
- 1web前端如何才能成为架构师_只会前端能做前端架构吗
- 2ISE约束文件UCF与Vivado约束文件XDC FPGA_ise约束文件格式
- 3图形学初识--空间变换
- 4补盲激光雷达大爆发,各路产品谁领风骚?_一径ml30s用户手册
- 5使用MD5当做文件的唯一标识,这样安全么?_文件唯一标识md5
- 6Fooocus 使用笔记
- 71688商品详情API接口(标题|主图|SKU|价格|一件代发|库存..)_1688代发接口
- 8git连接远程仓库出现:ssh: connect to host github.com port 22: Connection refused
- 9C#学习笔记二 (资源托管,泛型,数组和元组,运算符和类型强制转换)
- 10postgresql和postgrest安装及使用
大数据毕业设计hive+spark知识图谱图书推荐系统 豆瓣图书数据分析可视化大屏 豆瓣图书爬虫 图书大数据 机器学习 计算机毕业设计 深度学习 人工智能 数据可视化_spark 为底层的基于 k-means 算法的个性化图书推荐系统
赞
踩
基于Spark个性化书籍推荐系统
系统用到的各项技术和工具的介绍:
1. Python编程语言
Python是一种流行的高级编程语言,因其简单易学、清晰明了、开发效率高等特点,被广泛应用于机器学习、科学计算、Web开发、数据处理等领域。在该系统中,Python被用于实现数据抓取、推荐算法、Web应用程序等方面。
2. PySpark
PySpark是基于Python的Apache Spark API,Spark是一种快速大规模数据处理引擎,能够进行高速批处理和交互式查询,具有高可靠性和容错性,还可以支持各种数据源和格式。在该系统中,PySpark被用于数据分析和处理。
3. Hadoop
Hadoop是一个开源的大数据处理框架,能够处理和存储大量的分布式数据,并提供了高可靠性和容错性。Hadoop主要由HDFS和MapReduce组成,HDFS用于数据存储,而MapReduce则用于数据计算。在该系统中,Hadoop被用于大规模数据存储和处理。
4. Django Web框架
Django是一个基于Python的Web框架,可以帮助开发者快速构建高质量、可扩展的Web应用程序,具有诸如自带ORM、自动管理Web请求等优点。在该系统中,Django被用于实现用户模块、图书分类模块、图书查询模块和后台管理模块等。
5. Scrapy框架
Scrapy是一个Python编写的Web爬虫框架,可用于快速地爬取网站数据并进行数据处理。该框架提供了强大的页面解析能力和异步网络请求支持,适用于大规模数据抓取场景。在该系统中,Scrapy被用于实现数据抓取模块。
6. Vue.js
Vue.js 是一款流行的渐进式 JavaScript 框架,用于构建用户界面。它具有易用性、高效率等特点,被广泛应用于前端开发领域。在该系统中,Vue.js被用于构建前端界面。
7. Element Plus
Element Plus是基于Vue.js的UI框架,提供了丰富的UI组件、特效和交互。该框架具有可定制性、易用性和高性能等特点,适用于各种Web应用程序的构建。在该系统中,Element Plus被用于构建前端界面。
8. 协同过滤算法
协同过滤算法是一种基于相似度的推荐算法,能够通过用户历史行为数据来预测用户对未看过的物品的喜好程度,从而完成推荐。在该系统中,协同过滤算法被用于实现图书推荐模块。
该系统各个模块的实现细节:
1. 数据抓取模块实现
该模块使用Scrapy框架实现了对“豆瓣读书”网站上的图书数据的抓取。具体步骤如下:
- 分析目标网站:分析“豆瓣读书”网站的网页结构、URL链接等信息,确定需要抓取的数据。
- 定义爬虫:在Scrapy中定义Spider,包括指定起始URL、定义爬取规则和数据处理方法等。
- 解析页面:使用XPath或CSS Selector对HTML页面进行解析,提取出需要的数据,如书名、作者、评分等。
- 存储数据:将解析得到的数据存储到数据库中。
2. 用户模块实现
该模块实现了以下功能:
- 用户注册:用户可以通过注册页面填写用户名、密码、邮箱等信息进行注册,注册信息将被保存到数据库中。
- 用户登录:用户可以通过登录页面输入用户名和密码进行登录,系统会检查数据库中是否存在该用户,并验证账号密码是否正确。
3. 图书分类模块实现
该模块用于展示图书分类,并提供了分类查询功能。具体步骤如下:
- 提取分类信息:从数据库中提取所有的图书分类信息,如小说、历史、传记等。
- 展示分类信息:将提取到的分类信息在前端页面进行展示。
- 分类查询:用户可以选择一个特定的分类,系统会根据用户选择的分类来查询该分类下的所有图书信息,并将查询的结果展示在前端页面中。
4. 图书查询模块实现
该模块用于根据书名、书籍分类、作者和ISBN等信息筛选图书,分页查询的功能。具体步骤如下:
- 定义图书模型:通过Django内置的ORM框架创建图书模型,该模型定义了图书的各种属性,包括书名、作者、ISBN、价格、出版社等。
- 接收查询条件:用户可以在前端页面输入查询条件,如书名、作者、分类等,系统接收到这些查询条件后,使用Django的QuerySet方法从数据库中查询满足条件的图书数据。
- 数据查询:根据用户输入的查询条件,使用Django的QuerySet方法从数据库中查询满足条件的图书数据。
- 分页展示:使用Django自带的Paginator组件对查询结果进行分页,将其展示在前端页面中。
5. 协同过滤推荐算法实现
该模块实现了基于用户的协同过滤和基于物品的协同过滤算法。具体步骤如下:
- 构建评分矩阵:将用户对图书的浏览评分构建成评分矩阵,使用矩阵运算进行相似度计算。
- 基于用户的协同过滤算法:根据用户之间的相似度,预测目标用户对图书的评分,并为用户推荐相似性高的图书。
- 基于物品的协同过滤算法:根据图书之间的相似度,为用户推荐相似度高的图书。
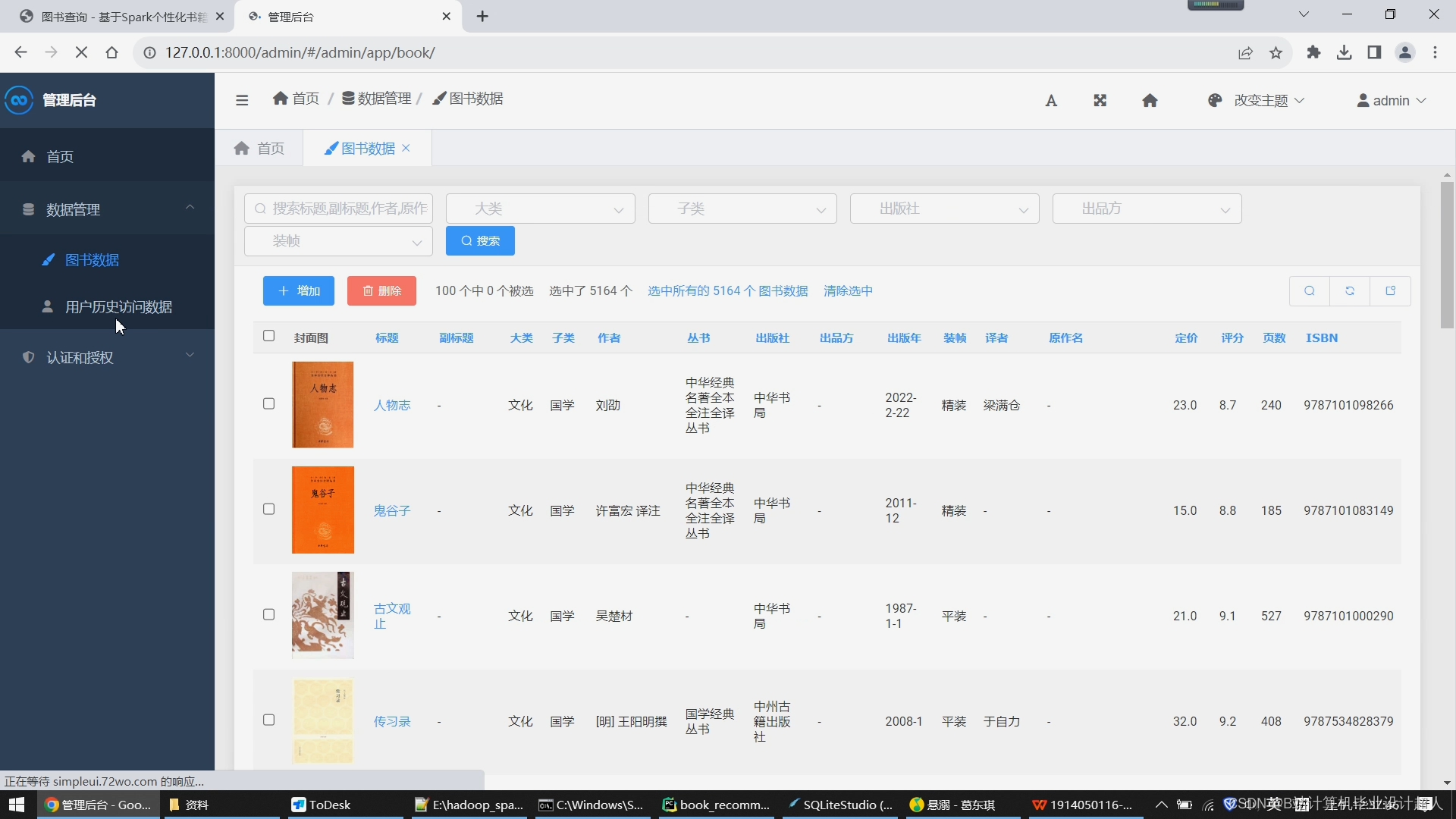
6. 后台管理模块实现
该模块提供了管理员对抓取到的图书数据进行管理的功能。具体步骤如下:
- 管理员登录:管理员输入用户名和密码,通过验证后进入后台管理系统。
- 数据管理:管理员可以查看和修改数据库中的图书信息,包括图书名称、作者、ISBN号、价格等。
技术及功能关键词:
python pyspark hadoop django scrapy vue element-plus 协同过滤算法
通过scrapy爬虫框架抓取“豆瓣读书”网站上的书籍数据
前台用户通过登陆注册后进入系统
管理员可在后台管理所有抓取到的图书数据
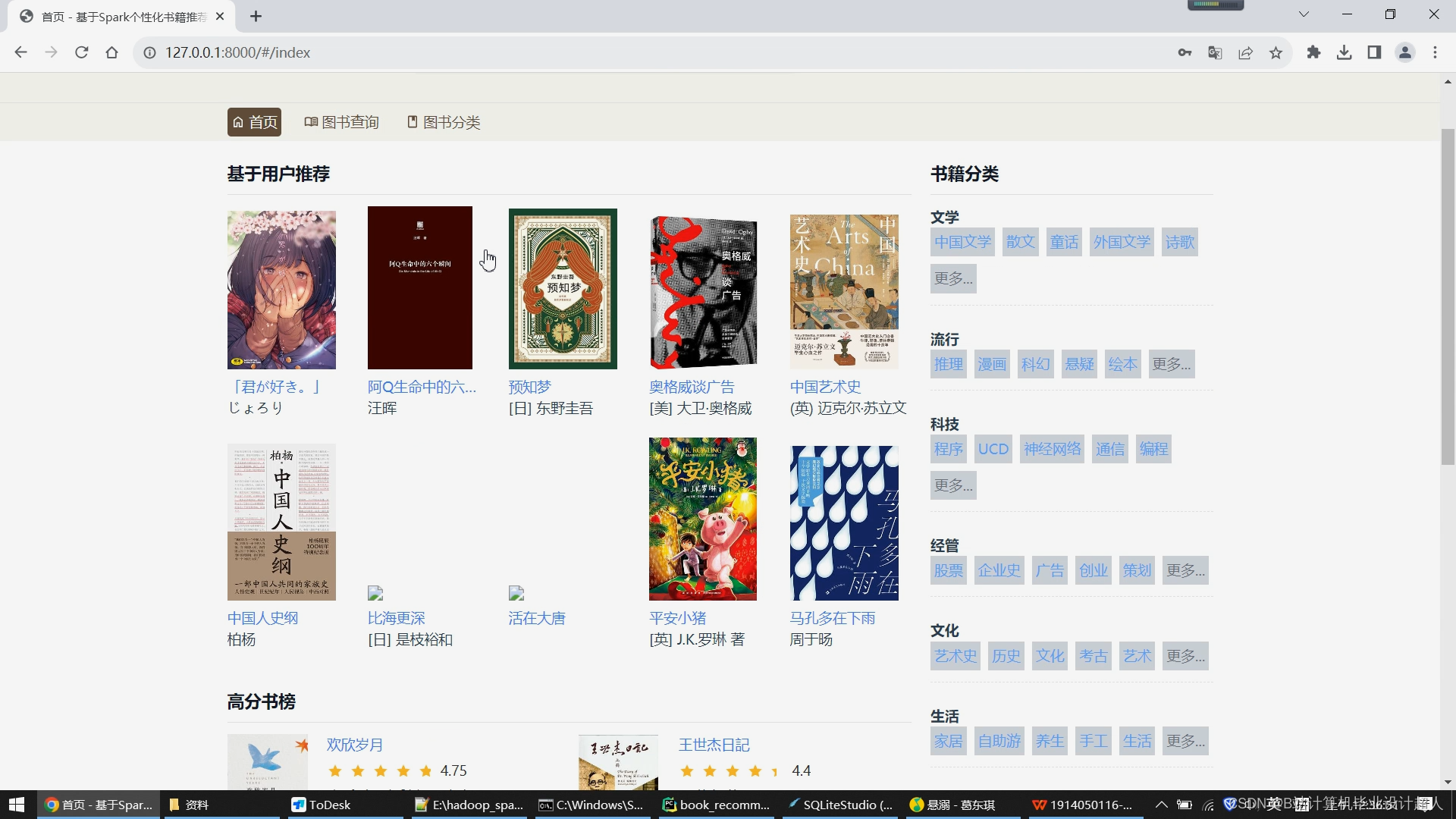
首页分为左右两侧,右侧展示所有图书的分类,比如文学、流行、科技、经管、文化、生活等大类,大类下亦有许多小类;左侧展示基于用户的协同过滤推荐算法给用户推荐的10个图书数据,下方是根据图书评分推荐的高分书榜
图书查询模块,可以根据书名、书籍分类、作者和ISBN等信息筛选图书,底部带有一个分页器,以10本书籍信息为一页实现分页查询,降低后端数据库的压力
图书分类模块,展示了所有图书的大类小类,用户可以通过点击某一分类,实现快速查找合适自己口味的图书信息
当用户访问某一书籍详情时,页面展示了图书的封面、作者、译者、出版社、出品方、类型、出版年、页数、装帧类型、ISBN等基本信息,还展示了图书的内容简介以及大纲等;在此页面的底部最后部分,我们向用户推荐了5本基于物品的协同过滤算法推荐的图书结果
目录结构(只关注标注了中文的):
├── app 图书数据后端最重要的模块!!!
│ ├── __init__.py
│ ├── admin.py 后台显示数据的配置
│ ├── apps.py 协同过滤算法代码!!!
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py 图书相关的数据库模型
│ ├── tests.py
│ ├── urls.py
│ └── views.py 图书相关所有重要的后端代码!!!!!
├── auth 用户登陆注册模块
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ └── views.py 登陆注册的代码!
├── book_recommend_system
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py 后端配置文件
│ ├── urls.py 路由配置文件
│ └── wsgi.py
├── db.sqlite3
├── dist
│ ├── assets
│ │ ├── detail.15fd66c8.js
│ │ ├── detail.36aa23b0.css
│ │ ├── detail.6b0150d6.js
│ │ ├── index.0b336648.css
│ │ ├── index.0ee13b90.css
│ │ ├── index.1a0a0bcd.js
│ │ ├── index.485fc076.js
│ │ ├── index.4c336a7c.js
│ │ ├── index.63bf9bc7.css
│ │ ├── index.6d5765b8.js
│ │ ├── index.79803d2c.js
│ │ ├── index.9860a311.js
│ │ ├── index.9877344b.js
│ │ ├── index.bd7b408d.js
│ │ ├── index.db570182.css
│ │ ├── login.248044ee.js
│ │ ├── login.5d7fb03b.js
│ │ ├── login.61bcbfce.css
│ │ ├── register.211ff2cd.css
│ │ ├── register.5042fb1f.js
│ │ └── register.c3ddecb6.js
│ └── index.html
├── fake.py
├── frontend
│ ├── README.md
│ ├── index.html
│ ├── package-lock.json
│ ├── package.json
│ ├── public
│ ├── src
│ │ ├── App.vue
│ │ ├── assets
│ │ ├── components
│ │ ├── directives
│ │ ├── layout_h
│ │ ├── layout_v
│ │ ├── main.js
│ │ ├── mixins
│ │ ├── router
│ │ ├── stores
│ │ ├── utils
│ │ └── views 前端源代码,前台所有页面的代码都在这!!!
│ └── vite.config.js
├── index
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ ├── utils.py
│ └── views.py
├── manage.py
├── middlewares
│ └── __init__.py
├── recommend.py
├── requirements.txt
├── scrapy.cfg
├── spider
│ ├── __init__.py
│ ├── extendsion
│ │ ├── __init__.py
│ │ └── selenium
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py 爬虫数据入库逻辑
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── book.py 爬虫代码!!!
└── 项目介绍.txt
28 directories, 83 files


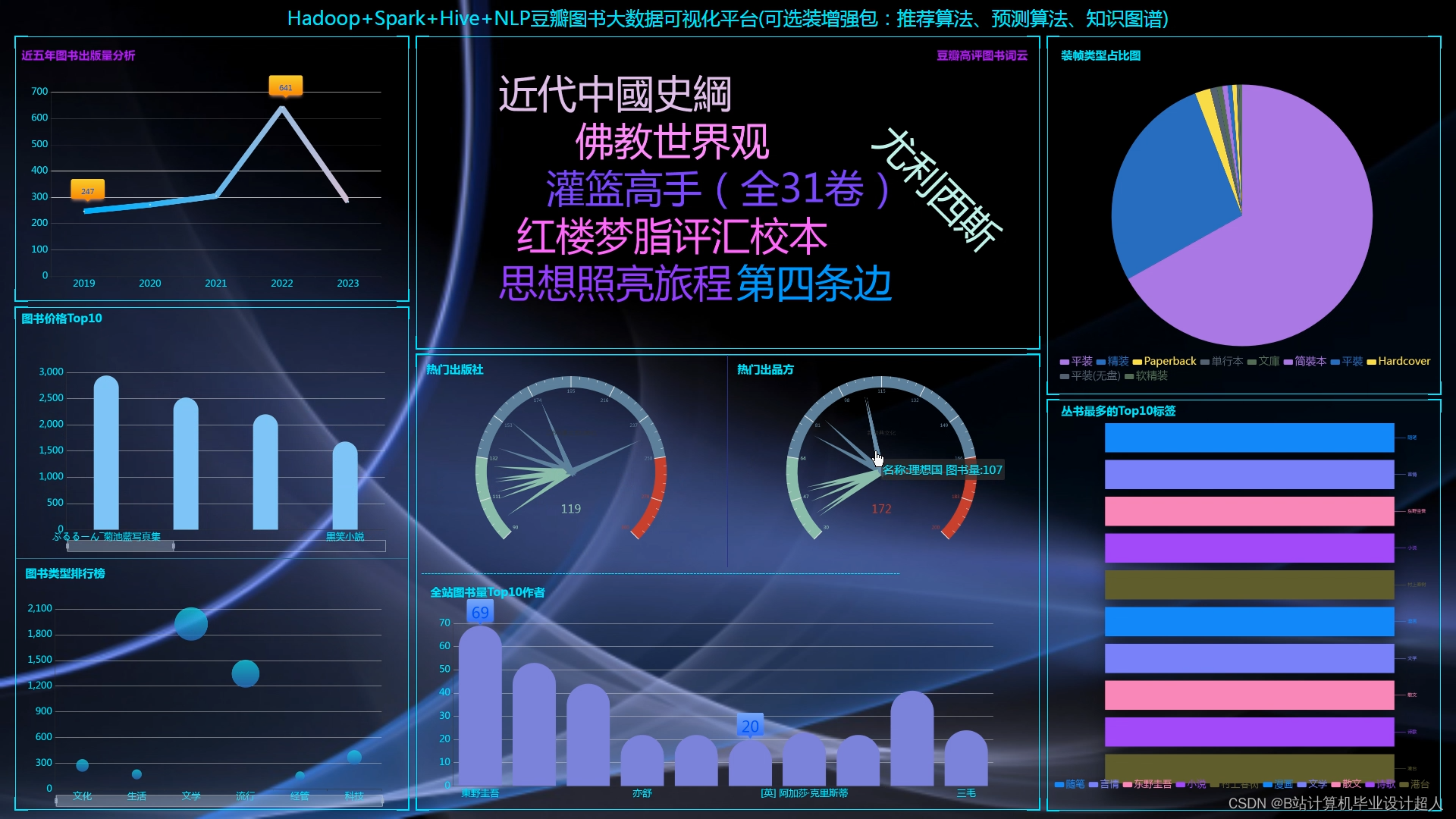
毕业设计工作内容:
本毕业设计拟使用Hadoop,Spark,协同过滤推荐算法等,开发一个书籍推荐系统,用于实现针对用户的书籍个性化推荐,实现查询书籍、个性化推荐推荐书籍等功能。具体工作内容为:
1.查阅相关资料和文献(2022.9.13-2022.10.15)
2.需求分析(2022.10.16-2022.10.31)
3.搭建开发环境,做好前期准备(2022.11.1-2022.11.15)
4.系统概要设计和详细设计(2022.11.16-2022.11.30)
5.进行算法研究以及数据集获取(2022.12.1-2022.12.15)
6.完成推荐算法编写(2022.12.16-2023.3.20)
7.完成前端开发(2023.3.21-2023.4.25)
8.系统测试与修改(2023.4.26-2023.5.15)
9.项目总结及论文撰写(2023.5.16-2023.6.20)

