
- 1edge 错误 客户端和服务器不支持常用的 SSL 协议版本或密码套件
- 2功率谱 幅值谱_频谱、能谱、功率谱、倍频程谱、1/3 倍频程谱
- 3MinDoc v0.4 发布 轻量级文档在线管理系统
- 4毕业设计:基于深度学习的农作物病虫害识别系统 深度卷积 人工智能 机器视觉_基于深度学习的植物病虫害识别系统
- 5人脸识别开源算法库和开源数据库_opencv人脸识别模块
- 6亲测有效,已解决java.lang.IllegalStateException异常的正确解决方法,嘿嘿嘿_java.lang.illegalstateexception: error processing
- 7云服务器上搭建hadoop外网web页面9870无法访问及解决_hadoop无法连接9870
- 8C++11 设计模式6. 建造者模式,也叫做生成器模式
- 9前端发送请求之参数处理---【text/plain】与【application/json】_plain text application
- 10【python】基础知识复习_python复习资料
【Linux】进程的地址空间
赞
踩
思维导图

学习内容
地址是一个很重要的名词,我们的每一个进程在内存中运行都会有若干个地址。在之前我们学习进程的时候,学过一个函数——fork(),这个函数仅仅被调用一次,却能够返回两次。这是为什么呢?那么这一篇博客将会解释这种现象——进程的地址空间。
学习目标
- 通过一些奇怪的现象来引入进程的地址空间
- 进程地址空间的概念
- 地址空间的理解
- 为什么要有地址空间
- 如何理解虚拟地址
- Linux的调度算法
一、进程地址空间的引入
我们可以通过一个特别的代码来看到一个奇怪的现象:就是在同一个地址空间中,对于同一个变量的值是不同的,是不是感到很奇怪。在我们的认知和印象中,对于一个地址空间来说,只会有一个变量的大小,而不会出现多个值在同一个地址空间的现象,所以我们推断出这个地址空间一定不会是真正的物理地址,而是一种虚拟的地址空间。
进程 = 内核数据结构 + 代码(只读) + 数据,所以父子进程是具有独立性的。父子进程有一个进程退出不会影响其他进程。
- #include <iostream>
- #include <algorithm>
- #include <string>
- #include <cstring>
- #include <unistd.h>
- #include <sys/types.h>
- #include <sys/wait.h>
- using namespace std;
-
- int g_val = 100;
-
- int main()
- {
- pid_t id = fork();
- if(id == 0)
- {
- while (true)
- {
- cout << "I am child, g_val:" << g_val << ", dist:" << &g_val << endl;
- sleep(1);
- }
- }
- else if(id > 0)
- {
- g_val = 200;
- while (true)
- {
- cout << "I am prant, g_val:" << g_val << ", dist:" << & g_val << endl;
- sleep(1);
- }
- }
- return 0;
- }


二、进程地址空间的概念
进程地址空间不能简单的认为是内存,通过上面的现象,其也一定不是物理地址,因此一定是虚拟地址。这段空间中自下而上,地址是增长的,栈是向地址减小方向增长(栈是先使用高地址),而堆是向地址增长方向增长(堆是先使用低地址),堆栈之间的共享区,主要用来加载动态库。
每一个进程在启动时都会有一个进程地址空间的存在,进程地址空间是操作系统给进程花的“大饼”——告诉进程:操作系统中的所有物理地址都可以使用————使每个进程都认为自己独占系统内存资源。(即虚拟空间)。
2.1 对上面的代码进行解释
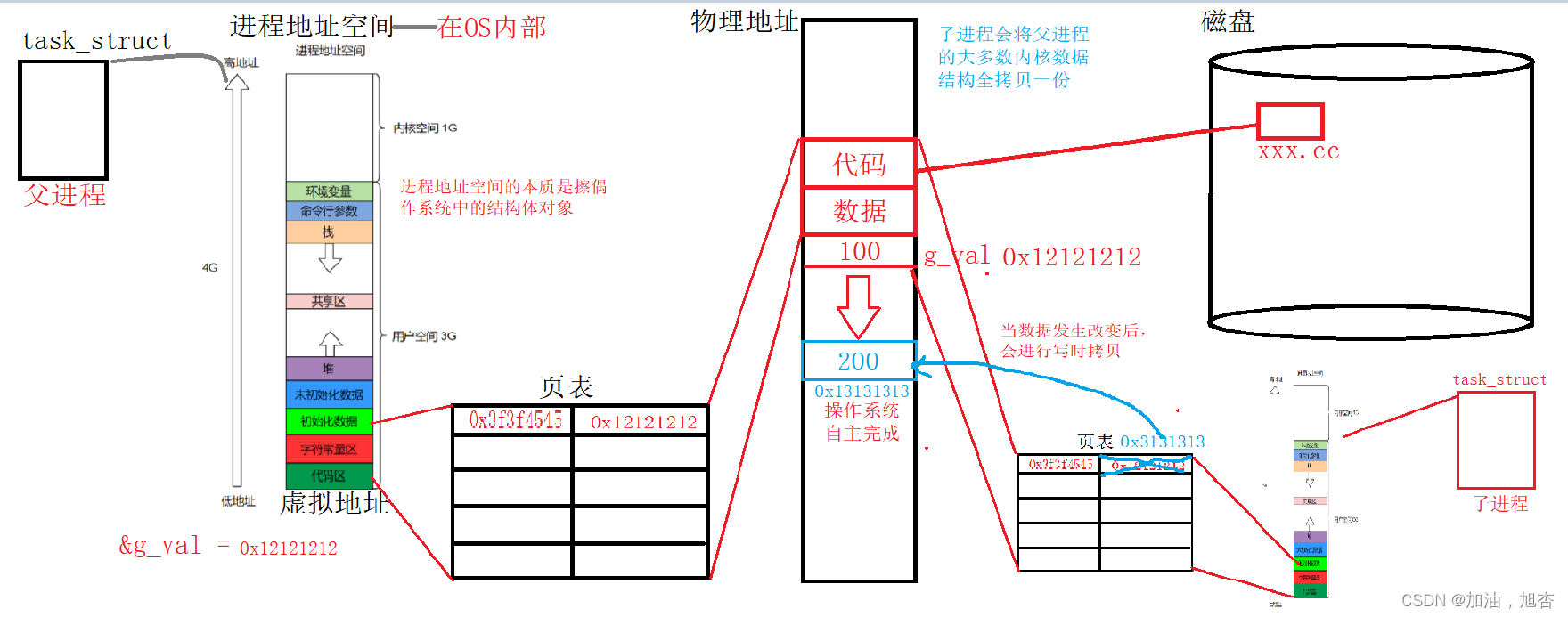
2.2 写时拷贝
2.2.1 写时拷贝的概念
写时拷贝的概念:就是等到修改数据时,才真正分配内存空间,这是对程序性能的优化,可以延迟甚至避免内存拷贝,当然目的就是避免不必要的拷贝。

2.2.2 写时拷贝的原理
写时拷贝实际上是运用了一个“引用计数”的概念来实现的,在开辟的空间中多维护了四个字节来存储引用计数。
有两种方式来存储引用计数:
- 多开辟四个字节(pCount)的空间,用来记录有多少个指针指向这片空间。
- 在开辟空间的头部预留四个字节的空间来记录有多少个指针指向这片空间。
当我们多开辟一个空间时,让引用计数 + 1,如果有释放空间,那么就让引用计数 - 1,但是此时不是真正的释放,是假释放,等到引用计数为0时,才是真正的释放空间。如果有修改或写的操作,那么也让原空间的引用计数-1,并且真正开辟新的空间。
三、进程地址空间的细节问题
3.1 地址空间的理解
3.1.1 什么是划分区域
我们可以通过一个例子来引出进程地址空间的划分区域。在同桌时期,我们同桌双方会约定在桌子上划分割线来确定我们各自的区域。那么在操作系统中,我们应该如何进行划分区域呢??我们知道进程地址空间的本质是操作系统中的一个结构体,在结构体中,我们可以定义变量来表示这个区域的起始点和终止点。
- struct area
- {
- int start;
- int end;
- };
-
- struct destop
- {
- struct area left;
- struct area right;
- };
在操作系统内核中,我们可以找到:

3.1.2 地址空间的理解
我们可以将操作系统当做英国的大富翁,将进程看成大富翁的私生子,大富翁告诉私生子:我有10亿的遗产,可以给你使用。每一个私生子都不知道彼此的存在,因此每一个私生子都以为自己会获得10亿的遗产,但是整体来看,这是不正确的。为什么操作系统可以这样做呢??因为进程在申请空间时,是不会将操作系统的物理地址全部申请过来,因此每次申请是够用的。
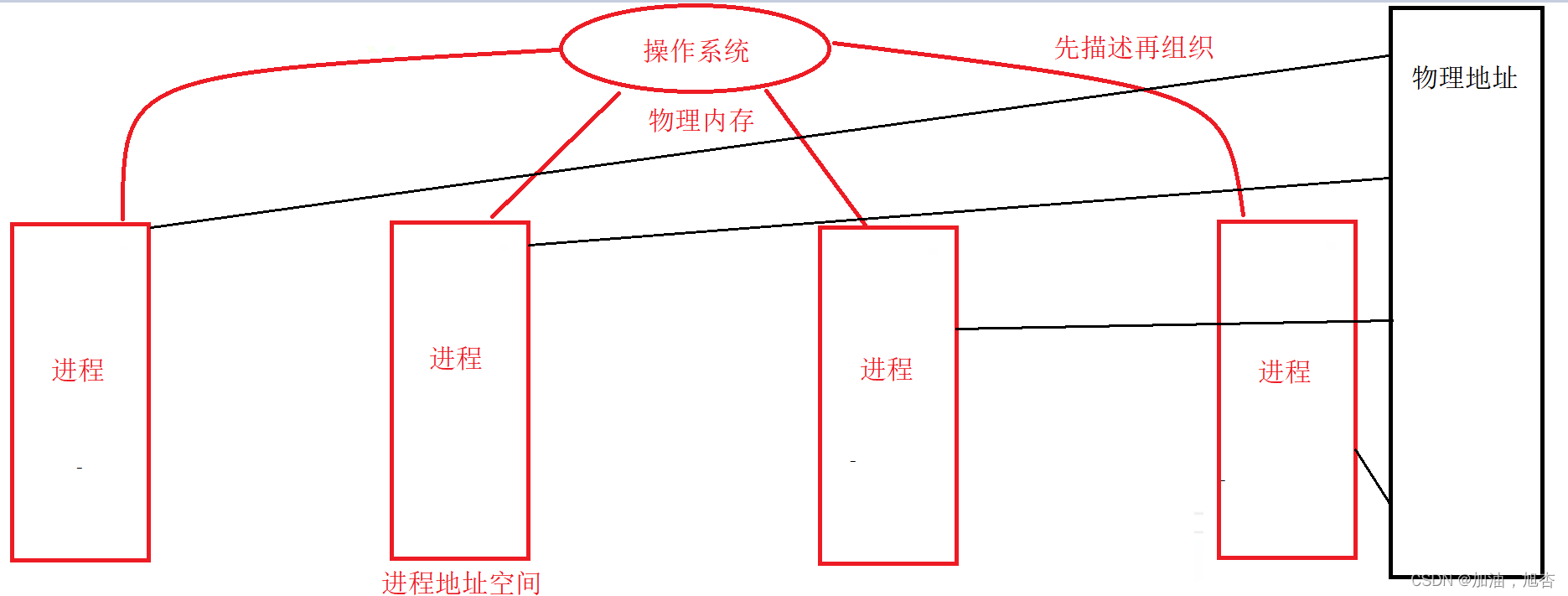
3.2 为什么要有地址空间
进程地址空间有三个好处:
- 可以将无序的地址空间变成有序的虚拟地址空间,让进程以统一的视角看待物理内存以及自己运行的各个区域
- 进程管理模块和内存管理模块进行解耦:有了进程地址空间后,每个进程都认为自己在独占内存,这样能更好的完成进程的独立性以及合理使用内存空间(当实际需要使用内存空间的时候再在内存进行开辟)
- 拦截非法请求
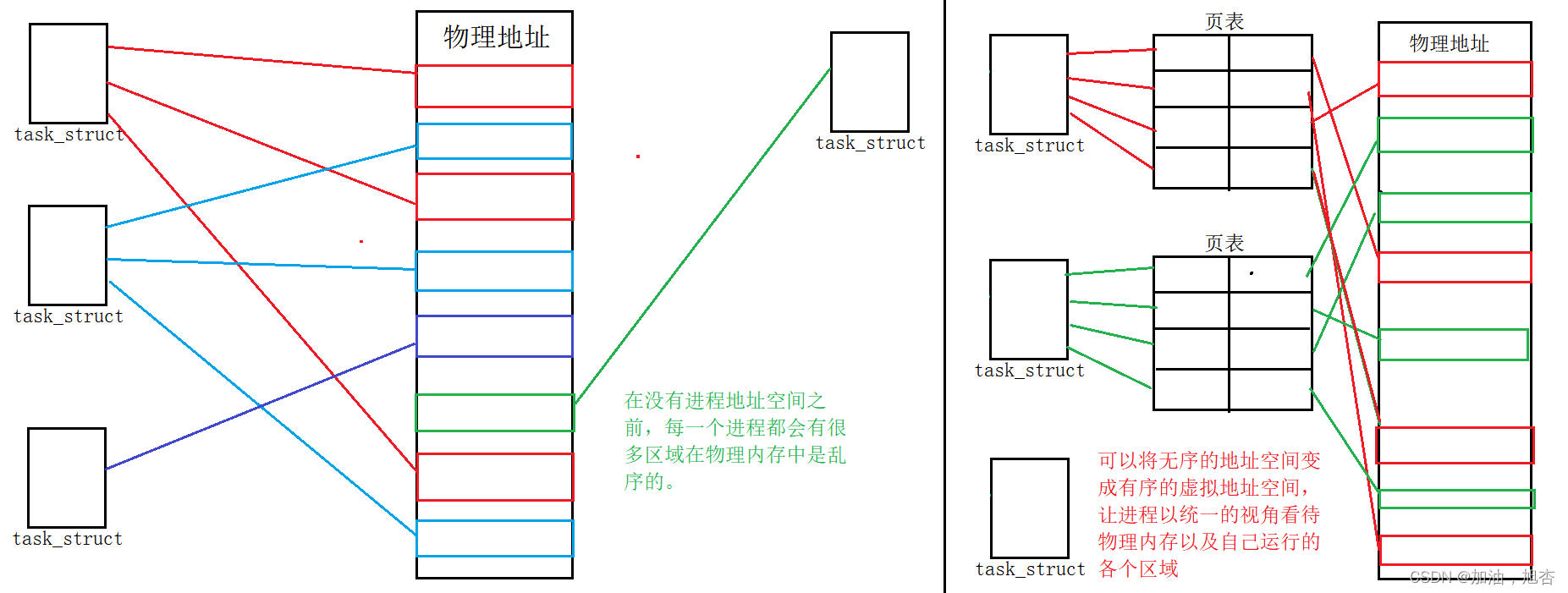
3.3 如何进一步理解页表和写时拷贝
3.3.1 页表
页表是非常复杂的。我们可以通过页表来完成一些操作:虚拟地址与物理地址的转化、页表的rwx权限、进程挂起。
3.3.1.1 虚拟地址与物理地址的转化
在CPU中,有CR3寄存器,将页表中的虚拟地址 + CR3,我们可以构成物理地址。
3.3.1.2 页表的rwx权限
举一个例子:我们在C语言中如果修改常量字符串,编译器会阻止你,不会使你修改常量字符串的,就是因为在页表中有一个rwx权限,常量字符串中的权限只有r,所以不能进行修改。在出现异常情况时,由于页表的存在,不会将系统内部进行破坏。
3.3.1.3 进程挂起
在页表中还有一个标志位:如果是0,表示进程挂起,将程序加载到磁盘中;如果是1,表示进程运行。

3.3.2 写时拷贝
由于页表将父子进程的代码的权限设置为r,当OS识别出错误时,我们可以进行分情况讨论:
- 是不是数据不在物理内存——缺页中断
- 是不是数据需要进行写时拷贝——进行写时拷贝
- 如果都不是,进行异常处理
3.4 如何理解地址空间
程序本身内部就有地址,我们可以通过下面的指令来看一看可执行程序的反汇编文件:
程序本身内部就有地址,这些地址就是虚拟地址,页表直接从中加载虚拟地址,在程序加载到内存中会出现物理地址,页表进行匹配,完成写入。

3.5 如何解释学习内容中关于fork函数的疑惑??
因为fork()函数在创建子进程后,将id的值发生改变,那么我们将会发生写时拷贝,就会使id的值返回两份。
四、Linux的进程调度队列

4.1 一个CPU中只有一个运行队列
Linux系统中每一个CPU中拥有一个运行队列,如果有多个CPU就要考虑进程个数的父子均衡问题。Linux系统是分时操作系统,讲究公平。
4.2 优先级
queue数组的下标说明:
- 普通优先级:100~139
- 实时优先级:0~99
在之前的优先级中讲过nice值的取值范围是:-20~19,而这里的普通优先级下标正好也是40个。在Linux系统中,我们的进程是普通的优先级,所以一一对应queue数组的100~139。
而还有一个系统:实时操作系统。实时优先级对应实时进程,实时进程是指先将一个进程执行完毕再执行下一个进程,现在基本不存在这种机器了,所以对于queue当中下标为0~99的元素我们不关心。

由于队列的数组元素过多,我们可以使用位图来判定哪个优先级对应有进程。因为有140的元素,所以我们可以使用5个整形数组的元素可以将整个元素表示出来。我们可以通过数字的二进制来发现哪个优先级上有进程运行,搜寻次数大大减少。
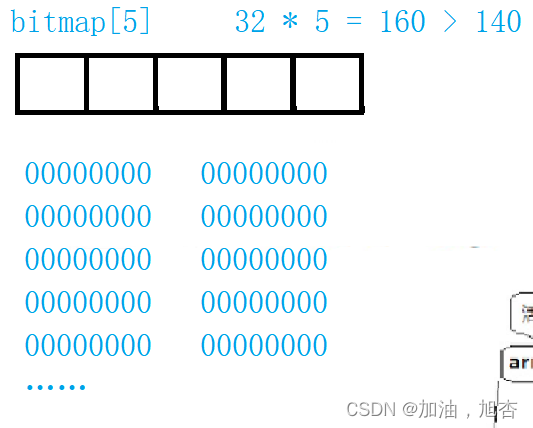
4.3 活动队列(只出不进)
队列中的三个元素:nr_active、bitmap[5]、queue[140]。
nr_active:代表总共有多少个运行状态的进程;
bitmap[5]:位图,表示哪个优先级上有运行状态的进程;
queue[140]:表示的是优先级,分为普通优先级和实时优先级。

时间片还没有结束的所有进程都按照优先级放在活动队列当中,相同优先级的进程按照FIFO规则进程排队调度。
调度过程如下:
- 从0下标开始遍历bitmap[5]。
- 找到第一个非空队列,该队列必定为优先级最高的队列。
- 拿到选中队列的第一个进程,开始运行,调度完成。
- 接着拿到选中队列的第二个进程进行调度,直到选中进程队列当中的所有进程都被调度。
- 继续向后遍历bitmap[5],寻找下一个非空队列。
4.4 过期队列(只进不出)
- 过期队列和活动队列的结构相同。
- 过期队列上放置的进程都是时间片耗尽的进程。
- 当活动队列上的进程被处理完毕之后,对过期队列的进程进行时间片重新计算。
4.5 active指针和expired指针
- active指针永远指向活动队列
- expired指针永远指向过期队列
当活动队列上的进程随着时间片的轮转,数量会越来越少;而过期队列的进程会越来越多;直到时间片到期,活动队列的进程为0,过期队列的进程数量最大。此时,操作系统只需交换一下active指针和expired指针,将指针内容进行交换,继续进行时间片的轮转即可,如此循环往复。

