
- 1首起针对国内金融企业的开源组件投毒攻击事件_组件投毒 数据库
- 2项目体检(Health Check)升级上线
- 3Mac系统安装及配置python_macbook如何安装python2
- 4python读程序写结果-31.Python:文件读写
- 5Git+TortoiseGit详细安装教程(HTTP方式)_tortoisegit http
- 6Python的日志输出_python日志输出到文件
- 7Springboot+Vue项目-基于Java+MySQL的图书馆管理系统(附源码+演示视频+LW)
- 8阅读小车循迹论文笔记:灰度传感器、仿生处理器、路径跟踪机制()_灰度传感器原理图
- 9SIDE:开启研发新的颠覆式的开发体验
- 10Flask-SQLAlchemy的使用(详解)_flask sqlalchemy options
2024山东大学软件学院创新实训——智慧医疗问答系统(三)
赞
踩
ChatGML微调训练医疗问答任务
目录
一. ChatGLM2-6B
ChatGLM2-6B 是 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,同时引入了许多新特性,如:更强大的性能、更长的上下文、更高效的推理、更开放的协议 等。
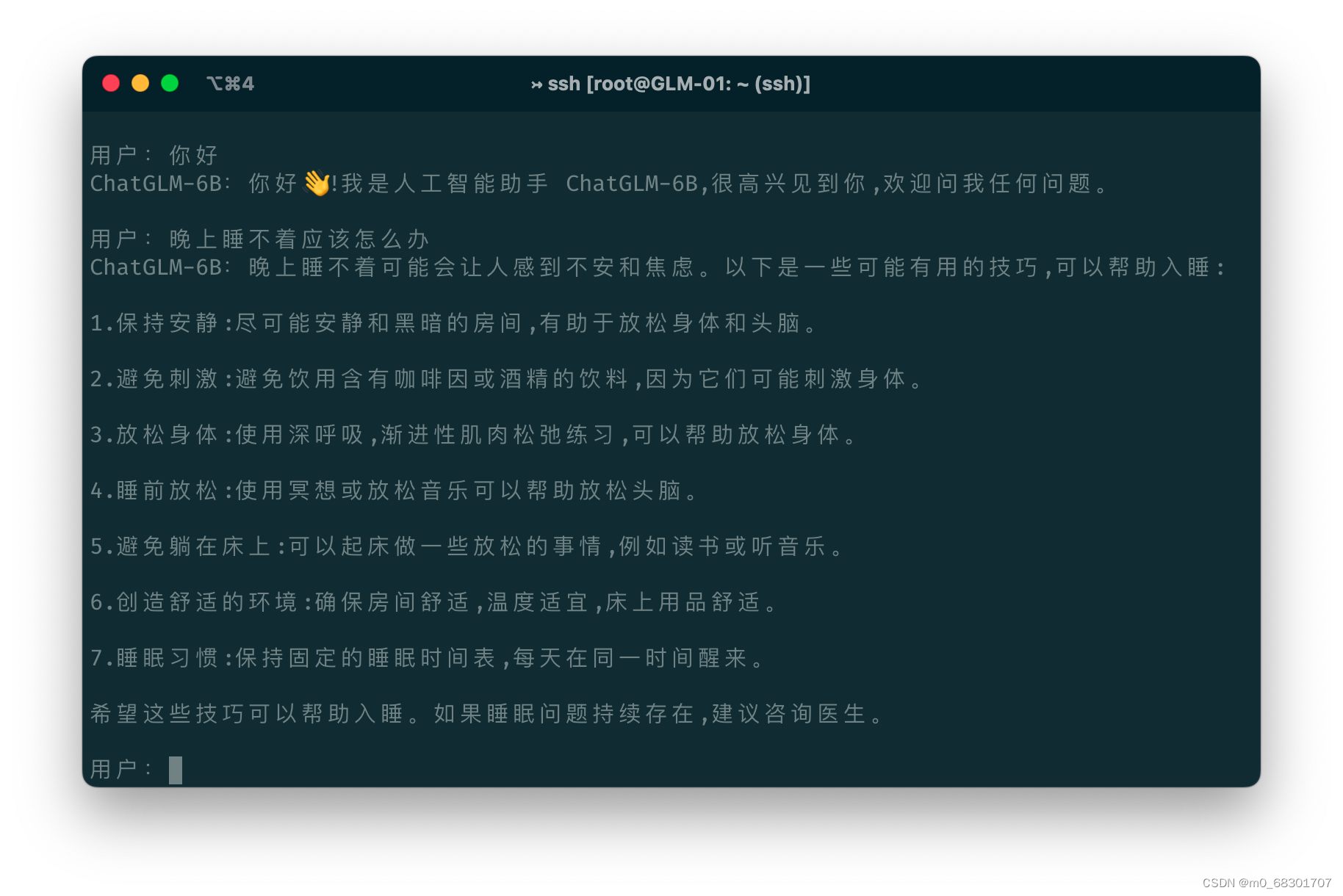
(1)cli_demo
cli界面是通过在命令行之内直接交互来进行问答的,如下图所示:
(2)web_demo
web_demo界面是通过在Web网页中进行交互问答的,如下图所示:
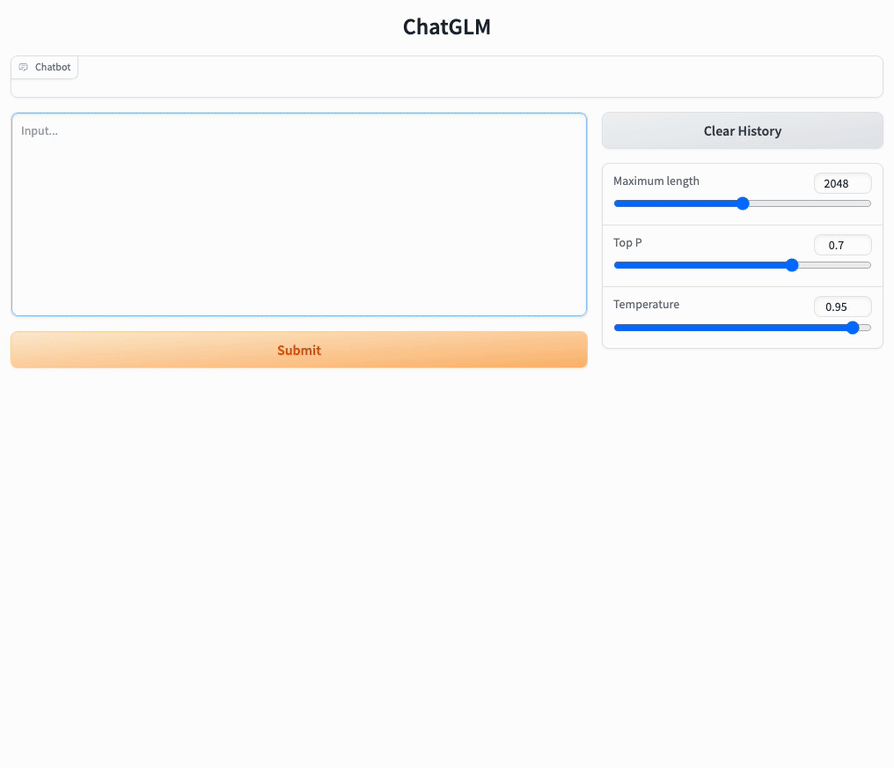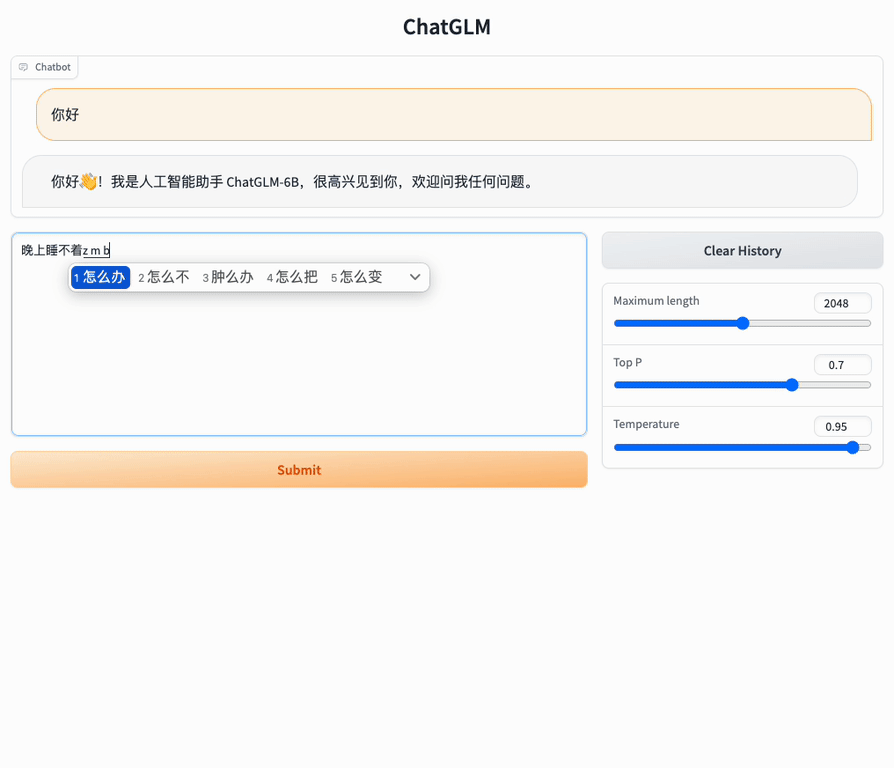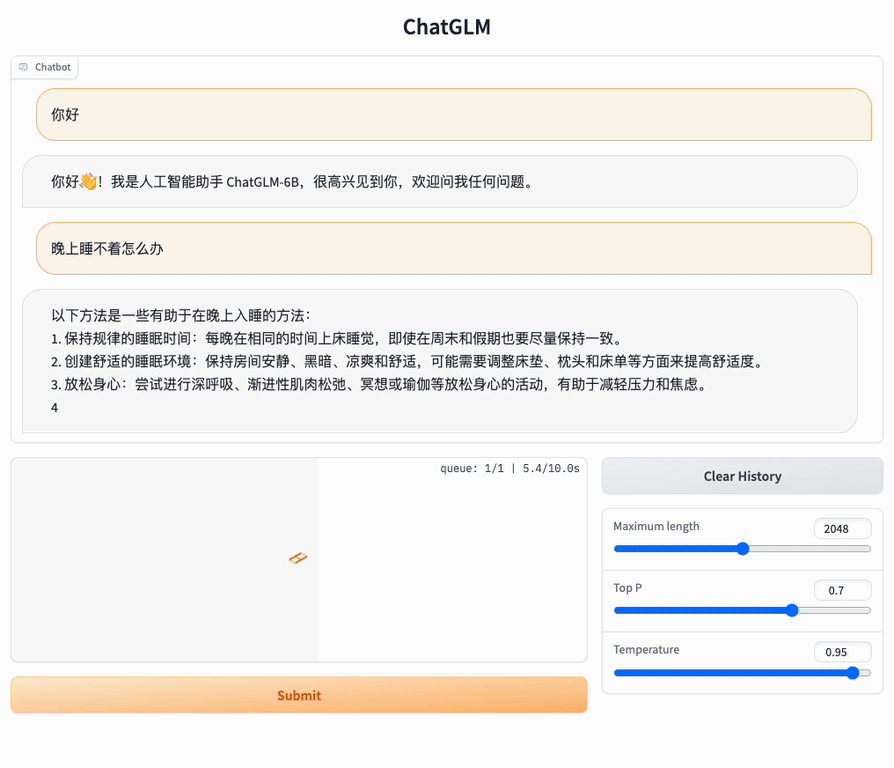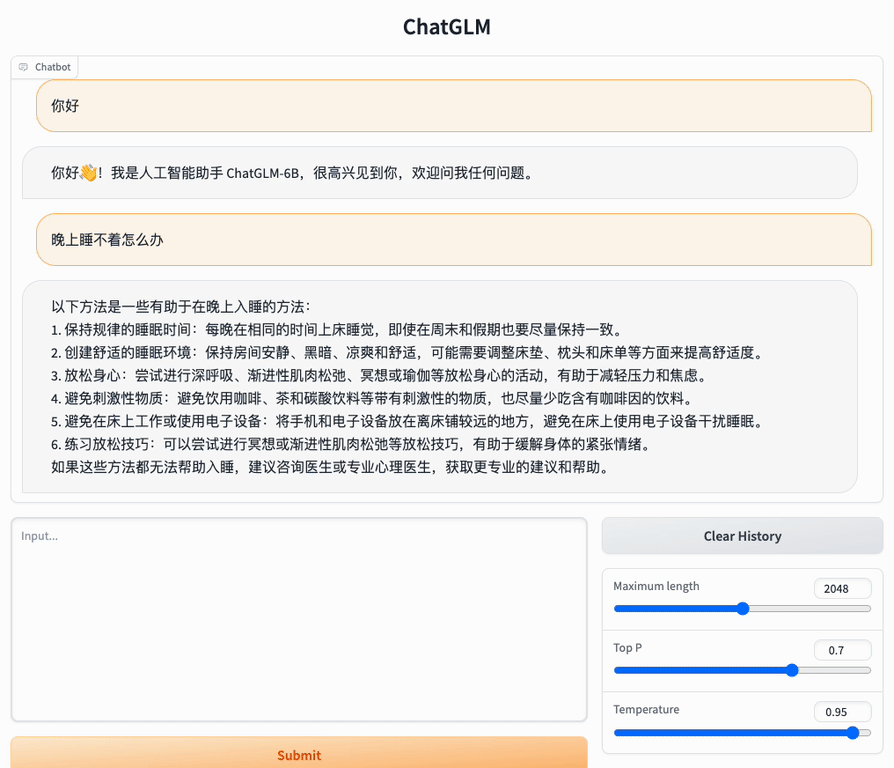
(3)web_demo2
web_demo2界面也是通过在Web网页中进行交互问答的,如下图所示:

二. P-tuning-v2
参考论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
微调技术:使用ChatGLM 官方推出的 P-tuning-v2
P-tuning v2 微调技术利用 deep prompt tuning,即对预训练 Transformer 的每一层输入应用 continuous prompts 。deep prompt tuning 增加了 continuo us prompts 的能力,并缩小了跨各种设置进行微调的差距,特别是对于小型模型和困难任务。
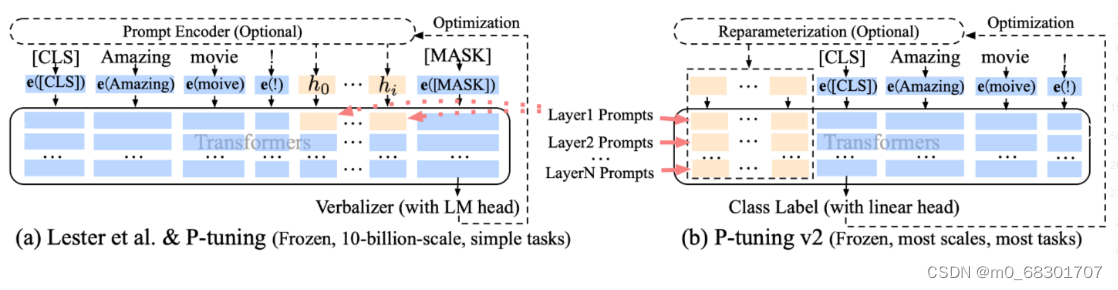
左图为P-tuning,右图为P-tuning v2
三. 模型下载
huggingface 地址:https://huggingface.co/THUDM/chatglm2-6b/tree/main
注意:这里将模型文件下载到了ChatGLM2-6B/THUDM/chatglm2-6b目录下

四. 数据集处理
使用 GitHub 上的 Chinese-medical-dialogue-data 中文医疗问答数据集
下载地址:https://github.com/Toyhom/Chinese-medical-dialogue-data
“Data_数据”中共有六个文件夹,包含792099条数据。分别是:
- <Andriatria_男科> ——含有94596个问答对
- <IM_内科> ——含有220606个问答对
- <OAGD_妇产科> ——含有183751个问答对
- <Oncology_肿瘤科> ——含有75553个问答对
- <Pediatric_儿科> ——含有101602个问答对
- <Surgical_外科>——含有 115991个问答对
数据格式如下:
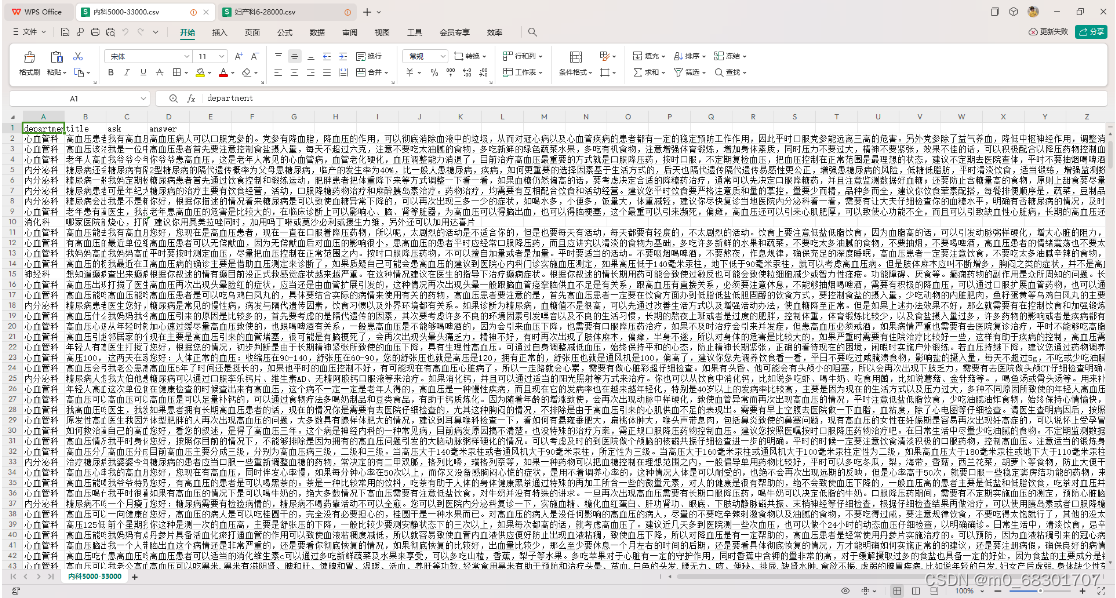
其中 ask 为病症的问题描述,answer 为病症的回答。
整体加起来数据比较多,这里为了演示效果,只训练 内科、肿瘤科、儿科、外科 四个科目的数据,并且每个科目取前 1000 条数据进行训练、200 条数据进行验证:
- import json
- import pandas as pd
-
- data_path = [
- "./Chinese-medical-dialogue-data-master/Data_数据/IM_内科/内科5000-33000.csv",
- "./Chinese-medical-dialogue-data-master/Data_数据/Oncology_肿瘤科/肿瘤科5-10000.csv",
- "./Chinese-medical-dialogue-data-master/Data_数据/Pediatric_儿科/儿科5-14000.csv",
- "./Chinese-medical-dialogue-data-master/Data_数据/Surgical_外科/外科5-14000.csv",
- ]
-
- train_json_path = "./train.json"
- val_json_path = "./val.json"
- # 每个数据集取一定数量的记录作为训练集和验证集
- train_size = 1000
- val_size = 200
-
- def doHandler():
- train_data = []
- val_data = []
- for path in data_path:
- data = pd.read_csv(path, encoding='GB18030')
- for index, row in data.iterrows():
- ask = row["ask"]
- answer = row["answer"]
- line = {
- "content": ask,
- "summary": answer
- }
- if len(train_data) < train_size:
- train_data.append(line)
- elif len(val_data) < val_size:
- val_data.append(line)
- # 由于我们已经有了 train_size 和 val_size 的数据,我们停止循环
- if len(train_data) >= train_size and len(val_data) >= val_size:
- break
- else:
- continue # 只有当没有触发 break 时才继续处理下一个文件
-
- # 如果我们已经有了足够的数据,我们停止处理文件
- if len(train_data) >= train_size and len(val_data) >= val_size:
- break
-
- # 将数据转换为 JSON 字符串并写入文件
- with open(train_json_path, "w", encoding='utf-8') as train_f:
- train_f.write("[\n")
- train_f.write(",\n".join(json.dumps(x, ensure_ascii=False) for x in train_data))
- train_f.write("\n]\n")
-
- with open(val_json_path, "w", encoding='utf-8') as val_f:
- val_f.write("[\n")
- val_f.write(",\n".join(json.dumps(x, ensure_ascii=False) for x in val_data))
- val_f.write("\n]\n")
-
- print("数据处理完毕!")
-
- if __name__ == '__main__':
- doHandler()

运行上述代码后可以看到data文件夹下出现了两个文件:train.json 和 val.json
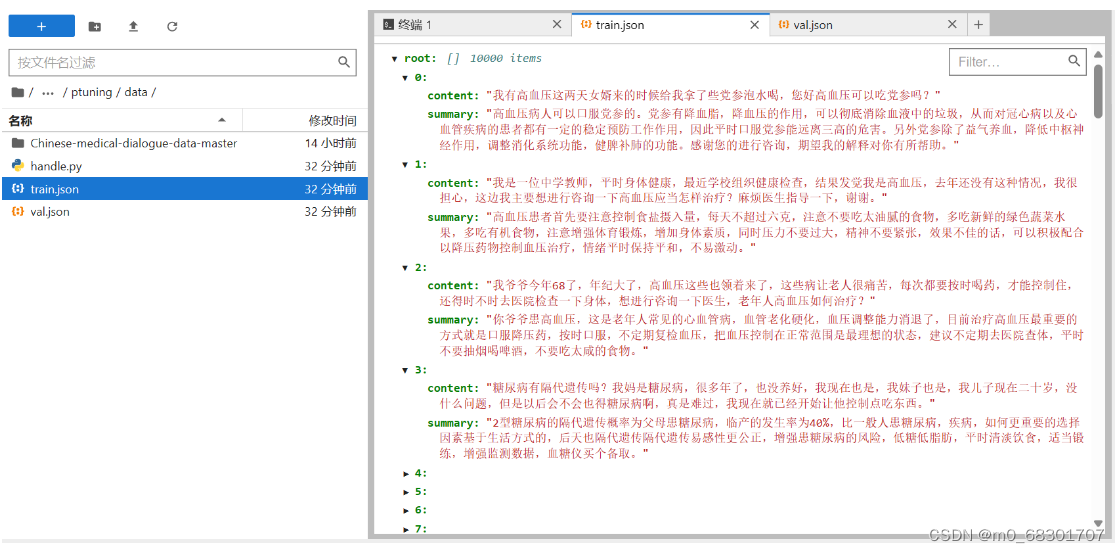
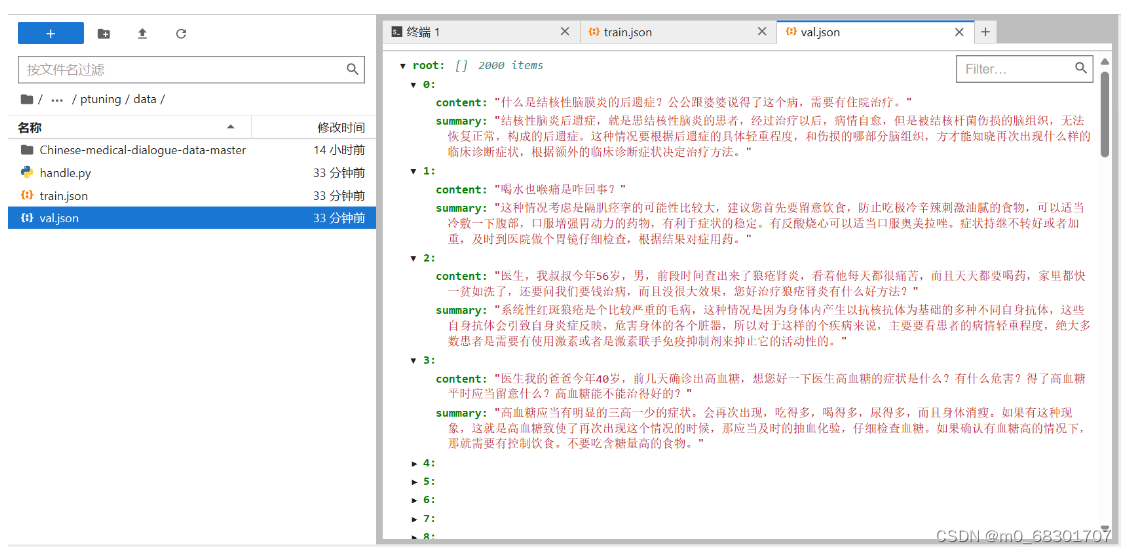
五. 模型微调
运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
先看官网提供的shell脚本文件train.sh:
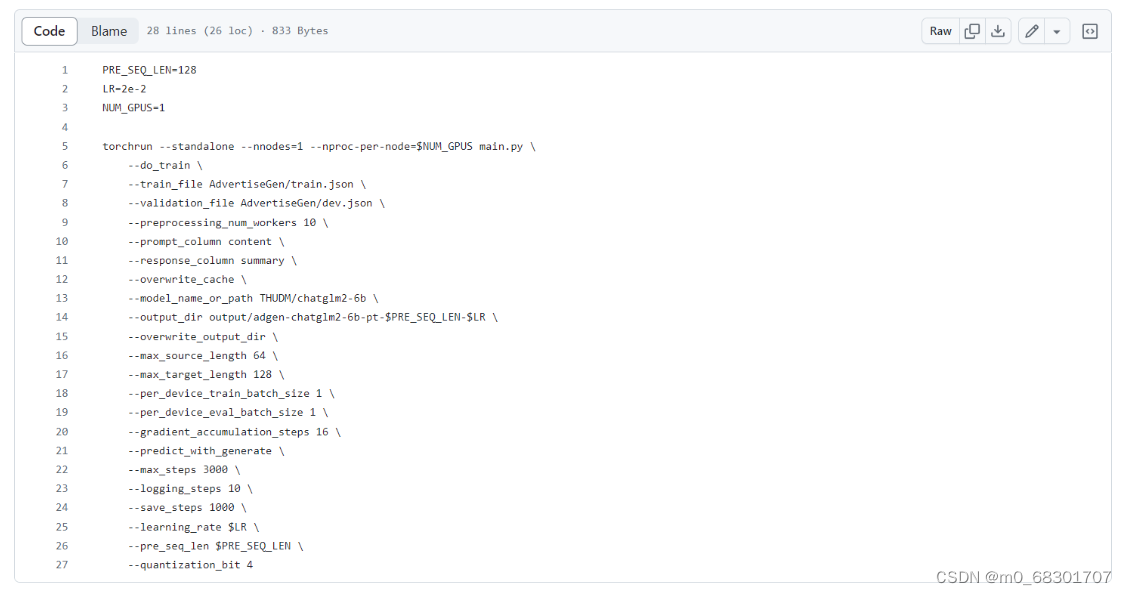
需要修改train.sh文件参数
train_file:训练集路径, 改为前面生成的 train.json 文件所在路径。
validation_file:验证集路径, 改为前面生成的 val.json 文件所在路径。
model_name_or_path:预训练模型的名称或路径,改为模型文件下载到的目录路径,我这里是../THUDM/chatglm2-6b
修改后的train.sh:
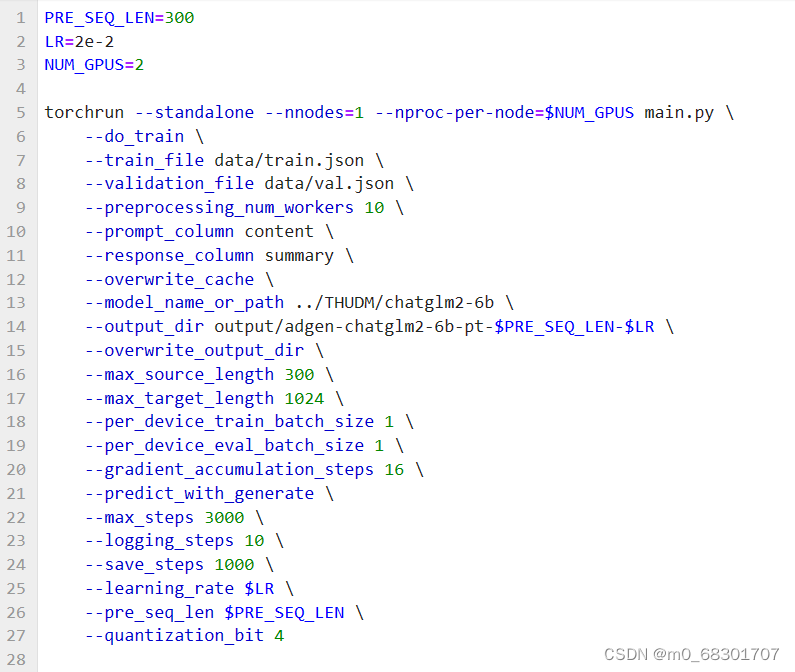
执行脚本 bash train.sh,开始训练
小tips:如果报错'ChatGLMModel' object has no attribute 'prefix_encoder',则需要更新模型文件chatglm2-6b至最新
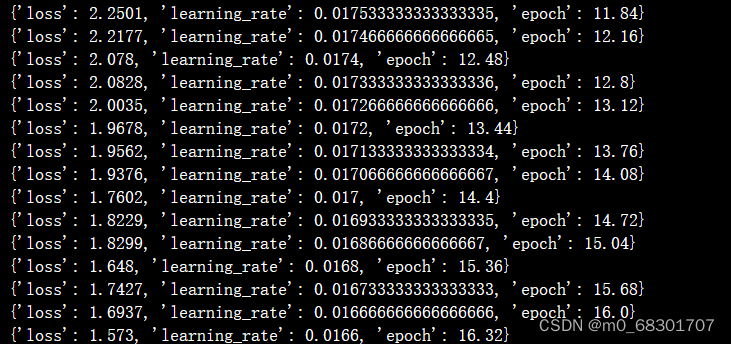
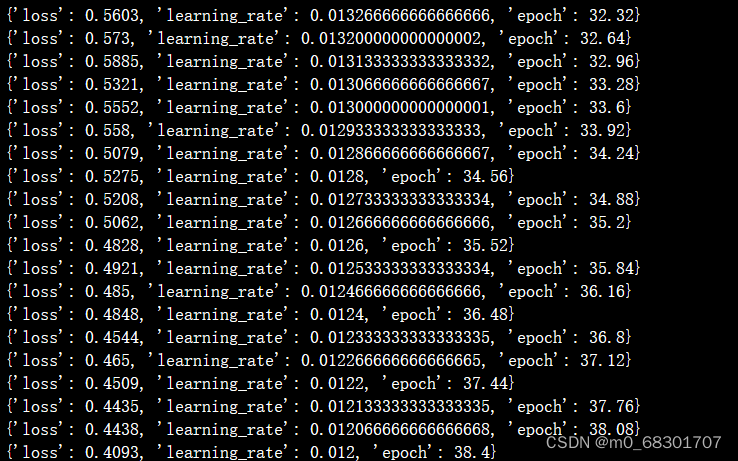
训练过程:
六. 模型推理
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM2-6B 模型以及 PrefixEncoder 的权重,因此需要指定 evaluate.sh 中的参数:
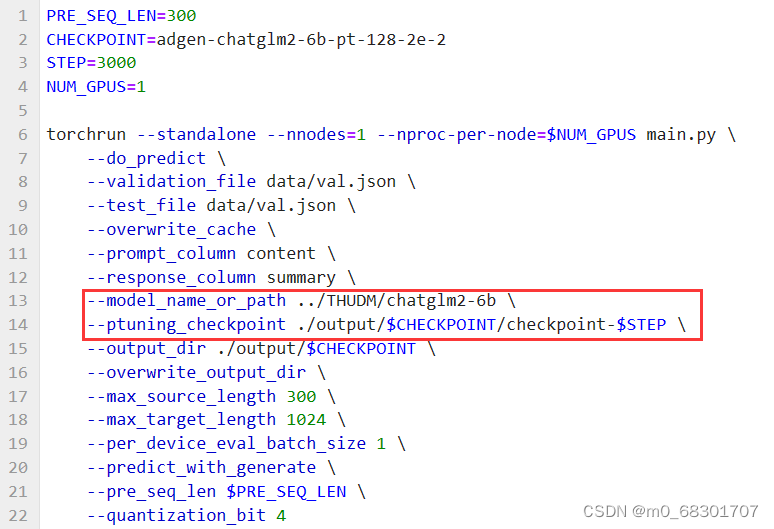
执行脚本 bash evaluate.sh
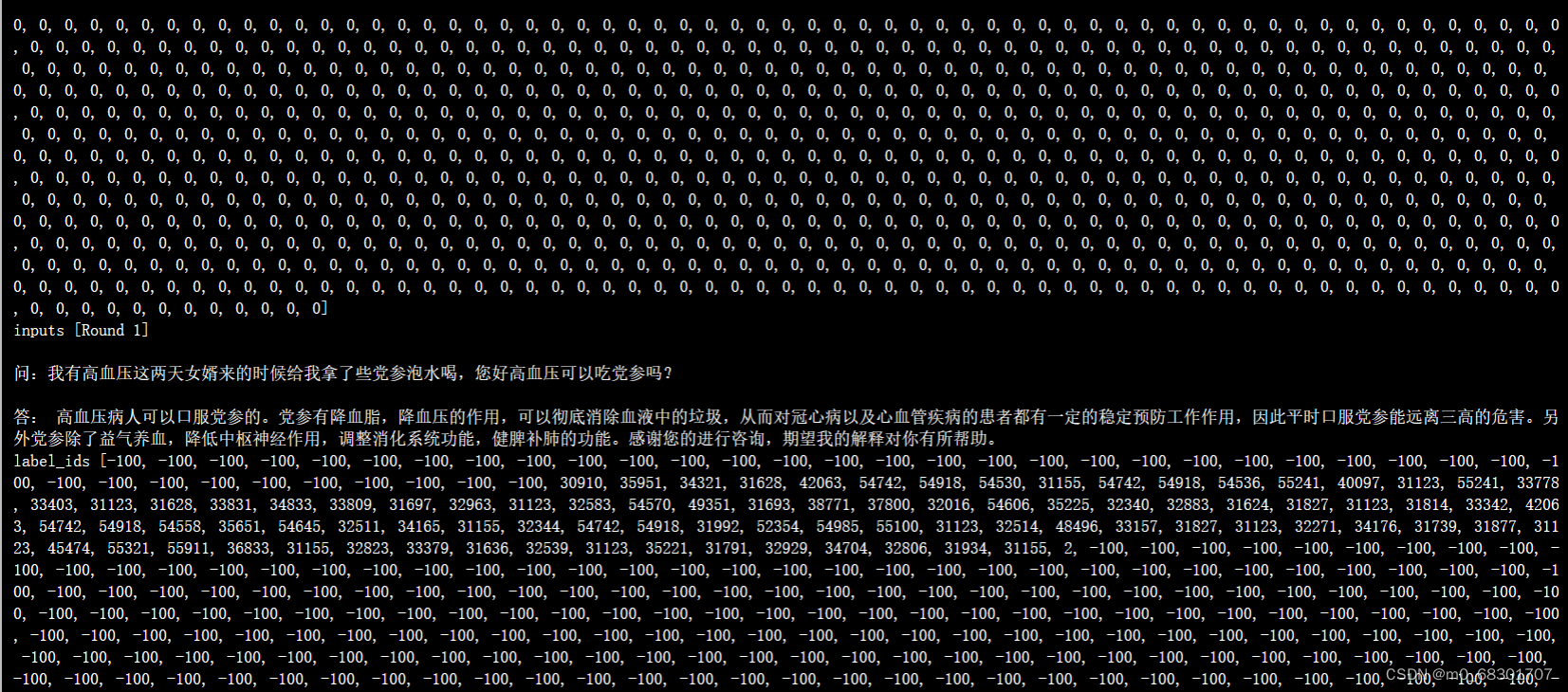
推理过程:
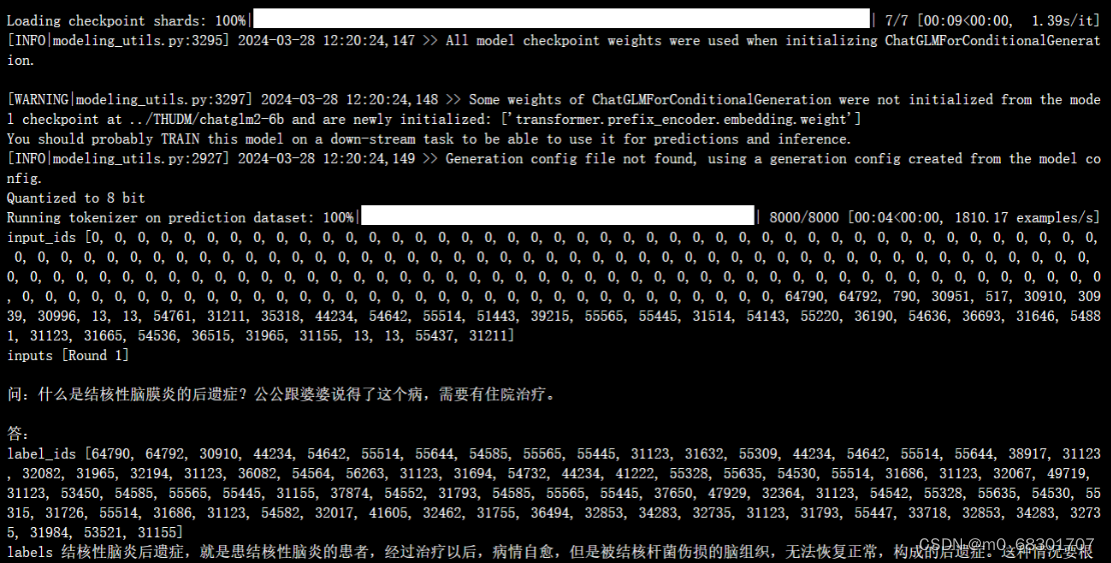
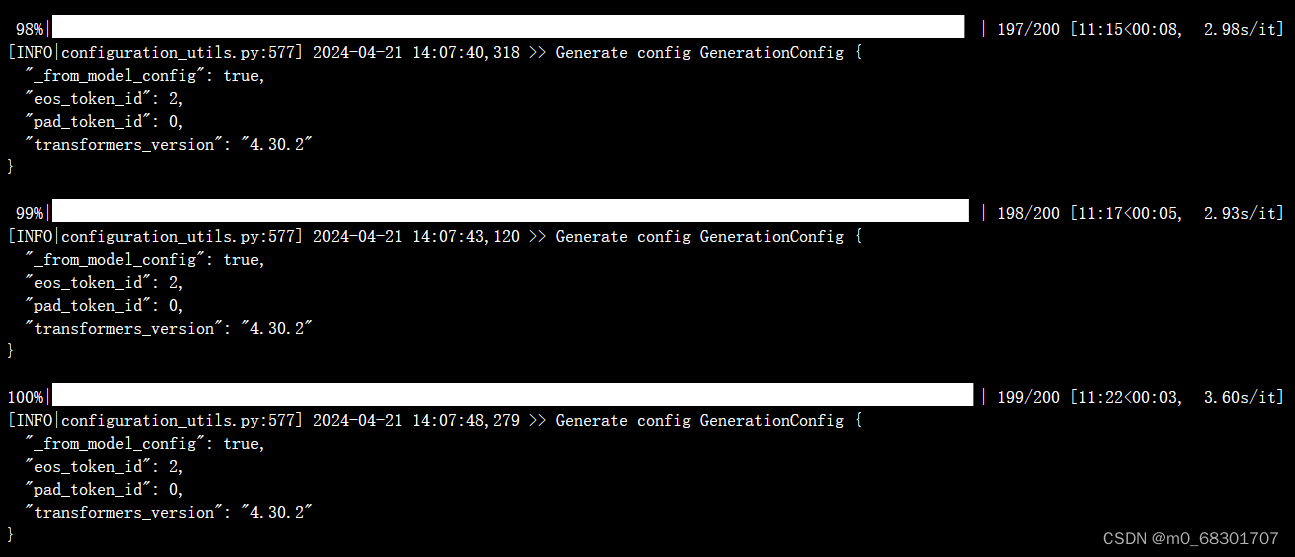
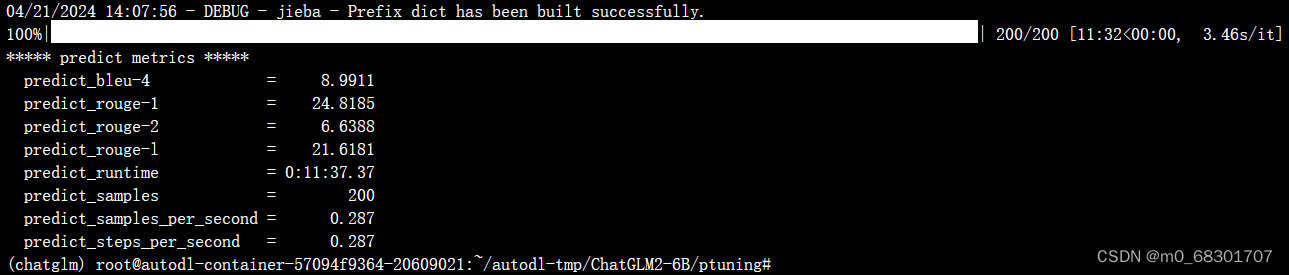
评测指标为中文 Rouge score 和 BLEU-4。生成的结果保存在 ./output/adgen-chatglm2-6b-pt-300-2e-2/generated_predictions.txt
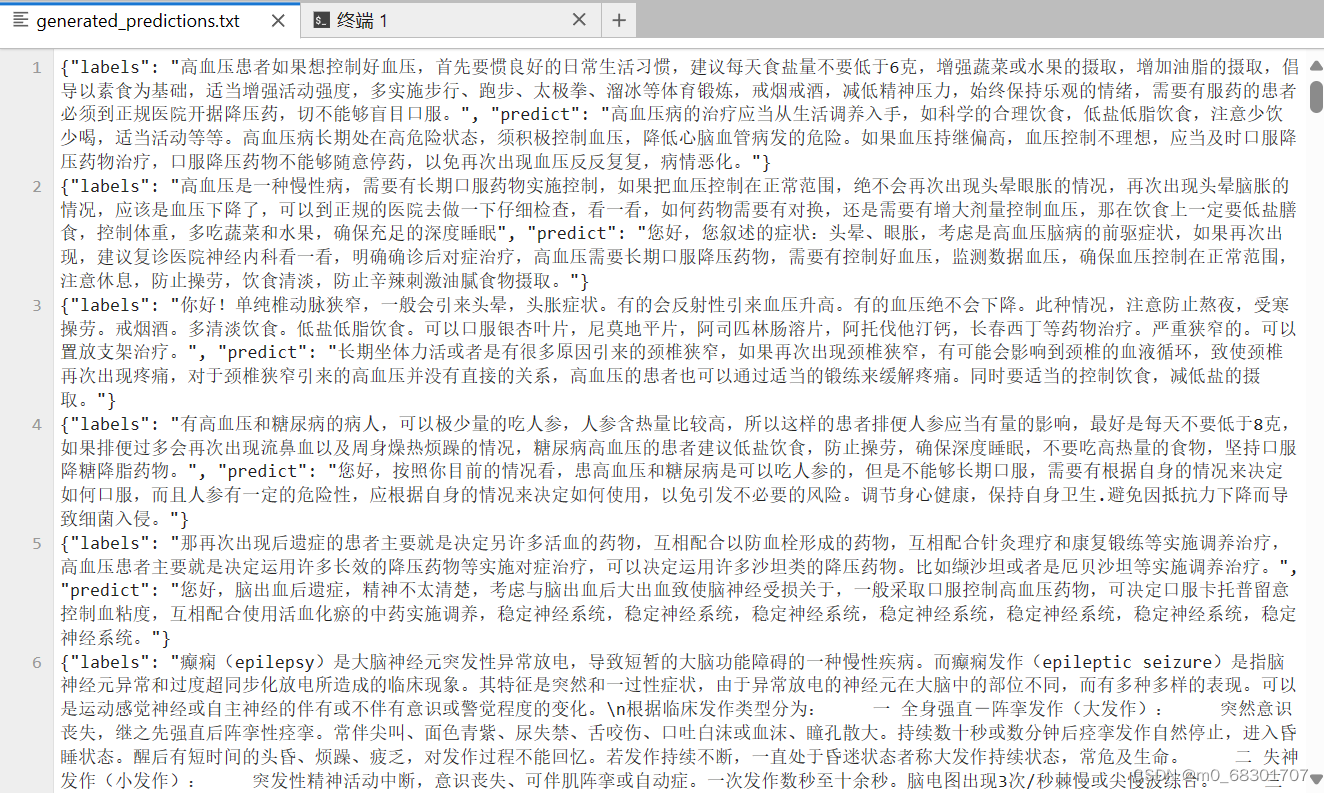
我们准备了 200 条推理数据,所以相应的在文件中会有 200条评测数据。其中labels 是 val.json 中的预测输出,predict 是 ChatGLM2-6B 生成的结果。通过对比预测输出和生成结果,可以评测模型训练的好坏。如果不满意可以重新调整训练的参数再次进行训练。
七. 模型检测
运行以下代码test.py单独调用测试
- from fastapi import FastAPI, Request
- from fastapi.middleware.cors import CORSMiddleware
- from transformers import AutoTokenizer, AutoModel, AutoConfig
- import uvicorn, json, datetime
- import torch
- import os
-
-
- def main():
- pre_seq_len = 300
- # 训练权重地址
- checkpoint_path = "ptuning/output/adgen-chatglm2-6b-pt-300-2e-2/checkpoint-3000"
-
- tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
- config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=pre_seq_len)
- model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, device_map="auto", trust_remote_code=True)
- prefix_state_dict = torch.load(os.path.join(checkpoint_path, "pytorch_model.bin"))
- new_prefix_state_dict = {}
- for k, v in prefix_state_dict.items():
- if k.startswith("transformer.prefix_encoder."):
- new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
- model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
- # 量化
- model = model.quantize(4)
- model.eval()
-
- # 问题
- question = "我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?"
-
- response, history = model.chat(tokenizer,
- question,
- history=[],
- max_length=2048,
- top_p=0.7,
- temperature=0.95)
-
- print("回答:", response)
-
- if torch.backends.mps.is_available():
- torch.mps.empty_cache()
-
-
- if __name__ == '__main__':
- main()
-

八. 对比微调前后效果
- >>> display_answer(model, "哪些原因会致使幽门螺旋杆菌?吃了久置的面包会感染吗?")
-
- # 微调前
- 幽门螺旋杆菌 (Hp) 是一种常见的胃病幽门螺杆菌感染 ( Helicobacter pylori infection) 的病原体,它通常是通过口腔与胃部之间的幽门传播。
- 久置的面包本身不会导致幽门螺旋杆菌感染。但是,如果面包没有正确地存储或处理,可能会受到污染并导致细菌滋生。久置的面包可能会成为细菌滋生的温床,因此建议在食用前将其彻底放入冰箱并确保在保质期内食用。
- 然而,如果您食用了被幽门螺旋杆菌感染的食物,则可能成为携带者或患者。因此,建议您避免食用过期或被污染的食物,并注意个人卫生,以降低感染幽门螺旋杆菌的风险。如果您有消化问题,请咨询医生以获取更具体的建议。
-
- # 微调后
- 幽门螺旋杆菌是一种常见的幽门螺旋杆菌感染,幽门螺旋杆菌感染的主要原因是由于幽门螺旋杆菌通过不洁的食物或水传染给,幽门螺旋杆菌通过空气传给,也可以从母体传染给孩子。幽门螺旋杆菌感染的常见症状有:胃炎,消化性溃疡,胃癌,胃炎,胃炎,胃炎等。
- 吃久置的面包不一定会感染幽门螺旋杆菌。但是,如果面包保存不当,例如温度过高或过低,或者保存时间过长,可能会引来细菌的滋生,因此建议您吃新鲜的面包。以免引发动脉炎。
- >>> display_answer(model, "现在假定你是一名医生。有如下对话历史:\n患者:肠胃不好,胃有点胀,经常放屁。(男,22岁)\n医生:你好,这种情况多久了\n根据上述对话历史,给出你的回复")
-
- # 微调前
- 你好,根据你的描述,你的症状已经持续了挺长一段时间,建议你尽快来医院进行详细检查,以确定具体的病因并获得适当的治疗。建议你在此期间饮食清淡,避免油腻、辛辣和刺激性食物,多喝水,适当的运动,以缓解症状。
-
- # 微调后
- 你好,根据你的描述我认为你可能患的是消化性溃疡,这种疾病经常会在吃饭后几个小时内发生,且常常伴有疼痛和反酸,希望你能注意饮食,注意节制,不要吃太油腻,辛辣的食物,多吃蔬菜,水果,保持良好的心情,注意休息。并且建议你去医院消化科实施仔细检查,以便及早治疗。
- >>> display_answer(model, "3月至今上腹靠右隐痛,右背隐痛带酸,便秘,喜睡,时有腹痛,头痛,腰酸症状")
-
- # 微调前
- 这些症状可能是多种疾病或症状的表现,具体病因和治疗需要通过详细的身体检查和病因分析来确定。
- 建议您尽快咨询医生,进行详细的体格检查和可能的影像学检查,以确定病因并获得适当的治疗。此外,您可以尝试避免食用辛辣、油腻和刺激性食物,多喝水,适当运动,缓解压力和焦虑。
-
- # 微调后
- 这些症状可能是胃肠道炎症或者十二指肠溃疡的原因。胃肠道炎症或者十二指肠溃疡,会引来腹部疼痛,也可以引来头昏,腰酸,腹痛,还会引来便秘。建议您到正规医院消化内科实施仔细检查,根据医生的诊断制定适当的治疗方案。祝健康!
从以上例子可以看出,微调后的模型回答更加简洁,前后文联系也更有逻辑性,同时在医疗领域的问答更加合理,有明显的准确率提升。
九. 灾难性遗忘
灾难性遗忘是指在微调过程中,模型学习新的任务时忘记了原有任务的知识,在原始任务上的表现灾难性地下降。
在本模型中,使用官方的学习率(2e-2 )可能会使得训练之后的模型回答问题时发生严重的错误回答,称为灾难性遗忘。例如:
微调前:
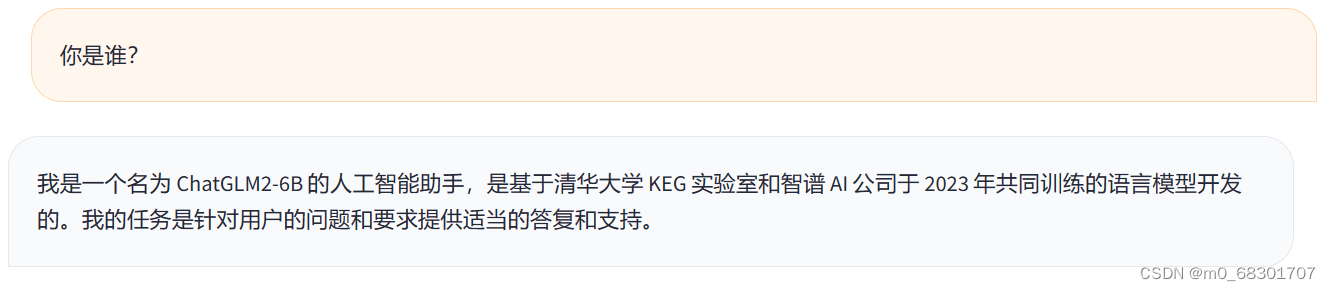
微调后:
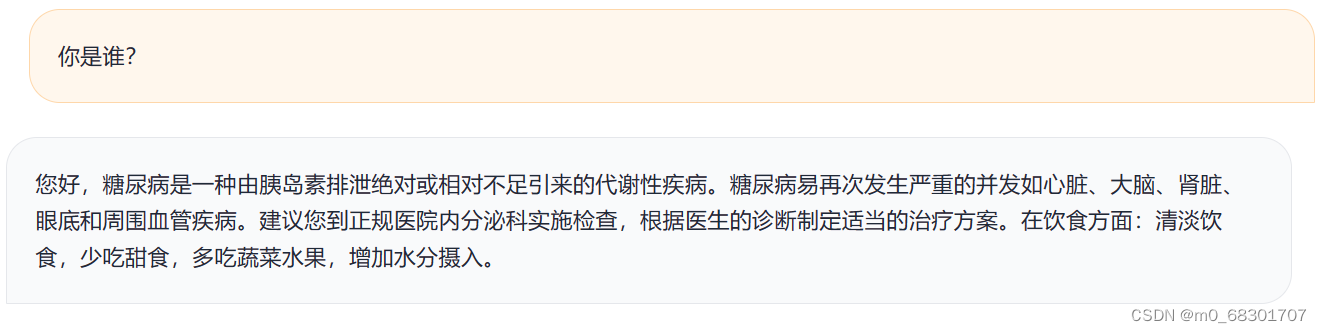
问题是“你是谁?”,回答却是糖尿病的相关介绍,回答与问题完全不相符。
解决方案可参考:清华大模型Chatglm2-6B基于P-Tuning的微调方法和微调模型使用方式(非常仔细,值得借鉴且使用自己的数据集微调未发生灾难性遗忘,效果很好)_清华大学glm下载-CSDN博客
对train.sh文件内的配置进行调整和修改
由于使用官方的学习率(2e-2 )可能会导致灾难性遗忘,因此需要对学习率LR进行调整,将其设置为15e-3。重新训练后再次进行检测,发现现在能正常回答,没有发生灾难性遗忘。

