
- 1动作/行为识别调研_动作识别
- 2华为OD机试 - 多段线数据压缩(Java & JS & Python & C & C++)_多线段数据压缩华为od
- 3基于Python的豆瓣电影评论数据分析与可视化(源代码+可远程部署安装)_评论数据研究背景
- 4linux系统使用git对指定的文件进行回滚_linux git 回滚
- 5Python:“TypeError: list indices must be integers or slices, not str“问题解决方案
- 6实操指南:ORB-SLAM3的编译运行_orbslam3安装运行
- 72024 年第一季度勒索软件态势
- 8在使用python的Pip安装库时,报错:Fatal error in launcher:Unable to create process using ‘“‘_执行pip安装 fatal error in launcher:
- 9C语言链表实现
- 10linux中for引用变量,在 awk 中怎么使用循环 | Linux 中国
从了解到掌握 Spark 计算框架(二)RDD
赞
踩

RDD 概述
RDD(Resilient Distributed Dataset)是 Spark 中的核心数据抽象,代表着分布式的不可变的数据集合。
RDD 具有以下几个重要的特点和特性:
-
分布式的:RDD 将数据分布存储在集群中的多个计算节点上,每个节点上都存储着数据的一个分区。这样可以实现数据的并行处理和计算。
-
不可变的:RDD 是不可变的数据集合,一旦创建就不能被修改。任何对 RDD 进行的转换操作都会生成一个新的 RDD,原始的 RDD 不受影响。
-
可并行计算的:RDD 支持并行计算,可以在集群中的多个计算节点上同时进行计算。这样可以充分利用集群中的资源,加速数据处理和计算。
-
容错性:RDD 具有容错性,可以在计算节点失败或数据丢失时进行恢复。它通过 RDD 的血统(Lineage)来记录每个 RDD 的来源和依赖关系,当某个分区的数据丢失或出错时,Spark 可以根据 RDD 的血统重新计算丢失的数据分区,保证计算结果的正确性。
RDD 组成
RDD 的重要组成(主要属性)部分包括数据的分区、计算函数、依赖关系、分区函数和最佳位置等信息。这些关键组成部分共同构成了 RDD 的核心特性和功能,为 Spark 提供了高效的数据处理和计算能力。
数据集合
- RDD 表示了一个分布式的、不可变的数据集合。这个数据集合可以来自于外部数据源,如 HDFS、本地文件系统、HBase、Cassandra 等,也可以通过对其他 RDD 进行转换操作生成。
分区列表
- RDD 将数据分成多个分区存储在集群中的不同计算节点上,每个分区在集群中的一个计算节点上计算。分区列表描述了数据集被划分为多少个分区以及分区之间的关系。
计算函数
- 每个 RDD 都有一个计算函数,用于描述数据的转换过程。转换操作会生成新的 RDD,新的 RDD 依赖于原始的 RDD。计算函数定义了 RDD 如何通过转换操作来生成新的 RDD。
依赖关系
- 依赖关系描述了 RDD 之间的依赖关系,即一个 RDD 如何依赖于其他 RDD。Spark 中的转换操作会生成新的 RDD,新的 RDD 依赖于原始的 RDD。依赖关系通过 RDD 的血统(Lineage)来表示,用于容错和数据恢复。
分区函数
- 分区函数定义了 RDD 中数据如何分布到各个分区中。默认情况下,Spark 使用
hash分区函数将数据均匀地分布到各个分区中,但用户也可以根据需要自定义分区函数,根据数据的特性进行分区。
最佳位置
- 最佳位置指的是 RDD 中数据的最佳存储位置,即计算节点上离数据所在位置最近的节点。Spark 会尽量将计算任务调度到数据所在的节点上执行,以减少数据传输和网络通信开销,提高计算性能。
RDD 的作用
RDD 在 Spark 中扮演着多种角色,包括数据抽象、并行计算、数据处理和转换以及数据持久化等,为用户提供了一个高效、通用、可扩展且易用的大数据处理平台。
-
数据抽象:RDD 是 Spark 中的核心数据抽象,代表着分布式的不可变的数据集合。它可以从各种数据源创建,如HDFS、HBase、本地文件系统、数据库等,同时也可以通过对现有 RDD 进行转换操作生成新的 RDD。这种灵活的数据抽象使得开发者可以轻松地处理和分析各种类型的数据。
-
并行计算:RDD 支持并行计算,在集群中的多个计算节点上同时进行计算,充分利用集群的资源,加速数据处理和分析过程。通过 RDD 的分区机制,Spark 可以将数据分配到不同的计算节点上进行并行计算,提高了数据处理的效率。
-
数据处理和转换:RDD 提供了丰富的转换操作,如
map、filter、reduceByKey、join等,用于对数据进行转换和处理。这些转换操作可以将原始数据集合转换成各种形式的数据集合,实现复杂的数据处理和分析任务。 -
数据持久化:RDD 支持数据持久化,可以将中间计算结果缓存到内存或磁盘中,以加速迭代计算和交互式查询。通过持久化操作,Spark 可以在迭代算法中复用中间计算结果,避免重复计算,提高计算性能。
RDD 算子分类
算子(Operator)通常是指对数据进行操作的一种函数或方法。在 Spark 中,算子是指对 RDD 或 DataFrame 等数据集进行转换或行动操作的函数或方法。
在 RDD 中,支持两种算子类型的操作:
-
转换操作算子(Transformations):转换操作是对现有的 RDD 进行转换,生成一个新的 RDD(新的数据集)。常见的转换操作包括
map、filter、flatMap、reduceByKey、join等。转换操作是惰性的,不会立即执行,而是在遇到行动操作时才会触发实际的计算。 -
行动操作算子(Actions):行动操作是对 RDD 进行实际的计算,并返回结果。常见的行动操作包括
collect、count、reduce、saveAsTextFile、foreach等。行动操作会触发 Spark 作业的执行,从而在集群中进行数据处理和计算。
RDD 的创建
1.从外部数据源读取
使用 SparkContext 或 SparkSession 中提供的方法,从外部数据源(如文本文件、JSON 文件、CSV 文件等)读取数据,创建 RDD。这种方式适用于从文件系统或数据库等外部数据源中读取数据。
package com.jsu.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.List;
public class rddTest {
public static void main(String[] args) {
// 1.创建 Spark 配置对象
SparkConf conf = new SparkConf().setAppName("rddTest").setMaster("local[*]");
// 2.创建 Spark 内容对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.读取外部数据源
JavaRDD<String> stringRDD = sc.textFile("src/main/resources/data/name.txt",1);
// 4.获取元素内容打印输出
List<String> collect = stringRDD.collect();
for (String s : collect) {
System.out.println(s);
}
// 5.释放资源
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
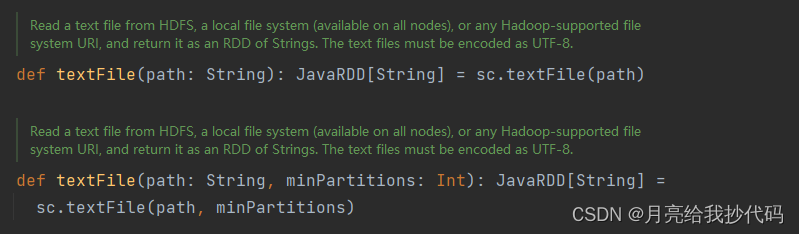
textFile 方法是 Spark 中用于从文本文件创建 RDD 的函数。它会将文本文件的每一行作为 RDD 中的一个元素,拥有两个参数:
-
path:指定要读取的文本文件的路径。可以是本地文件系统的路径,也可以是分布式文件系统(如 HDFS)的路径。 -
minPartitions:可选参数,指定最小的分区数。如果不指定,Spark 会根据文件的大小自动确定分区数。
从源码中可以看到,它拥有两个重载的方法,传递参数不同,需要注意的是,读取的文本文件编码格式必须是 UTF-8。
注:本系列均采用 Java 版 Spark
3.3.1,与 Scala 版 Spark 中的 API 有些许差异,但逻辑是一样的。
2.从已有的集合或数组创建
使用 SparkContext 的 parallelize 方法,将已有的集合或数组转换为 RDD。这种方式适用于将内存中的数据集合转换为 RDD。
package com.jsu.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class rddTest2 {
public static void main(String[] args) {
// 1.创建 Spark 配置对象
SparkConf conf = new SparkConf().setAppName("rddTest2").setMaster("local[*]");
// 2.创建 Spark 内容对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.创建集合
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 4.通过集合创建 RDD
JavaRDD<Integer> rdd = sc.parallelize(list);
// 5.获取元素内容打印输出
System.out.println(rdd.take(5));
// 6.释放资源
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
parallelize 方法是 Spark 中用于从一个已有的集合创建 RDD 的方法。该方法将集合中的元素分发到集群中的各个计算节点上,形成一个分布式的数据集,方便后续进行分布式计算。参数:
-
list:要并行化的集合,通常是一个 List 或者数组。 -
numSlices:指定要将数据划分为多少个分区,默认值为默认并行度,即集群中可用的处理器数目。
3.从已有的 RDD 进行转换
通过对已有的 RDD 进行转换操作生成新的 RDD,这种方式适用于对现有数据集进行进一步处理或分析。
package com.jsu.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class rddTest3 {
public static void main(String[] args) {
// 1.创建 Spark 配置对象
SparkConf conf = new SparkConf().setAppName("rddTest3").setMaster("local[*]");
// 2.创建 Spark 内容对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.创建集合
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 4.创建RDD
JavaRDD<Integer> rdd1 = sc.parallelize(list);
// 5.通过现有RDD创建新RDD
JavaRDD<Integer> rdd2 = rdd1.map(el -> el + 1);
// 6.获取元素内容打印输出
System.out.println(rdd2.take(5));
// 7.释放资源
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
map 算子是一个转换算子,它不会立即执行计算,而是在遇到行动算子时才会触发实际的计算。它对每个元素逐一遍历执行转换操作,形成新的 RDD。
RDD 常用算子大全
转换算子
| 算子 | 作用说明 | 示例代码 |
|---|---|---|
map | 对 RDD 中的每个元素应用一个函数,返回一个新的 RDD。 | rdd.map(x -> x * 2) |
flatMap | 类似于 map,但每个输入元素可以被映射为 0 个或多个输出元素(返回一个扁平化的 RDD)。 | rdd.flatMap(x -> Arrays.asList(x, x * 2).iterator()) |
filter | 对 RDD 中的每个元素应用一个函数,返回一个只包含函数返回值为 true 的元素的新 RDD。 | rdd.filter(x -> x > 2) |
mapPartitions | 类似于 map,但在 RDD 的每个分区上运行一个函数,返回一个新的 RDD。 | rdd.mapPartitions(iterator -> iterator.map(x -> x * 2)) |
mapToPair | 将 RDD 中的每个元素映射为一个 (K, V) 键值对,返回一个新的 Pair RDD。 | rdd.mapToPair(x -> new Tuple2<>(x, x * 2)) |
mapValues | 只对 (K, V) 键值对 RDD 的每个 V 值应用一个函数,返回一个新的 (K, V) RDD。 | pairRdd.mapValues(x -> x * 2) |
mapPartitionsWithIndex | 类似于 mapPartitions,但函数同时接收分区索引。 | rdd.mapPartitionsWithIndex((index, iterator) -> iterator.map(x -> (index, x))) |
repartition | 随机地将数据重新分区,可以增加或减少分区数。 | rdd.repartition(10) |
coalesce | 减少分区数,且尽量避免数据的移动。适用于减少分区数时使用。 | rdd.coalesce(2) |
partitionBy | 通过一个分区器(Partitioner)重新分区,适用于 (K, V) 键值对 RDD。常见的分区器有 HashPartitioner 和 RangePartitioner。 | pairRdd.partitionBy(new HashPartitioner(3)) |
sample | 从 RDD 中以指定的随机采样方式抽取样本,返回一个新的 RDD。 | rdd.sample(false, 0.1) |
union | 返回两个 RDD 的并集。 | rdd1.union(rdd2) |
intersection | 返回两个 RDD 的交集。 | rdd1.intersection(rdd2) |
distinct | 返回一个新的 RDD,只包含唯一的元素(去重)。 | rdd.distinct() |
groupByKey | 对 (K, V) 键值对 RDD 进行分组,返回一个 (K, Iterable) 形式的 RDD。 | pairRdd.groupByKey() |
reduceByKey | 对 (K, V) 键值对 RDD 中每个键使用指定的二元操作进行聚合,返回一个新的 (K, V) RDD。 | pairRdd.reduceByKey((x, y) -> x + y) |
aggregateByKey | 类似于 reduceByKey,但允许返回的值与输入的值类型不同。 | pairRdd.aggregateByKey(zeroValue, seqOp, combOp) |
sortByKey | 对 (K, V) 键值对 RDD 按键进行排序,返回一个新的 RDD。 | pairRdd.sortByKey() |
join | 对两个 RDD 进行内连接,返回一个 (K, (V, W)) 形式的 RDD。 | rdd1.join(rdd2) |
cogroup | 对两个 (K, V) 和 (K, W) 键值对 RDD 进行分组,返回一个 (K, (Iterable, Iterable)) 形式的 RDD。 | rdd1.cogroup(rdd2) |
cartesian | 返回两个 RDD 的笛卡尔积。 | rdd1.cartesian(rdd2) |
pipe | 将 RDD 的每个分区的内容作为输入传递给外部程序,并将输出作为一个新的 RDD 返回。 | rdd.pipe("script.sh") |
zipWithIndex | 为 RDD 中的每个元素分配一个唯一的索引值,返回一个 (元素, 索引) 的键值对形式的新 RDD。 | rdd.zipWithIndex() |
行动算子
| 算子 | 作用说明 | 示例代码 |
|---|---|---|
collect | 将 RDD 中的所有元素作为一个数组返回到驱动程序中。 | rdd.collect() |
count | 返回 RDD 中的元素个数。 | rdd.count() |
take | 返回 RDD 的前 n 个元素。 | rdd.take(5) |
top | 返回 RDD 中的前 n 个元素,按照默认的或自定义的顺序。 | rdd.top(5) |
reduce | 对 RDD 的元素使用指定的二元操作进行聚合,返回一个单一的结果。 | rdd.reduce((x, y) -> x + y) |
fold | 与 reduce 类似,但提供了一个初始值。 | rdd.fold(0, (x, y) -> x + y) |
aggregate | 与 fold 类似,但允许返回的值与输入的值类型不同。 | rdd.aggregate(zeroValue, seqOp, combOp) |
foreach | 对 RDD 中的每个元素应用一个函数,通常用于触发执行。 | rdd.foreach(x -> System.out.println(x)) |
countByKey | 对 (K, V) 键值对 RDD 中每个键进行计数,返回一个 Map。 | pairRdd.countByKey() |
saveAsTextFile | 将 RDD 保存到指定目录中的文本文件。 | rdd.saveAsTextFile("output/path") |
saveAsSequenceFile | 将 RDD 保存为 Hadoop 序列文件。 | pairRdd.saveAsSequenceFile("output/path") |
saveAsObjectFile | 将 RDD 以 Java 对象序列化的形式保存到指定路径。 | rdd.saveAsObjectFile("output/path") |
takeSample | 返回 RDD 的一个随机采样子集。 | rdd.takeSample(false, 5) |
RDD 算子综合练习
假设现有一个包含服务器访问日志的文本文件 logs.txt,每一行表示一个访问记录,格式如下:
timestamp ip_address url response_code response_time
2023-05-01 12:34:56 192.168.0.1 /index.html 200 123
2023-05-01 12:35:01 192.168.0.2 /about.html 404 56
2023-05-01 12:35:05 192.168.0.1 /index.html 200 78
2023-05-01 12:35:10 192.168.0.3 /contact.html 200 150
2023-05-01 12:35:15 192.168.0.4 /products.html 200 200
2023-05-01 12:35:20 192.168.0.5 /index.html 200 300
2023-05-01 12:35:25 192.168.0.6 /about.html 500 450
2023-05-01 12:35:30 192.168.0.2 /index.html 200 90
2023-05-01 12:35:35 192.168.0.3 /contact.html 404 30
2023-05-01 12:35:40 192.168.0.7 /products.html 200 100
2023-05-01 12:35:45 192.168.0.8 /index.html 200 60
2023-05-01 12:35:50 192.168.0.9 /about.html 404 50
2023-05-01 12:35:55 192.168.0.10 /contact.html 200 80
2023-05-01 12:36:00 192.168.0.1 /products.html 200 120
2023-05-01 12:36:05 192.168.0.2 /index.html 200 110
2023-05-01 12:36:10 192.168.0.3 /about.html 200 200
2023-05-01 12:36:15 192.168.0.4 /contact.html 404 70
2023-05-01 08:36:20 192.168.0.5 /products.html 500 250
2023-05-01 11:36:25 192.168.0.6 /index.html 200 90
2023-05-01 09:36:30 192.168.0.7 /about.html 200 60
2023-05-01 13:36:35 192.168.0.8 /contact.html 200 180
2023-05-01 11:36:40 192.168.0.9 /products.html 200 170
2023-05-01 10:36:45 192.168.0.10 /index.html 200 220
2023-05-01 12:36:50 192.168.0.1 /about.html 404 140
2023-05-01 12:36:55 192.168.0.2 /contact.html 200 130
2023-05-01 12:37:00 192.168.0.3 /products.html 200 190
2023-05-01 12:37:05 192.168.0.4 /index.html 200 260
2023-05-01 12:37:10 192.168.0.5 /about.html 404 160
2023-05-01 19:37:15 192.168.0.6 /contact.html 200 150
2023-05-01 12:37:20 192.168.0.7 /products.html 200 80
2023-05-01 18:37:25 192.168.0.8 /index.html 200 140
2023-05-01 12:37:30 192.168.0.9 /about.html 500 210
2023-05-02 12:37:35 192.168.0.10 /contact.html 200 170
2023-05-02 11:37:05 192.168.0.4 /index.html 200 260
2023-05-02 11:37:10 192.168.0.5 /about.html 404 160
2023-05-02 11:37:15 192.168.0.6 /contact.html 200 150
2023-05-02 11:37:20 192.168.0.7 /products.html 200 80
2023-05-02 11:37:25 192.168.0.8 /index.html 200 140
2023-05-02 13:37:30 192.168.0.9 /about.html 500 210
2023-05-02 14:37:35 192.168.0.10 /contact.html 200 170
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
读取日志文件,进行解析,完成下列需求:
1.统计不同 URL 的访问次数
- 计算每个 URL 的访问次数,按访问次数降序排序,输出前
10个 URL 及其访问次数。
2.计算每个 IP 地址的平均响应时间
- 计算每个 IP 地址的平均响应时间,输出前
10个平均响应时间最长的 IP 地址及其平均响应时间。
3.计算每小时的访问量
- 计算每个小时的访问量,输出每小时的访问量。
4.保存结果
- 将以上统计结果分别保存到文件路径中。
package com.jsu.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class rddTask {
public static void main(String[] args) {
// 1.创建 spark 对象
SparkConf conf = new SparkConf().setAppName("rddTask").setMaster("local[*]");
JavaSparkContext spark = new JavaSparkContext(conf);
// 2.读取日志文件内容,过滤首行表头数据
JavaPairRDD<String, Long> rdd = spark.textFile("src/main/resources/data/logs.txt").zipWithIndex().filter(el -> el._2 >= 1);
// 3.对数据进行分割
JavaRDD<String[]> splitRdd = rdd.map(Tuple2::_1).map(el -> el.split(" "));
// 4.统计不同 URL 的访问次数
JavaPairRDD<String, Integer> urlRdd = splitRdd.mapToPair(el -> new Tuple2<>(el[3], 1)).reduceByKey(Integer::sum);
urlRdd.foreach(x -> System.out.println(x));
System.out.println();
urlRdd.repartition(1).saveAsTextFile("src/main/resources/res1");
// 5.计算每个 IP 地址的平均响应时间
JavaPairRDD<String, Integer> ipTimeRDD = splitRdd
.mapToPair(el -> new Tuple2<>(el[2], new Tuple2<>(Integer.parseInt(el[5]), 1)))
.reduceByKey((x, y) -> new Tuple2<>(x._1 + y._1, x._2 + x._2))
.mapValues(sumCount -> sumCount._1 / sumCount._2);
ipTimeRDD.foreach(x -> System.out.println(x));
urlRdd.repartition(1).saveAsTextFile("src/main/resources/res2");
// 6.计算每小时的访问量
JavaPairRDD<String, Integer> rdd4 = splitRdd.mapToPair(el -> new Tuple2<>(el[0] + " " + el[1].substring(0, 2), 1)).reduceByKey(Integer::sum);
System.out.println();
rdd4.sortByKey().foreach(x -> System.out.println(x));
rdd4.repartition(1).saveAsTextFile("src/main/resources/res3");
// 7.释放资源
spark.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
代码释义
1.创建 Spark 对象
- 初始化 Spark 配置
SparkConf并创建JavaSparkContext对象,设置应用程序名称为 “rddTask”,运行模式为本地 (local[*]),使用所有可用 CPU 核心。
2.读取日志文件内容并过滤表头数据
- 使用
spark.textFile读取日志文件内容,并通过zipWithIndex给每一行数据加上索引。 - 过滤掉索引为
0的表头数据。
3.对数据进行分割
- 通过
map方法对每行数据进行分割,将其转换为字符串数组。
4.统计不同 URL 的访问次数
- 使用
mapToPair将每行数据映射为(URL, 1)的键值对,并使用reduceByKey对相同的 URL 进行计数。 - 将统计结果输出到控制台并保存到文件中。
5.计算每个 IP 地址的平均响应时间
- 将每行数据映射为
(IP地址, (响应时间, 1))的键值对。 - 使用
reduceByKey聚合相同 IP 地址的响应时间和计数。 - 计算每个 IP 地址的平均响应时间并输出到控制台和文件中。
6.计算每小时的访问量
- 将每行数据映射为
(日期 小时, 1)的键值对。 - 使用
reduceByKey计算每小时的访问次数。 - 对结果按时间排序,并输出到控制台和文件中。
7.释放资源
- 调用
spark.stop()释放 Spark 资源。
RDD 依赖关系
RDD 的依赖关系描述了一个 RDD 是如何从一个或多个 RDD 派生出来的。这些依赖关系有助于 Spark 在发生失败时,能够恢复丢失的分区数据,并且能够高效地执行集群计算任务。
在 RDD 中的依赖关系主要有两种类型:窄依赖和宽依赖。
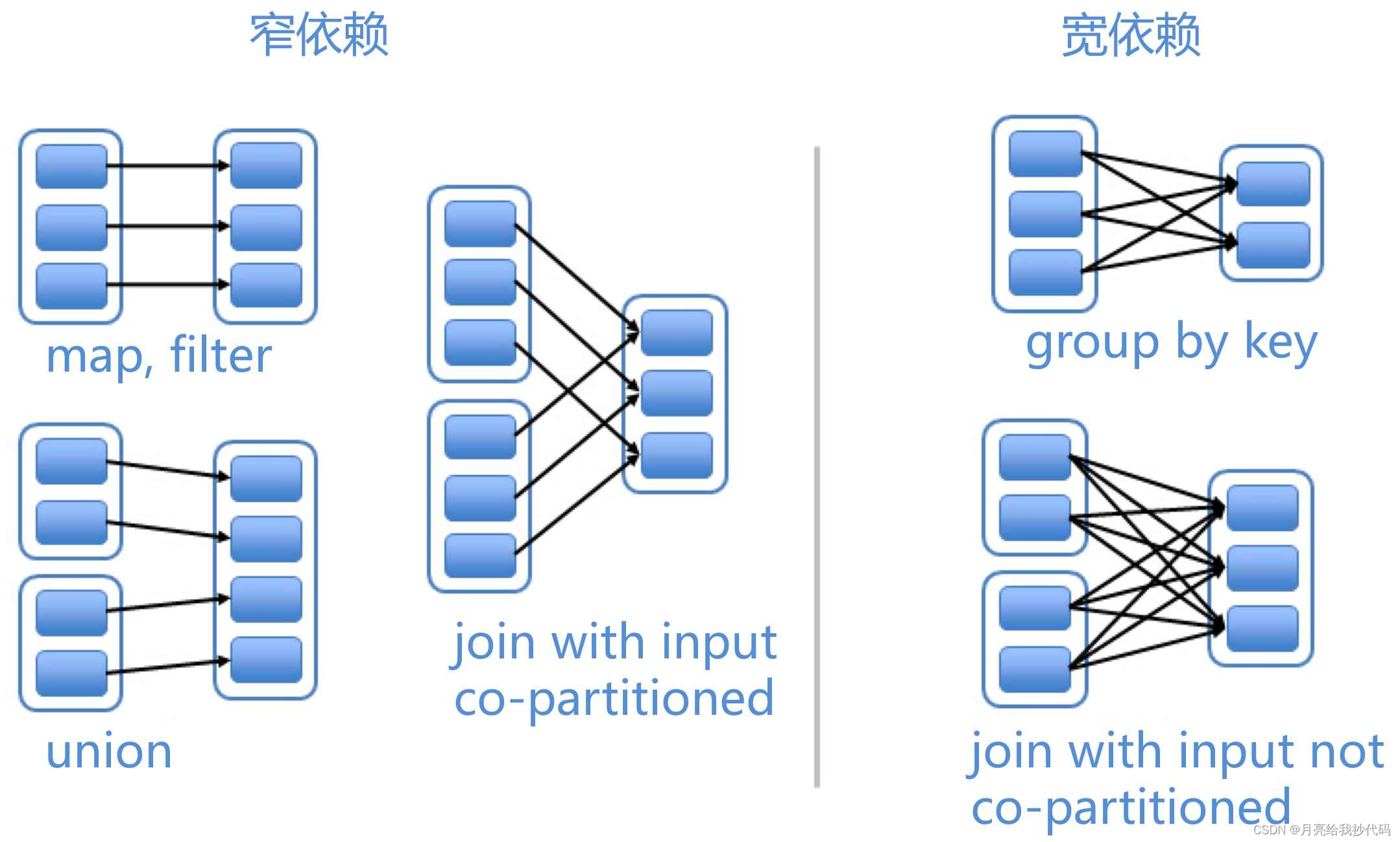
图片来源 —— Spark 的宽依赖和窄依赖
窄依赖
窄依赖表示父 RDD 的每一个分区只被子 RDD 中的一个分区依赖使用,属于一对一或者多对一。窄依赖不会引发 Shuffle 操作,效率高。
为什么也属于多对一呢?
因为不同父 RDD 中的某一个分区,可以提供给相同的子 RDD 中的一个分区使用。
这种依赖关系在发生故障时可以更快地恢复,因为只需要重新计算少量的分区即可。
案例:map 和 filter
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class NarrowDependencyExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("NarrowDependencyExample").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(data);
// 窄依赖: map 操作
JavaRDD<Integer> mappedRdd = rdd.map(x -> x * 2);
// 窄依赖: filter 操作
JavaRDD<Integer> filteredRdd = mappedRdd.filter(x -> x > 5);
filteredRdd.collect().forEach(System.out::println);
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在这个例子中,map 和 filter 操作都属于窄依赖,因为 mappedRdd 的每个分区仅依赖于 rdd 的一个分区,而 filteredRdd 的每个分区仅依赖于 mappedRdd 的一个分区。
宽依赖
宽依赖表示父 RDD 中至少有一个分区对应子 RDD 的多个分区,属于一对多。会涉及 Shuffle 阶段,在执行计算任务时需要跨节点的数据交换,效率低。
案例:reduceByKey 和 join
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
public class WideDependencyExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("WideDependencyExample").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Tuple2<String, Integer>> data = Arrays.asList(
new Tuple2<>("a", 1),
new Tuple2<>("b", 2),
new Tuple2<>("a", 3),
new Tuple2<>("b", 4)
);
JavaPairRDD<String, Integer> pairRDD = sc.parallelizePairs(data);
// 宽依赖: reduceByKey 操作
JavaPairRDD<String, Integer> reducedRdd = pairRDD.reduceByKey(Integer::sum);
reducedRdd.collect().forEach(System.out::println);
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
在这个例子中,reduceByKey 操作涉及 shuffle 阶段,因为需要跨分区对相同的 key 进行合并。这意味着 reducedRdd 的每个分区可能依赖于 pairRDD 的多个分区。
宽窄依赖算子区分
只有转换算子会有宽依赖和窄依赖的划分,行动算子没有这种划分,因为行动算子的作用是触发计算并生成结果,而不是对 RDD 进行转换和依赖构建。
我们在编写程序时,要避免使用宽依赖算子,在满足业务需求的情况下,尽量使用窄依赖算子。
-
宽依赖算子:会引起 Shuffle 操作的算子,例如:
join、reduceByKey、groupByKey、sortByKey、partitionBy、distinct、intersection、repartition等 -
窄依赖算子:不会引发 Shuffle 操作的算子,例如:
map、filter、flatMap、mapPartitions、mapValues、coalesce、mapPartitionsWithIndex、mapToPair、union等
宽依赖会增加 Spark 作业中的 stage(阶段),这是因为宽依赖的算子需要进行 Shuffle 操作,而 Shuffle 操作涉及到数据在不同节点之间的重新分配和传输,导致需要重新划分计算任务。
当一个 RDD 的计算依赖于前一个 RDD 的多个分区(即宽依赖),这就意味着需要将数据从前一个阶段的多个分区重新分配到下一个阶段的新分区中。因此,每次遇到宽依赖算子时,Spark 会将作业拆分为两个阶段:
-
Stage 1:执行宽依赖算子之前的所有窄依赖算子;
-
Shuffle Operation:执行宽依赖算子,进行数据重分配(Shuffle);
-
Stage 2:执行宽依赖算子之后的所有算子。
RDD 血统信息
血统信息(Lineage)是指 RDD 之间的依赖关系图,用于记录如何从初始输入数据通过一系列转换生成新的 RDD,使 Spark 能够在任何一步出错时根据血统信息重新计算数据,而不需要重新读取整个数据集。
血统信息的作用
-
故障恢复:如果在计算过程中某个节点发生故障,Spark 可以根据血统信息重新计算丢失的数据块。这样可以确保计算的正确性和完整性,而不需要重新启动整个作业。
-
懒计算:RDD 是惰性求值的,只有在触发行动操作(action)时才会真正计算。血统信息帮助 Spark 记录转换过程,只有在需要时才计算最终结果。
-
优化执行:Spark 可以根据血统信息进行优化,如合并多个窄依赖的转换步骤以减少数据传输和计算开销。
血统信息的组成
血统信息包含了 RDD 的所有依赖关系及其转换操作,主要包含以下内容:
-
初始 RDD:从文件系统(如 HDFS)或其他数据源读取的数据。
-
转换操作:如
map、filter、flatMap等,描述了如何从一个 RDD 生成另一个 RDD。 -
依赖关系:表示一个 RDD 如何依赖于其他 RDD,分为窄依赖和宽依赖。
代码案例
假设我们有以下代码片段:
// 17 行
JavaRDD<String> lines = sc.textFile("src/main/resources/data/logs.txt");
// 18 行
JavaRDD<String> errors = lines.filter(line -> line.contains("ERROR"));
- 1
- 2
- 3
- 4
在这个例子中,血统信息将包含以下内容:
-
初始 RDD:从文件中读取的
linesRDD。 -
转换操作:
errorsRDD 由linesRDD 通过filter转换生成,条件是包含"ERROR"。 -
依赖关系:
errors依赖于lines,属于窄依赖。
我们在代码中可以通过 rdd.toDebugString() 方法获取指定 RDD 的血统信息,如下所示:
System.out.println(errors.toDebugString());
- 1
输出结果:
(2) MapPartitionsRDD[2] at filter at rddTestLineage.java:18 []
| src/main/resources/data/logs.txt MapPartitionsRDD[1] at textFile at rddTestLineage.java:17 []
| src/main/resources/data/logs.txt HadoopRDD[0] at textFile at rddTestLineage.java:17 []
- 1
- 2
- 3
从后往前看:
-
HadoopRDD[0]表示:这是从 HDFS 或本地文件系统中读取的初始 RDD,称为 HadoopRDD。 -
MapPartitionsRDD[1]表示:这是textFile方法创建的 MapPartitionsRDD,它表示对读取的数据进行了初步分区。 -
MapPartitionsRDD[2]表示:这是errorsRDD,通过对linesRDD 进行filter操作生成的 MapPartitionsRDD。
血统信息的弊端
虽然血统信息在 Spark 中用于跟踪 RDD 的生成和转换过程,能够应对故障,避免重复计算,是 RDD 容错机制的基础,但是过长的血统信息会带来一些弊端和问题。
1.计算开销增加
- 如果 RDD 血统链过长,每次行动操作(如
collect、count等)都需要从最初的 RDD 开始重头计算所有依赖链条中的转换操作,导致计算开销和延迟显著增加。
2.容错开销增加
- 如果某个分区丢失,Spark 会根据血统信息重新计算该分区的数据。过长的血统链会导致重新计算的步骤繁多,增加恢复数据的时间和资源消耗。
3.内存和存储开销增加
- 维护长链条的血统信息需要占用更多的内存和存储资源,尤其是对于大量中间结果和复杂计算的应用。
4.调试困难
- 血统链条过长会使调试过程变得复杂,难以追踪数据的流动和转换,尤其是在复杂的计算流程中。
那么如何解决血统信息所带来的弊端呢?
这就要靠下面介绍的持久化与缓存以及检查点来进行处理了,接着奏乐,接着舞!Lets go~
RDD 持久化与缓存
在 Spark 中,RDD 是不可变且惰性求值的。默认情况下,RDD 的每次计算都是从头开始的。如果一个 RDD 被多次使用,为了避免重复计算,可以将 RDD 进行持久化或缓存。
持久化是将 RDD 存储在内存中或者磁盘上,以便后续重用时可以直接访问存储的数据,而不需要重新计算。
持久化级别
-
MEMORY_ONLY:将 RDD 以序列化的形式存储在 JVM 堆内存中。 -
MEMORY_AND_DISK:如果内存不足,则将 RDD 以序列化的形式部分存储在内存中,部分存储在磁盘上。 -
MEMORY_ONLY_SER:将 RDD 以序列化的形式存储在内存中,节省空间,但序列化和反序列化的开销较大。 -
MEMORY_AND_DISK_SER:将 RDD 以序列化的形式部分存储在内存中,部分存储在磁盘上,节省空间,但序列化和反序列化的开销较大。 -
DISK_ONLY:将 RDD 只存储在磁盘上。 -
OFF_HEAP:将 RDD 存储在堆外内存中,适用于管理大数据集时减少 JVM 垃圾回收的影响。
在 Spark 中通过 persist 方法调用,例如:rdd.persist(StorageLevels.MEMORY_ONLY)。
缓存
缓存是持久化的一种简化方式,通过调用 rdd.cache() 方法实现,默认情况下,等同持久化级别中的 MEMORY_ONLY,将 RDD 以序列化的形式存储在 JVM 堆内存中。
代码案例
下面是一个展示 RDD 持久化与缓存的具体案例:
package com.example.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.StorageLevels;
import scala.Tuple2;
import java.util.Arrays;
public class RDDCacheExample {
public static void main(String[] args) {
// 创建 Spark 配置和上下文对象
SparkConf conf = new SparkConf().setAppName("RDDCacheExample").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建一个 RDD
JavaRDD<String> lines = sc.parallelize(Arrays.asList(
"2023-05-01 12:34:56 192.168.0.1 /index.html 200 123",
"2023-05-01 12:35:01 192.168.0.2 /about.html 404 56",
"2023-05-01 12:35:05 192.168.0.1 /index.html 200 78"
));
// 分割日志数据
JavaRDD<String[]> splitLines = lines.map(line -> line.split(" "));
// 缓存 RDD
splitLines.cache();
//splitLines.persist(StorageLevels.MEMORY_ONLY);
// 计算不同 URL 的访问次数
JavaPairRDD<String, Integer> urlCounts = splitLines.mapToPair(fields -> new Tuple2<>(fields[3], 1))
.reduceByKey(Integer::sum);
urlCounts.foreach(x -> System.out.println("URL: " + x._1 + ", Count: " + x._2));
// 释放资源
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
在需要多次使用同一个 RDD 时,建议对 RDD 进行缓存或持久化,以提高计算效率。
其它场景可以根据数据规模和资源限制选择合适的存储级别,例如内存不足时可以选择 MEMORY_AND_DISK。
RDD 容错机制
Spark 中的 RDD 具有内置的容错机制,通过血统(Lineage)信息追踪 RDD 的生成方式,可以在节点失败时重算丢失的分区。但在复杂的计算过程中,重算代价可能很高。为了优化这个问题,Spark 提供了 Checkpoint 检查点机制。
Checkpoint
Checkpoint 是将 RDD 的数据保存到可靠存储系统(如 HDFS)上。这会切断 RDD 的血统信息,从而避免复杂计算步骤的重复执行。
在以下情况,使用 Checkpoint 非常有用:
-
血统图(Lineage)非常长且复杂。
-
需要容忍频繁的节点故障。
-
需要保存中间结果,避免重复计算。
使用 Checkpoint 也非常简单,仅需两步:
-
设置 Checkpoint 目录;
-
调用
checkpoint()方法对 RDD 进行 Checkpoint 操作。
缓存与检查点的区别
| 特性 | 缓存(Cache) | 检查点(Checkpoint) |
|---|---|---|
| 存储位置 | 内存(默认)或磁盘 | 可靠存储系统(如 HDFS) |
| 血统信息 | 保留血统信息 | 切断血统信息 |
| 使用场景 | 需要多次访问同一个 RDD,重复计算代价高 | 血统图长且复杂,需要高容错性,防止数据丢失 |
| 恢复方式 | 通过血统信息重新计算 | 通过检查点存储恢复 |
| 性能影响 | 内存利用率高,适合快速重用 | 性能开销较大,但提高容错性,适合长时间运行和复杂计算 |
在实际应用中,可以根据具体需求选择合适的机制,例如在长血统图和复杂计算中使用检查点,而在需要快速重用数据时使用缓存。
当然我们也可以同时使用 Cache 和 Checkpoint。在进行 Checkpoint 操作之前,提前对 RDD 进行缓存,避免在 Checkpoint 操作期间重复计算 RDD,可以有效提升 Spark 应用的性能和容错能力。
代码案例
package com.example.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class RDDCheckpointExample {
public static void main(String[] args) {
// 创建 Spark 配置和上下文对象
SparkConf conf = new SparkConf().setAppName("RDDCheckpointExample").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
// 设置 Checkpoint 目录
sc.setCheckpointDir("src/main/resources/checkpoint");
// 创建一个 RDD
JavaRDD<String> lines = sc.parallelize(Arrays.asList(
"2023-05-01 12:34:56 192.168.0.1 /index.html 200 123",
"2023-05-01 12:35:01 192.168.0.2 /about.html 404 56",
"2023-05-01 12:35:05 192.168.0.1 /index.html 200 78"
));
// 分割日志数据
JavaRDD<String[]> splitLines = lines.map(line -> line.split(" "));
// 缓存 RDD
splitLines.cache();
// 进行 Checkpoint 操作
splitLines.checkpoint();
// 统计不同 URL 的访问次数
JavaPairRDD<String, Integer> urlCounts = splitLines.mapToPair(fields -> new Tuple2<>(fields[3], 1))
.reduceByKey(Integer::sum);
urlCounts.foreach(x -> System.out.println("URL: " + x._1 + ", Count: " + x._2));
// 释放资源
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
DAG
DAG 是有向无环图(Directed Acyclic Graph)的简称。在计算中,DAG 是一种图形结构,包含一组顶点和有向边,其中没有任何一个顶点可以通过一系列边回到自身。

DAG 通常用于表示依赖关系,例如任务调度、表达式求值、工作流和数据处理流水线。
Spark 中的 DAG
在 Spark 中,DAG 是用来表示一系列操作(如转换和行动)之间的依赖关系的基础结构。
当我们对 RDD 进行一系列转换(如 map、filter 等)时,这些转换操作会形成一个逻辑上的 DAG,代表数据从输入到输出的流动过程。行动操作(如 count、collect 等)会触发 Spark 实际执行这些操作。
DAG 划分
-
逻辑 DAG:在用户编写 Spark 程序时,转换操作会形成一个逻辑上的 DAG。这是用户代码中操作的有序集合,还没有实际执行。
-
物理 DAG:当行动操作触发时,逻辑 DAG 会被转换成物理执行计划,其中包含具体的执行步骤,这是由 Spark 调度器生成的。
Stage
在 Spark 中,DAG 被分解成多个 Stage,每个 Stage 由一系列可以并行执行的任务组成。一个 Stage 通常对应于 RDD 依赖关系中的一个宽依赖(如 reduceByKey、join 等),而窄依赖(如 map、filter 等)通常可以在同一个 Stage 内完成。
Stage 的划分
-
窄依赖(Narrow Dependency):一个 RDD 的每个分区仅依赖于前一个 RDD 的一个分区。例如,
map和filter操作。窄依赖的转换操作通常在同一个 Stage 内完成。 -
宽依赖(Wide Dependency):一个 RDD 的分区依赖于多个上一个 RDD 的分区。例如,
reduceByKey和groupByKey操作。宽依赖的转换操作会导致一个新的 Stage 的开始。
执行流程
当一个行动操作被调用时,Spark 会根据逻辑 DAG 生成物理执行计划并划分阶段。
执行过程如下:
-
生成逻辑 DAG:根据用户的转换操作生成逻辑 DAG。
-
划分阶段:根据依赖关系(窄依赖和宽依赖)划分成多个 Stage。
-
任务调度:每个 Stage 被分解成多个任务,这些任务在集群的不同节点上并行执行。
-
执行:任务被提交给集群中的节点执行,节点会将数据加载到内存中进行计算。
-
结果返回:行动操作的结果会返回给驱动程序(对于
collect等操作),或者保存到存储系统中(对于saveAsTextFile等操作)。
代码案例
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class SparkDAGExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Spark DAG Example").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("src/main/resources/data/logs.txt");
JavaRDD<String> errors = lines.filter(line -> line.contains("ERROR"));
JavaRDD<String> warnings = lines.filter(line -> line.contains("WARN"));
JavaRDD<String> allIssues = errors.union(warnings);
JavaRDD<String> formattedIssues = allIssues.map(issue -> "Issue: " + issue);
formattedIssues.saveAsTextFile("output/issues.txt");
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在这个程序中:
-
textFile读取数据,形成第一个 RDDlines(HadoopRDD)。 -
filter操作生成两个新的 RDDerrors、warnings(MapPartitionsRDD)。 -
union操作生成一个新的 RDDallIssues(UnionRDD),这是一个宽依赖,会触发一个新的 Stage。 -
map操作生成一个新的 RDDformattedIssues(MapPartitionsRDD),这是一个窄依赖。 -
saveAsTextFile触发行动操作。
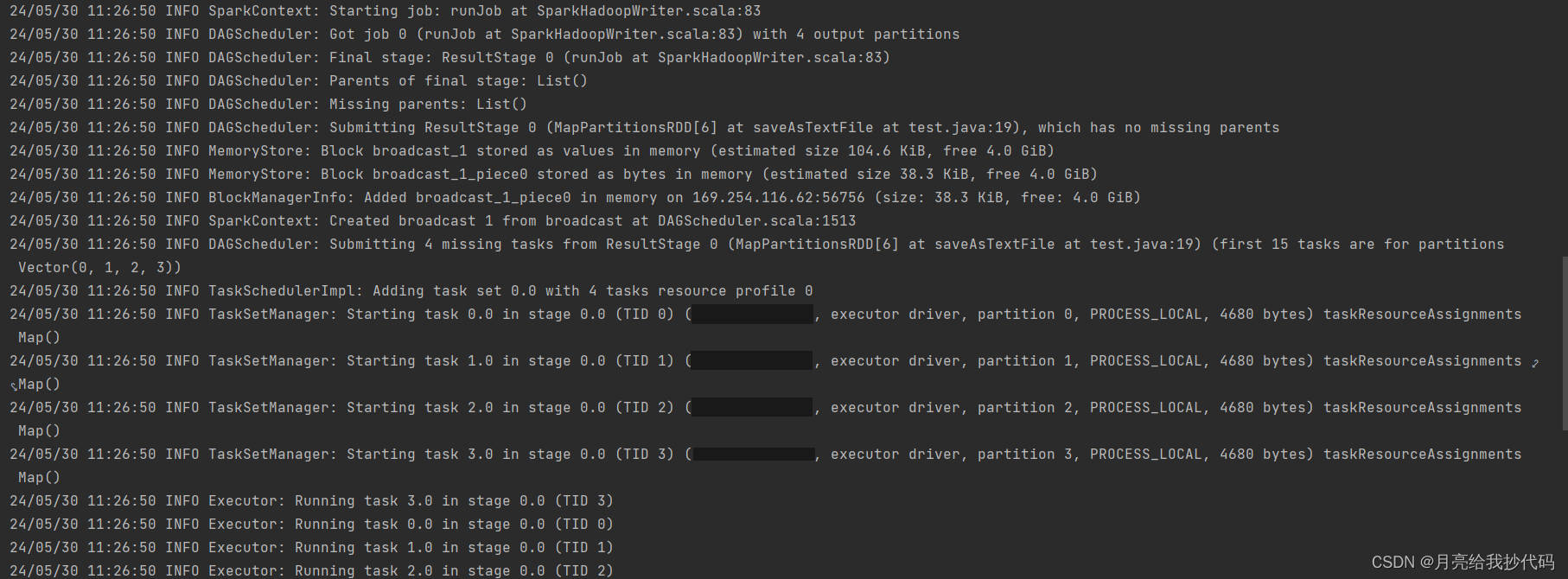
Stage 阶段划分:
- Stage 0:包括
textFile、filter、union、map、saveAsTextFile操作,这些是窄依赖。
在 IDEA 中运行上面这段代码时,如果没有关闭日志,我们可以清楚的看到程序日志的输出过程,从中可以看出,这段代码的确只有一个阶段,因为我们没有使用任何宽依赖算子。
累加器
累加器(Accumulator)是 Spark 提供的一种变量,用于在并行计算中进行累加操作。它可以在所有节点之间进行数值累加操作,并将结果返回给驱动程序(Driver)。
累加器最主要的作用是对分布式数据进行聚合。由于 Spark 中的数据处理是分布在多个节点上的,累加器提供了一种方式,可以跨任务累加数值,从而在全局范围内进行数据聚合。
累加器的特点
-
累加器只能在 Spark 的转换算子(如
map、filter等)中进行累加操作,不能在行动算子(如collect、count等)中读取值。 -
累加器的值只能在驱动程序端读取,并且是线程安全的。
-
虽然累加器可以用于其他类型的数据,但最常用的还是数值累加。
累加器应用场景
在处理大规模数据时,我们经常需要收集一些统计信息,比如:
-
处理了多少条记录。
-
有多少记录符合某些条件。
-
出现了多少次错误或警告。
累加器可以用来方便地收集这些统计信息,并在驱动程序中进行汇总和输出。
累加器的类型
Spark 提供了几种常用的累加器类型:
-
数值累加器(
LongAccumulator、DoubleAccumulator):用于累加数值类型的数据。 -
集合累加器(
CollectionAccumulator):用于累加集合类型的数据。 -
自定义累加器:用户可以定义自己的累加器类型,实现特定的数据累加逻辑。
累加器的创建与使用
在 Spark 中使用累加器共分为三步:
-
创建累加器:通过 SparkContext 上下文对象,调用驱动程序中的累加器方法,创建累加器,返回一个累加器对象。
-
使用累加器:在转换算子中对累加器进行累加操作。
-
获取累加值:通过累加器对象调用
value()方法,获取累加器最终的值。
代码案例
以下是一个使用数值累加器统计日志文件中错误行数的示例:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.util.LongAccumulator;
public class SparkAccumulatorExample {
public static void main(String[] args) {
// 1. 创建 Spark 配置和上下文
SparkConf conf = new SparkConf().setAppName("Spark Accumulator Example").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
// 2. 创建数值累加器
LongAccumulator errorAccumulator = sc.sc().longAccumulator("Error Lines");
// 3. 读取日志文件
JavaRDD<String> lines = sc.textFile("src/main/resources/data/logs.txt");
// 4. 在转换算子中使用累加器
JavaRDD<String> errors = lines.filter(line -> {
if (line.contains("ERROR")) {
errorAccumulator.add(1);
return true;
} else {
return false;
}
});
// 5. 触发行动
errors.collect();
// 6. 打印累加器的值
System.out.println("Number of error lines: " + errorAccumulator.value());
// 7. 关闭 Spark 上下文
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这里主要说明一下创建与使用累加器的核心代码:
创建数值累加器
LongAccumulator errorAccumulator = sc.sc().longAccumulator("Error Lines");
- 1
其中 sc.sc() 表示获取到 Spark 的驱动程序,然后调用 longAccumulator 方法为其创建数值累加器,其中传入的字符串 "Error Lines" 表示这个累加器的名字,最终返回一个累加器对象 errorAccumulator。
使用累加器
JavaRDD<String> errors = lines.filter(line -> {
if (line.contains("ERROR")) {
errorAccumulator.add(1);
return true;
} else {
return false;
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用 filter 转换操作过滤包含 "ERROR" 的行,并在每次遇到 "ERROR" 时,累加器加 1。
触发行动
errors.collect();
- 1
使用 collect 操作触发转换算子的执行。此时,累加器会对所有分区的结果进行累加。
获取累加器的值
System.out.println("Number of error lines: " + errorAccumulator.value());
- 1
通过创建累加器返回的对象 errorAccumulator 直接调用 value() 方法即可获得累加器最终的值(默认值为 0)。
广播变量
广播变量(Broadcast Variable)是 Spark 中的一种机制,用于将一个只读变量缓存到每一个节点上,使得任务可以高效地访问该变量,而无需在每个任务中传输该变量的副本。
这对于需要在所有节点上共享大数据集(例如查找表、配置数据)特别有用,因为它避免了重复传输数据,从而节省了网络开销,提高了性能。
广播变量的作用
-
减少数据传输:通过将变量广播到各个节点,只需一次传输,而不是每个任务传输一次,减少了网络开销。
-
提高效率:任务可以直接从节点的内存中读取广播变量,而不需要从驱动程序获取数据,提高了访问速度。
-
确保一致性:所有任务访问的都是相同的广播变量的副本,保证了一致性。
广播变量的创建与使用
在 Spark 中使用广播变量同样分为三步:
-
通过 SparkContext 上下文对象调用
broadcast方法,将要进行广播的变量传入其中,生成一个Broadcast对象。 -
在算子中使用广播变量。在执行 RDD 的转换操作(如
map、filter等)时,可以使用广播变量,通过Broadcast对象的value方法来访问广播的数据。 -
通过行动算子(如
collect、count等)触发计算,完成计算任务。
注意: 广播到各个节点的数据应尽量保持不变,因为广播变量是只读的。
代码案例
假设我们有一个日志文件,每行记录了用户的活动,我们需要根据用户 ID 在另一个数据集中查找用户的详细信息并进行处理。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.broadcast.Broadcast;
import java.util.HashMap;
import java.util.Map;
public class SparkBroadcastExample {
public static void main(String[] args) {
// 创建 Spark 配置和上下文
SparkConf conf = new SparkConf().setAppName("Spark Broadcast Example").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
// 模拟用户详细信息数据集
Map<String, String> userDetails = new HashMap<>();
userDetails.put("1", "Alice");
userDetails.put("2", "Bob");
userDetails.put("3", "Cathy");
// 创建广播变量
Broadcast<Map<String, String>> broadcastUserDetails = sc.broadcast(userDetails);
// 读取日志文件
JavaRDD<String> lines = sc.textFile("src/main/resources/data/logs.txt");
// 根据用户 ID 查找用户详细信息
JavaRDD<String> userActivities = lines.map(line -> {
String[] parts = line.split(" ");
String userId = parts[0];
String activity = parts[1];
String userName = broadcastUserDetails.value().get(userId);
return userName + " did " + activity;
});
// 打印结果
userActivities.foreach(System.out::println);
// 关闭 Spark 上下文
sc.stop();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
代码释义
1.模拟用户详细信息数据集
Map<String, String> userDetails = new HashMap<>();
userDetails.put("1", "Alice");
userDetails.put("2", "Bob");
userDetails.put("3", "Cathy");
- 1
- 2
- 3
- 4
模拟一个用户详细信息的数据集,以 Map 的形式存储,键为用户 ID,值为用户名。
2.创建广播变量
Broadcast<Map<String, String>> broadcastUserDetails = sc.broadcast(userDetails);
- 1
使用 sc.broadcast 方法将用户详细信息数据集广播到每个节点。
3.读取日志文件
JavaRDD<String> lines = sc.textFile("src/main/resources/data/logs.txt");
- 1
使用 textFile 方法读取日志文件,返回一个包含每行日志的 RDD。
4.根据用户 ID 查找用户详细信息
JavaRDD<String> userActivities = lines.map(line -> {
String[] parts = line.split(" ");
String userId = parts[0];
String activity = parts[1];
String userName = broadcastUserDetails.value().get(userId);
return userName + " did " + activity;
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用 map 转换操作处理每行日志,根据用户 ID 在广播变量中查找用户名,并构建新的字符串表示用户活动。
5.打印结果
userActivities.foreach(System.out::println);
- 1
使用 foreach 操作打印每个用户的活动信息。

