
- 1算法-动态规划入门(C++实现)_c++动态规划
- 2Guitar Pro8软件激活码许可证如何获取?最新2024年免费教学步骤_guitarpro8许可证
- 3CNN中的卷积的作用及原理通俗理解_添加卷积cnn的作用是什么?
- 4HybridCLR热更新介绍
- 5用I/O流建立一个text.txt并写入字符。_用io流以文本方式建立一个文件txt,写入字符
- 6Redis集群原理和总结_redis的无主集群
- 7网络原理——TCP/IP--数据链路层,DNS
- 8Java安全--CC1的补充和CC6_yso cc6
- 9计划有变,国内应用厂商都在适配HarmonyOS?_haromony os next 适配情况_鸣潮适配鸿蒙吗
- 10基于OpenHarmony 系统通过S7协议读取西门子PLC数据_go plc s7
Ops实践 | 从零开始,在云原生环境下快速实现K8S集群可视化监控
赞
踩


微信改版了,现在看到我们全凭缘分,为了不错过【全栈工程师修炼指南】重要内容及福利,大家记得按照上方步骤设置「接收文章推送」哦~
关注回复【交流群】加入【SecDevOps】学习答疑群交流群!
原文链接:Ops实践 | 从零开始,在云原生环境下快速实现K8S集群可视化监控
前言简述:
描述: 上一章作者讲解了如何监控预警Windows/Linux系统服务器的资源,相信看过小伙伴们已经掌握实践过了吧,若还没看过的小伙伴也可以去看看,一定会让您收获满满的。此小节作者将继续讲解,如何在云原生的环境中使用Prometheus 来针对内部或者外部的 kubernetes 集群以及容器Pod指标进行监控和预警,以及使用 Grafana 工具针对的采集指标数据进行可视化展示。
此处作者在内部或外部K8S集群中以 DaemonSet 控制器形式部署 node-exporter(版本:v1.7.0)导出器,从而来动态采集K8S集群node节点的服务器的各类资源数据,如cpu、内存、磁盘、网络流量等, 然后使用cadvisor来采集集群中容器监控指标(cadvisor集成在K8S的kubelet中所以无需部署), 最后自定义要抓取采集指定的Pod容器中指标, 所以说此文适用于有多K8S集群需要监控预警的朋友。说到这里,作者也请大家多多支持《#云原生落地实用指南》专栏(一杯茶颜悦色,就手把手实践企业在云原生环境下的监控预警),作者也将会持续更新此专栏,发布更多的云原生落地实践文章。
温馨提示:已付费此专栏的看友,若需要文章中的部署资源清单以及相关配置,请关注公众号回复【10014】或者直接添加作者WX。
此篇文章将实现如下架构图所示中针对内部K8S集群以及外部K8S集群监控。
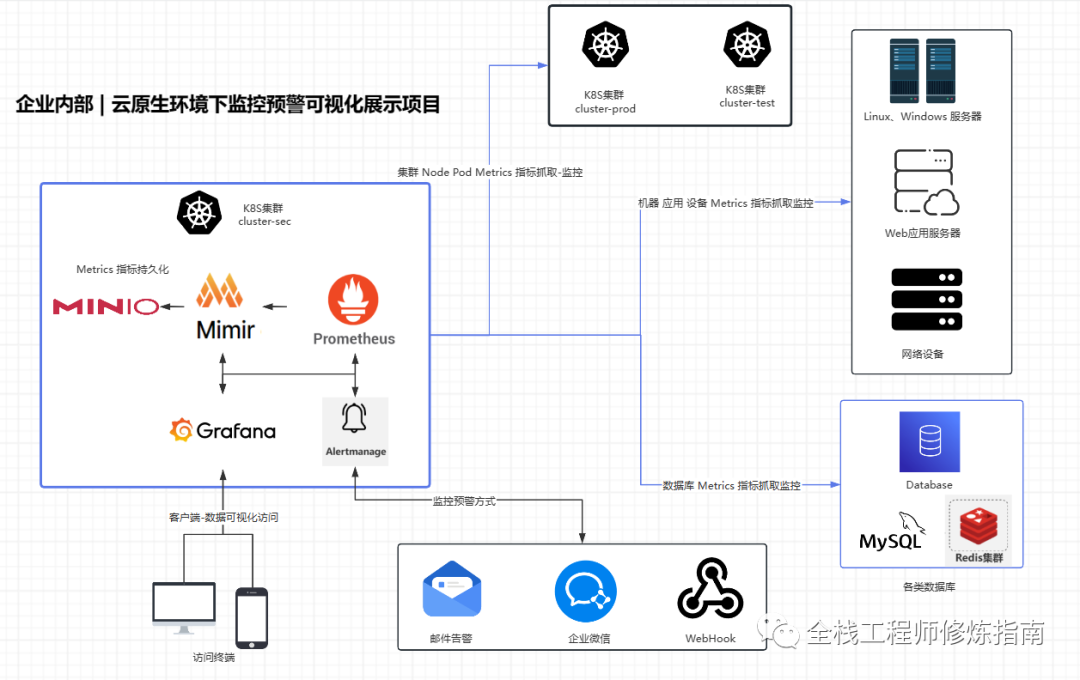
0.外部K8S集群节点监控指标抓取图
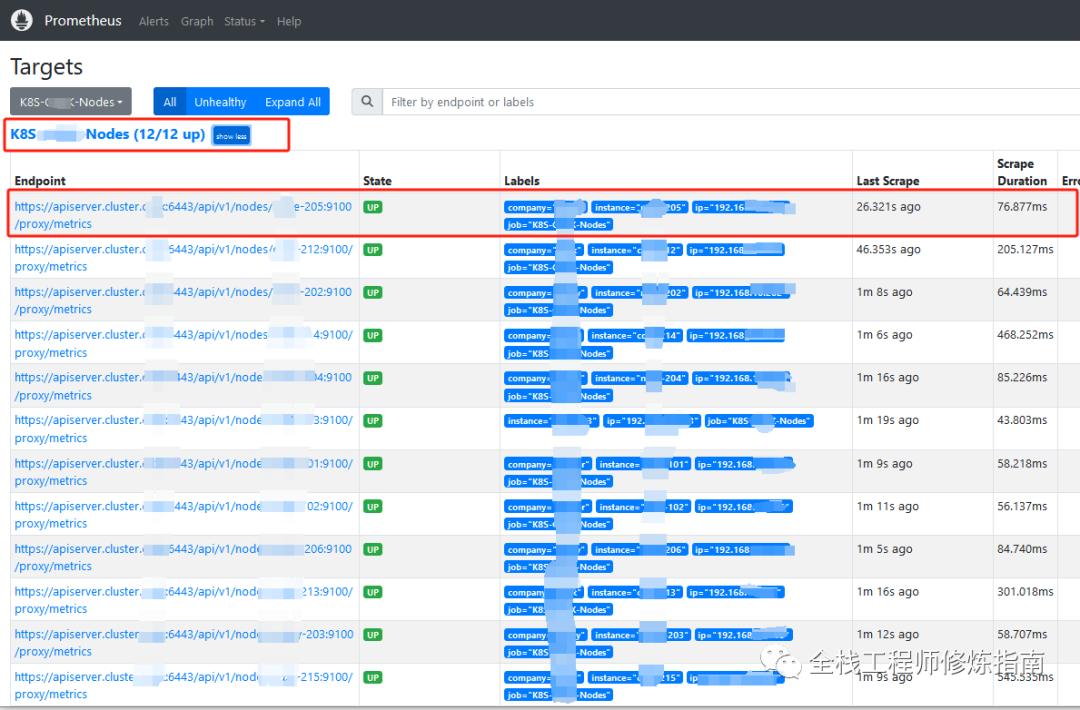
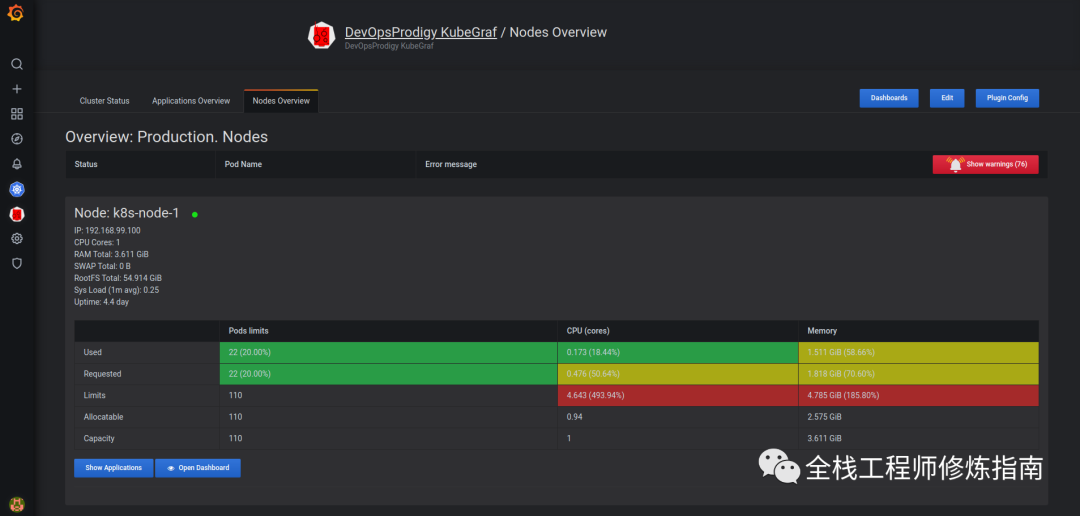
1.K8S集群节点可视化监控图
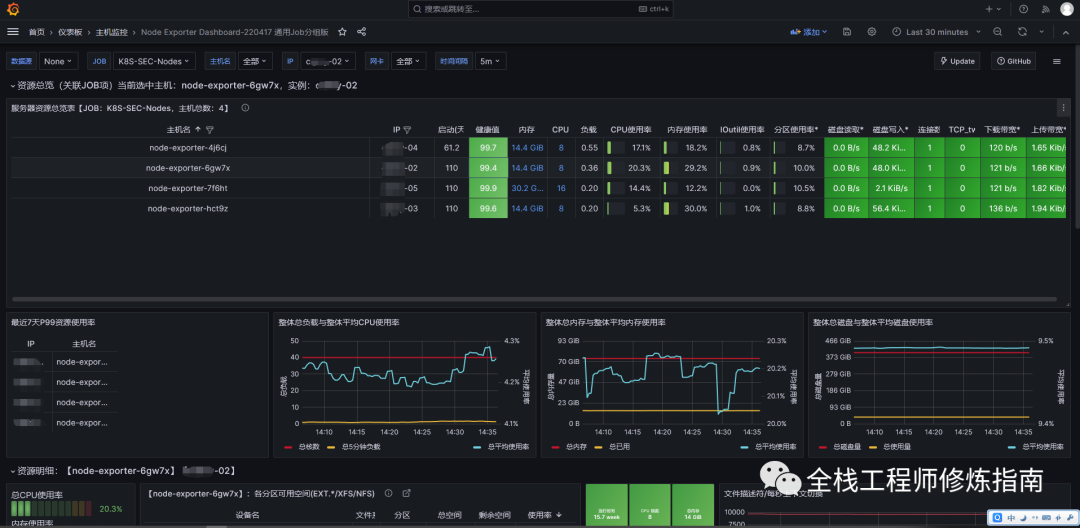
2.K8S集群容器可视化监控图
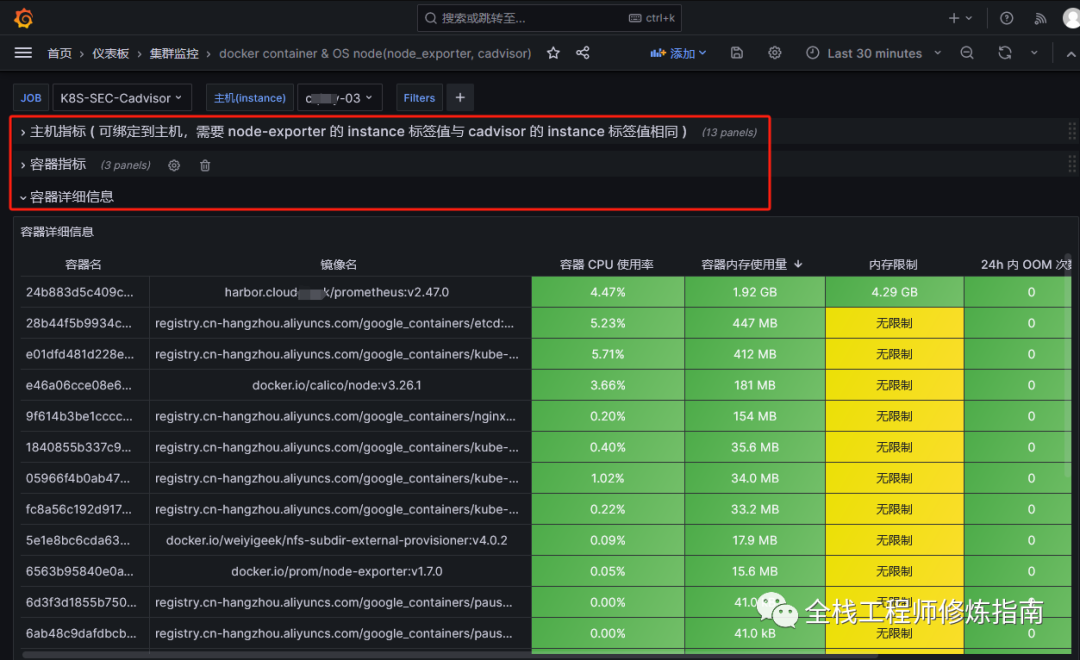
3.在Grafana中使用KubeGraf插件来监控K8S集群
0x00 前置知识
如何实现 Kubernetes 集群内监控指标的抓取?
-
Node 资源监控 :使用
node-exporter 工具来实现各K8S节点 Node 的CPU、内存利用率等监控, 其__metrics_path__为:/api/v1/nodes/node名:9100/proxy/metrics。 -
Pod 资源监控 :使用 kubelet 中集成的
cadvisor 工具来实现容器 Pod 的CPU、内存利用率等监控,其__metrics_path__为:/api/v1/nodes/node名/proxy/metrics/cadvisor。 -
K8S 资源监控 : 使用
kube-state-metrics 工具来实现K8S集群中 pod、deployment、service等各资源监控,其__metrics_path__需要按照__scheme__://__address____metrics_path__基于 Prometheus 的动态发现会基于标签进行自动补全;或者使用Metrics-Server用于收集聚合节点和Pod的指标数据, 其__metrics_path__为:/api/v1/nodes/node名:10250/proxy/metrics。
知识扩展:
在Kubernetes集群中,Metrics-Server、kube-state-metrics、cAdvisor 之间的区别
-
Metrics-Server:
-
Metrics-Server是Kubernetes官方提供的一个轻量级指标收集器,用于收集和聚合节点和Pod的指标数据。
-
Metrics-Server通过Kubernetes的Metrics API(/apis/metrics.k8s.io)提供指标数据,包括CPU使用率、内存使用量和网络流量等。
-
Metrics-Server主要用于自动扩展和调度Pod,以确保资源的合理利用。
kube-state-metrics:
-
kube-state-metrics是一个独立于Kubernetes官方的开源项目,用于提供更详细和全面的集群状态指标数据。
-
kube-state-metrics通过监听Kubernetes API服务器的事件和对象状态来收集指标数据,包括Pod、Node、Deployment、ReplicaSet、Service等。
-
kube-state-metrics提供了更多关于集群对象的详细指标,如副本数量、重启次数、容器状态等,可以用于监控和分析集群的运行状况和性能。
cAdvisor:
-
cAdvisor(Container Advisor)是一个开源项目,由Google开发,用于收集和提供容器级别的指标数据。
-
cAdvisor通过在每个节点上运行的代理程序来监控容器的资源使用情况,包括CPU、内存、磁盘和网络等。
-
cAdvisor提供了容器级别的指标数据,可以用于监控和分析容器的性能和资源使用情况。
总结:Metrics-Server主要用于监控节点和Pod的基本指标数据,kube-state-metrics提供了更详细和全面的集群状态指标数据,而cAdvisor专注于容器级别的指标数据。在实际使用中,可以根据需求选择部署和使用这些组件,以获得全面的监控和分析能力。
温馨提示:此处的实践的云原生环境, 是在 国产化操作系统KylinOS V10服务器中部署的(国产化替代大趋势),具体搭建配置请参照此文《从零开始:新手快速在国产操作系统中搭建高可用K8S(V1.28)集群落地实践》其中已完成了 Metrics-Server 的安装,若要进行完成符合等保三级的主机安全配置,请参考此篇文章《网安等保-国产Linux操作系统银河麒麟KylinOS-V10SP3常规配置、系统优化与安全加固基线实践文档》。
温馨提示:下述操作在没有明确说是在Prometheus服务所在集群中操作的,默认就是在被要监控(抓取目标)的K8S集群中运行。
0x01 实践记录
操作流程:
Step 1.创建一个名为 monitor 的名称空间,此处不建议直接在 kube-system 空间下部署此服务,可以极大防止误操作,若没有创建此名称空间,请使用如下命令进行创建kubectl create ns monitor
Step 2.创建一个名为 prometheus 的 serviceaccount 以及 clusterRole 角色,主要用于 RBAC 权限的声明和控制,决定了使用此用户访问集群资源权限。
- tee prometheus-rabc-setup.yaml <<'EOF'
- apiVersion: v1
- kind: ServiceAccount
- metadata:
- name: prometheus
- namespace: monitor
- ---
- apiVersion: rbac.authorization.k8s.io/v1
- kind: ClusterRole
- metadata:
- name: prometheus
- namespace: monitor
- rules:
- - apiGroups: [""]
- resources:
- - nodes
- - services
- - endpoints
- - pods
- - nodes/proxy
- - pods/proxy
- verbs: ["get", "list", "watch"]
- - apiGroups: [""]
- resources:
- - configmaps
- - nodes/metrics
- verbs:
- - get
- - apiGroups:
- - "extensions"
- resources:
- - ingresses
- verbs: ["get", "list", "watch"]
- - nonResourceURLs: ["/metrics", "/metrics/cadvisor"]
- verbs: ["get"]
- ---
- apiVersion: rbac.authorization.k8s.io/v1
- kind: ClusterRoleBinding
- metadata:
- name: prometheus
- roleRef:
- apiGroup: rbac.authorization.k8s.io
- kind: ClusterRole
- name: prometheus
- subjects:
- - kind: ServiceAccount
- name: prometheus
- namespace: monitor
- EOF
-
- # 创建 rabc
- kubectl apply -f prometheus-rabc-setup.yaml

Step 3.创建部署 DaemonSet 控制器管理的 node-exporter 服务,使之运行在不同的节点之上。
- # 资源清单
- tee node-exporter-DaemonSet.yaml <<'EOF'
- kind: DaemonSet
- apiVersion: apps/v1
- metadata:
- name: node-exporter
- namespace: monitor
- labels:
- k8s-app: node-exporter
- annotations:
- prometheus.io/scrape: 'true'
- spec:
- selector:
- matchLabels:
- k8s-app: node-exporter
- template:
- metadata:
- labels:
- k8s-app: node-exporter
- name: node-exporter
- spec:
- containers:
- - image: prom/node-exporter:v1.7.0
- name: node-exporter
- ports:
- - containerPort: 9100
- hostPort: 9100
- name: http
- hostNetwork: true
- hostPID: true
- tolerations:
- - key: "node-role.kubernetes.io/master"
- operator: "Exists"
- effect: "NoSchedule"
- ---
- kind: Service
- apiVersion: v1
- metadata:
- name: node-exporter
- namespace: monitor
- labels:
- k8s-app: node-exporter
- annotations:
- prometheus.io/scrape: 'true'
- prometheus.io/port: '9100'
- prometheus.io/path: '/metrics'
- spec:
- type: ClusterIP
- clusterIP: None
- ports:
- - name: http
- port: 9100
- protocol: TCP
- selector:
- k8s-app: node-exporter
- EOF
-
- # 部署 node-exporter
- kubectl apply -f node-exporter-DaemonSet.yaml
- # daemonset.apps/node-exporter created
- # service/node-exporter created
-
- # 查看部署
- kubectl get svc,pod -n monitor -o wide
-
- # 验证部署
- curl -s 192.168.11.102:9100/metrics | head -n 10
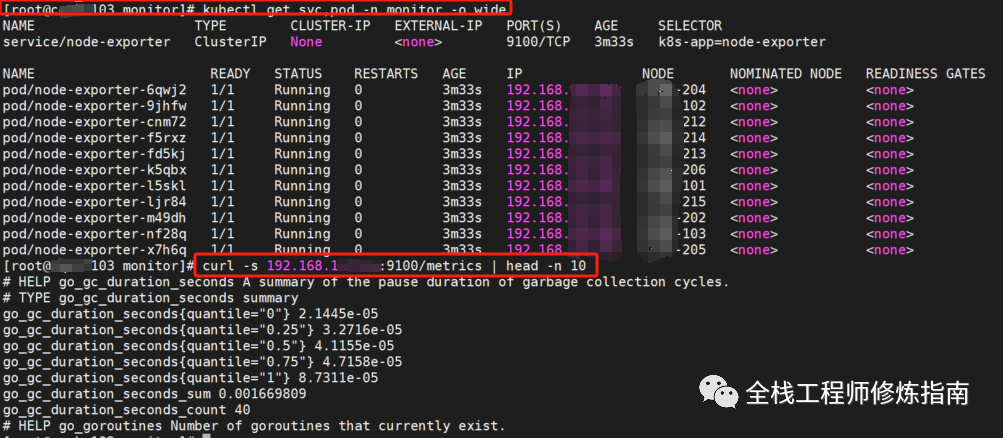
至此,在K8S集群中部署 node-exporter 实践完毕,下面我们分别来配置内部、外部K8S集群的节点指标采集和监控!
1.内部集群监控指标拉取
描述:此处的集群内部(本地)表示是我们 Prometheus 服务所部署在的K8S集群对象,即在此集群中安装了Prometheus等相关服务,在此合集《Ops实践 | 从零开始,搭建云原生环境下企业监控预警可视化平台》中,安装Prometheus时同样进行了Prometheus的servicesaccount、clusterrole 、ClusterRoleBinding 等资源的创建,此处不累多说,直接开始 Prometheus 抓取K8S集群节点指标、Pod 指标配置。

