
- 1实战:win10安装docker并用docker-compose构建运行容器_windows docker compose
- 2《python语言程序设计》课后练习答案部分-北京理工大学_python语言程序设计基础教程答案
- 3智慧轨道交通运维监控解决方案_地铁mcc自动化运维服务报价方案
- 4程序员跳槽时,如何高效地准备面试?
- 5hadoop修改配置文件和环境变量_hadoop命令环境变量export配置_hadoop修改配置文件yarn-site.xml文件
- 6h5(html5)+css3+移动端前端_h5+
- 7基于微信小程序的毕业设计题目(3)php评选投票小程序(含开题报告、任务书、中期报告、答辩PPT、论文模板)_投票微信小程序用户验收报告模板
- 8android RadioButton自定义图片样式_安卓radiobutton增加图片
- 9SpringSecurity整合JWT_spring security3.1.1
- 10nginx升级,添加ssl模块_--with-http-stub
(非常详细)大数据平台学习·环境安装配置(二)(Hadoop3.2.4版集群搭建)_windows安装hadoop3.2.4
赞
踩
一.文章简介
上一篇文章我们着手搭建了大数据平台所需要的虚拟机环境,那么接下来我们来搭建hadoop环境。
文章目录
- 一.文章简介
- 二.资源准备
- 三.Haddop下载教程
- 四.jdk下载教程
- 五.Hadoop 集群的安装和环境配置要求
- 六.启动Hadoop和检测
- 七.关闭集群
二.资源准备
Hadoop:3.2.4版本
Hadoop官方下载地址
jdk:1.8.0 linux版本
jdk1.8官方下载地址
三.Haddop下载教程
1.进入官方下载链接后,选择binary下载
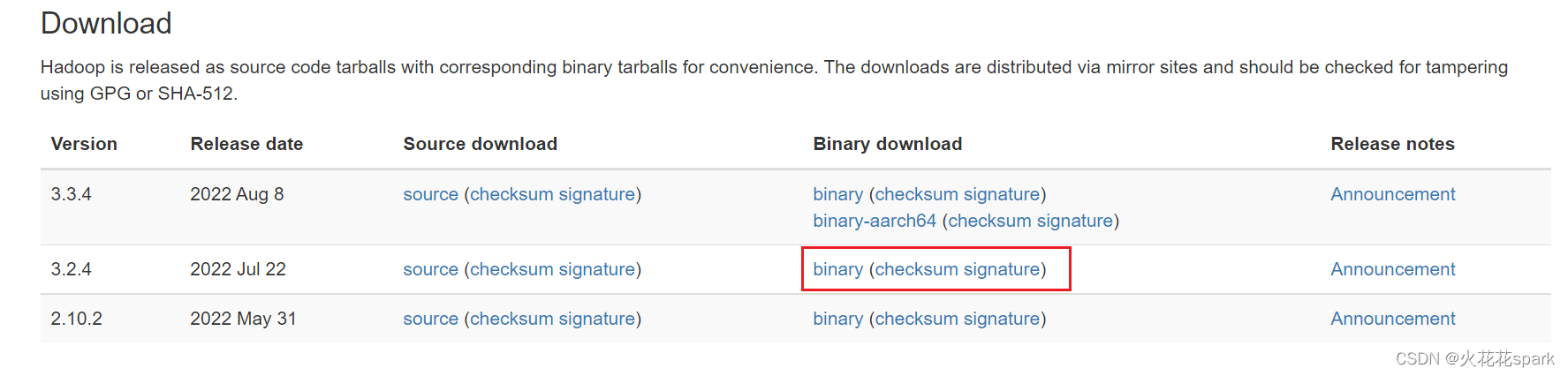
注意:不要下载source版,source版是源码下载,用于研究源码或者maven构建编译打包的。我们现选择binary版,可以直接下载后解压配置文件使用的。
如果需要其他Hadoop版本的,进入下方的官方收录版本库里寻找自己想要的版本
Hadoop官方历史版本下载
2.下载后存放到本地中
建立一个专门用于存放Hadoop压缩包和解压后的Hadoop文件

3.传输到master主节点上
(1)在master主节点和其他三台机子都建立对应的目录用于存放和安装软件
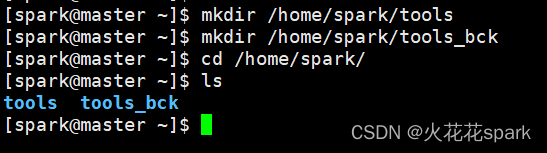
注意一定要在home目录下的对应大数据专用用户下存放和安装
tools目录用于安装后、tools_bck用于存放压缩包等
(2) 使用xftp将Hadoop压缩包传输至master主节点的tools_bck中

四.jdk下载教程
1.进入官方下载连接后,选择linux版本下载
注意:官方下载需要登录oracle账户,而且部分时候容易连接失败

2.下载后存放到本地

3.传输到master主节点和其他三个从节点上
利用xftp,将jdk传输到所有机子的/home/spark/tools_bck目录

4.解压安装jdk
命令:tar -zxf jdk-8u351-linux-x64.tar.gz -C /home/spark/tools
5.配置环境
在~/.bashrc 文件末尾加上如下的三行代码:
#set java environment
export JAVA_HOME=/home/spark/tools/jdk1.8.0_351
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
- 1
- 2
- 3
- 4
然后运行source ~/.bashrc 让环境变量生效,输入java -version检测配置

五.Hadoop 集群的安装和环境配置要求
1.各节点分配
| 主机名 | 主机IP | 作用 |
|---|---|---|
| master | 192.168.xxx.140 | Namenode;SecondaryNamenode;ResourceManager;JobHistoryServer |
| slaver1 | 192.168.xxx.141 | Datanode; NodeManger |
| slaver2 | 192.168.xxx.142 | Datanode; NodeManger |
| slaver3 | 192.168.xxx.143 | Datanode; NodeManger |
2.在master主节点解压Hadoop安装包
命令:tar -zxf hadoop-3.2.4.tar.gz -C /home/spark/tools

3.配置Hadoop环境变量,方便使用Haoop命令
命令:vim ~./bashrc
在最下面新增如下:
#set Hadoop environment
export HADOOP_HOME=/home/spark/tools/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 1
- 2
- 3
输入source ~/.bashrc 让环境变量生效,输入hadoop version检测配置

注意:如果此时输入hadoop version 是报错的,可能是还没有配置jdk环境,请返回上面配置好
4.在主节点配置 hadoop-env.sh,加入JDK的位置环境变量
命令1:cd /home/spark/tools/hadoop-3.2.4/etc/hadoop
命令2:vim hadoop-env.sh
新增如下代码
export JAVA_HOME=/home/spark/tools/jdk1.8.0_351
- 1

5.在主节点配置 core-site.xml 文件
命令2:vim core-site.xml
新增如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/spark/tools/hadoop-3.2.4/tmp</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6.在主节点配置 hdfs-site.xml 文件(注:复制因子是 3)
(1)先在/home/cspark/tools/hadoop-3.2.4/下创建目录 tmp

(2)配置 hdfs-site.xml 文件
命令:vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/spark/tools/hadoop-3.2.4/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/spark/tools/hadoop-3.2.4/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
7.在主节点配置 mapred-site.xml 文件
命令:vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
8.在主节点配置 yarn-site.xml 文件
命令:vim yarn-site.xml
<!-- Site specific YARN configuration properties -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
9.在主节点配置 yarn-env.sh 文件
命令:vim yarn-env.sh
###
#set some java parameters
export JAVA_HOME=/home/spark/tools/jdk1.8.0_351
- 1
- 2
- 3
10.在主节点配置workers文件
命令:vim workers
删掉原有的,改为如下:

11.向各节点复制Hadoop
依次输入命令:
scp -r /home/spark/tools/hadoop-3.2.4 slaver1:/home/spark/tools
scp -r /home/spark/tools/hadoop-3.2.4 slaver2:/home/spark/tools
scp -r /home/spark/tools/hadoop-3.2.4 slaver3:/home/spark/tools
12.格式化namenode
需要在Hadoop 安装目录下的 bin 目录里的 hdfs 命令进行格式化
即:/home/spark/tools/hadoop-3.2.4/bin
命令:./hdfs namenode -format
六.启动Hadoop和检测
1.启动Hadoop集群
以下命令需要在/home/spark/tools/hadoop-3.2.4/sbin中进行
命令1:./start-dfs.sh(HDFS 集群)
命令2:./start-yarn.sh(Yarn 集群)
命令3:./mr-jobhistory-daemon.sh start historyserver(日志服务)
输入后利用jps对主节点和从节点检查
主节点
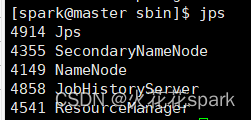
从节点

2.配置本地主机系统映射
在 Windows 系统中设置 IP 映射
对hosts新增如下

3.进入web界面查看监控
http://master:9870(查看 HDFS 集群监控)
http://master:8088(查看 YARN 集群监控)
七.关闭集群
同样需要在sbin目录下进行
命令1:./stop-dfs.sh(HDFS 集群)
命令2:./stop-yarn.sh(Yarn 集群)
命令3:./mr-jobhistory-daemon.sh stop historyserver(日志服务
好了,到这里我们的Hadoop集群就已经搭建好了,如果有错误的地方,欢迎各位指出哈

