
- 1手把手带你玩转Spark机器学习-使用Spark构建回归模型_spark线性回归 可视化
- 22024年(第十届)全国大学生统计建模大赛选题参考(二)_统计建模选题
- 3Python中列表的基本操作
- 4Mac OS X 10.10 Yosemite 关闭Dashboard和Spotlight_spotlightv100能删除吗
- 5产品经理 | 职业选择及面试技巧_产品经理面试职业规划
- 6【JAVA】 Java 性能比较差的代码写法及替换方案_java stream int 假发
- 7复刻yolo系列时出现的BUG及解决方法_runtimeerror: "slow_conv2d_cpu" not implemented fo
- 8XZ-Utils后门事件过程及启示_xzuntil
- 9HarmonyOS实战开发-拼图、如何实现获取图片,以及图片裁剪分割的功能。_鸿蒙 分割图片
- 10三款好用的 Docker 可视化管理工具_docker可视化界面管理工具
强化学习笔记【9】演员-评论家算法(Actor-Critic Algorithm)
赞
踩
该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
笔记【4】到笔记【11】为李宏毅《深度强化学习》的部分;
笔记 【1】和笔记 【2】根据《强化学习纲要》整理而来;
笔记 【3】 和笔记 【12】根据《百度强化学习》 整理而来。
演员-评论家算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法,其中:
- 演员(Actor)是指策略函数πθ(a|s),即学习一个策略来得到尽量高的回报。
- 评论家(Critic)是指值函数Vπ(s),对当前策略的值函数进行估计,即评估演员的好坏。
- 借助于值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
下面介绍两种常见的演员-评论家算法:
(1)A3C(Asynchronous Advantage Actor-Critic)
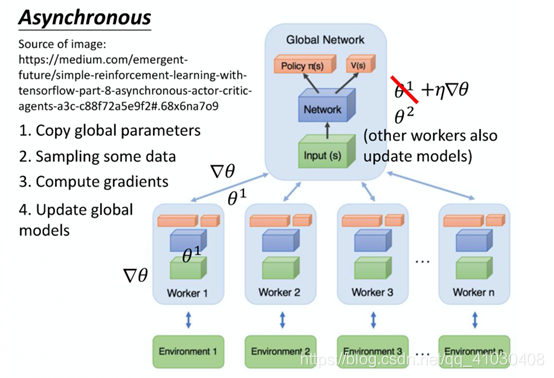
图1.A3C
A3C就相当于火影忍者里面鸣人为了在一周之内打败晓,他开了1000个影分身同时修行,这就是A3C的本质。
A3C 这个方法就是同时开很多个worker,每一个worker其实就是一个影分身,训练过程中这些影分身同时进行训练,最后这些影分身会把所有的经验通通集合在一起。如果没有多个CPU,A3C可能不好实现,此时实现 A2C就好, A2C即Advantage Actor-Critic。
具体而言,A3C一开始会有一个global network。它们有包含policy的部分和value的部分,假设它的参数就是θ1。对于每一个worker都用一张CPU训练(举例说明),第一个worker就把 global network的参数copy过来,每一个worker工作前都会global network的参数copy过来。然后这个worker就要去跟environment进行交互,每一个actor去跟environment做互动后,就会计算出gradient并且更新global network的参数。这里要注意的是,所有的actor 都是平行跑的、之间没有交叉。所以每个worker都是在global network“要”了一个参数以后,做完就把参数传回去。所以当第一个worker做完想要把参数传回去的时候,本来它要的参数是θ1,等它要把gradient传回去的时候。可能别人已经把原来的参数覆盖掉,变成θ2了。但是没有关系,它一样会把这个 gradient就覆盖过去就是了。

图2. Pathwise Derivative Policy Gradient
Pathwise Derivative Policy Gradient是另一种演员-评论家算法,其具体算法是:假设我们学习了一个Q-function,Q-function 就是输入s 跟a,输出Qπ(s,a)。然后接下来,我们要再学习一个actor,这个actor的功能就是输入一个状态 s,希望可以输出一个动作a。这个动作a被丢到Q-function以后,它可以让Qπ(s,a)的值越大越好。
在训练的时候,其实就是把Q跟actor接起来变成一个比较大的网络。Q是一个网络,输入s跟a,输出一个 value。Actor在训练的时候,它要做的事情就是输入s,输出a。把a丢到Q里面,希望输出的值越大越好。在训练的时候会把Q跟actor接起来,当作是一个大的网络。然后你会固定住Q的参数,只去调actor的参数,就用gradient ascent的方法去最大化Q的输出。
这其实就是GAN,是conditional GAN——Q就是GAN里面的 discriminator,但在强化学习叫做critic,actor在GAN里面就是generator,其实它们就是同一件事情。这样的话,在GAN里面尝试过的方法,都可以在Actor-Critic里面试一试效果。

