
- 1Linux —— 信号量
- 2贵州省关于做好2024年职称工作有关事项的通知
- 3蚁剑连接不上远程shell的解决办法_蚁剑添加数据成功但连接不上
- 4五年十届WAVE SUMMIT,飞桨汇聚1070万AI开发者,星河社区全要素升级
- 5云原生监控——VictoriaMetrics_vmstorage
- 6FPGA 学习之路_verilog hdl程序设计与实践 xilinx大学计划pdf
- 7探索【Stable-Diffusion WEBUI】的插件:界面主题与中文翻译_stable diffusion 主题
- 8智能电销机器人《各版本机器人部署》_ai电销电话机器人php源码搭建部署(2022完整可用包安装使用
- 9Anaconda中安装cv2包详细教程_conda安装cv2
- 10云原生监控体系建设
基于FPGA的数字图像处理【2.5】_两个图像像素点对齐 行对齐 列对齐
赞
踩
2.利用行缓存实现图像行列对齐
行缓存最常见的应用之一是实现行列对齐,实际上,对于二维的图像处理来说,图像的行列对齐是时序对齐的关键步骤,读者阅读本书的后面章节就会发现,相当一部分的图像处理算法涉及图像的行列对齐操作(这是由于算法需要对图像进行开窗的缘故)。本节将以行缓存为基础给出图像行列对齐的一个方法。
行列对齐的关键点是同时得到若干行像素数据,这可以理解为行对齐。同时每行的第一个像素实现对齐,这也是列对齐。行对齐可以通过上面介绍的行缓存来实现,列对齐可以通过合理控制各个行缓存的读出时刻来实现。实际上,我们在上面介绍行缓存实例的时候,已经给出了一个行缓存的应用电路:行缓存的设计原则是保证流水线的通畅。
对于多行图像的对齐,一个简单的方法就是将行缓存连接成菊花链式,即将前一个行缓存的输出接入下一个行缓存的输入(实现一个n行图像的对齐需要n-1个行缓存),如图4-27所示。
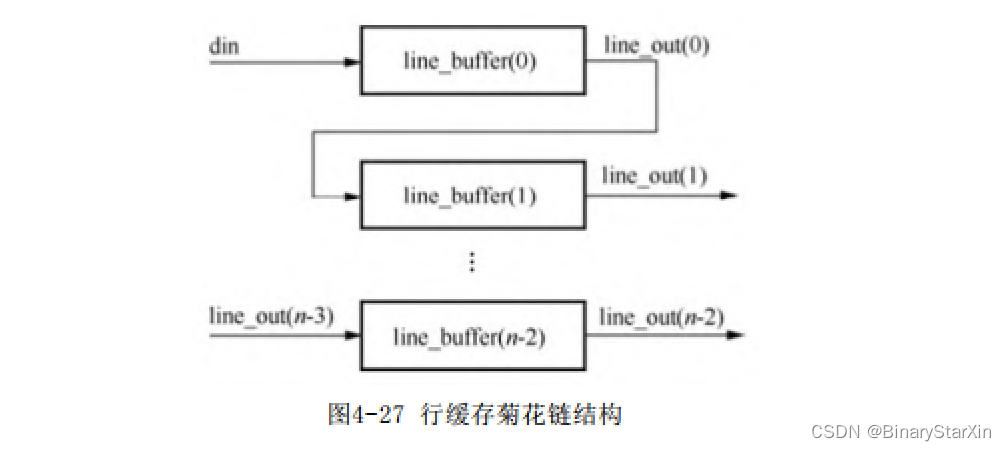
在图 4-27 中,din,line_out(0),line_out(1)…line_out(n-2)即为待对齐的n行图像数据。
下一个问题是行缓存的读出与写入时刻。我们在前面已经讨论过行缓存的读出时刻:为了不破坏流水线的流通性,每个行缓存需要在装满一整行图像后开始读出,直到所有的行缓存装满后流水线开始流通。
第一个行缓存line_buffer(0)的写入时刻显然是输入数据din的有效时刻。其他的行缓存的写入时刻发生在上一个行缓存的读出时刻。这样就可以保证:在流水线开始工作的第一个时刻,line_out(n-2)输出的是第一行的第一个像素,line_out(n-1)输出的是第二行的第一个像素,line_out(0)输出的是第(n-1)行的第一个像素,din输出的是第n行的第一个像素,由此完成了行列方向上的时序对齐。
- Verilog示例代码如下:
- generate
- begin : xhdl1
- genvar i;
- for (i = 0; i <= n- 2; i = i + 1)/*共n-1个行缓存*/begin : buffer _inst
- //第一个行缓存
- if (i == 0)
- begin : MAP12
- //输入数据接入第一个行缓存
- always @(*) line_din[i]<= din;
- //输入数据有效时将数据写入第一个行缓存
- always @(valid)
- line_wren[i]<= valid;
- end
- //其余的行缓存,接成菊花链形式
- if ((~(i == 0)))
- begin : MAP13
- always @(posedge clk)
- begin
- if (rst_all == 1'b1)
- begin
- line_wren[i]<= 1'b0;
- line_din[i]<= {DW{1'b0}};
- end
- else
- begin
- //上一个缓存读出时,本缓存写入
- line_wren[i]<= #1 line_rden[i - 1];
- //本缓存写入的数据为上个缓存的输出
- line_din[i]<= line_dout[i - 1];
- endend
- end
- //本缓存的读出时刻为当前缓存装满且输入有效的时刻
- assign line_rden[i]= buf_pop_en[i]& valid ;
- //对缓存内的数据进行计数,装满一行后允许打出
- always @(posedge clk)
- begin
- if (rst_all == 1'b1)//新的一帧到来时复位
- buf_pop_en[i]<= #1 1'b0;
- else if (line_count[i]== IW)// 数 据 装 满 一 行
- Image Width
- buf_pop_en[i]<= #1 1'b1;
- end
- //例化当前行缓存
- line_buffer #(DW,IW)
- line_buf_inst(
- .rst(rst_all),
- .clk(clk),
- .din(line_din[i]),
- .dout(line_dout[i]),
- .wr_en(line_wren[i]),
- .rd_en(line_rden[i]),
- .empty(line_empty[i]),
- .full(line_full[i]),
- .count(line_count[i])
- );
- endend
- endgenerate

以上的代码并未考虑流水线卸载的过程,流水线的卸载发生在当前输入图像帧结束之后,流水线没有新的数据输入。在接下来的若干行时间段内,流水线处于卸载状态。卸载的一个目的是保持输入和输出数据的带宽平衡:在流水线装载阶段输出处于停滞状态(边界信息除外)。
为了说明这个问题,以3×3的图像对齐为例来进行说明;要完成3行图像的对齐要例化两个行缓存,如图4-28所示。
在输入行结束之后line_buffer(0)不再有数据输入,即din数据无效。这个时候line_buffer(0)和line_buffer(1)里面正好存有两整行图像数据(最后两行图像数据)。若需要对这两行图像进行卸载,则这个过程称为卸载过程。在介绍流水线原理的时候也提到,实际应用时多数情况下不会对着两行数据进行卸载,因为这两行数据往往不够最少的处理单元(3×3的窗口处理需要最少3行图像),普遍的做法是将其搁置不管,并将最后一行输出数据置0(当然也有其他的边界处理方法,有兴趣的读者可以查阅相关文献)。
这个边界行也称为溢出行(flush_line),溢出行是完成输入/输出带宽匹配的必要行。
在介绍行列对齐的过程中多次提到图像的边界,图像的边界是图像处于处理边界的像素。设定radius为图像处理算法的半径,则边界像素为图像边界宽度为radius的外环,如图4-29所示。

外框为输入图像,左上角的小方框即为处理核core,处理核从图4-29所示位置出发一直移动到图像的右下角即完成整幅图像的处理。图中矩形框的“外环”(图中阴影部分)即为图像的边界。很明显,这些边缘像素包括以下几种:
(1)行数在处理半径以内的。
(2)列数在处理半径以内的。
(3)行数在图像宽度-处理半径之内的。
(4)列数在图像高度-处理半径之内的。
当然,这些都是针对输出行列计数而言。
//行列计数及边界判决实例代码如下:
- always @(posedge clk)
- begin
- if (rst_all == 1'b1)
- in_line_cnt <= #1 {11{1'b0}};
- else if (((~(valid))) == 1'b1 & valid_r == 1'b1)
- in_line_cnt <= #1 in_line_cnt +
- 11'b00000000001;//输入行计数
- end
- //溢出行计数
- always @(posedge clk)
- begin
- if (rst_all == 1'b1)
- begin
- flush_line <= #1 1'b0;
- flush_cnt <= #1 {16{1'b0}};
- end
- else
- begin
- if (flush_cnt >= ((IW - 1)))
- flush_cnt <= #1 {16{1'b0}};
- else if (flush_line == 1'b1)
- flush_cnt <= #1 flush_cnt +
- 16'b0000000000000001;if (flush_cnt >= ((IW - 1)))
- flush_line <= #1 1'b0;
- else if (in_line_cnt >= IH & out_line_cnt <
- ((IH - 1)))
- flush_line <= #1 1'b1;
- end
- end
- //输出行计数和输出像素计数
- always @(posedge clk)
- begin
- if (rst_all == 1'b1)
- begin
- out_pixel_cnt <= #1 {16{1'b0}};
- out_line_cnt <= #1 {11{1'b0}};
- end
- else
- begin
- if(dout_valid_temp_r==1'b1&(( ~
- (dout_valid_temp)))==1'b1)
- out_line_cnt <= #1 out_line_cnt +
- 11'b00000000001;
- else
- out_line_cnt <= #1 out_line_cnt;
- if(dout_valid_temp_r==1'b1&(( ~
- (dout_valid_temp)))==1'b1)
- out_pixel_cnt <= #1 {16{1'b0}};
- else if (dout_valid_temp == 1'b1)out_pixel_cnt <= #1 out_pixel_cnt +
- 16'b0000000000000001;
- end
- end
- //边界判决
- assign is_boarder = (((dout_valid_temp == 1'b1) &
- (out_pixel_cnt <=((radius - 1)) | out_pixel_cnt >= ((IW -
- radius)) | out_line_cnt <= ((radius- 1)) | out_line_cnt >=
- ((IH - radius))))) ? 1'b1 : 1'b0;
4.3.3 异步缓存
异步缓存主要应用在跨时钟的场合。对于一些设计,在不同的部分使用不同的时钟是不可避免的。这个问题主要出现在视频输入、视频输出及与外部的异步接口等场合。
一般来说,外部的视频输入数据流都会附带一个视频流的参考时钟,而这个时钟与本地逻辑时钟是异步的。同时,处理完的视频流要进行显示,显示驱动电路的时钟与本地系统时钟往往也是不同的。系统与外部的一些异步接口,例如异步存储器等,都是跨时钟域的场合(我们将在时序约束的章节讨论异步时钟域的设计问题)。
异步时钟带来的一个问题就是有效的读写速率不一致。一般情况下,这种场合是读取速度要小于写入速度。解决异步时钟的一个方法就是建立异步缓存器,用一个异步FIFO即可实现。
设计异步缓存时的基本原则是防止缓存上溢(overflow)和下溢(underflow)。增加FIFO的深度可以有效解决溢出问题,但这往往会增加存储器的资源消耗。而有的时候,缓存必须要设置地很大才能解决问题,或是由于系统设计的不合理,导致无法对读写速率进行有效匹配。实际上,在设计时我们会根据实际的读写速率事先对缓存所需要的深度做一个预估。
在对异步FIFO的深度进行估算时要考虑到最坏的情况,也就是读写速率差别最大的时候。一般情况下,用以下公式来计算FIFO深度。

实际应用时,也可以通过实际测试确定FIFO的深度。
4.3.4 增加存储器带宽
在实际应用中,经常会遇到存储器带宽不够的情况。例如由于成本限制,外部的一个存储器最多只能存放一张完整的图像,而我们又需要至少两个帧缓存。这种情况下,存储器的带宽就成为了设计瓶颈,必须想办法增加存储器的带宽。
1.增加存储器个数
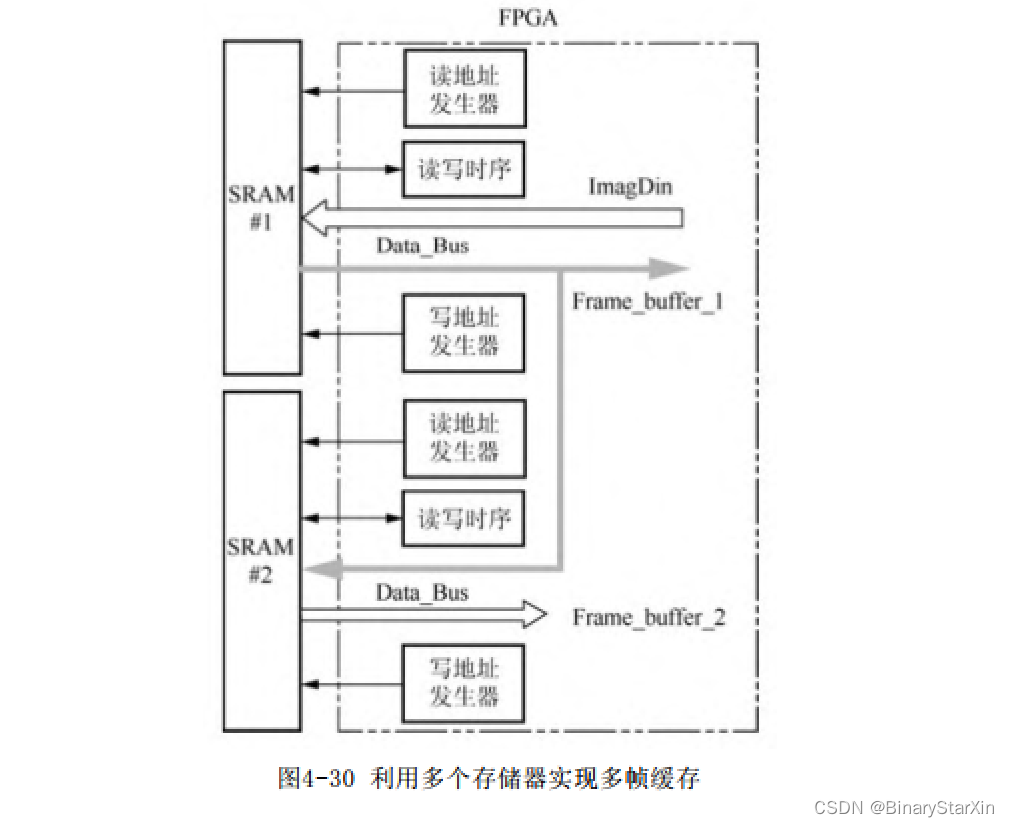
增加多个并行的存储器系统是增加存储器带宽的最简单的方法。如果每个存储器都有独立的地址和数据总线连接到FPGA,那么每个存储器都可以独立并行地与FPGA进行数据交互。虽然对于片外存储器来说,这不是最高效的存储结构,但是也是最简单可靠的实现方式。考虑以下情况:实现连续3帧图像的均值运算,图4-30所示的电路可以保存若干个图像帧缓存,只要这些图像的总大小不会超过SRAM的容量。但是,如果要利用当前电路实现流水操作,那么上述存储器系统只能
实现连续两帧数据的流水运算。而如图4-30所示的存储器系统,通过增加一个物理存储器,可同时得到连续3帧的图像数据,实现连续三帧的流水运算。
2.增加存储器字宽
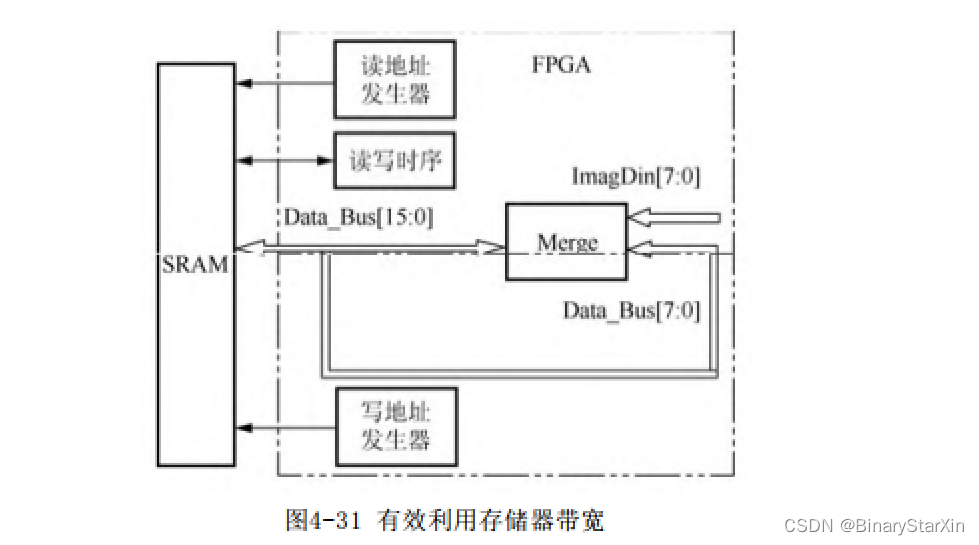
进一步增加存储器带宽的方法是增加其字宽。这样一来,每次对存储器的访问可以同时读写多个像素。这样做的效果等同于并行地连接多个存储器,但是存储器被划分为了多个分区。与多个物理存储器不同的是,这些分区共享相同的地址线,只是在数据线上进行区分。在像素数据的读取和写入方面,比单纯的多个物理存储器复杂。
这是基于以下考虑:要将多个像素进行合并写入存储器,并在读取后将像素数据从总线上解出。以8位的数据存入16位的存储器为例,系统结构如图4-31所示。
3.使用多端口存储器
使用多端口存储器并不能“真正意义”上地提高存储器的带宽,实际上,存储器的位宽和大小均没有发生变化。但是多端口存储器提供了多个存取接口,也就是多个数据总线和地址总线。多个端口可以同时提供读写功能,理论上将带宽提升了一倍。但是也要注意,需要小心处理访问冲突问题。
还有一种方法是将存储器划分为不同的地址区间,多个端口可以同时访问不同的地址分区,这在一定程度上可以简化设计。对于连续3帧的流水运算,可以将第一帧数据放在上半区,第二帧数据存放在下半区来实现连续两帧的缓存。但是通常情况下不会这么做,这是因为如果存储器可以存得下两幅图片,那么通过简单的逻辑即可实现单口存储,而双口RAM的成本比单口RAM高得多。
双口RAM的一个典型应用是完成双边主机的通信,例如DSP与FPGA协作系统中,完成DSP与FPGA的数据交互。
4.提高时钟速率
将存储器以一个与系统其他部分更高的速度运行,可以允许在一个系统时钟内对存储器进行两次或多次访问。存储器应该和时钟同步,这样能避免同步问题。双倍数据速率(DDR)存储器就是这样的一种存储器。它能在时钟的上升沿和下降沿各传送一次数据,即每个时钟周期传送两次数据。对于时钟速度较低或者具有高速存储器的系统来说,使用一个较高频率的RAM时钟才是可行的。
此外,当数据每隔几个时钟进入到流水线处理时,整个设计都能以较高的时钟速率运行。这种方法称为“多阶段”设计,时钟周期的数目或阶段与像素时钟有关。多阶段设计不仅增加了带宽,而且在不同阶段重复使用硬件而减少了计算硬件。
4.3.5 存储器建模与仿真
对于外部存储器的建模与仿真对于整个系统的稳定性至关重要。一般情况下,客户很少对所用到的存储器进行建模,存储器的仿真模型一般情况下可以通过存储器的生产厂家或者第三方(如专门进行仿真模型建立的组织Free Model Foundry或是Altera,Xilinx等FPGA厂家)得到。

