汇进行编码。但是这样的表示方法,一:需要的向量长度实在是太长了,二:从向量中无法表示词汇的相关关系,例如语义上的关系。比如cat和dog,从语义关系上它们都是动物,但是这种coding方法无法表示二者都是动物这一特征。
另一种方法就是用Word embedding,embedding层也就是嵌入层,实际上就是通过降维或升维,将一些类型的数据转化为向量。我们可以看到在上面的坐标轴上,词汇被我们转为了对应的向量(用点表示向量),因此可以看到一些相似语义的词汇在分布上是十分接近的。整个句子就可以被看作是一排长度不一的向量。
或者我们也可以对音频就行处理,我们可以每隔一段时刻例如10ms截取一段窗口frame作为输出的向量,例如1s就有100frames。
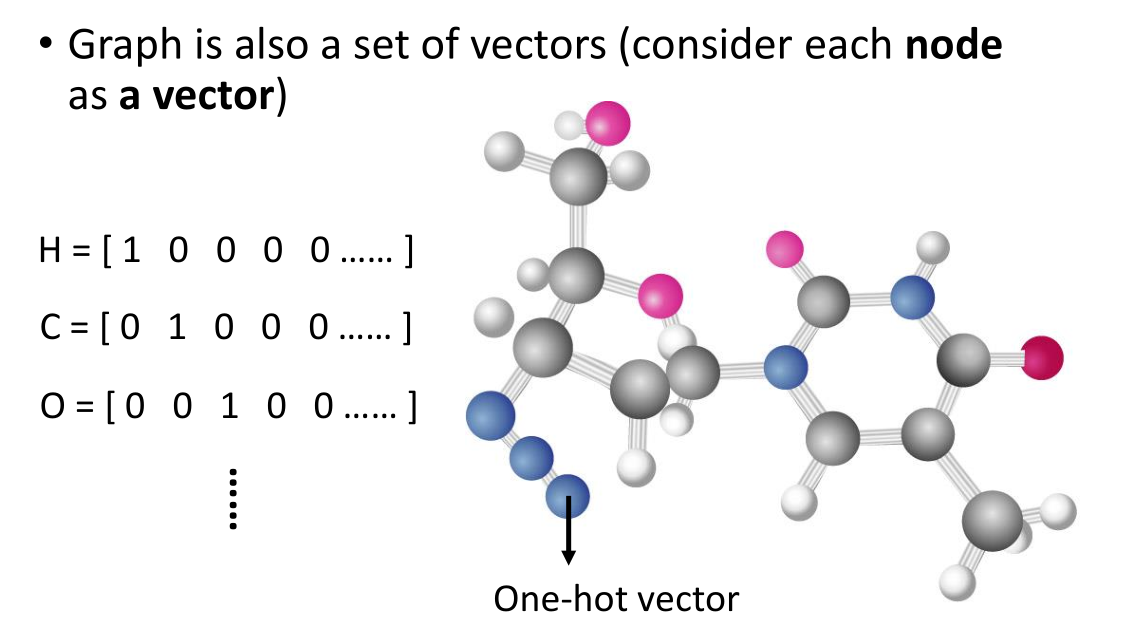
再例如给出一个图结构graph,我们也可以看作一组向量,将每个节点作为一个向量。一个比较实际的应用就是将分子结构视为graph,我们将其中的每一个原子都可以用one-hot coding 的方式作为一个vector,尤其是分子中碳,氢,氧原子这种比较多的结构使用one-hot coding 的效果挺好。
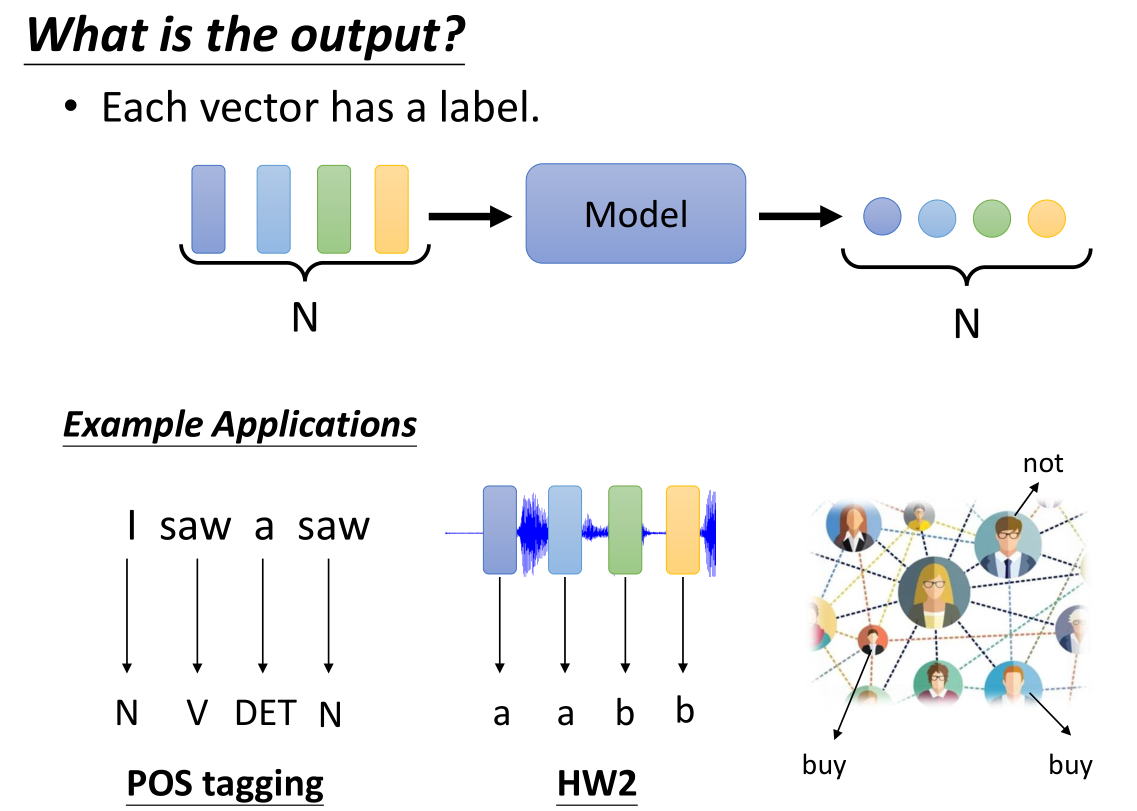
像这样给出一排的向量集合作为输入,我们也有多种输出的方法,第一种就是输出对应数量的向量,这相当于通过model给每一个向量打上了一个label标签。例如下面的一些应用:如果是给出句子的话,每个单词相当于一个向量,我们通过model给上一个词性标签POS tagging,这样就能让NN知道每个单词对应的词性,例如上面例子中的saw,第一个是动词,而第二个是名词,即使同一个单词也会出现不同词性。
第二个例子就是对音频的label,例如识别这一小段的frame属于哪个语音的音标,例如上面的例子第一个和第二个frame都是“a”发音的音标,第3,4对应的是“b"(HW2指的是homework2,就是课后作业题)
第三个例子是对graph来决定每个节点的一些特性,例如给出一个商品,model会告诉我们那些人(节点)会购买这个商品,而那些人不会。
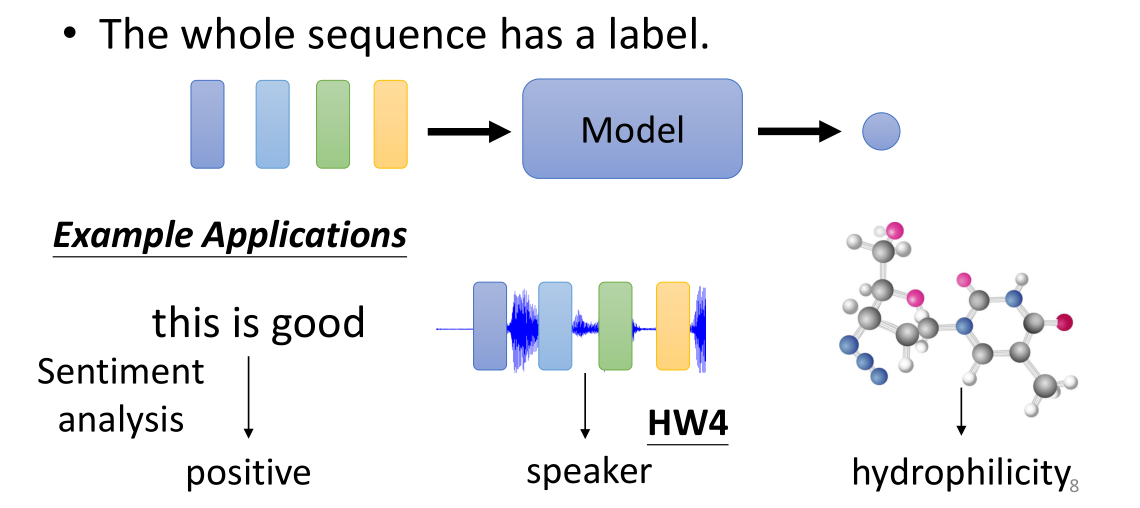
另一种输出结果就是输入多向量给出单个label。例如第一个例子用来作出语义识别,判断这个句子是一个正面的还是负面的评价;第二个例子是给出音频,让model判断这是谁讲的;第三个例子是给出分子图的graph,预测它的一些特性(例如亲水性)
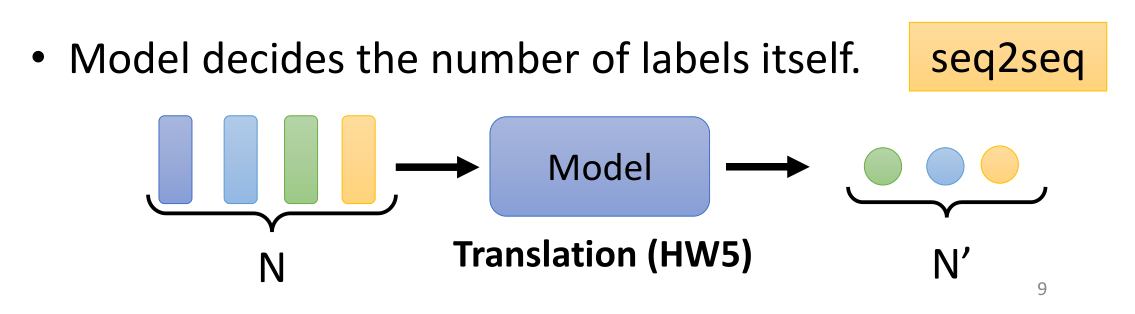
最后要讲的一种输入输出模式叫做seq2seq,也就是给定一个sequence,让机器自己决定输出的sequence应该有多少个label。
Sequence Labeling
所谓的Sequence Labeling也就是我们刚才所讲的第一种输入输出模式,也就是对于n个长度的向量的sequence,对应地给出n个label。
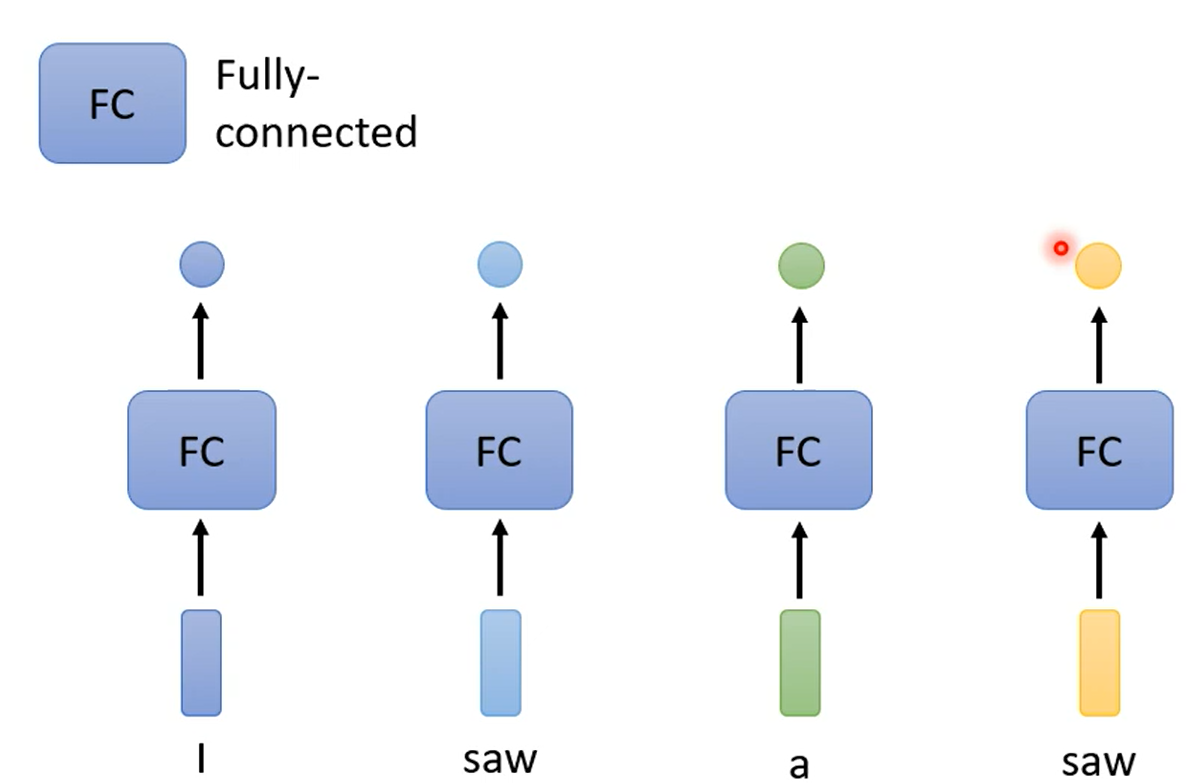
一种最简单的模型就是对每个输入向量给出一个全连接再输出一个label。但是这样会产生一个问题:那就是,对于这个句子I saw a saw,第二个单词saw和第四个单词saw,这两个单词的输出是完全一模一样的,但我们知道两个是不同词性的单词。我们期待第一个saw它能输出动词,而第二个saw输出名词,简单的结构是不可能做到这点的。想要改进这种方式,我们就要问问自己,我们平时阅读的时候是怎么分辨同一个单词的不同词性的?答案是:联系上下文(consider the context)。
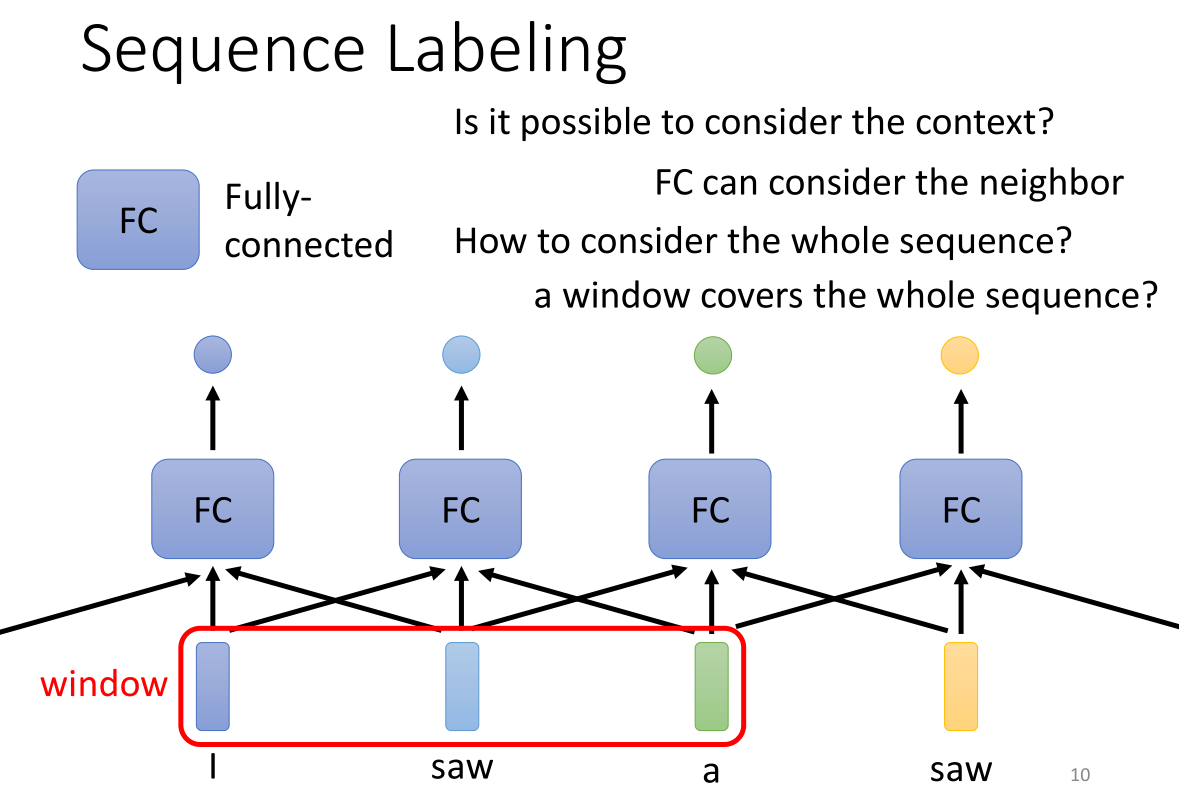
我们可以通过对给出的全连接层再连接上其他的向量(整个结构看起来就像CNN的卷积网络,而window就类似于上面FC的感知域),通过这个window那么一个FC可以连接其他的向量,这样我们就能联系上下文来考虑。那么如果一个完全覆盖了整个sequence长度的window是否是最好的呢?也不尽然,因为sequence的长度是会变的,如果需要覆盖整个sequence就要预先统计所有input中最长的那个sequence的长度,因此反而不具有泛化性。而且如果window太大,那么FC不仅要计算过大的参数,而且容易导致过拟合的情况发生。
Self-attention
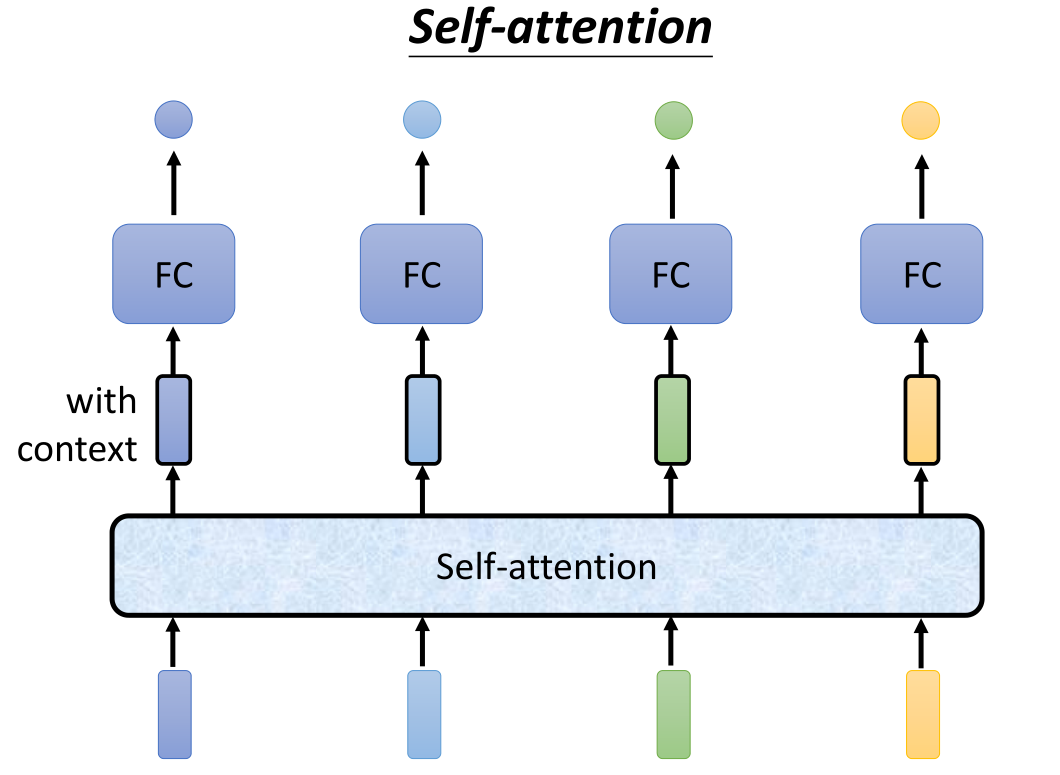
所以有没有方法来更好地考虑整个input的sequence呢?这就要用到Self-attention层,我们将向量给入self-attention,得到一个考虑了context上下文的向量,然后再传入到FC得到单个的label,这样我们所得到的label就不是对向量的简单输出,而是考虑了整个sequence的context得到的label。也就是说,最后一步是单个向量的labeling输出方式,中间的Self-attention层就是刚才讲的类似window输入的处理结构,我们将两种方式组合了起来。
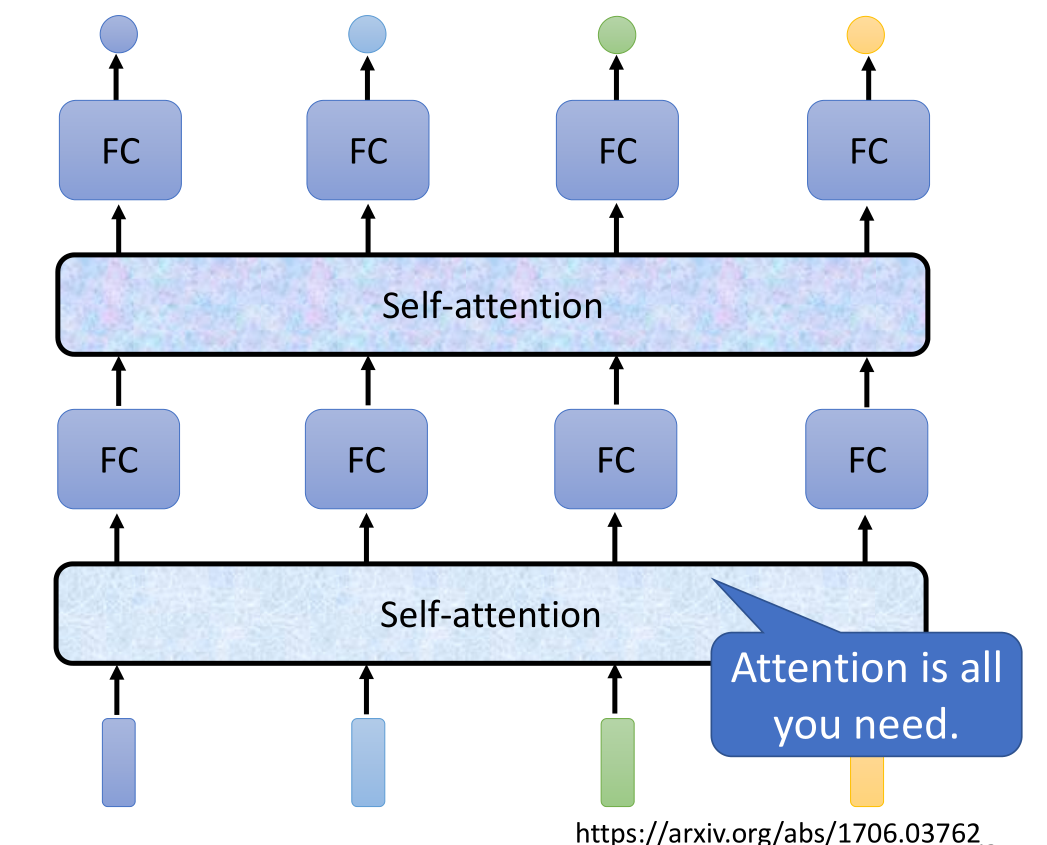
Self-attention也可以叠加很多次,我们可以在使用Self-attention考虑输入向量的一些信息后,再丢入另一个Self-attention层去考虑其他的一些信息。所以整体的结构上来看,Self-attention用于处理整体sequence相关的信息,而FC是专注于处理某一个位置的信息,我们通常会交替使用这两个层,这种结构在《Attention is all you need》这篇论文中是组成transformer(变形金刚 变形器) 的重要module。
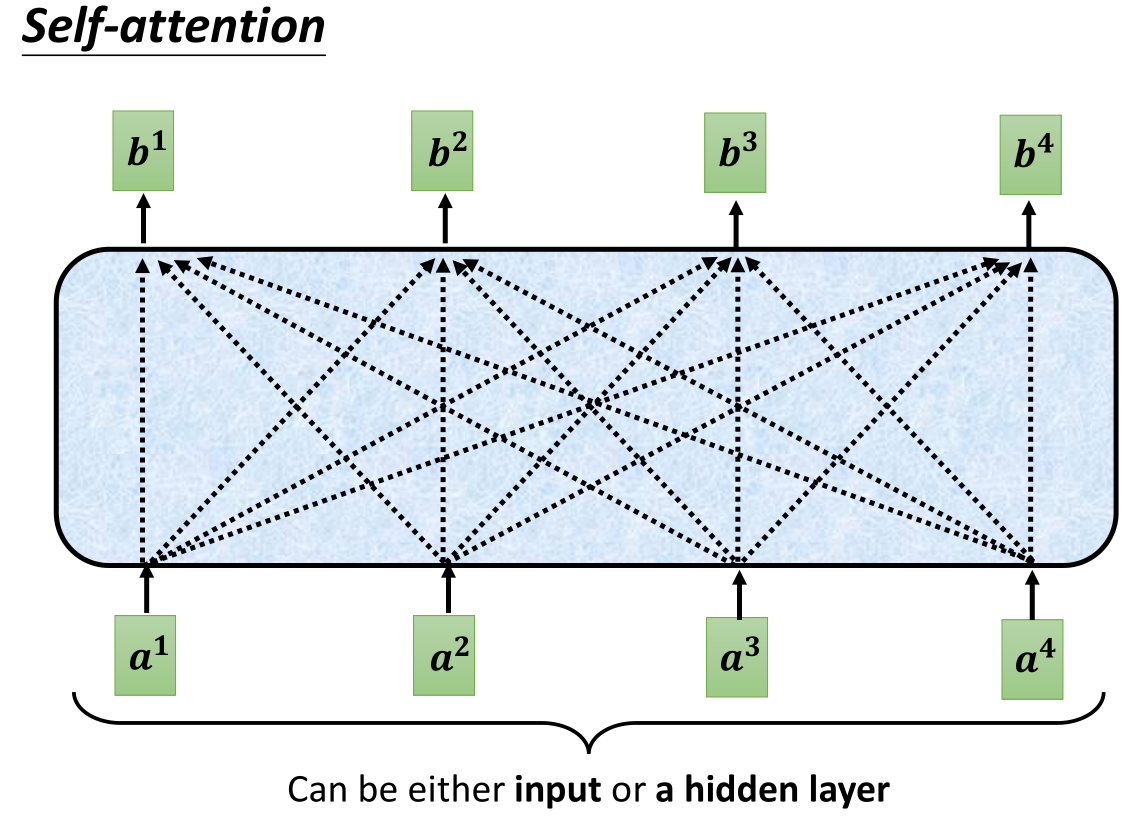
Self-attention内部的具体结构就像是FNN那种全连接的方式,具体来讲是怎么产生的呢?我们以b1为例:
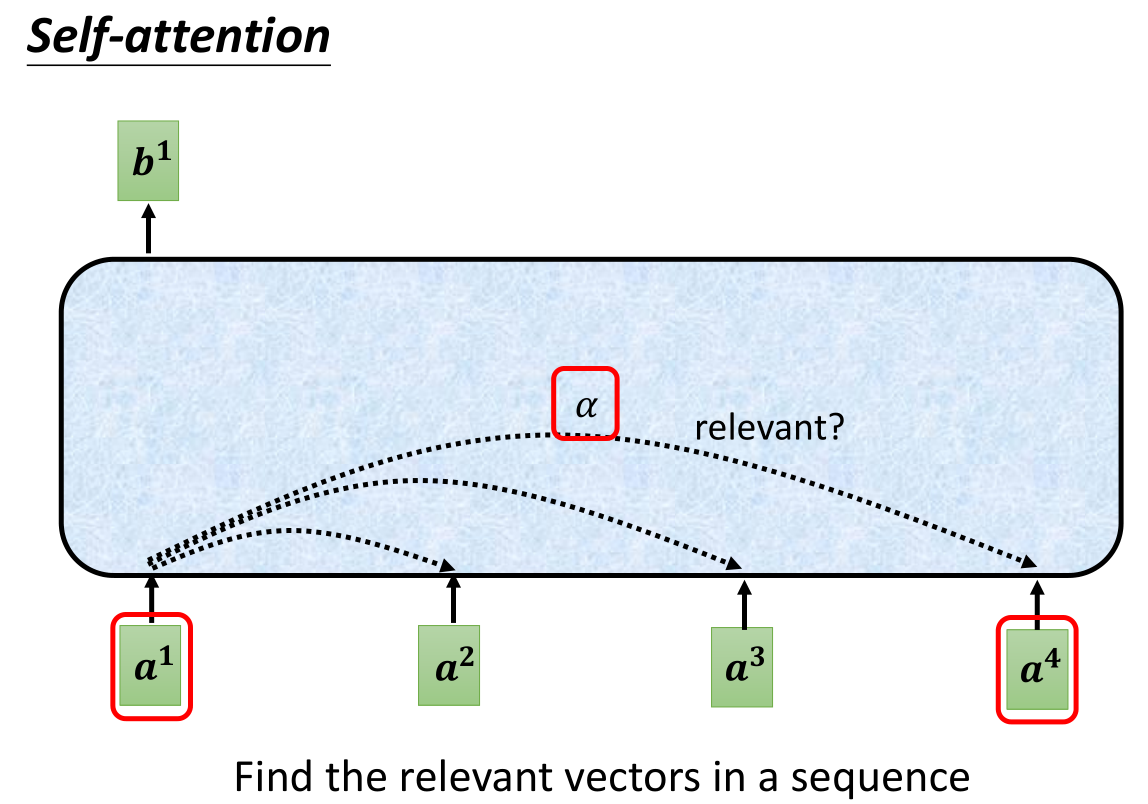
其中一个重要的参数就是判断b1对应的主输入a1和其他向量的一些相关性,我们可以用参数 α \alpha α来表示a1和每一个其他向量的相关性,
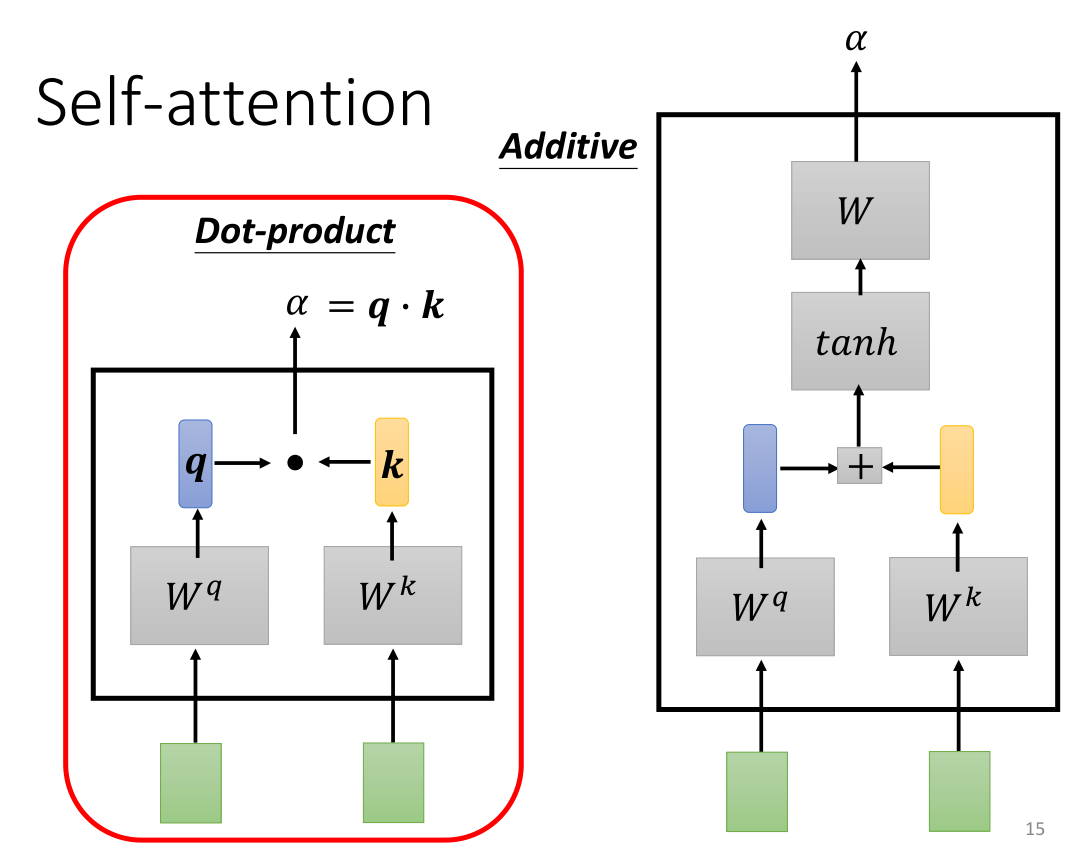
常见的计算
α
\alpha
α的方式有两种,一种是Dot-product点积,将计算相关性的两个向量分别乘以参数矩阵
W
q
W^q
Wq和
W
k
W^k
Wk(参数矩阵相乘的本质就是提取出一些重要的特征),再将得到的向量
q
⋅
k
q \cdot k
q⋅k进行点乘,最后得到的
α
\alpha
α就是相关系数,称为注意力得分。
另一种方法就是Additive,我们将得到的q和k直接concat进行纵轴拼接,然后丢入tanh双曲正切函数(这里省略了一部分,有时需要先进行线性变换后再丢入tanh),得到矩阵W最后通过一些不同方式的计算得到对应的
α
\alpha
α。
最常用的方法还是点积的这个方法。
部分同学可能注意到了,其实这里的小写 q , k q,k q,k就是上节课中U-net层中的 Q , K Q,K Q,K(还少个V),我们来详细解释一下点积计算的这个过程:
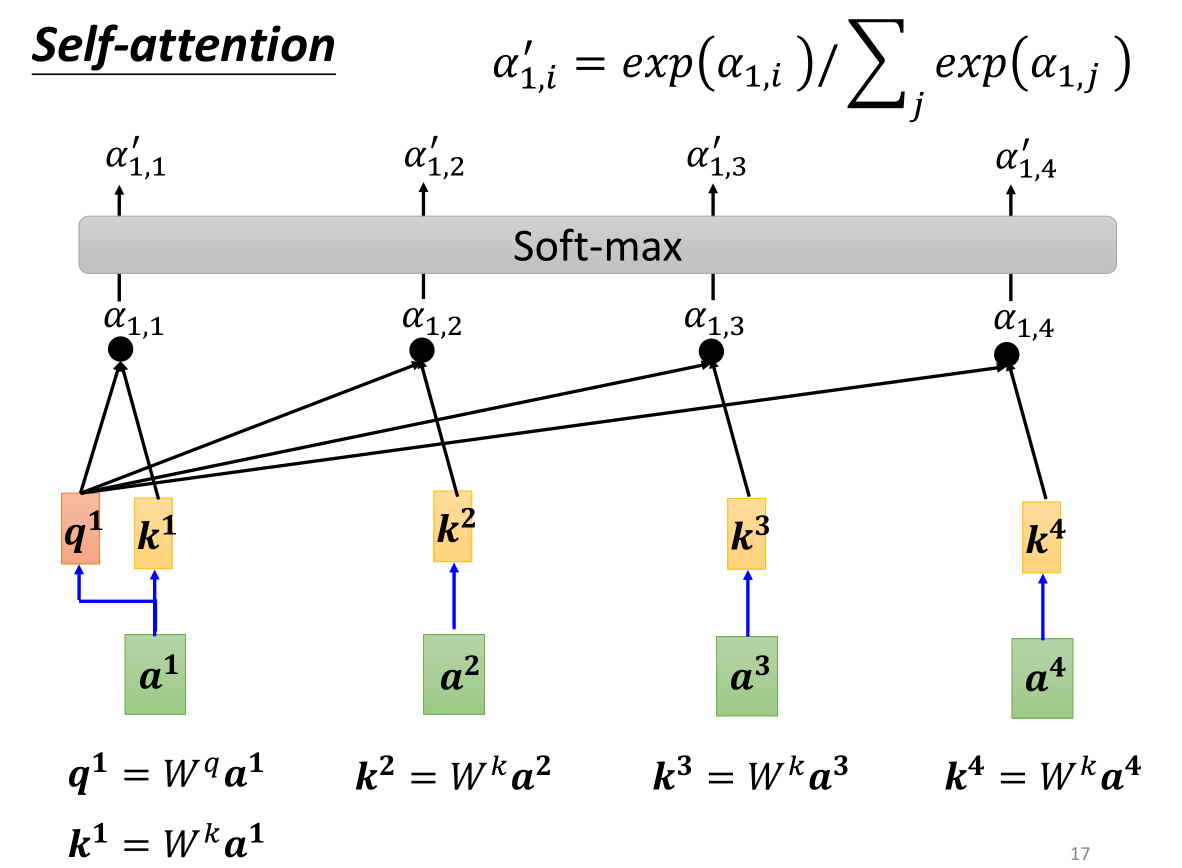
q q q代表的是query,即查询(搜寻), k k k代表的是key,即关键词, α = q ⋅ k \alpha=q \cdot k α=q⋅k,即 α \alpha α的结果就是q和k的相关性,我们称为注意力得分,同理我们也可以得到其他向量之间的 α \alpha α,需要注意的是例如 α 1 , 2 \alpha_{1,2} α1,2,下标的第一个数字代表了 a 1 a^1 a1得到的 q 1 q^1 q1,第二个数字代表了 a 2 a^2 a2得到的 k 2 k^2 k2。当然 a 1 a^1 a1自己的q和k也可以进行点积,被我们称为自相关性。
随后我们将所有的相关性参数 α \alpha α全部输入到Soft-max中,我们在多分类问题中讲到了使用Soft-max的方法,其本质就在于将整个生成的所有参数转换为对应的概率分布的概率probability α ′ \alpha ' α′(当然也不一定要使用Soft-max,具体问题具体分析)。
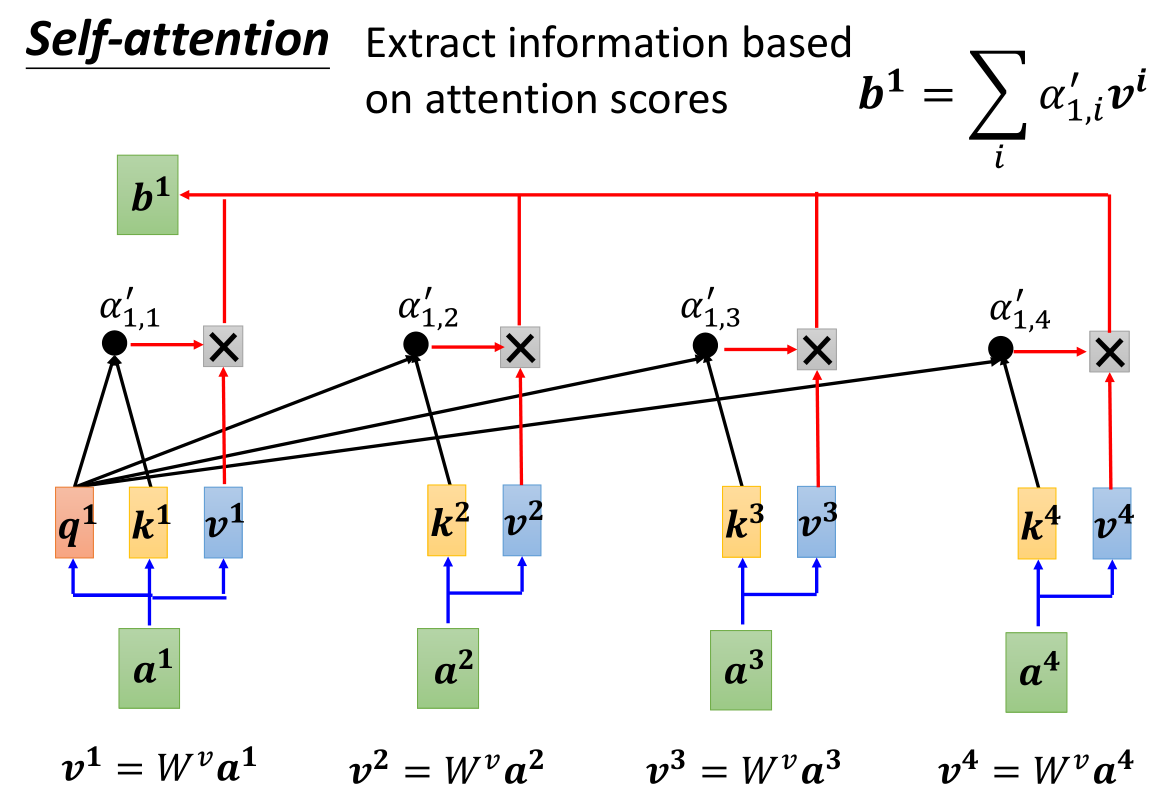
现在我们再加上一个 v = α × W v v=\alpha × W^v v=α×Wv,这个v指的是Value,代表了信息本身,也就是对原来的向量 a a a乘以了一个矩阵变为了我们所需的向量形式,V只是单纯表达了输入特征的信息。我们将 α ′ v \alpha ' v α′v相乘之后累加得到了 b 1 b^1 b1的值,那么我们审视一下这个公式,会发现得到的概率 α ′ \alpha ' α′实际上代表了一种相关性的权重系数,然后再对每个向量的value进行了权重相乘再累加,最后哪个权重系数 α ′ i , j \alpha{'}_{i,j} α′i,j越大,那么 b 1 b^1 b1的值就更接近与其相乘的 v j v^j vj。
其他b也是同理计算得出,并且self-attention层的b1…bn都是并行计算得出的。
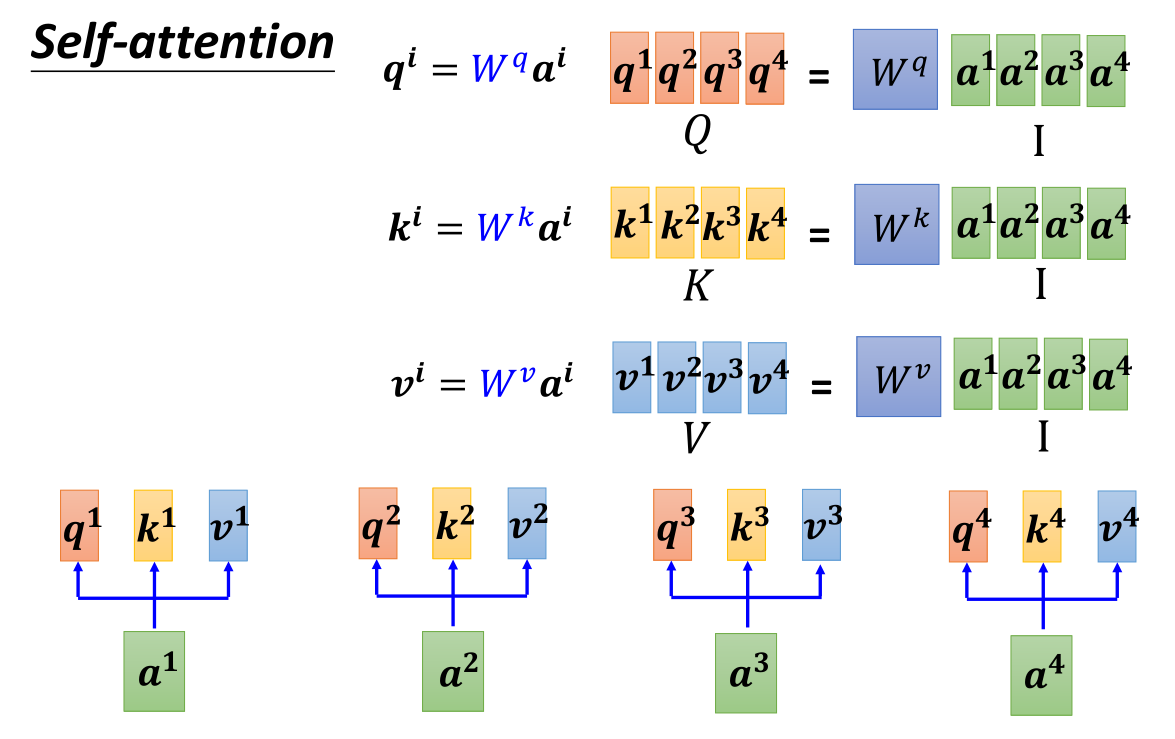
既然对于向量需要进行相同的操作,那么我们不如将向量input表示为矩阵的形式,将其变成矩阵乘法。我们把q,k,v的矩阵称为Q,K,V。输入矩阵为
I
I
I,乘以参数矩阵
W
W
W(通过网络的学习得到)。
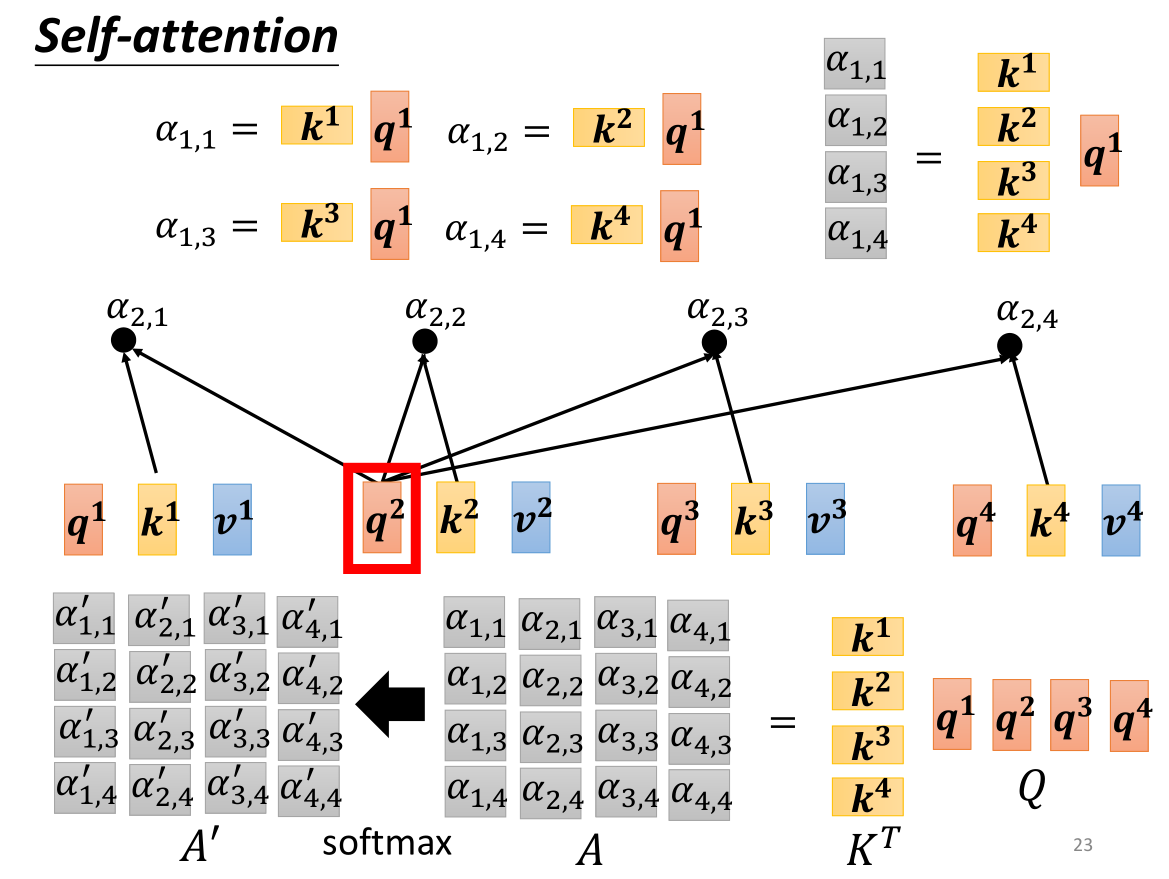
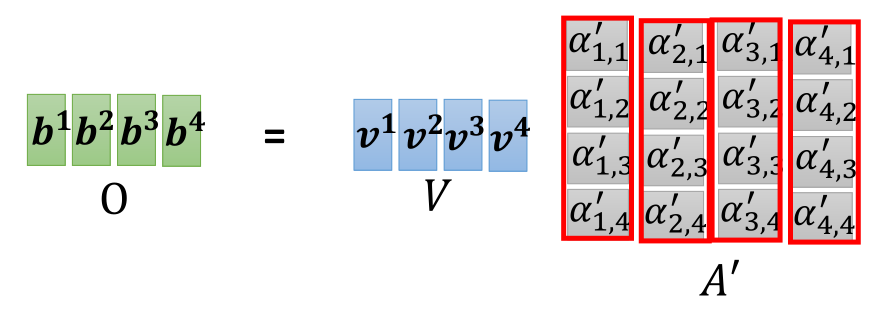
那么如果用矩阵的形式来表示的话,则注意力得分矩阵 A = K T Q A=K^TQ A=KTQ,然后对其进行一些规范化例如softmax得到 A ′ = s o f t m a x ( A ) A'=softmax(A) A′=softmax(A)。随后我们得到output: O = V A ′ O=VA' O=VA′。
Multi-head Self-attention
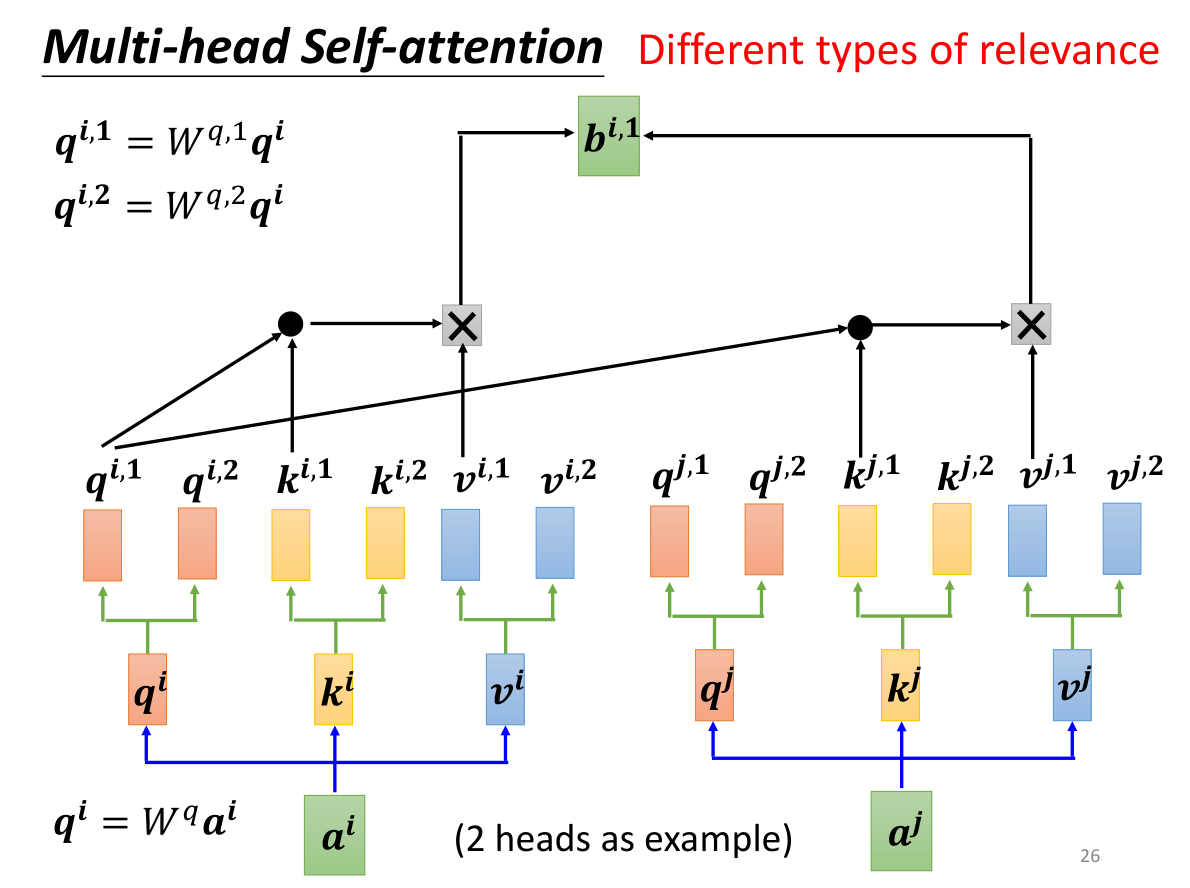
我们说Self-attention的实质是寻找q和k之间的相关性 α \alpha α,但是即使是同一个事物,也会存在不同性质的一些相关性,例如词义上的相关性,发音上的相关性等等…为了选择需要的相关性,一个方法是使用Multi-head Self-attention多头注意力机制,如上图所示,我们将 q i , k i , v i q^i,k^i,v^i qi,ki,vi乘以两个不同的矩阵,就能得到两个不同相关性的 q i , j , k i , j , v i , j q^{i,j},k^{i,j},v^{i,j} qi,j,ki,j,vi,j称为head,但是 q i , 1 q^{i,1} qi,1只会和 k i , 1 o r k j , 1 k^{i,1} ~or ~k^{j,1} ki,1 or kj,1计算内积,也就是将相同相关性的q和k用同一个数字进行标号,然后只对相同数字标号进行内积之后sum得到 b i , 1 b^{i,1} bi,1。多头注意力允许模型能对齐不同表示子空间信息到不同的位置。而普通的只有一个头的注意力会因为求平均而抑制了这一点。

然后我们将得到的
b
b
b拼接起来乘以矩阵
W
O
W^O
WO得到
b
i
b^i
bi
Positional Encoding
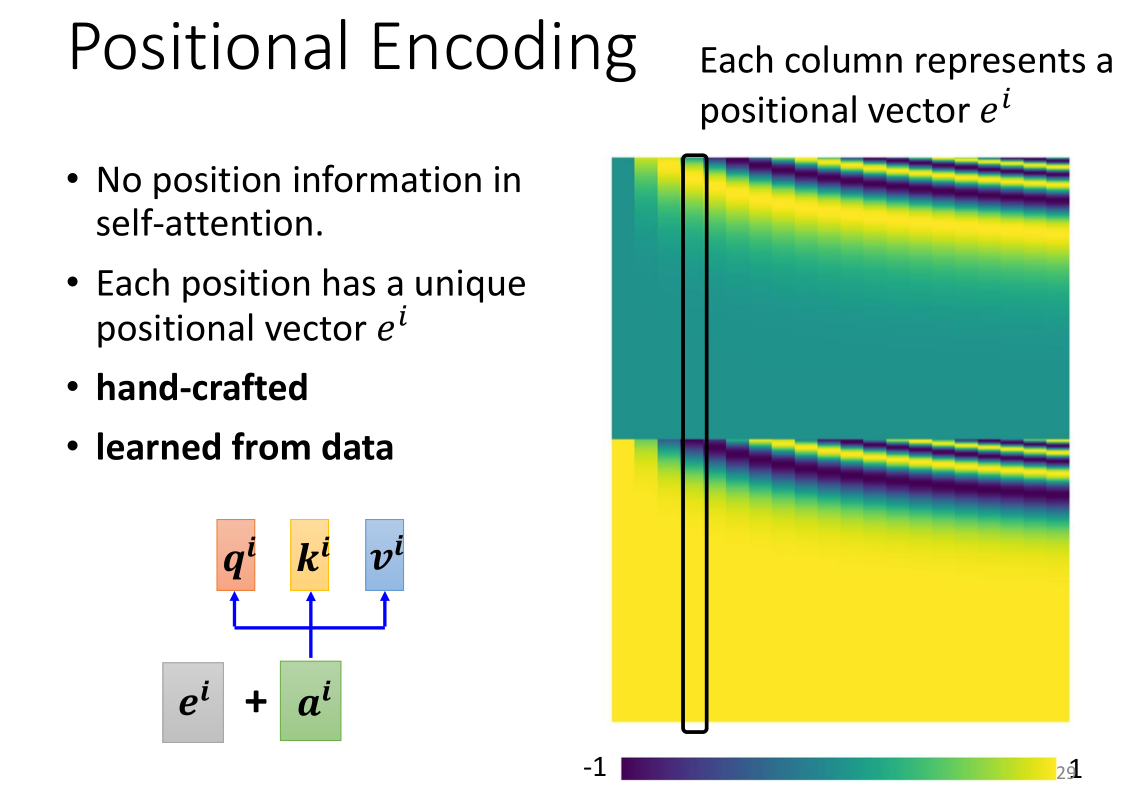
刚才我们进行self-attention计算的时候,其实还缺少一些重要信息——就是得到的output的Positional位置关系。虽然我们在示意图中已经标注了 b 1 , b 2 . . b n b^1,b^2..b^n b1,b2..bn,但是对算法而言,由于是并行计算的,因此它们之间并无差别,也无位置上的关系。因为我们的模型不包含循环和卷积,为了使用序列顺序信息,我们必须接入一些关于序列中单词相对或绝对位置的信息 。
我们使用Positional encoding的机制对位置进行编码,对于每一个位置我们都给上一个专属的Positional向量 e i e^i ei,直接把 e i e^i ei加到 a i a^i ai上就完成了,右图是对位置向量上色后的一张可视化分析图,图中的一整个黑框是一个位置向量。
论文中使用了不同频率的正弦和余弦函数来表示位置编码:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
∕
1000
0
2
i
∕
d
m
o
d
e
l
)
PE_{(pos,2i)}=sin(pos ∕10000^{2i ∕ d_{model}})
PE(pos,2i)=sin(pos∕100002i∕dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
∕
1000
0
2
i
∕
d
m
o
d
e
l
)
PE_{(pos,2i+1)}=cos(pos ∕10000^{2i ∕ d_{model}})
PE(pos,2i+1)=cos(pos∕100002i∕dmodel)
其中 p o s pos pos代表位置, i i i代表维度,也就是说,位置编码的每个维度都对应一个正弦曲线。波长形成一个从 2 π 2\pi 2π到 10000 π 10000 \pi 10000π的等比数列,我们之所以选择这个函数,是因为我们假设这个函数可以让模型很容易地学到相对位置的注意力,因为对于任何固定的偏移量 k k k, P E p o s + k PE_{pos+k} PEpos+k都能表示为 P E p o s PE_{pos} PEpos的一个线性函数。
论文也实验了学习后的位置嵌入,然后发现这两种方式产生了几乎同样的结果。我们选择正弦版本是因为允许模型推断比训练期间遇到的更长的序列。
不过Positional Encoding如何选取仍然是一个暂待研究的问题。
Self-attention的应用
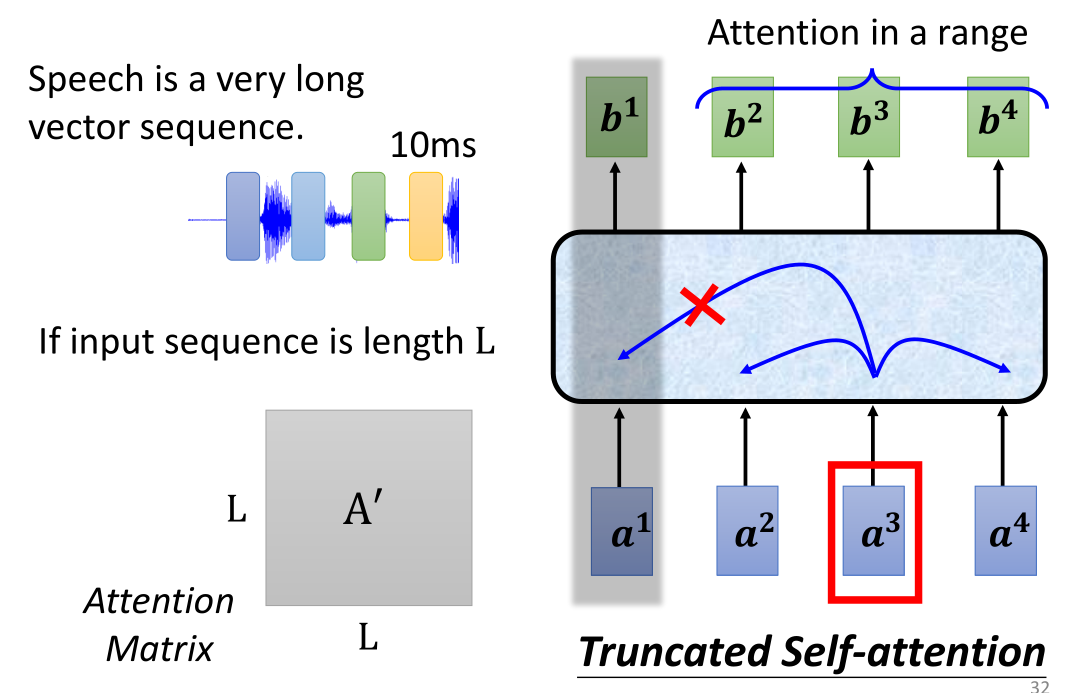
Self-attention最广泛的应用就是我们要讲到的transformer以及BERT,除了在处理语句之外,Self-attention在处理音频或者图片上也存在许多应用。例如我们之前说过的语音处理,使用方式和我们刚刚所讲的语句处理是一样的,但是我们之前讲过,音频的设置往往是window每10ms截取一个向量,那么1s就有100个向量,因此处理音频往往会导致出现过长的sequence,因此计算量和内存就会非常的大,不容易进行处理和训练,因此我们会使用到一个叫做Truncated Self-attention(截断自注意力)的机制,简单来说就是sequence太长就分块切开处理。(我发现处理太长太多的思想都是一样的,要么分块分批,给一个window或者切块或者确定batch-size,要么直接把它变小,例如kernel或者映射或者embedding)
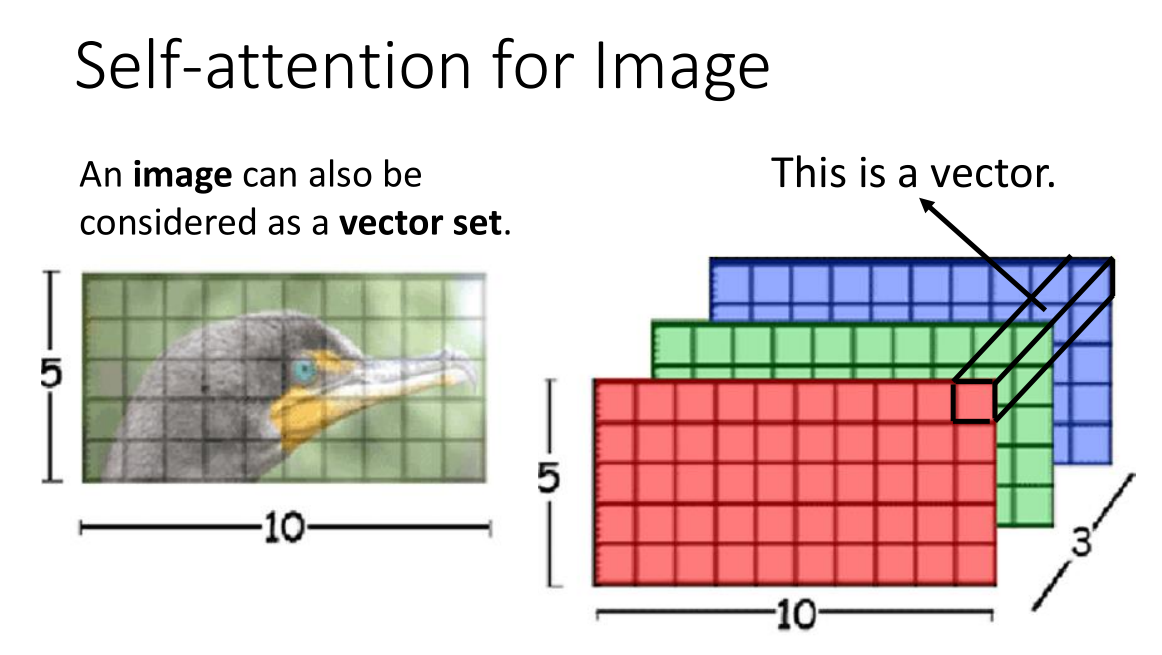
Self-attention也可以用在图像上,我们在讲CNN卷积网络的时候说:图像在于卷积核计算的时候可以看作按列展开的一个向量。当然我们也可以将其看作一个vector set,例如一张RGB图片在三维上展开,我们可以将三个通道的同一个像素看作一个向量,那么整张图片就是一个数量为像素尺寸的向量集合。Self-attention GAN和DEtection Transformer(DETR)就使用了Self-attention来处理图像。
Self-attention对比其他算法
vs CNN

其实CNN和Self-attention的机制还是很像的,例如CNN可以视为卷积核上的一个加权计算求和,本质上就是对小范围的信息的一个self-attention,CNN的卷积核就相当于对这个卷积窗口大小的input进行了self-attention的计算。而self-attention是对整体输入的加权计算求和。CNN的接受域是人为划定的,而self-attention的接受域是通过对相关性的学习计算得到的
如果究其本质,CNN就是简化版的Self-attention,Self-attention就是复杂版的CNN。
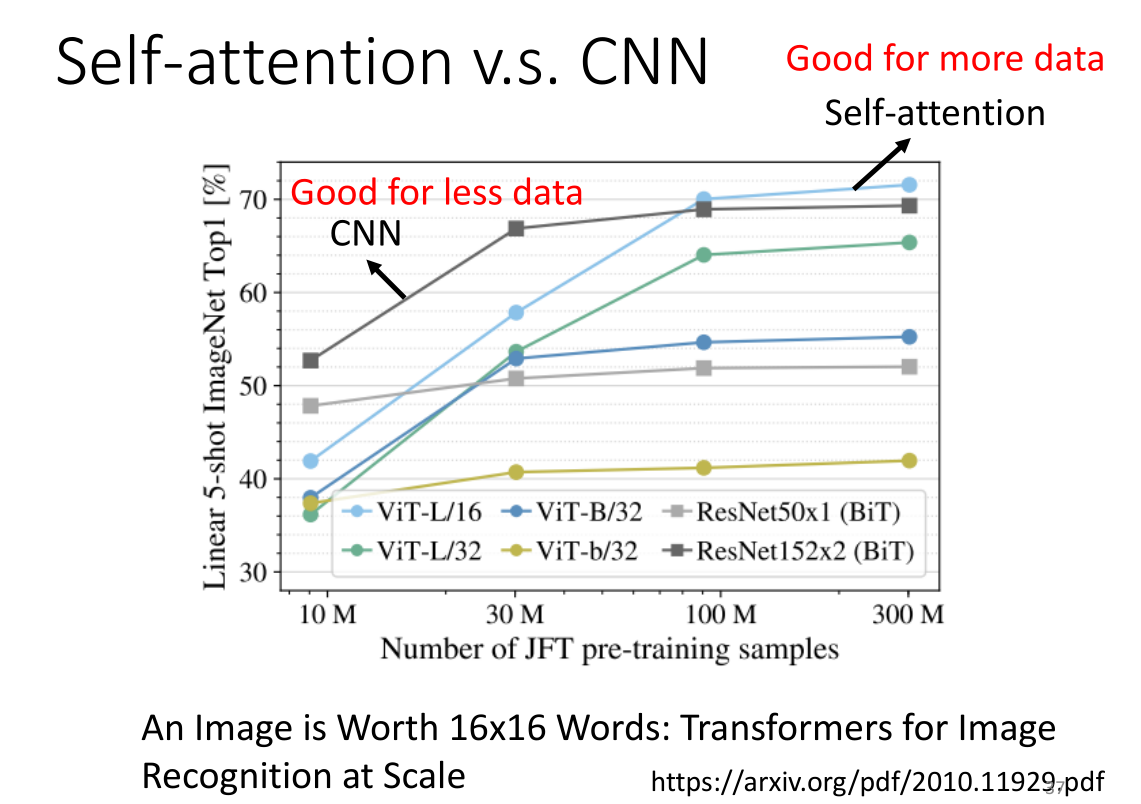
这篇论文通过测试得到了一个结论:当训练量较小的时候CNN效果会更好,而训练量大的时候self-attention效果更好
vs RNN
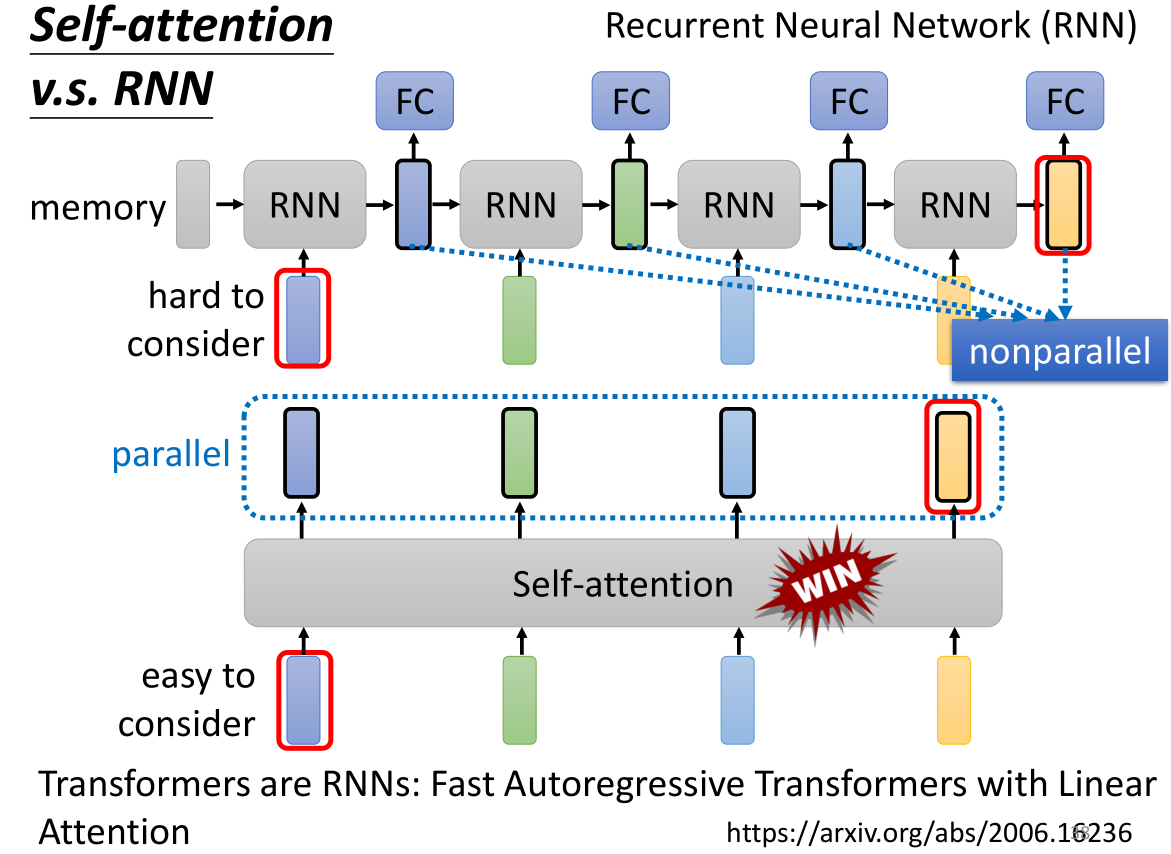
我们看上面介绍的RNN的整个处理过程,其中我们要给到一个空间memory用于存储上一次RNN计算的结果,然后将每一个vector输入到RNN和上一个output进行计算,得到一个新的output,然后送入FC全连接层,重复直到所有vector都计算完毕。
我们比较一下这两种方式:
首先这两个model 的input都是同样的sequence,但是对于self-attention它考虑到了所有的sequence里的input进行的相关性计算,而RNN只能考虑到左边给出的output结果,除非RNN是双向的才能考虑到整个sequence。
其次在计算上,RNN是串行计算,而self-attention是并行计算,如果在RNN中我们要考虑最右边黄色向量的输出与sequence的关系,那么就要经历整个过程,从最左边开始,让memory存放这个蓝色的输入向量,一路带到最右边,直到计算到右边的黄色向量的输出位置为止。而self-attention可以轻易的考虑sequence上的关系。
并且RNN没办法一次性产生许多的output,这就意味着很难计算过长的sequence,而self-attention就没有这个问题。
对比RNN,self-attention不能说是势均力敌,只能说是完爆。所以RNN也逐渐被取代了。
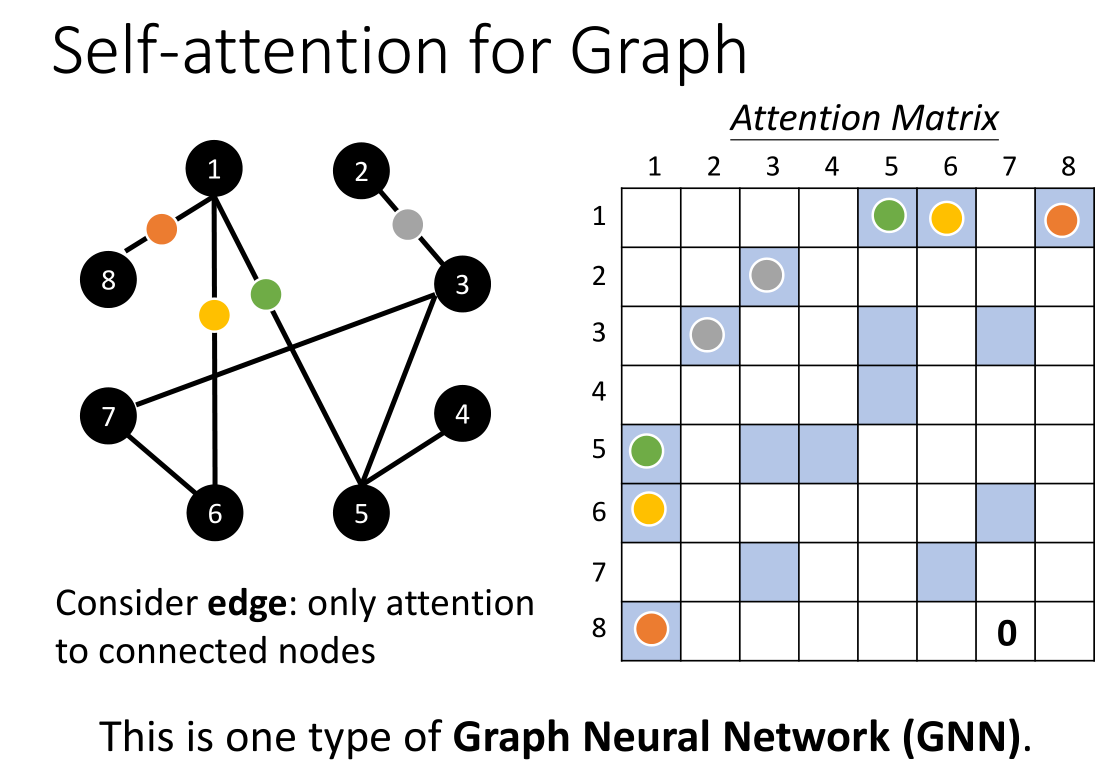
最后是讲到了self-attention在图上的应用,例如上面给出的这个graph,其实我们发现如果结点代表了input的向量,那么节点之间的相关性,例如点1和点8的关系,其实不就是它们之间的那条边吗?因此self-attention如果用于graph,那么整个相关性其实我们就可以用图的邻接矩阵来进行表示,这个邻接矩阵就是self-attention的attention矩阵。这种思想也可以算是某种类型的GNN。
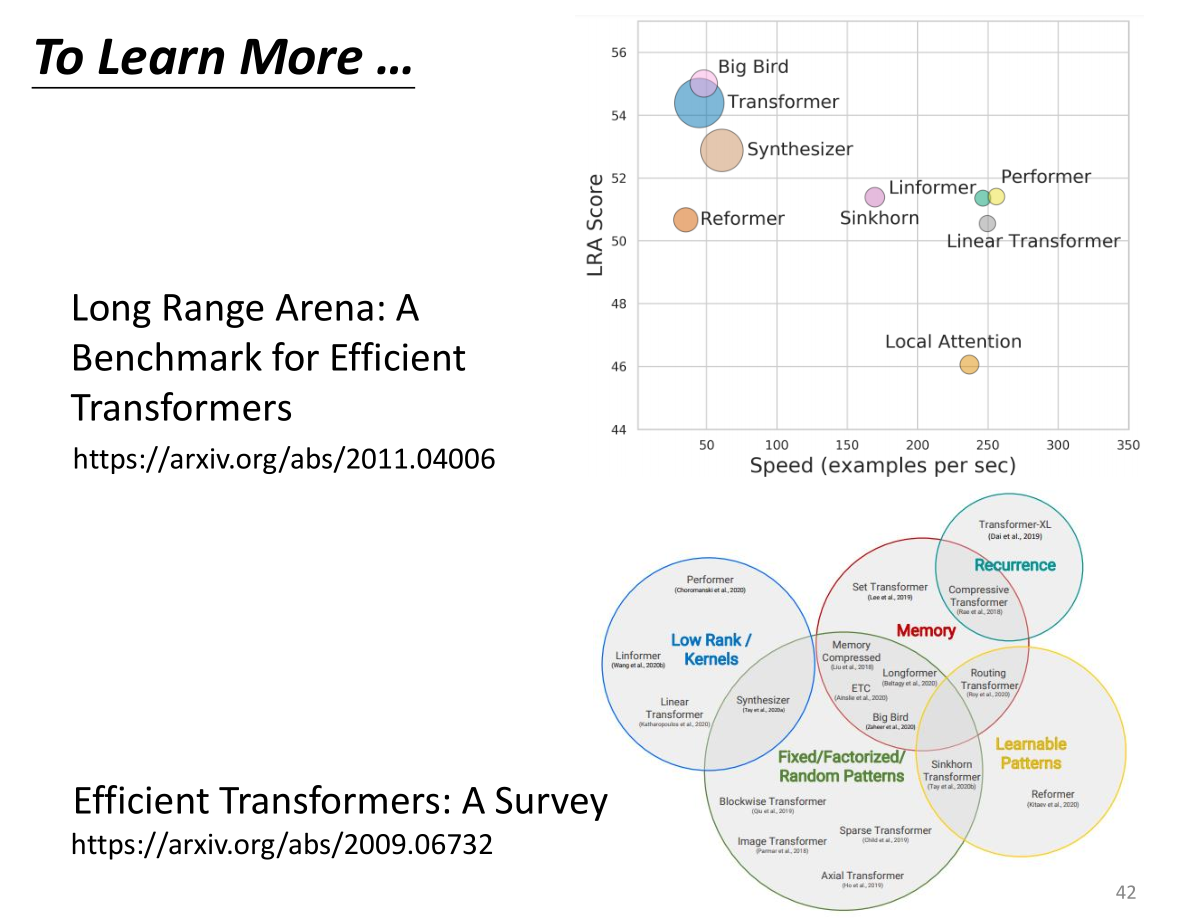
self-attention也有多种不同的变形(最原始的self-attention用于transformer,所以transformer就是指的self-attention),后面也出现了许多XXXformer,例如Linformer,Performer,Linear Transformer等等,它们都是旨在解决transformer的计算慢的问题。但是对应的,计算速度变快带来的是score变低,也就是效果变差,如何找到一个又快又好的former依然是一个待解决的问题。
总结
本节课还是相当简单易懂的,该笔记也就是照抄文案然后加上自己的一些理解,推荐看李老师的原视频

