
- 1粒子群算法调参支持向量回归进行预测(PSO-SVR)Python实现_pso-svr python
- 2分词及去停用词(可用作科研实验)python_python分词停用词库
- 3数据库中的算法实现_数据库算法实现
- 4Navicat 导入数据时报Incorrect datetime value: '0000-00-00 00:00:00.000000' 错误
- 5Flink-输出算子(Sink)使用_richsinkfunction
- 6记录:java.lang.Integer cannot be cast to java.lang.Long...【解决方案】
- 7IDER软件git使用技巧_ider根据git无法从远处数据库读取用http可以
- 8<长篇文章!!>数据结构与算法的重要知识点与概要总结 ( •̀ ω •́ )✧✧临近考试和查漏补缺的小伙伴看这一篇就都懂啦~_数据结构与算法的知识点
- 9TensorRT部署总结(一)
- 10深入掌握以太坊核心技术_mastering ethereum
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation论文阅读_c++系统调试
赞
踩
1. 代码地址
2. 动机
本篇文章旨在将点云语义分割的复杂模型中的知识蒸馏到较轻量级的模型中。具体的实现方式为将原有的3D backbone网络的每一层进行裁剪,对每一层只保留原有通道数的一半,通过自监督蒸馏学习的方式,使得裁剪后的小模型依然能够达到原有的模型效果,提升模型的运行速度,更好地满足例如自动驾驶车辆的硬件限制。
3. 贡献
由于点云数据的特殊性和局限性(例如离散性、无序性、密度不均匀),直接将传统的蒸馏方法应用到点云语义分割上很难取得好的效果,所以本文提出了一个新的知识蒸馏方法PVD,该模型在点(point)和体素(voxel)两种数据格式上将teacher中的隐藏知识蒸馏到student模型上
- 同时使用pointwise和voxelwise的输出蒸馏方式来弥补点云稀疏性上的缺陷。
- 为了更好地学习数据内的结构信息,提出超体素的概念,将点云数据划分为若干个超体素,利用超体素的空间知识,使模型学习点云的空间信息。
- 由于点云数据的不同区域在空间密度上有很大的差异,距离点云中心很远的物体的点数据具有很高的稀疏性,并且点云数据集内部的类别占比也并不均匀,如果在点云内进行均衡采样学习,模型会很难学到这些稀疏表示的物体和小样本物体的特征知识,致使模型的性能下降,所以在本文中提出了一个困难意识采样机制,该机制的作用是在生成超体素数据流时能够尽可能地倾向去选择稀疏表示的超体素或者包含小样本的超体素,使得模型能够更多地学习这些物体的特征,从而提升模型的性能。
- 在提出超体素之后,本篇文章利用超体素进行亲和度蒸馏,超体素内的点和体素的相似信息可以帮助模型更好地学习点云空间信息。并且已有的方法在训练模型学习点云空间信息时往往使用整个点云数据,这会消耗大量的计算资源其效率也不高,而在本文提出超体素概念后,便可以在超体素的规模下进行空间结构学习。
4. 网络结构图
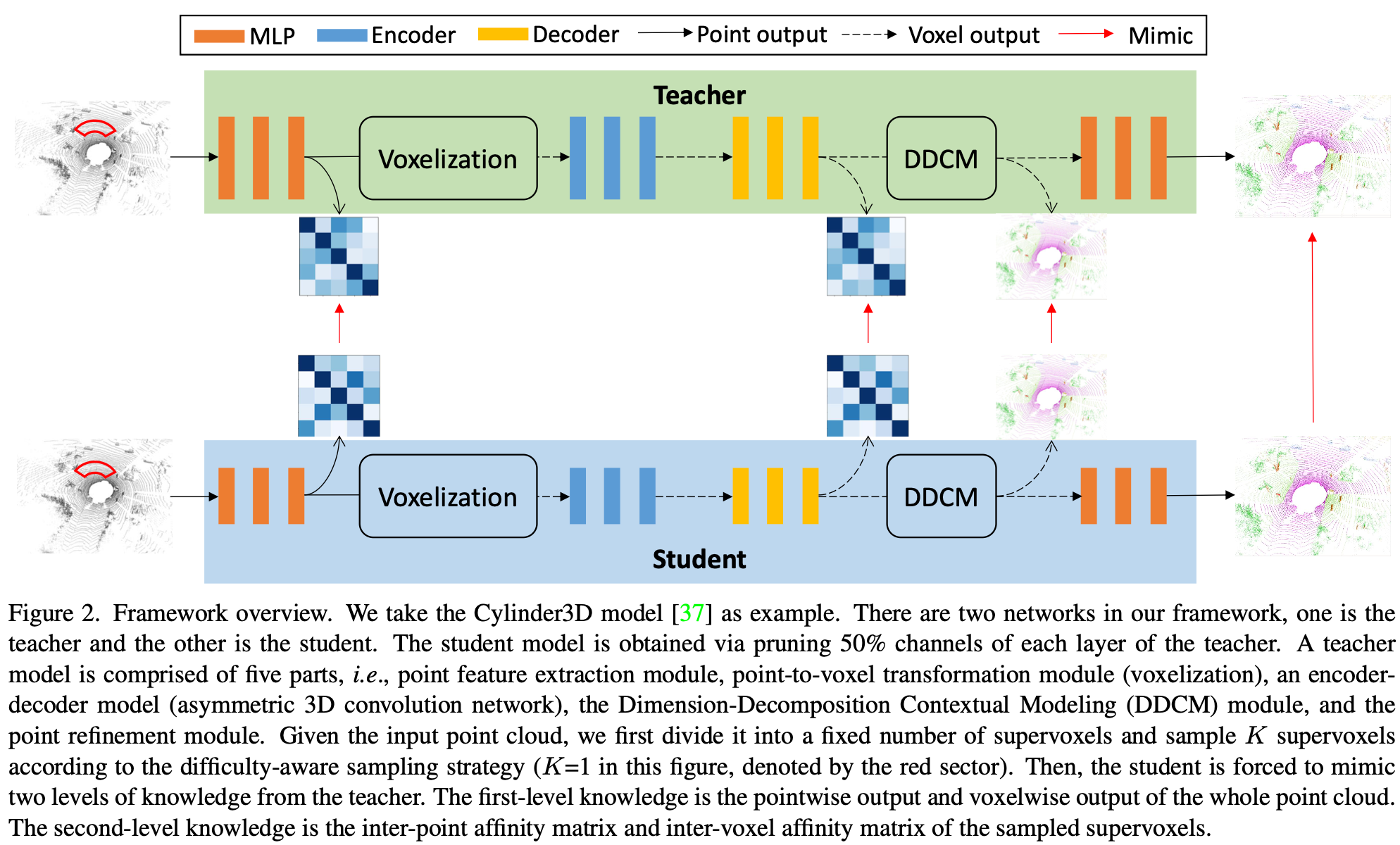
很容易注意到网络中的四个红色的箭头,这4个红色的箭头就代表着本文最重要的四个损失函数,首先看后面的两个损失,分别对应着体素和点的输出损失(KL散度),前面两个箭头代表着基于超体素而生成的超体素内部点亲和度和体素亲和度的2范数损失。下面说下网络结构,像介绍中所说,网络包含5个模块,第一个模块是多层感知机得到一个的特征图,在这个特征图上产生超体素内的point的亲和度蒸馏损失;第二个模块是体素化模块;第三个是3D卷积网络输出新的体素特征图,在这产生voxel的亲和度蒸馏损失;第四个模块是维度分解模块,该模块的作用是产生空间特征信息,将原本平面的信息转换成了包含半径、方位角、高度的空间特征信息,并在该模块后产生voxel的输出蒸馏损失;最后一个模块是由多层感知机组成的精炼模块用于产生pointwise 的类别输出,最后生成point的蒸馏损失
体素和点的输出损失公式如下,point的损失很好理解,这里的voxel的损失与传统的不同,它包含了半径、方位角、高度和类别通道的信息
本文的核心还是在空间结构信息的学习,也就是超体素内的亲和度蒸馏:
4.1. 超像素的划分
将点云数据体素化后,对得到体素点云进行超体素划分,每个超体素大小为Rs x As x Hs.
4.2. 困难意识采样机制
为了能够更多地选择特殊的区域(小样本的区域、稀疏区域等),本文设计了一个困难意识采样机制使得模型在选择超体素进行模型蒸馏训练时,能够更多地选择这些特殊区域的超体素从而提高模型的性能。在点云中为每一个超体素赋权重,其权重计算方式如下:
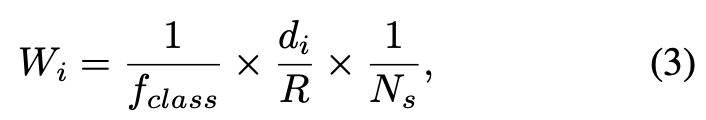
这里的是超体素到点云中心的距离,R是半径,
是超体素内体素的数量
![]()
是指包含小样本的体素数量
4.3. 点/体素特征处理

 为了保持计算的一致性(点云的不同区域和不同的点云会造成超体素内部点数量和体素数量不均衡),首先在超体素内选取
为了保持计算的一致性(点云的不同区域和不同的点云会造成超体素内部点数量和体素数量不均衡),首先在超体素内选取个点和
个体素,多出的从点数量较多的类别中删去,少的则直接补0特征向量。计算超体素内的亲和矩阵,以point为例,voxel的与之类似:

基于超体素内的亲和矩阵进行空间结构信息蒸馏,损失如下:
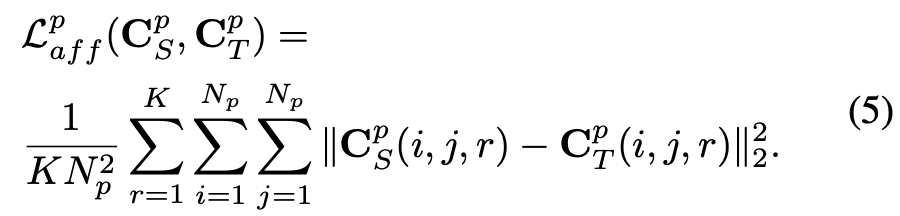 最终的优化目标
最终的优化目标

后面4个损失在前文已经介绍了,最前面两个损失分别是基于点的和基于体素的加权交叉熵损失,其是为了保证类别多样性,防止有的类别为空。lovasz损失是语义分割中十分常见的损失,其与普通的交叉熵损失相比会注重类别的不均衡性,在优化MIOU指标上会比普通的交叉熵损失更有效果
参考文献
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation 论文阅读CVPR2022-CSDN博客

