
- 1快速上手的AI工具 - 文心编码辅助
- 2java.lang.ClassCastException: class java.lang.Integer cannot be cast to class java.lang.String
- 3第三代AlphaFold发布:生物大分子复合物结构预测问题将被解决?_alphafold3
- 4html网页制作——奶茶网页设计与实现(HTML+CSS+JavaScript)_奶茶店网站具体设计
- 5Docker部署GitLab代码托管工具保姆级教程(小白都能学会)_docker部署代码管理工具
- 6mysql honeypot_Mysql使用语法总结
- 7决策树DTC数据分析及鸢尾数据集分析_决策树分析源数据
- 8python发送邮件的时候出现 error (535, b‘5.7.3 Authentication unsuccessful‘) 解决方法_535, b'5.7.139 authentication unsuccessful, smtpcl
- 9【Python】PySpark 数据处理 ② ( 安装 PySpark | PySpark 数据处理步骤 | 构建 PySpark 执行环境入口对象 )_pyspark安装
- 10C语言 数据结构 链表 基本操作代码_数据结构链表c语言代码
Windows下搭建kafka环境并测试_windows 搭建kafka
赞
踩
一:kafka介绍
kafka(官网地址:http://kafka.apache.org)是一种高吞吐量的分布式发布订阅的消息队列系统,具有高性能和高吞吐率。
1.1 术语介绍
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
主题:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition
分区:Partition是物理上的概念,每个Topic包含一个或多个Partition.(一般为kafka节点数cpu的总核数)
- Producer
生产者,负责发布消息到Kafka broker
- Consumer
消费者:从Kafka broker读取消息的客户端。
- Consumer Group
消费者组:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
1.2 基本特性
- 可扩展性
在不需要下线的情况下进行扩容
数据流分区(partition)存储在多个机器上
- 高性能
单个broker就能服务上千客户端
单个broker每秒种读/写可达每秒几百兆字节
多个brokers组成的集群将达到非常强的吞吐能力
- 性能稳定,无论数据多大
Kafka在底层摒弃了Java堆缓存机制,采用了操作系统级别的页缓存,同时将随机写操作改为顺序写,再结合Zero-Copy的特性极大地改善了IO性能。
1.3 消息格式
一个topic对应一种消息格式,因此消息用topic分类
一个topic代表的消息有1个或者多个patition(s)组成
一个partition应该存放在一到多个server上,如果只有一个server,就没有冗余备份,是单机而不是集群;如果有多个server,一个server为leader(领导者),其他servers为followers(跟随者),leader需要接受读写请求,followers仅作冗余备份,leader出现故障,会自动选举一个follower作为leader,保证服务不中断;每个server都可能扮演一些partitions的leader和其它partitions的follower角色,这样整个集群就会达到负载均衡的效果
消息按顺序存放;消息顺序不可变;只能追加消息,不能插入;每个消息都有一个offset,用作消息ID, 在一个partition中唯一;offset有consumer保存和管理,因此读取顺序实际上是完全有consumer决定的,不一定是线性的;消息有超时日期,过期则删除
1.4 原理解析
producer创建一个topic时,可以指定该topic为几个partition(默认是1,配置num.partitions),然后会把partition分配到每个broker上,分配的算法是:a个broker,第b个partition分配到b%a的broker上,可以指定有每个partition有几分副本Replication,副本的分配策略为:第c个副本存储在第(b+c)%a的broker上。一个partition在每个broker上是一个文件夹,文件夹中文件的命名方式为:topic名称+有序序号。每个partition中文件是一个个的segment,segment file由.index和.log文件组成。两个文件的命名规则是,上一个segmentfile的最后一个offset。这样,可以快速的删除old文件。
producer往kafka里push数据,会自动的push到所有的分区上,消息是否push成功有几种情况:1,接收到partition的ack就算成功,2全部副本都写成功才算成功;数据可以存储多久,默认是两天;producer的数据会先存到缓存中,等大小或时间达到阈值时,flush到磁盘,consumer只能读到磁盘中的数据。
consumer从kafka里poll数据,poll到一定配置大小的数据放到内存中处理。每个group里的consumer共同消费全部的消息,不同group里的数据不能消费同样的数据,即每个group消费一组数据。
consumer的数量和partition的数量相等时消费的效率最高。这样,kafka可以横向的扩充broker数量和partitions;数据顺序写入磁盘;producer和consumer异步
二:环境搭建(windows)
2.1 安装zookeeper
1、kafka需要用到zookeeper,所以需要先安装zookeeper
2、到官网下载最新版zookeeper,http://www.apache.org/dyn/closer.cgi/zookeeper/ 官网目前有两个版本,注意下载带bin名称的版本,否则自动zookeeper时会报错 找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain
3、解压到指定路径
复制conf目录下zoo_sample.cfg,粘贴改名为zoo.cfg,修改zoo.cfg中的dataDir的值为E:/data/zookeeper,并添加一行dataLogDir=E:/log/zookeeper
4、修改系统环境变量,在Path后添加 ;E:\zookeeper\zookeeper-3.4.10\bin
运行cmd命令窗口,输入zkServer回车,启动
2.2 安装kafka
1、到官网下载最新版kafka,http://kafka.apache.org/downloads
2、解压到指定路径,如:E:\kafka_2.12-0.10.2.0
3、修改E:\kafka_2.12-0.10.2.0\config目录下的server.properties中 log.dirs的值为E:/log/kafka
4、添加系统环境变量,在Path后添加 ;E:\kafka_2.12-0.10.2.0\bin\windows
5、启动kafka,在cmd命令行用cd命令切换到kafka根目录E:\kafka_2.12-0.10.2.0,输入命令
.\bin\windows\kafka-server-start.bat .\config\server.properties
出现started (kafka.server.KafkaServer)字样表示启动成功
2.3 测试kafka
1、运行cmd命令行,创建一个topic,命令如下:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
2、再打开一个cmd,创建一个Producer,命令如下:
kafka-console-producer.bat --broker-list localhost:9092 --topic test
3、再打开一个cmd,创建一个Customer,命令如下:
一般的博客写的创建指令: kafka-console-consumer.bat --zookeeper localhost:2181 --topic test,这个指令会报错zookeeper is not a recognized option
使用这条指令: kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
在Producer窗口下输入信息进行测试 ,每输入一行回车后消息马上就会出现在Customer中,表明kafka已经安装测试成功
三:基于.net的常用类库
基于.net实现kafka的消息队列应用,常用的类库有kafka-net,Confluent.Kafka,官网推荐使用Confluent.Kafka,本文也是基于该库的实现,使用版本预发行版1.0.0-beta,创建控制台应用程序。
四:应用–生产者
生产者将数据发布到指定的主题,一般生产环境下的负载均衡,服务代理会有多个,BootstrapServers属性则为以逗号隔开的多个代理地址
- /// <summary>
- /// 生产者
- /// </summary>
- public static void Produce()
- {
- var config = new ProducerConfig { BootstrapServers = "localhost:9092" }
- Action<DeliveryReportResult<Null, string>> handler = r =>
- Console.WriteLine(!r.Error.IsError
- ? $"Delivered message to {r.TopicPartitionOffset}"
- : $"Delivery Error: {r.Error.Reason}");
-
- using (var producer = new Producer<Null, string>(config))
- {
- // 错误日志监视
- producer.OnError += (_, msg) => { Console.WriteLine($"Producer_Erro信息:Code:{msg.Code};Reason:{msg.Reason};IsError:{msg.IsError}"); };
-
- for (int i = 0; i < 5; i++)
- {
- // 异步发送消息到主题
- producer.BeginProduce("MyTopic", new Message<Null, string> { Value = i.ToString() }, handler);
- }
- // 3后 Flush到磁盘
- producer.Flush(TimeSpan.FromSeconds(3));
- }
- }

五:应用–消费者
消费者使用消费者组名称标记自己,并且发布到主题的每个记录被传递到每个订阅消费者组中的一个消费者实例。消费者实例可以在单独的进程中,也可以在不同的机器
如果所有消费者实例具有相同的消费者组,则记录将有效地在消费者实例上进行负载平衡。
如果所有消费者实例具有不同的消费者组,则每个记录将广播到所有消费者进程
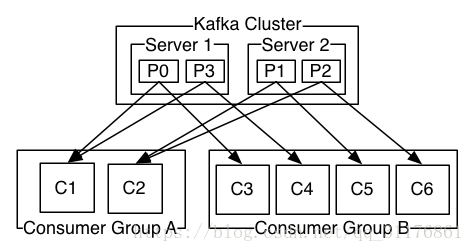
上图为两个服务器Kafka群集,托管四个分区(P0-P3),包含两个消费者组。消费者组A有两个消费者实例,B组有四个消费者实例。
默认EnableAutoCommit 是自动提交,只要从队列取出消息,偏移量自动移到后一位,无论消息后续处理成功与否,该条消息都会消失,所以为免除处理失败的数据丢失,消费者方可设置该属性为false,后面进行手动commint()提交偏移
- /// <summary>
- /// 消费者
- /// </summary>
- public static void Consumer()
- {
- var conf = new ConsumerConfig
- {
- GroupId = "test-consumer-group",
- BootstrapServers = "localhost:9092",
- AutoOffsetReset = AutoOffsetResetType.Earliest,
- EnableAutoCommit = false // 设置非自动偏移,业务逻辑完成后手动处理偏移,防止数据丢失
- };
-
- using (var consumer = new Consumer<Ignore, string>(conf))
- {
- // 订阅topic
- consumer.Subscribe("MyTopic");
- // 错误日志监视
- consumer.OnError += (_, msg) => { Console.WriteLine($"Consumer_Error信息:Code:{msg.Code};Reason:{msg.Reason};IsError:{msg.IsError}"); };
-
- while (true)
- {
- try
- {
- var consume = consumer.Consume();
- string receiveMsg = consume.Value;
- Console.WriteLine($"Consumed message '{receiveMsg}' at: '{consume.TopicPartitionOffset}'.");
- // 开始我的业务逻辑
- ...
- // 业务结束
- if(成功)
- {
- consumer.Commit(new List<TopicPartitionOffset>() { consume.TopicPartitionOffset }); //手动提交偏移
- }
- }
- catch (ConsumeException e)
- {
- Console.WriteLine($"Consumer_Error occured: {e.Error.Reason}");
- }
- }
- }
- }
执行结果
常见数据问题处理
重复消费最常见的原因:re-balance问题,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的session timeout时间(0.10.x版本默认是30秒),那么就会re-balance重平衡,此时有一定几率offset没提交,会导致重平衡后重复消费。
去重问题:消息可以使用唯一id标识
保证不丢失消息:
生产者(ack= -1 或 all 代表至少成功发送一次)
消费者 (offset手动提交,业务逻辑成功处理后,提交offset)
保证不重复消费:落表(主键或者唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到Redis或者mongdb中,先查询是否存在,若存在则不处理;若不存在,先插入Redis或Mongdb,再进行业务逻辑处理)
Kafka 可视化调试
借助可视化客户端工具 kafka tool
具体使用可参考:https://www.cnblogs.com/frankdeng/p/9452982.html

