
热门标签
热门文章
- 1【python】flask框架的生命周期,多种查询参数的获取方式_flask 查询参数
- 2git安装和使用_gethup下载
- 3网络爬虫——GO_go 爬虫
- 4Spring Boot 框架_springboot框架
- 5决策树算法--C4.5算法_c4.5连续与缺失的处理去采用信息增益
- 6uniapp+vue3+vant-weapp运行到微信小程序中绘制海报,将画布中绘制base64格式的图片以及长按进行图片的分享和下载
- 7JAVA OJ练习第8题——链表的回文结构_acm回文链表 oj java
- 8java.lang.NullPointerException异常的正确解决方法,亲测有效!!!_java.lang.nullpointerexception解决办法
- 9redis 事务
- 10sql sever如何进行英文词频统计_英语语料库及词频表介绍
当前位置: article > 正文
数据结构与算法之快速排序_数据结构快速排序
作者:笔触狂放9 | 2024-05-23 23:49:00
赞
踩
数据结构快速排序
快速排序概念
快速排序(Quick Sort),又称划分交换排序(partition-exchange sort),通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
排序步骤:
- 1、 从数列中挑出一个元素,称为"基准"(pivot),通常选择第一个元素
- 2、重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 3、递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
动图展示:
- 动图1

- 动图2:

静图分析:
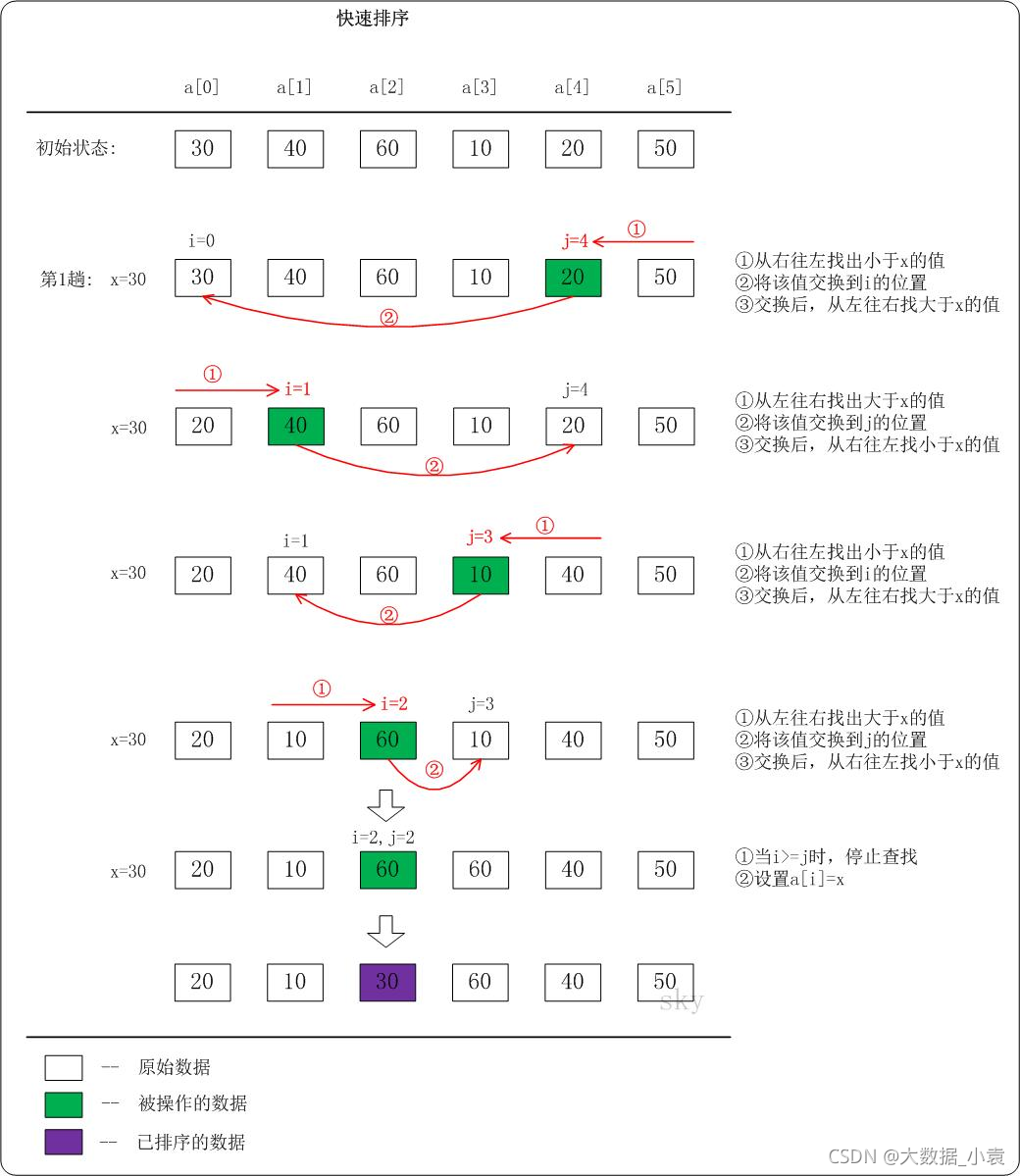
代码实现
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
int[] arr = {30, 40, 60, 10, 20, 50};
quickSort(arr, 0, arr.length - 1);
// [20, 10, 30, 60, 40, 50]
// [10, 20, 30, 60, 40, 50]
// [10, 20, 30, 60, 40, 50]
// [10, 20, 30, 50, 40, 60]
// [10, 20, 30, 40, 50, 60]
// [10, 20, 30, 40, 50, 60]
}
//快速排序
public static void quickSort(int[] arr, int start, int end) {
//递归结束的标记
if (start < end) {
//把数组中第0个数字作为标准数
int stard = arr[start];
//记录需要排序的下标
int low = start;
int high = end;
//循环找比标准数大的数和标准数小的数
while (low < high) {
//如果右边数字比标准数大,下标向前移
while (low < high && arr[high] >= stard) {
high--;
}
//右边数字比标准数小,使用右边的数替换左边的数
arr[low] = arr[high];
//如果左边数字比标准数小
while (low < high && arr[low] <= stard) {
low++;
}
//左边数字比标准数大,使用左边的数替换右边的数
arr[high] = arr[low];
}
//把标准数赋给低所在的位置的元素
arr[low] = stard;
//打印每次排序后的结果
System.out.println(Arrays.toString(arr));
//递归处理所有标准数左边的数字(含标准数)
quickSort(arr, start, low);
//递归处理所有标准数右边的数字
quickSort(arr, low + 1, end);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
时间复杂度
- 最优时间复杂度:
O(nlogn) - 最坏时间复杂度:
O(n^2) - 稳定性:不稳定
从一开始快速排序平均需要花费O(n log n)时间的描述并不明显。但是不难观察到的是分区运算,数组的元素都会在每次循环中走访过一次,使用O(n)的时间。在使用结合(concatenation)的版本中,这项运算也是O(n)。
在最好的情况,每次我们运行一次分区,我们会把一个数列分为两个几近相等的片段。这个意思就是每次递归调用处理一半大小的数列。因此,在到达大小为一的数列前,我们只要作log n次嵌套的调用。这个意思就是调用树的深度是O(log n)。但是在同一层次结构的两个程序调用中,不会处理到原来数列的相同部分;因此,程序调用的每一层次结构总共全部仅需要O(n)的时间(每个调用有某些共同的额外耗费,但是因为在每一层次结构仅仅只有O(n)个调用,这些被归纳在O(n)系数中)。结果是这个算法仅需使用O(n log n)时间。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/614903
推荐阅读

相关标签

