
- 1强化学习笔记【9】演员-评论家算法(Actor-Critic Algorithm)
- 21.6 Nacos服务配置中心应用实践_nacos配置服务实例
- 3DSP学习 -- 前言_ceva ti
- 4程序员国内外最受好评的接私活6大网站,有技术就不怕赚不到钱!_freelancer fiverr
- 5关于计算机专业大三方向,计算机专业哪个方向比较好
- 6应用限流常用方案及项目实战
- 7Illegal mix of collations
- 8如何评价微软发布的Phi-3,手机都可以运行的小模型
- 9百度智能云API——实现语言理解功能(python_百度智能云 api
- 10GitHub开源项目的多人协作详细操作_github其他人推代码
使用基于大语言模型的智能搜索打造下一代企业知识库-手把手快速部署指南
赞
踩

感谢大家阅读《基于智能搜索和大模型打造企业下一代知识库》系列博客,全系列分为 5 篇,将为大家系统性地介绍新技术例如大语言模型如何赋能传统知识库场景,助力行业客户降本增效。更新目录如下:
第二篇《手把手快速部署指南》(本篇)
第三篇《Langchain 集成及其在电商的应用》
第四篇《制造/金融/教育等行业实战场景》(即将上线)
第五篇《与 Amazon Kendra 集成》(即将上线)
背景
在该系列第一篇《典型实用场景及核心组件介绍》中,我们已经向您介绍了该方案的基本原理和背景。相信您已经跃跃欲试,想要第一时间在自己的环境中搭建智能搜索大语言模型增强方案。因此,我们撰写了本篇内容以供读者进行方案的快速部署。该方案部署流程并不复杂,只需要您对于亚马逊云科技相关服务有一个基本的了解即可。
方案架构图与功能原理
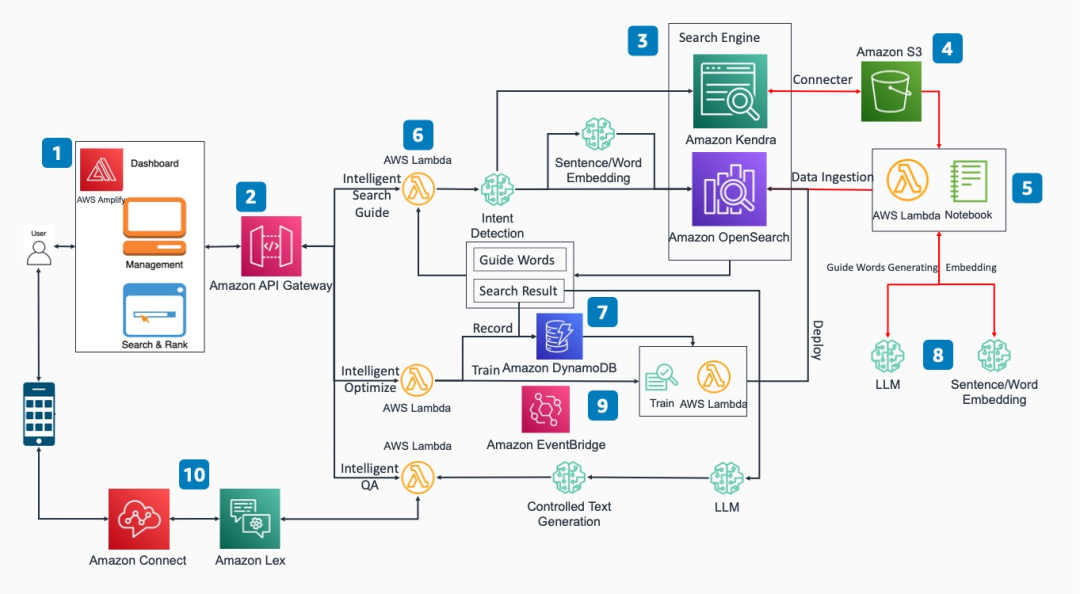
该方案分为以下几个核心功能模块:
前端访问界面:该方案提供了基于 React 的前端访问界面。用户可以通过网页以 REST API 的形式进行智能文档搜索等功能的操作。
REST API:通过集成了相应 Amazon API Gateway 和 Amazon Lambda 函数的实现和后端搜索引擎,数据库和模型推理端点交互。
企业搜索引擎:基于 Amazon OpenSearch 或 Amazon Kendra。可以基于双向反馈的学习机制,自动持续迭代提高输出匹配精准度。同时采用引导式搜索机制,提高搜索输入描述的精准度。
数据源存储:可选用多种存储方式如数据库,对象存储等,在这里 Amazon Kendra 通过连接器获取 Amazon S3 上的对象。
向量化数据注入:采用 Amazon SageMaker 的 Notebook 模块或者 Amazon Lambda 程序将原始数据向量化后的数据注入 Amazon OpenSearch。
智能搜索/引导/问答等功能模块:采用 Amazon Lambda 函数实现和后端搜索引擎,数据库和模型推理端点交互。
记录数据库:用户反馈记录存储在数据库 Amazon DynamoDB。
机器学习模型:企业可以根据自身需要构建大语言模型和词向量模型,将选取好的模型托管到 Amazon SageMaker 的 endpoint 节点。
反馈优化:用户在前端页面反馈最优搜索结果,通过手动或事件触发器 Amazon EventBridge 触发新的训练任务并且重新部署到搜索引擎。
插件式应用:利用该方案核心能力可以与 Amazon Lex 集成以实现智能会话机器人功能,也可以与 Amazon Connect 集成实现智能语音客服功能。
实施步骤介绍
我们以 smart-search v1 版本为例,为大家讲解方案的整个部署流程。
1、环境准备
首先您需要在您的开发环境中安装好 python 3、pip 以及 npm 等通用工具,并保证您的环境中拥有 16GB 以上的存储空间。根据您的使用习惯,您可以在自己的开发笔记本(Mac OS 或 Linux 环境)上部署,也可以选择 EC2 或者 Cloud9 进行部署。
2、CDK 自动部署
2.1 当前请联系亚马逊云科技官方渠道获取代码
热线电话:+86 (10) 1010 0866 或发起在线聊天
链接:
https://webchat-aws.clink.cn/chat.html?accessId=1e956ec1-f000-4f41-87f7-ff1d3e6d8b87&language=zh_CN&refid=acts-hero2
获取代码后把代码拷贝到指定目录下。打开终端窗口,进入 smart_search 的软件包,并切换到名为 deployment 文件夹下:
cd smart_search/deployment进入到 deployment 目录后,相应的 CDK 部署操作均在该目录下进行。然后安装 Amazon CDK 包:
npm install -g aws-cdk2.2 安装 CDK 自动化部署脚本所需的所有依赖项和环境变量
在 deployment 目录下运行以下命令安装依赖库:
pip install -r requirements.txt然后将您的 12 位 Amazon 账号信息、Acess Key ID、Secret Access Key、以及需要部署的 Region ID 导入到环境变量中:
- export AWS_ACCOUNT_ID=XXXXXXXXXXXX
- export AWS_REGION=xx-xxxx-x
- export AWS_ACCESS_KEY_ID=XXXXXX
- export AWS_SECRET_ACCESS_KEY=XXXXXXX
左滑查看更多
然后运行“cdk bootstrap”安装账户和目标区域内的 CDK 工具包,例如:
cdk bootstrap aws://$AWS_ACCOUNT_ID/$AWS_REGION左滑查看更多
2.3 在 cdk.json 可以进行自定义配置
该方案的默认配置文件在 deployment 目录下的 cdk.json 文件中,如果您想要自行配置需要部署哪些功能模块,您可以根据需要修改 cdk.json 的“context”部分。例如,如果您需要修改部署哪些功能函数,可以对“selection”值进行修改。
默认的参数如下所示:
"selecton":["knn","knn_faq","feedback","post_selection","xgb_train","knn_doc"]左滑查看更多
如果您仅需要使用“支持 knn 的文档搜索功能”,您可以仅保留“knn_doc”。除此之外,您还可以选择通过修改 cdk.json 的其他相应参数来自定义部署方式、部署哪些插件和名称和路径等配置。
2.4 CDK 命令自动化署
运行下面的命令将验证环境并生成 Amaon CloudFormation 的 json 模版:
cdk synth如果没有报错,则运行以下命令部署全部堆栈。
cdk deploy --allCDK 部署将提供相关 Amazon CloudFormation 堆栈以及相关资源,例如 Amazon Lambda、Amazon API Gateway、Amazon OpenSearch 实例和 Amazon SageMaker 的 notebook 实例等,预计安装的部署时间大约为 30 分钟左右。
3、利用 Amazon SageMaker 的 Notebook 实例部署模型与数据导入
3.1 部署模型
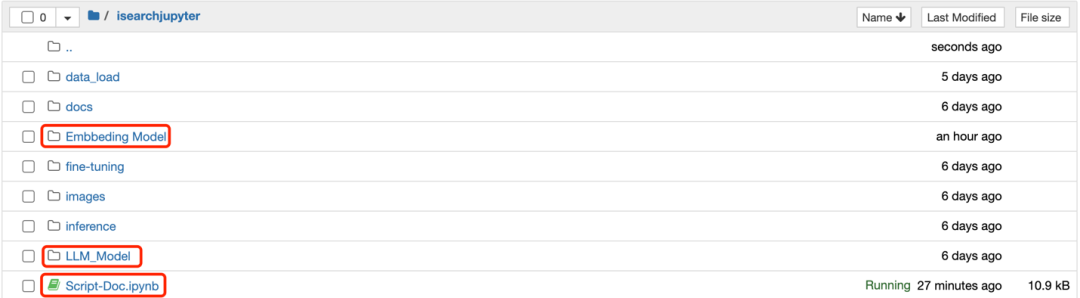
3.1.1 进入 Amazon SageMaker 控制台,进入 NoteBook Instances,选择 SmartSearchNoteBook 实例, 点击“Open Jupyter”,进入 SmartSearch 的代码主目录,点击“isearchjupyter”目录进入,您能看到包括 Embbeding Model、LLM_Model 等目录,这两个目录包含模型部署脚本,而 Script-Doc.ipynb 脚本则会用于后面的文档上传,目录如下图所示:
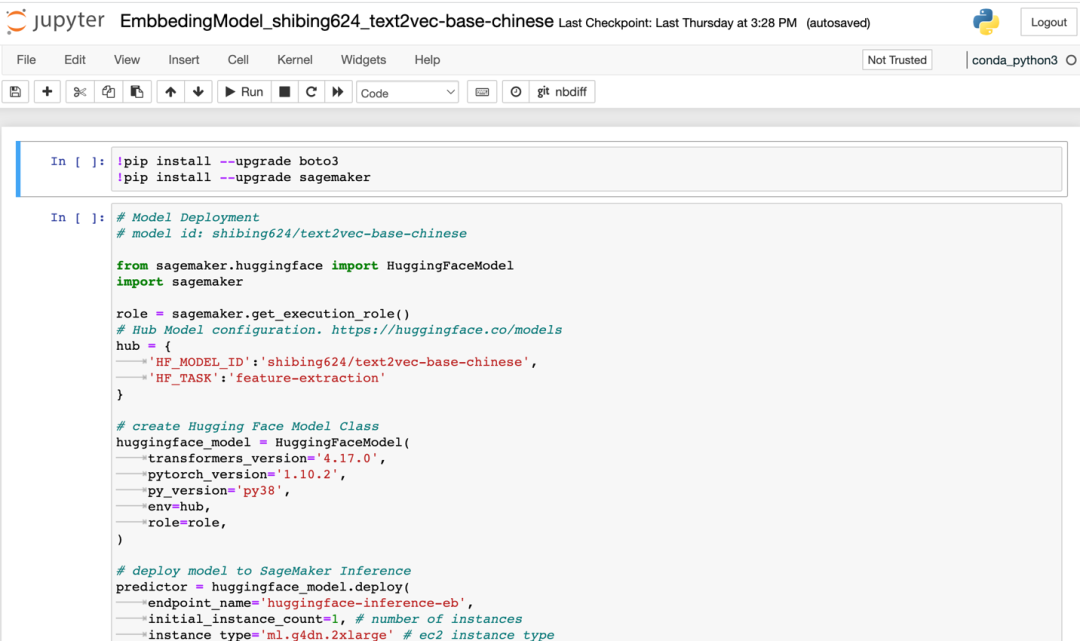
3.1.2 首先安装 Embbeding Model,进入“/isearchjupyter/Embbeding Model”目录,能看到对应的几个脚本。其中“EmbbedingModel_shibing624_text2vec-base-chinese.ipynb”为中文的词向量模型,其他两个为英文,打开相应脚本依次运行单元格,开始部署 embbeding model。等待 script 部署完毕,成功部署后您会在 Amazon SageMaker 的 endpoint 中看到名为“huggingface-inference-eb”的 endpoint,状态为“InService”。
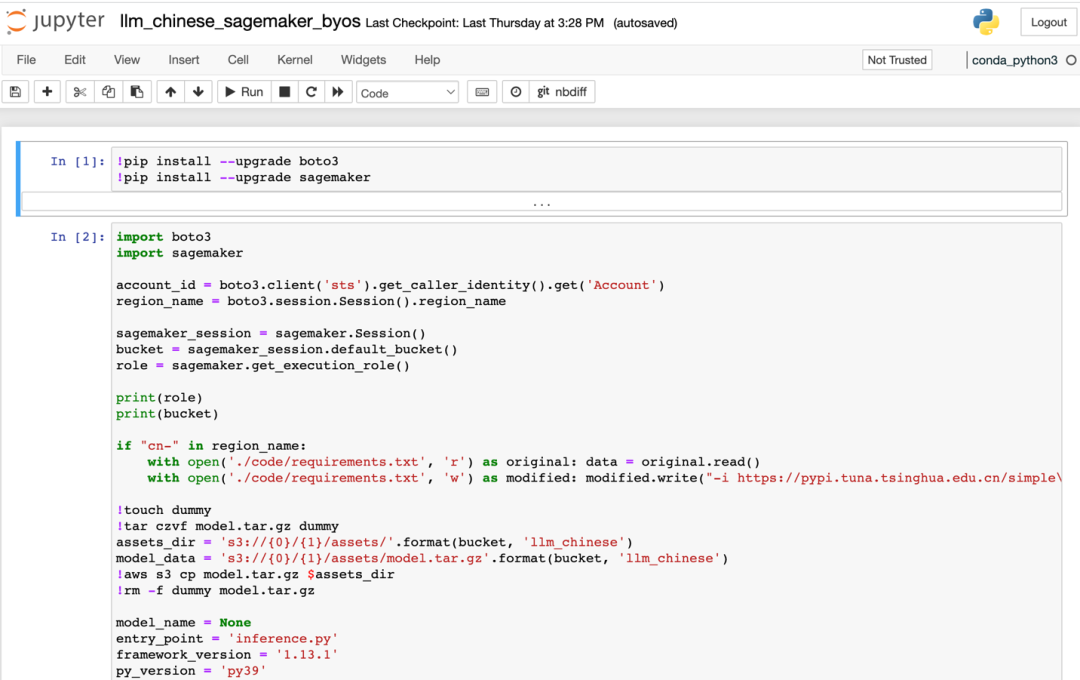
3.1.3 然后部署大语言模型,LLM_Model 目录下当前包含了中文和英文的大语言模型库。这里先为大家介绍中文的大语言模型的部署方法,找到 isearchjupyter/LLM_Model/llm_chinese/code/inference.py,该文件定义了大语言模型的统一部署方法。大语言模型可以通过唯一的名称进行部署,我们把该唯一名称声明为“LLM_NAME”的参数值,作为参数传递给部署脚本。您可以根据大语言模型的文档来确定“LLM_NAME”的值。我们以 https://huggingface.co/THUDM/chatglm-6b 网址文档为参考来说明如何确定“LLM_NAME”值。打开网址后对照该文档找到该模型部署的唯一名称,然后粘贴到为“LLM_NAME”赋值的位置即可,您可以参照该方法举一反三,指定您项目中需要使用的大语言模型。修改 inference.py 文件后进入“isearchjupyter/LLM_Model/llm_chinese/“目录,运行该目录的 script。等待 script 部署完毕,成功部署后您会在 Amazon SageMaker 的 endpoint 中看到名为“pytorch-inference-llm-v1”的 endpoint。
如果您选择部署英文大语言模型,部署方式类似,需要将英文大语言模型的参数填入 LLM_Model/llm_english/code/inference.py 文件的“LLM_NAME”参数中。以 https://huggingface.co/TheBloke/vicuna-7B-1.1-HF 为例来说明英文的模型部署,找到该大语言模型项目名称,则然后复制该名称再粘贴到为“LLM_NAME”赋值的位置,您可以用该方法进行举一反三,指定任意一个满足您的业务需求的大语言模型。进入“isearchjupyter/LLM_Model/llm_english/”的目录下,依次运行该目录下英文大语言模型的脚本的部署单元格。如下图所示:
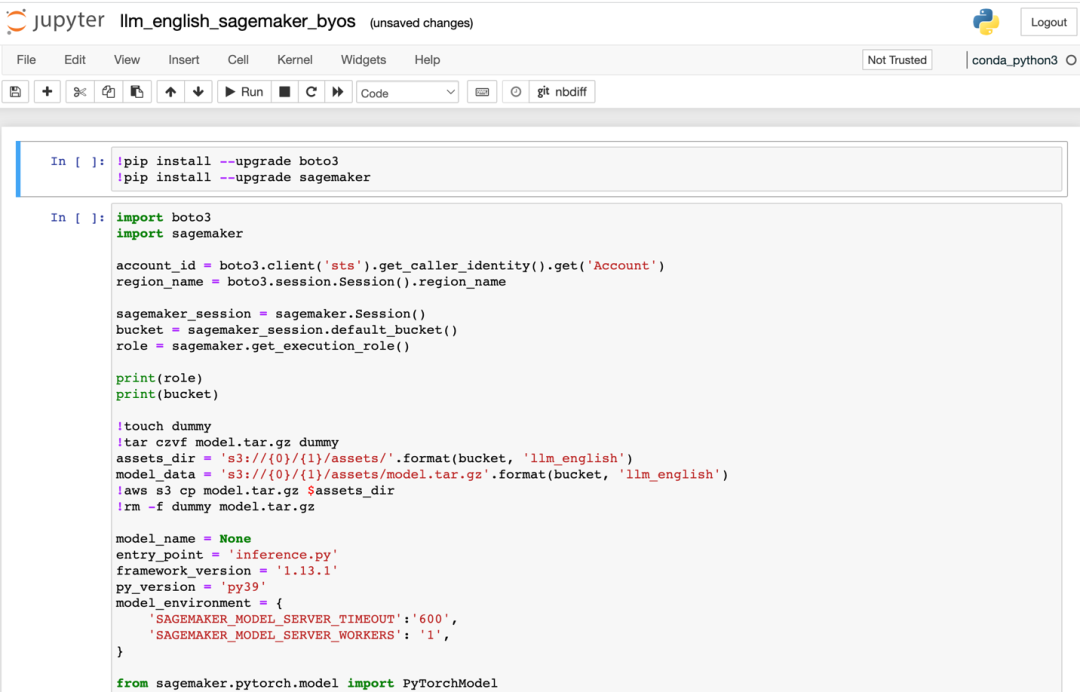
3.1.4 安装完成后,您会看到两个 endpoint 已经在”InService”状态,如下图:
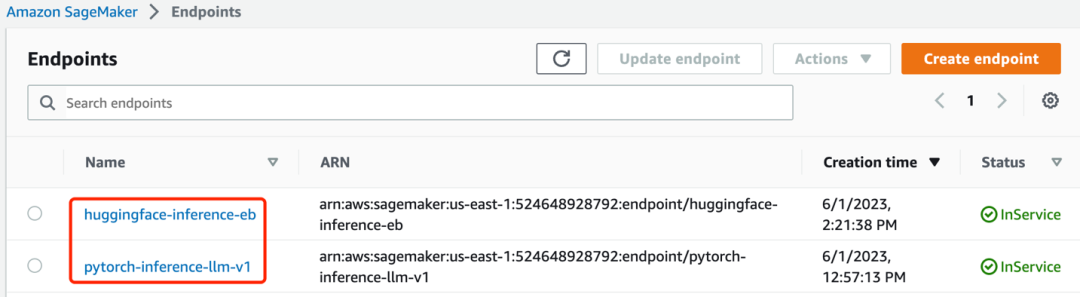
3.2 知识库数据上传
3.2.1 数据准备。进入 jupyter 的目录“/isearchjupyter”,在“docs”目录,将上传所需要的 word、excel 或 pdf 等格式的文档进行上传,该文件夹下已经提供了用于测试的样例文件“sample.docx”(该样例文件整理自 http://www.360doc.com/content/19/1017/08/7696210_867360083.shtml)。
3.2.2 进入 Script-Doc.ipynb,修改单元格“Hyperparameter”的如下参数,folder_path 为指定的 docs 目录,index_name 为 Amazon OpenSearch 的 index 名称,如下图:
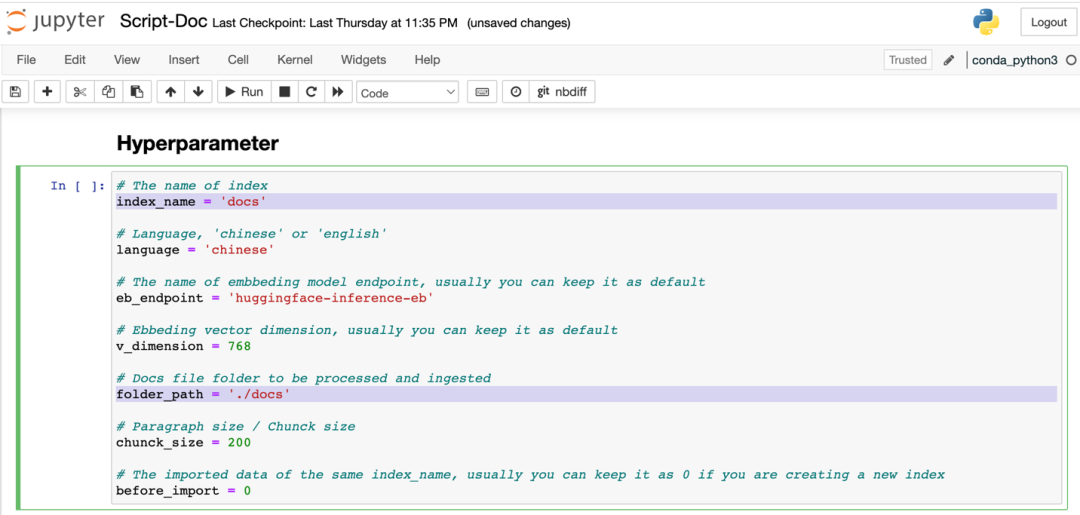
然后从头运行这个 script,完成数据导入。
4、配置 Web UI
4.1 进入 smart_search/ search-web-knn 目录,该目录包含基于 React 的前端界面代码。然后对 /src/pages/common/constants.js 文件进行编辑,如下图所示:
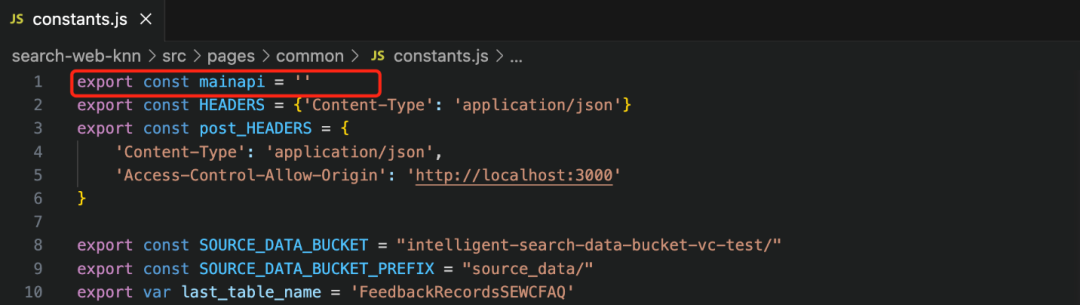
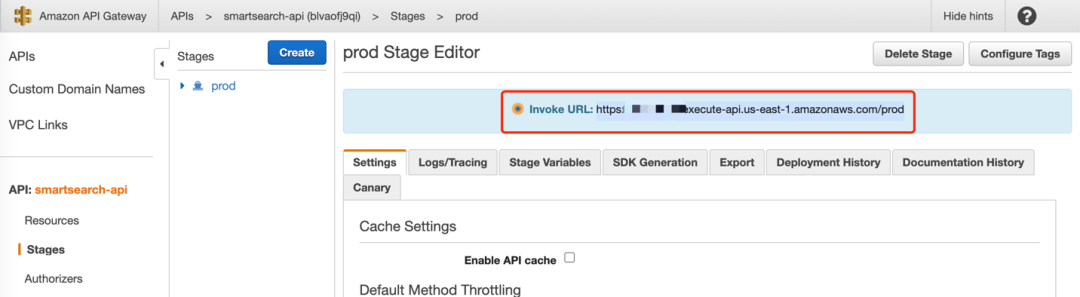
Mainapi 常变量指定了前端调用的 API 入口。该值可以从网页端进入 API Gateway 中获取,进入“smartsearch-api”的 Stages 侧边栏,将 prod stage 的 involke URL 赋值给 constants.js 的 mainapi 常变量,例如:https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com/prod。
4.2 检查主页面参数配置。smart_search/search-web-knn/src/pages/MainSearchDoc.jsx 为功能展示页面,在该文件的 last_index 参数设置了页面自动填充的默认 index 值,将上文 Notebook 实例部署的 index name 填入,如“docs”。
4.3 运行前端界面。进入目录 search-web-knn,执行如下两条命令:
npm install然后运行以下命令启动前端界面:
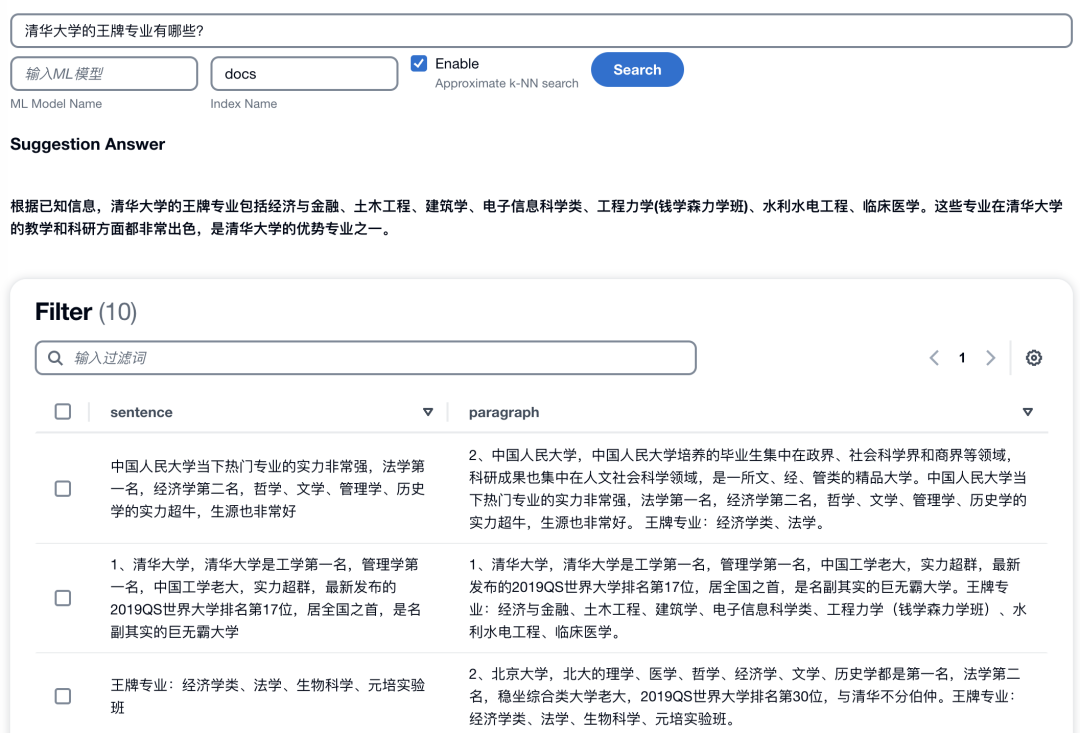
npm start一切顺利的话,您将得到一个网页版界面。在本地开发笔记本部署的默认访问地址和端口号是 localhost:3000,如果是 EC2 部署,需要启用对应端口访问的安全组策略,通过 EC2 的公网地址加端口号进行访问。该前端页面的使用方法为:将问题输入搜索栏,配置 index 名称和 k-NN 选项,点击“Search”按钮后您可以得到一个基于企业知识库的大语言模型汇总回答。如下图所示:
5、安装扩展插件
5.1 与 Amazon Lex 集成实现智能聊天机器人
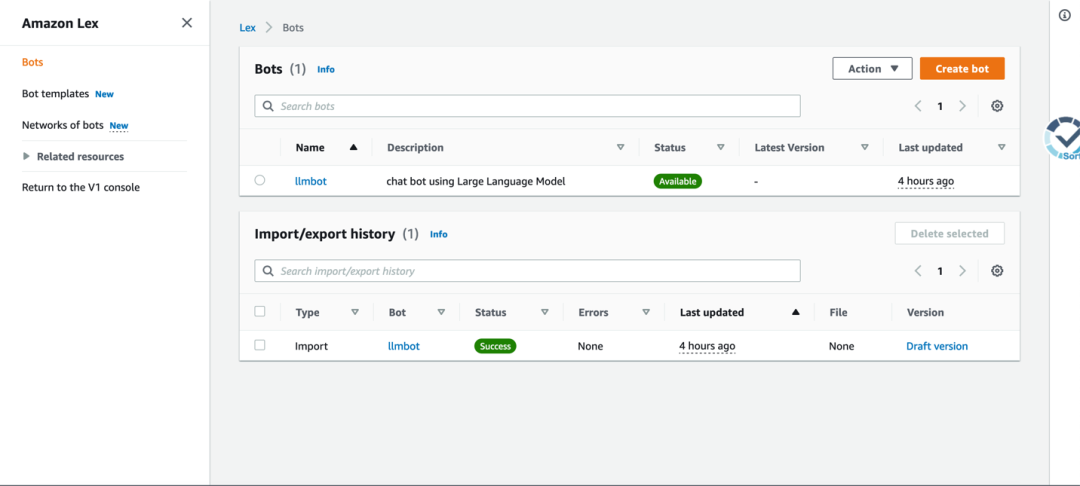
本方案已经集成了 Amazon Lex 的会话机器人功能,Amazon Lex 当前在海外区可用。在 cdk.json 文件中,将“bot”加入 extension 键值处。
"extension": ["bot"]cdk 部署成功后进入管理界面可以看到名为“llmbot”的对话机器人,如下图:
该机器人可以方便地进行前端页面的集成,例如,您可以启动 https://github.com/aws-samples/aws-lex-web-ui 中对应区域的部署模板 ,并将 llmbot 的信息(LexV2BotId、alias ID 等)填写到 CloudFormation 模板中即可。Lex 机器人的工作界面如下图所示。
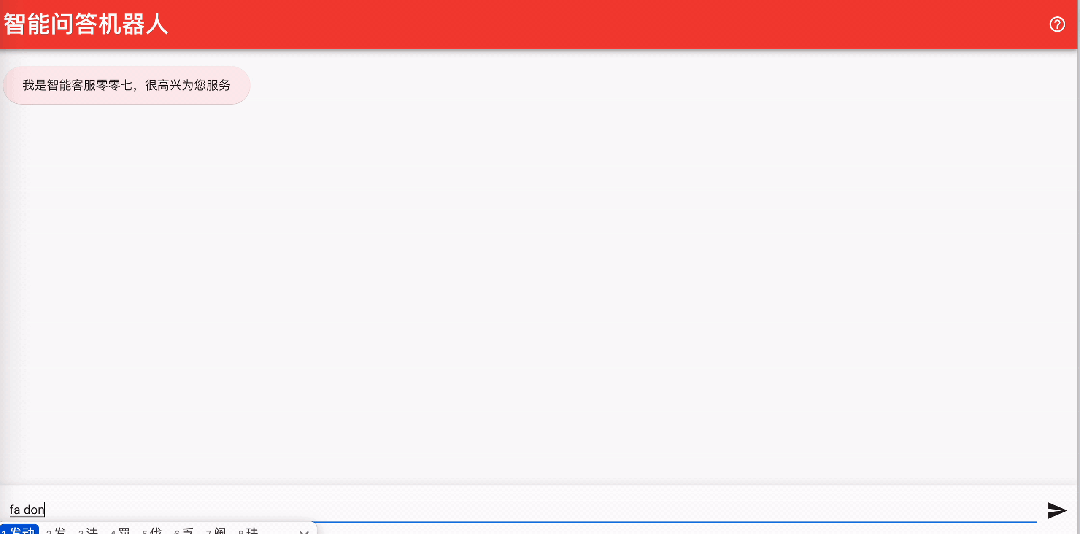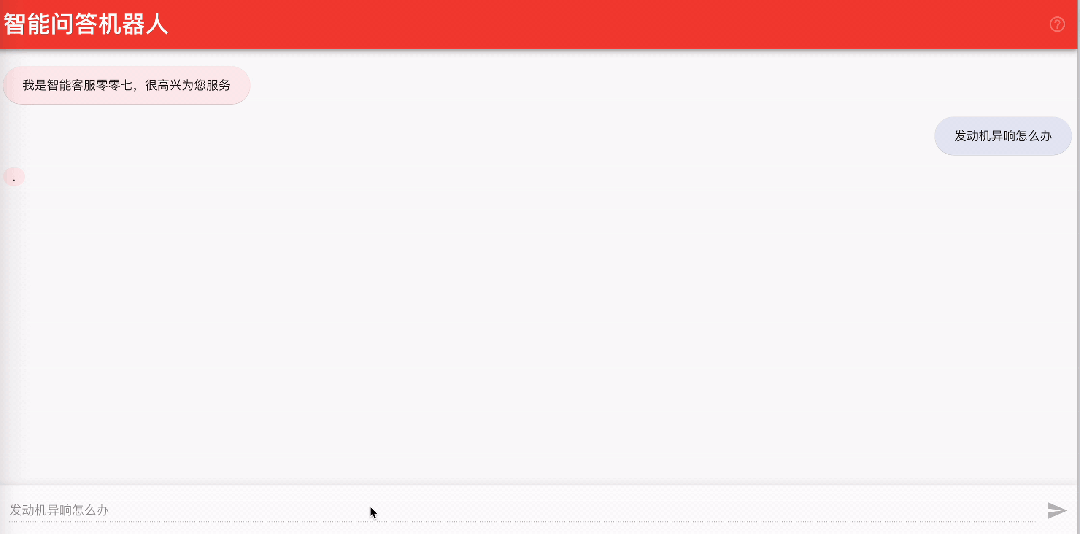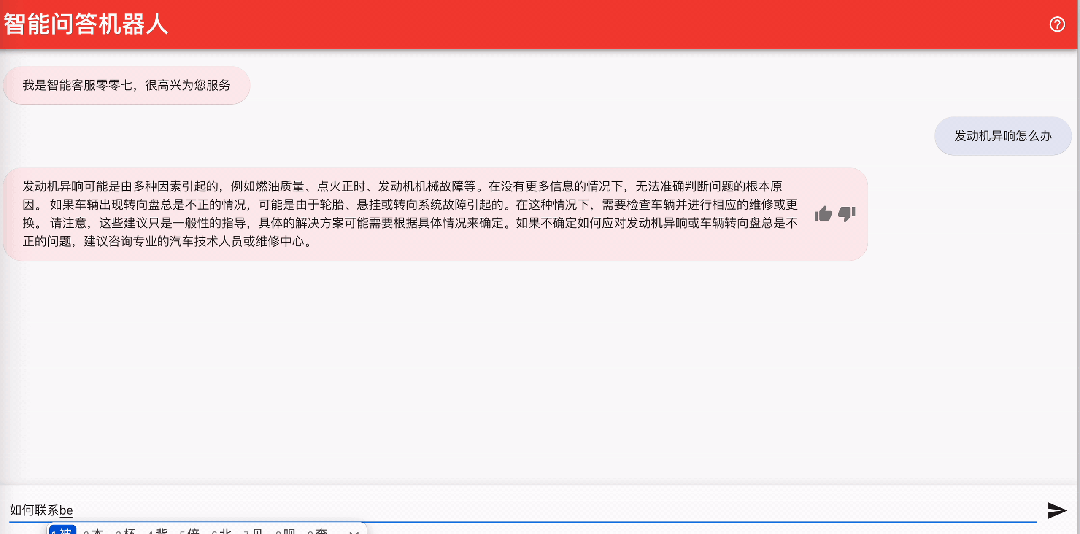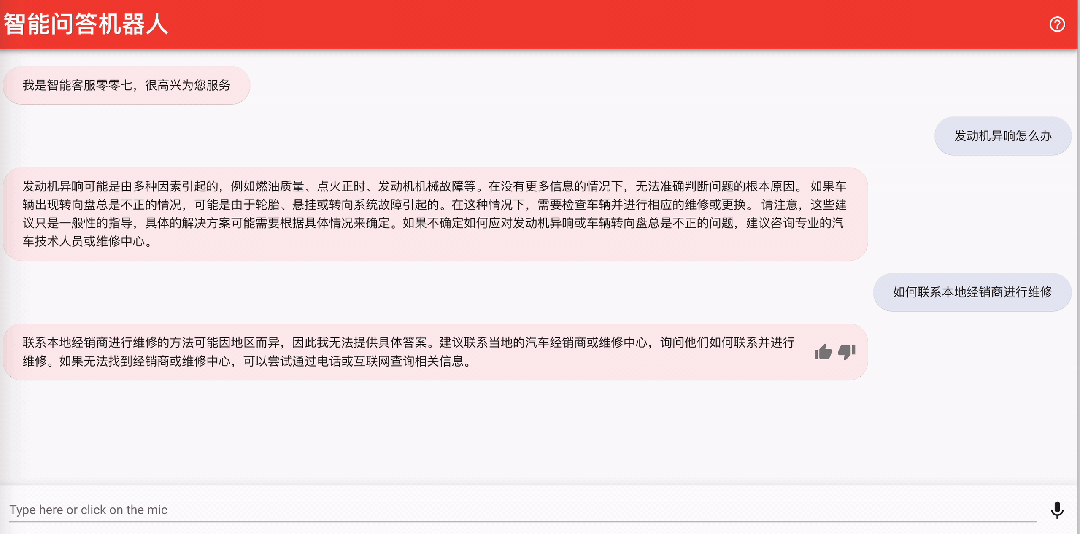
5.2 与 Amazon Connect 集成实现智能语音客服
Amazon Connect 为亚马逊云科技的云呼叫中心服务,该服务当前在海外区可用。该方案可以通过 Amazon Lex 机器人将大语言模型能力集成到 Amazon Connect 云呼叫中心中,通过以下几个步骤可以使您获得一个支持语音呼叫功能的智能客服机器人。
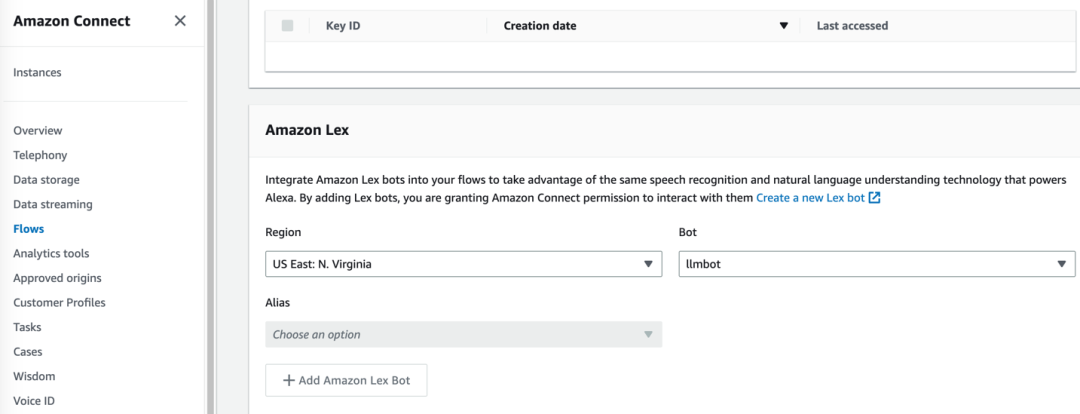
5.2.1 将上一步生成的 llmbot 机器人集成到现有 Amazon Connect 实例中。
5.2.2 然后进入 Amazon Connect 实例中,将 smart-search/extension/connect 里面的文件导入到 Contact Flow 中,并保存和发布。
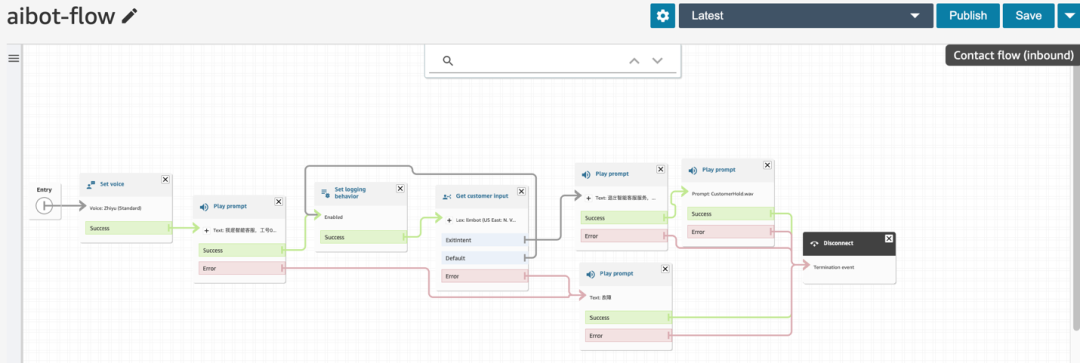
5.2.3 最后在 Amazon Connect 中将呼入号码与上一步配置的 Contact Flow 进行关联。则所有呼入该号码的语音通话将会连接到智能客服的呼叫服务流程。
正常情况下,智能客服将会识别呼入人的语音输入,随后集成到 Amazon Connect 的智能客服机器人会基于企业知识库信息和大语言模型的能力进行以接近人类的逻辑方式进行语音回答。以下音频展示了该方案用于汽车售后场景的智能客服案例,收听请点击播放:
6、资源清理
当您想要将资源进行清理时,请使用以下命令将所有堆栈进行删除:
cdk destroy --all注意:通过 Amazon SageMaker 的 Notebook 实例创建的推理模型资源需要进行手动删除,在 Amazon SageMaker 的“inference”边栏进入“endpoint”,点击“delete”,将所有 endpoint 进行删除。
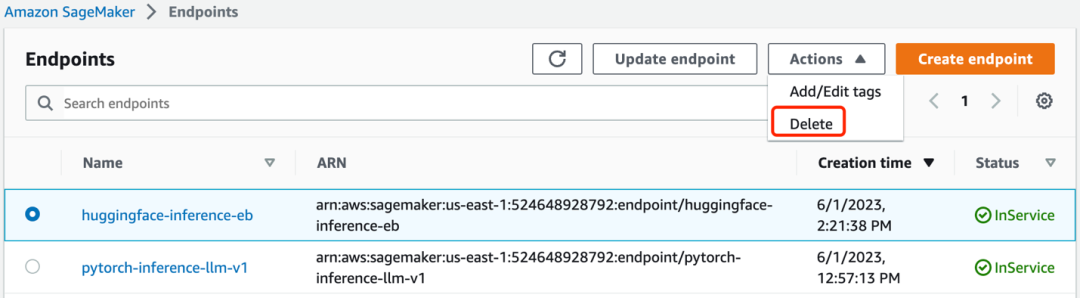
当堆栈创建的 Amazon S3 桶中已经有了数据或者存在其他手动创建或修改的资源时,则也需要手动删除。
总结
通过此次部署,您已经成功掌握了该方案的部署方法,也对该方案有了更深的了解。我们也将会对该方案进行持续的迭代与优化以支持更多的数据类型、模型库与扩展功能,进而将方案的能力延伸到更多的业务场景中去。该方案可以解决许多行业和领域的专业或通用场景,也期待您能够将该方案应用到企业的实际业务场景中去,通过使用该方案您可以使用人工智能的最新进展和亚马逊云科技的产品来为行业发展注入新的活力。
本篇作者

徐鹏
亚马逊云科技汽车行业解决方案架构师,拥有十余年国际整车企业自动驾驶与电子电器的研发经验,曾担任高阶自动驾驶大数据测试与验证负责人,包括大数据采集、大数据仿真验证、大数据分析与机器学习等方案的设计与实现。目前专注于自动驾驶、车联网、软件定义汽车等业务。

石锋
亚马逊云科技资深解决方案架构师,负责教育行业和交通行业的解决方案设计和落地。曾就职于阿里云六年,负责交通、政府、奥运、体育媒体等大型项目的技术团队,在 IBM 和 Oracle 工作过 10 年,在多个行业针对云计算、大数据、人工智能、物联网、元宇宙等领域有丰富的实践经验。

梁一鸣
亚马逊云科技解决方案架构师,致力于云计算方案架构设计、应用和推广。具有 15 年 IT 行业工作经验,擅长开发与数据灾备保护领域,历任软件开发工程师,项目经理,系统架构师。在加入亚马逊云科技之前,曾服务于 EMC、Microsoft 等公司。

杨志浩
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案的咨询与架构设计,目前专注在新能源电力行业。致力于推广 HPC,IoT 技术领域在风电,光伏等新能源电力行业的应用。


听说,点完下面4个按钮
就不会碰到bug了!


