
- 1关键点试衣_down to the last detail: virtual try-on with detai
- 2Elasticsearch创建索引_elasticsearch 创建索引
- 3不愧是GitHub点赞飙升的Java10W字面经,面面俱到,太全了_github面经
- 4深入了解ApusicAS服务器配置系列之——配置Web上下文根_apusic-application.yml
- 5uni框架下的前端小知识
- 60基础自学软件测试 如何短期快速学到可以找工作的程度?_如何快速学习软件测试,以便有能力找到一份工作?
- 7HDFS命令
- 8微服务架构下,SpringCloud集成分布式文件存储中间件:FastDFS
- 9Hadoop集群搭建--创建分发脚本xsync_hadoop xsync
- 10开发者技术网站以及一些好的iOS博主的主页_ios bang blog
车辆控制知识总结(一):LQR算法_lqr控制算法
赞
踩
目录
转载参考资料:
LQR:Linear Quadratic Regulator 线性二次型调节器_One.Wan的博客-CSDN博客_线性二次型调节器
【控制理论】离散及连续的LQR控制算法原理推导_CHH3213的博客-CSDN博客_lqr控制
1 LQR简介
LQR:Linear Quadratic Regulator 线性二次型调节器,常用于车辆的横向控制中。
那么,什么是LQR呢?
如果所研究的系统是线性的,且性能指标为状态变量和控制变量的二次型函数,则最优控制问题称为线性二次型问题。
而LQR,Linear Quadratic Regulator,即线性二次型调节器, 是求解线性二次型问题常用的求解方法。
LQR ,其对象是现代控制理论中以状态空间形式给出的线性系统,而目标函数为对象状态和控制输入的二次型函数。
LQR最优设计是指设计出的状态反馈控制器 K要使二次型目标函数J 取最小值,而 K由权矩阵Q 与 R 唯一决定,故此 Q、 R 的选择尤为重要。
LQR理论是现代控制理论中发展最早也最为成熟的一种状态空间设计法。特别可贵的是,LQR可得到状态线性反馈的最优控制规律,易于构成闭环最优控制。
2 现代控制理论基础
2.1 状态空间描述

2.2 线性定常系统的状态空间描述框图

2.3 线性系统连续系统的反馈控制
经典控制理论中,我们依据描述对象输入输出行为的传递函数模型来设计控制器,因此只能用系统的可测量输出作为反馈信号。
而现代控制理论则是用刻画系统内部特征的状态空间模型来描述对象,除了可测量的输出信号外,还可以用系统的内部状态来作为反馈信号。
根据可利用的信息是系统的输出还是状态,相应的反馈控制可分为输出反馈和状态反馈。
现代控制理论中,更多地使用状态反馈,由于状态反馈能提供更丰富的状态信息和可供选择的自由度,因而能使系统更容易获得更为优异的性能。其实,输出反馈是可以看做是部分状态反馈。
2.31 全状态反馈控制器
(1)设计一个状态反馈控制器,如下图所示:多了个K反馈环节,一般直接取u=-Kx;
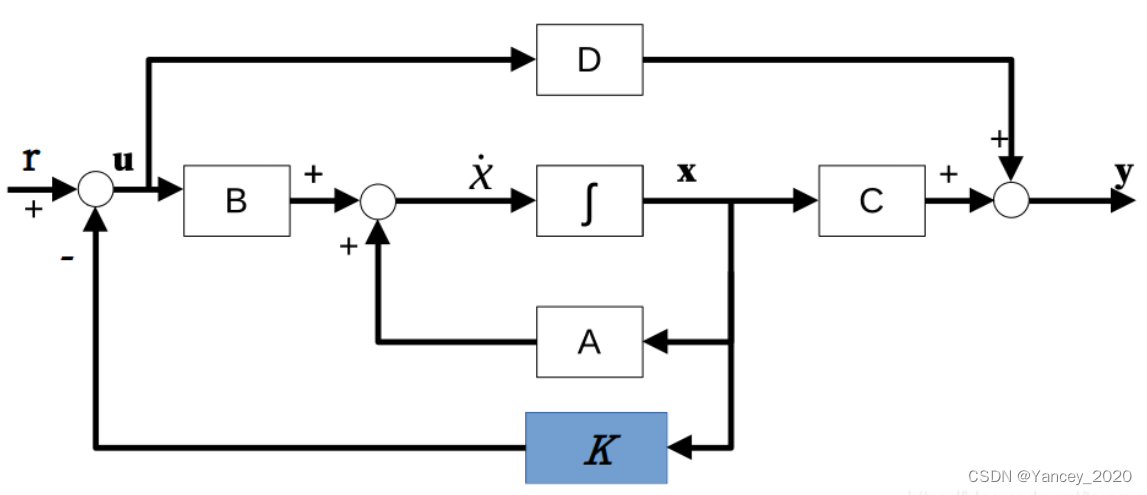

(2)设计完反馈控制器的架构之后,下面要保证反馈系统的稳定性。
反馈系统稳定性的充要条件是系统闭环传递函数的所有极点均有负实部,即均在复频域S平面的左侧。
根据稳定性判定的条件,首先求闭环系统的传递函数。
为了书写一致性,我们重写系统状态表达式将r替换成u:意思是最后实际是Y(s)/r(s);
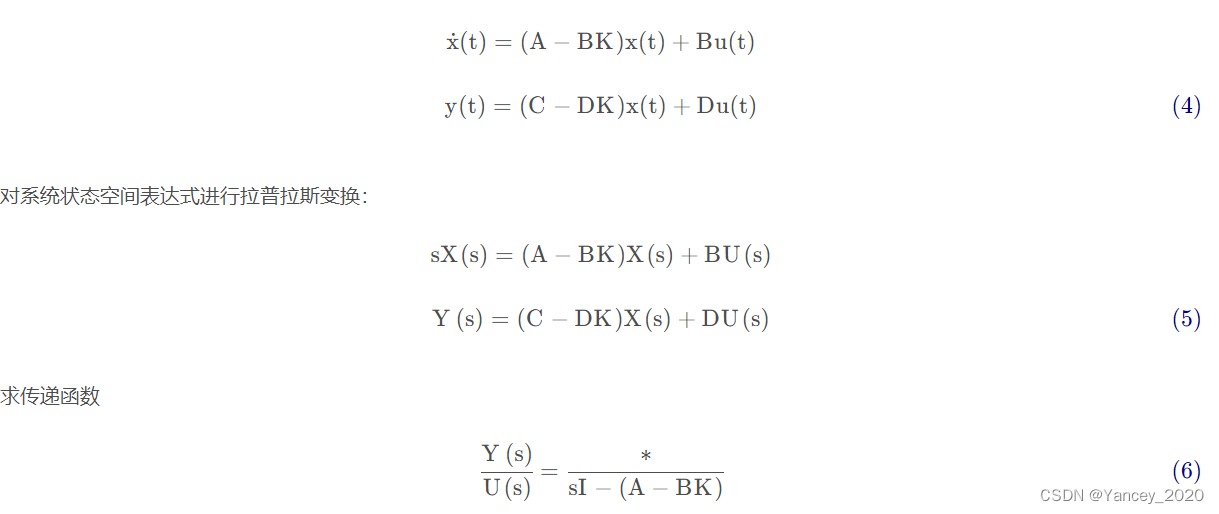
可以得到系统的闭环传递函数的形式如式(6)所示,只需要分母表达式。可见系统传递的极点就是矩阵A − BK的特征值。
因此,可以通过配置K矩阵 (r*n矩阵),使闭环系统达到我们期望的状态。
问题是:当系统变量很多的时候,即使设计好了极点,但是矩阵K也不好计算。接下来开始引入LQR帮助求解K。
3 LQR设计控制器的方法
3.1 什么是二次型
在不指定优化标准的前提下,控制领域中的“最优”体现在“输出能够完全跟踪控制,即在每一时刻输出量与控制量完全一致”。实际过程并不是这样完美的过程,每一时刻都会存在误差。退而求其次,追求在整个工作时间的范围内误差最小,与轨迹误差类似,我们研究状态误差。
因此,把整个工作时间内每一时刻状态的误差都累加起来,只要累加值更小,便会更加接近系统性能的期望。
1 首先,假设状态向量x(t)的维度为1以及闭环系统稳定。

2. 扩充状态变量到n个,则代价函数为:

类似的J的函数称为二次型函数,变量的最高次数是2。
所有展开的函数最高次数为2的,这种类型的函数统称为二次型函数。
3.2 二次型最优控制(注意:代价函数前面有公式加系数1/2)

3.3 连续时间下的LQR调节器设计步骤
3.3.1 Q、R矩阵选取
Q为半正定的状态加权矩阵, R为正定的控制加权矩阵(注意这里),两者通常取为对角阵。Q矩阵元素变大意味着希望状态量能够快速趋近于零;R矩阵元素变大意味着希望控制输入能够尽可能小,它意味着系统的状态衰减将变慢。所以,Q、R的选取,要综合看具体的实际应用场景来调节。
3.3.2 求解Riccati方程得到矩阵P
我们求解的前提是假定系统处于稳定状态,此时的状态反馈为 u(t)=-Kx(t);
将状态方程代入到代价函数中
状态方程:x ˙ ( t ) = ( A − B K ) x ( t )
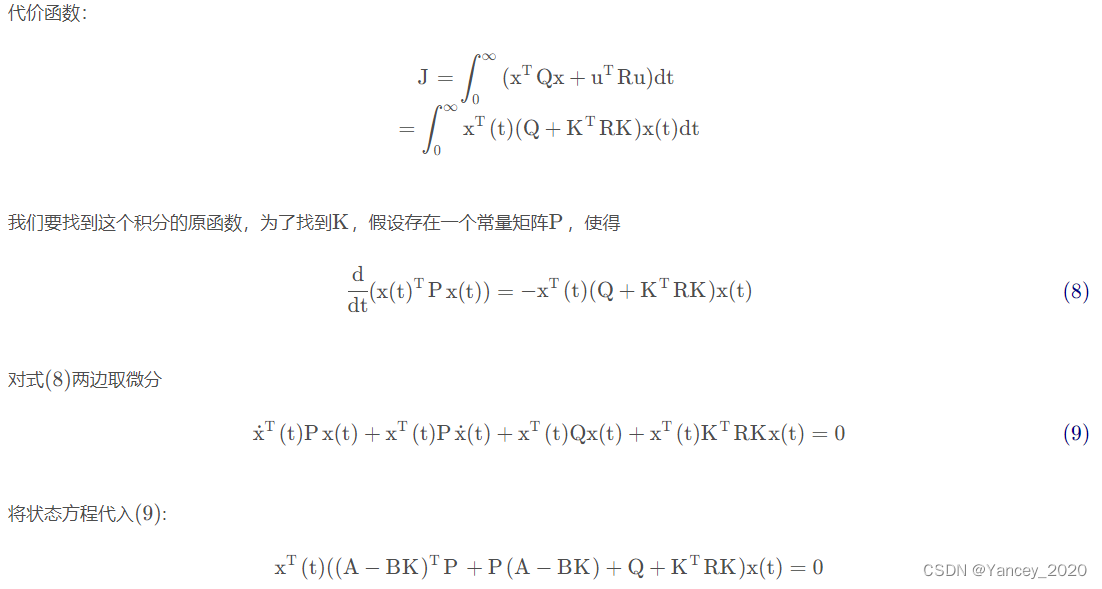

式(10)中A,B,Q,R 都是已知量,那么通过式(10)可以求解出 P(n×n维),式(10)就是著名的连续时间代数Riccati方程(CARE)。
3.3.3 计算反馈矩阵
根据P,可计算出反馈矩阵K=R-1BTP;
3.3.4 计算控制量
u=-Kx;
3.4 离散时间下的LQR调节器的设计(重要!!)
3.41 推导
首先,对状态方程进行离散化,如下图:Apollo是第二种

接着,以这个离散的系统进行dlqr推导,注意此时的代价函数略微不同,多了一项。

推导参考:
3.42 推导结果


3.43 离散lqr算法步骤:
一般迭代个几十步,P就不变了!!收敛了!!
输入A、B、Q、R、最大迭代次数N,以及精度,即P变化量多少时可以看做不变收敛了。


